Author: Denis Avetisyan
Researchers have developed a new system that combines the power of large language models with structured knowledge to deliver more accurate and adaptable conversational question answering.

Chatty-KG is a training-free, multi-agent framework leveraging knowledge graphs and retrieval-augmented generation for on-demand dialogue.
While large language models excel at natural conversation, reliably grounding responses in structured knowledge remains a challenge. This limitation motivates the development of Chatty-KG: A Multi-Agent AI System for On-Demand Conversational Question Answering over Knowledge Graphs, a novel multi-agent framework that unifies conversational flexibility with the accuracy of knowledge graph querying. By combining retrieval-augmented generation with task-specialized LLM agents, Chatty-KG translates natural language questions into executable SPARQL queries without training or extensive pre-processing. Does this approach represent a scalable path towards truly intelligent and reliable conversational knowledge access?
The Challenge of Conversational Knowledge Graphs
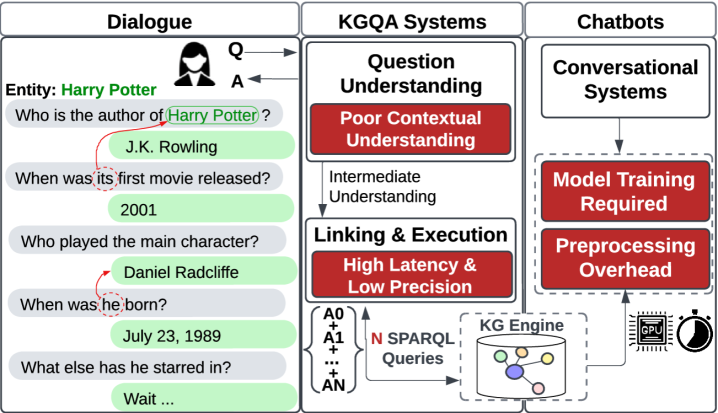
Conventional Knowledge Graph Question Answering (KGQA) systems historically face significant hurdles when confronted with the nuances of extended dialogues. These systems typically rely on painstakingly crafted features – attributes derived from the question and knowledge graph – to bridge the gap between natural language and formal queries. However, this feature engineering process is both time-consuming and often fails to capture the subtle contextual shifts inherent in multi-turn conversations. A key limitation is the difficulty in maintaining context across multiple exchanges; each question is frequently treated in isolation, hindering the system’s ability to correctly interpret follow-up questions that rely on previous dialogue or implicit assumptions. Consequently, traditional KGQA approaches often struggle with complex reasoning and require substantial retraining to adapt to even minor variations in conversational style, limiting their scalability and real-world applicability.
Retrieval-Augmented Generation, while demonstrating promise in conversational Knowledge Graph Question Answering, frequently operates as a ‘black box’, retrieving relevant knowledge snippets but offering limited transparency into how that information supports a specific answer. This contrasts with direct graph querying, where the reasoning path – the precise nodes and relationships traversed to arrive at a conclusion – is explicitly defined and verifiable. Consequently, RAG systems can sometimes generate plausible but inaccurate responses, lacking the logical rigor inherent in graph-based approaches. While RAG excels at leveraging vast amounts of unstructured data, the inherent imprecision can be a significant drawback in scenarios demanding high accuracy and explainability, particularly when dealing with complex relationships within a knowledge graph. The trade-off lies between broad knowledge access and the granular control offered by querying the graph directly.
Successfully interpreting a user’s question and converting it into a precise query for a knowledge graph presents a significant challenge due to the multifaceted nature of human language. Ambiguity, nuanced phrasing, and the reliance on implicit context all contribute to the difficulty of accurately discerning a user’s informational need. Existing systems often struggle with questions that require inference, coreference resolution, or an understanding of the relationships between entities beyond those explicitly stated in the query. Consequently, research focuses on developing sophisticated natural language processing techniques-including semantic parsing, intent recognition, and entity linking-to bridge the gap between colloquial language and the formal structure of knowledge graph queries. These methods aim to not simply identify keywords, but to truly understand the user’s intention, enabling the system to navigate the knowledge graph effectively and return relevant, accurate answers.
Chatty-KG: A Multi-Agent Framework for Conversational Reasoning
Chatty-KG addresses the challenge of conversational Knowledge Graph Question Answering (KGQA) by integrating Large Language Models (LLMs) with SPARQL query execution. The framework leverages LLMs for natural language understanding, question decomposition, and query generation. These generated queries, expressed in SPARQL, are then executed against a knowledge graph to retrieve precise answers. This combination aims to overcome the limitations of LLMs – specifically their potential for hallucination and lack of access to structured knowledge – while also mitigating the complexities of directly translating natural language into SPARQL. The resulting system provides a more robust and accurate approach to KGQA compared to relying solely on either LLMs or traditional information retrieval methods.
Chatty-KG leverages LangGraph as its foundational architecture to manage the complex interplay between multiple agents involved in knowledge graph question answering. LangGraph provides a framework for defining and chaining agents, allowing for the creation of conversational flows where each agent performs a specific task, such as question decomposition, KG querying, or response generation. This modular design promotes scalability by enabling the easy addition or modification of agents without disrupting the entire system. Furthermore, LangGraph facilitates the management of agent memory and context, ensuring coherent and consistent interactions throughout the conversational process, and supports both synchronous and asynchronous agent communication.
Chatty-KG is designed to interface directly with established knowledge graphs, including DBpedia, Wikidata, YAGO, and the Microsoft Academic Graph (MAG), providing access to extensive, structured data. Data retrieval is facilitated through a Virtuoso endpoint, a high-performance relational database management system and SPARQL query engine. This direct integration bypasses the need for intermediate data processing or reliance on potentially unreliable information extraction techniques, ensuring query accuracy and efficient access to knowledge graph data for conversational question answering.

Deconstructing Intent: The Contextual Understanding Module
The Contextual Understanding Module functions as the initial processing stage for user queries, performing a binary classification to determine if a question can be answered independently or requires reference to prior interactions. Self-contained questions possess all necessary information within the query itself, while context-dependent questions rely on previously established conversational history or implicit knowledge from the session. This determination is crucial for selecting the appropriate processing pathway; self-contained questions proceed directly to knowledge graph traversal, whereas context-dependent questions require additional processing to resolve external dependencies before a relevant response can be generated. The module’s accuracy in this classification directly impacts the system’s ability to maintain coherent and accurate conversations.
The Contextual Understanding Module utilizes a Classifier Agent to categorize incoming user questions based on their inherent complexity and dependency on prior conversation turns. This categorization process involves analyzing linguistic features and conversational history to determine if a question requires referencing previous exchanges for complete understanding. The Classifier Agent assigns labels indicating whether a question is self-contained or context-dependent, triggering distinct processing pathways within the module. Specifically, questions identified as context-dependent are flagged for reformulation, while self-contained questions proceed directly to knowledge graph traversal. The classification model is continuously refined through supervised learning, utilizing a dataset of labeled questions to improve accuracy and minimize misclassification rates.
When a user query is identified as context-dependent, the Rephraser Agent is activated to generate a standalone query suitable for knowledge graph traversal. This process involves analyzing the original question and its associated conversational history to extract all necessary information, effectively resolving any implicit references or ambiguities. The Rephraser Agent then constructs a complete and self-contained query, removing the dependency on previous turns in the conversation. This reformulated query is functionally equivalent to a user directly asking the question without prior context, allowing for consistent and accurate retrieval of relevant information from the knowledge graph.

From Query to Answer: Graph Traversal and LLM Reasoning
The Query Planning Agent within Chatty-KG functions by translating natural language questions into formal SPARQL queries for knowledge graph interrogation. This process begins with question reformulation to enhance clarity for the subsequent query generation. Crucially, the agent employs Entity Linking to precisely identify and map entities mentioned in the reformulated question to their corresponding identifiers within the knowledge graph. Accurate entity recognition is paramount; misidentified entities would result in incorrect query construction and ultimately, inaccurate answers. The resulting SPARQL query is then executed against the knowledge graph to retrieve relevant information, forming the basis for the final response.
Chatty-KG utilizes Large Language Models (LLMs), specifically GPT-4o and Gemini, in two key phases of its operation: query refinement and answer generation. During query refinement, the LLM analyzes the initial query generated from user input and restructures it to be more effective for knowledge graph traversal. Subsequently, after the knowledge graph returns relevant data, the LLM synthesizes this information into a coherent and natural language response presented to the user. This dual application of LLMs ensures both accurate information retrieval and a user-friendly conversational experience, moving beyond simple keyword matching to provide contextually relevant and easily understandable answers.
Chatty-KG demonstrates a Precision at 1 (P@1) score of 54.95 when evaluated on the Wikidata knowledge base. This metric indicates the proportion of times the system’s top-ranked answer is correct. Comparative testing reveals Chatty-KG’s performance significantly exceeds that of CONVINSE, which achieved a P@1 score of 27.47, and EXPLAIGNN, which scored 26.37, under identical evaluation conditions. The P@1 score is a key indicator of the system’s ability to consistently return the correct answer as its primary response.
Chatty-KG demonstrates a significant improvement in query efficiency by reducing the number of knowledge graph queries required to answer a given question. Comparative analysis reveals that Chatty-KG executes up to ten times fewer queries than the KGQAn system while maintaining or improving answer accuracy. This reduction in query count is achieved through optimized query planning and LLM-driven refinement, minimizing redundant data retrieval and focusing on the most relevant information. Consequently, the system achieves enhanced processing speed and reduced computational cost without sacrificing precision in knowledge graph question answering.
Chatty-KG utilizes multiple prompting techniques to enhance Large Language Model (LLM) performance in knowledge graph question answering. Zero-Shot Prompting enables the LLM to generate answers without prior examples, relying on its pre-trained knowledge. Few-Shot Prompting provides the LLM with a limited number of example question-answer pairs to guide its reasoning. Chain-of-Thought Prompting encourages the LLM to articulate its reasoning steps before providing the final answer, improving accuracy and explainability. The system’s flexibility in employing these techniques allows for optimization based on query complexity and LLM capabilities, contributing to improved performance metrics as demonstrated on the Wikidata benchmark.
Future Directions: Expanding Chatty-KG’s Capabilities
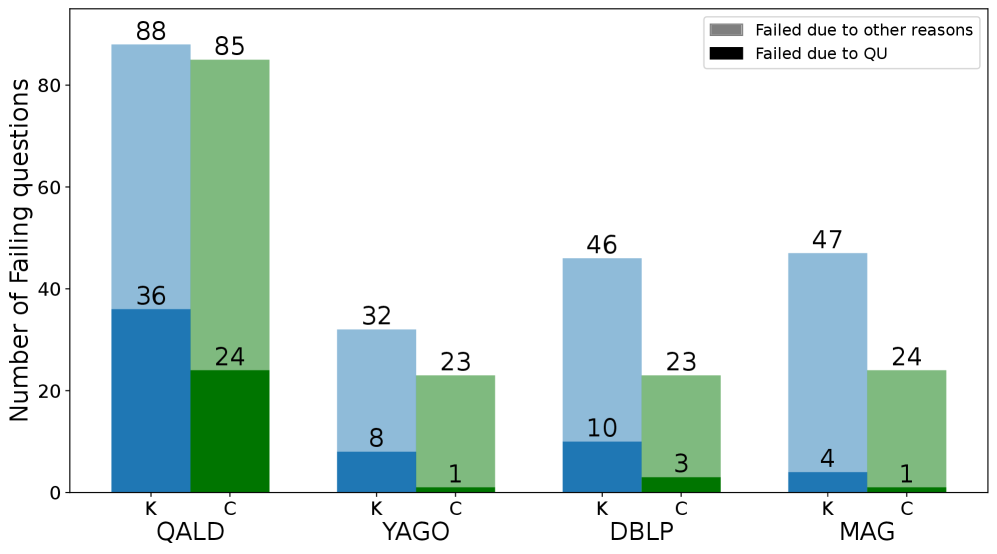
Rigorous evaluation of Chatty-KG’s performance reveals its strong standing within the field of Knowledge Graph Question Answering (KGQA). Standard metrics – including Precision at 1 ($P@1$), Mean Reciprocal Rank ($MRR$), and Hit Rate at 5 ($Hit@5$) – consistently demonstrate Chatty-KG’s competitive edge when contrasted with existing KGQA systems. These metrics assess the system’s ability to retrieve the correct answer within the top-ranked results, and Chatty-KG’s scores indicate a robust capacity for accurate and relevant information retrieval. This quantitative success suggests the framework offers a viable and effective approach to building conversational agents capable of accessing and utilizing structured knowledge from large graphs.
Evaluations reveal that Chatty-KG consistently achieves a high F1 score, peaking at 50.79 across a diverse set of knowledge graph question answering datasets. This metric, representing the harmonic mean of precision and recall, indicates a robust balance between the system’s ability to both accurately retrieve relevant information and minimize the inclusion of incorrect responses. The consistent performance across multiple benchmarks demonstrates Chatty-KG’s generalizability and its capacity to handle a wide variety of knowledge domains and query types, signifying a substantial advancement in the field of conversational knowledge graphs and highlighting its potential for real-world applications requiring precise and comprehensive information access.
Chatty-KG exhibits a significant advancement in processing speed, achieving response times up to ten times faster than the KGQAn system. This performance leap isn’t simply about quicker answers; it underscores the framework’s scalability when handling expansive knowledge graphs. The ability to maintain rapid response times while navigating complex, interconnected data demonstrates a robust architectural design. This efficiency is crucial for real-time applications and interactive dialogues, paving the way for more fluid and engaging knowledge-based interactions. The reduction in latency suggests that Chatty-KG can effectively manage the computational demands of large-scale knowledge, offering a practical solution for systems requiring quick access to and processing of extensive information.
Evaluations incorporating human assessment reveal a notably high degree of conversational coherence within Chatty-KG, registering a score of 4.51 on a 5-point scale. This metric suggests the system doesn’t simply answer questions, but maintains a natural and logical flow throughout extended dialogues. Participants consistently rated interactions as smooth and understandable, indicating the framework effectively manages conversational context and delivers responses that feel relevant and connected to preceding exchanges. This high score highlights Chatty-KG’s potential for building truly engaging and intuitive knowledge-based interfaces, moving beyond simple question-answering towards more fluid and human-like interactions with complex information.
Further development of Chatty-KG prioritizes advancements in its reasoning capabilities, moving beyond simple fact retrieval to encompass more complex inferential processes. This includes exploring techniques like multi-hop reasoning, which allows the system to synthesize information from multiple connected facts within the knowledge graph, and incorporating common-sense reasoning to bridge gaps in explicit knowledge. Simultaneously, efforts are underway to broaden the scope of supported knowledge graphs, moving beyond currently utilized datasets to encompass specialized domains like biomedical research or legal information. This expansion necessitates developing methods for efficient knowledge graph integration and adaptation, ensuring Chatty-KG can seamlessly leverage diverse data sources and maintain performance across varied knowledge structures. Ultimately, these combined enhancements aim to establish a more robust and versatile conversational knowledge-based system, capable of addressing increasingly nuanced and complex information requests.
The development of Chatty-KG signifies a noteworthy step towards knowledge-based systems that move beyond simple question answering to engage in genuinely conversational interactions. By integrating large knowledge graphs with a dialogue-focused architecture, this framework addresses the limitations of traditional systems struggling with complex, multi-turn information needs. The ability to maintain context and generate coherent responses, as demonstrated by human evaluations, suggests a pathway toward applications requiring nuanced understanding and adaptive communication-from personalized education and sophisticated virtual assistants to advanced data exploration and decision support. Further refinement of reasoning capabilities and expansion to diverse knowledge domains promise to unlock even greater potential, establishing Chatty-KG as a foundation for the next generation of intelligent, conversational interfaces.
The architecture of Chatty-KG prioritizes a surgical approach to information retrieval, mirroring a commitment to clarity over complexity. The system dissects a user’s query into manageable components, each handled by a specialized agent-a deliberate avoidance of monolithic design. This modularity isn’t merely organizational; it facilitates rigorous verification at each stage, ensuring the final answer is not a probabilistic guess but a logically derived conclusion. As Alan Turing observed, “There is no substitute for direct experimental evidence,” and Chatty-KG embodies this principle by grounding its responses in the verifiable structure of knowledge graphs, eschewing the opacity of purely generative models. The framework’s success lies in what it removes – ambiguity and reliance on statistical likelihood – leaving only demonstrable truth.
Where to Now?
The current iteration of Chatty-KG, while demonstrating a functional synthesis of linguistic fluency and structured data, merely postpones the inevitable confrontation with inherent ambiguity. The system excels at answering questions, but not at understanding why they are asked. Future work must address this imbalance, shifting focus from retrieval-augmented generation to genuine inferential reasoning-or accept that elegant answers to poorly formed questions are, ultimately, a distraction. The framework’s modularity is its strength, but also highlights the persistent problem of component integration; seamless interaction remains elusive.
A crucial, and often overlooked, limitation is the assumption of a complete, accurate knowledge graph. Real-world knowledge is notoriously fragmented and inconsistent. Systems like Chatty-KG will not merely ‘access’ knowledge, but must actively reconcile conflicting information-a task that requires not intelligence, but a rigorous commitment to identifying and discarding noise. The pursuit of ‘contextual understanding’ is, therefore, best served by focusing on what can be safely ignored.
Ultimately, the value of such systems will not be measured by their ability to mimic conversation, but by their capacity to reduce complexity. A perfect question-answering system does not generate more data; it eliminates the need for the question in the first place. That, perhaps, is the true north of this research.
Original article: https://arxiv.org/pdf/2511.20940.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- All Shadow Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- Best Bows in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- How to Craft the Elegant Carmine Armor in Crimson Desert
- Keeping Large AI Models Connected Through Network Chaos
- One Piece Chapter 1179 Preview: The Real Imu Arrives in Elbaf
2025-11-29 14:43