Author: Denis Avetisyan
Researchers have developed a new dataset and technique to significantly improve the accuracy of converting natural language questions into SQL queries for Arabic databases.

This paper introduces Ar-SParC, an Arabic dataset for context-dependent text-to-SQL, and demonstrates the effectiveness of the GAT Corrector prompt engineering approach.
While substantial progress has been made in natural language to SQL translation, most research and datasets remain focused on English and Chinese, creating a significant gap for other languages. This paper, ‘Prompt Engineering Techniques for Context-dependent Text-to-SQL in Arabic’, addresses this limitation by introducing Ar-SParC, the first Arabic dataset for complex, multi-turn text-to-SQL queries. Experiments utilizing large language models demonstrate that a novel prompt engineering approach, termed GAT Corrector, consistently improves performance on this new dataset-yielding gains in both execution and interaction accuracy. Could this technique offer a pathway toward more effective and accessible database interaction for Arabic speakers and beyond?
The Challenge of Bridging Language and Data
The ability to translate human language into Structured Query Language (SQL) represents a pivotal step towards democratizing data access, yet this conversion remains a formidable challenge. Linguistic complexity, inherent in the nuances of grammar, ambiguity, and synonymy, necessitates sophisticated natural language processing techniques. Simultaneously, the intricacies of database schemas – encompassing tables, columns, relationships, and constraints – demand a deep understanding of data organization. A successful translation requires not only parsing the user’s intent but also mapping that intent to the specific structure of the underlying database, a task complicated by variations in schema design and the potential for multiple valid SQL interpretations. This intersection of linguistic and structural challenges explains why robust natural language to SQL translation systems are still an active area of research, despite considerable progress in both fields.
Current natural language to SQL translation systems often falter when faced with questions that build upon previous inquiries. These systems typically treat each question in isolation, neglecting the crucial context established by prior interactions. Consequently, a follow-up question like “And now show me the total” – referencing a previously requested dataset – frequently results in errors because the system lacks the ability to connect the pronoun “it” to the correct table or data. Effectively handling such context-dependent questions demands a model capable of maintaining a dialogue state, tracking referenced entities, and integrating information across multiple turns of conversation – a significant hurdle in achieving truly intuitive database interaction.
The Foundation of Progress: Diverse Datasets
The advancement of text-to-SQL models is heavily reliant on the creation of specialized datasets such as Ar-SParC, PAUQ, Ar-Spider, and BIRD. These resources facilitate both the training and rigorous evaluation of models capable of translating natural language questions into SQL queries. Datasets differ in their complexity and scope; for example, Ar-Spider focuses on complex, multi-table queries, while PAUQ emphasizes compositional generalization. The inclusion of multiple datasets allows for assessment of a model’s ability to handle diverse database schemas, question types, and, increasingly, multiple languages, moving beyond English-centric development and enabling cross-lingual text-to-SQL capabilities.
Specialized datasets such as Ar-SParC, PAUQ, Ar-Spider, and BIRD function as critical benchmarks for evaluating text-to-SQL model performance by presenting challenges in two key areas: context-dependent queries and diverse database schemas. Context-dependent queries require the model to correctly interpret and utilize information from previous turns in a conversation or from complex query structures, moving beyond simple keyword matching. Simultaneously, the datasets incorporate a wide variety of database schemas – differing in the number of tables, relationships between tables, and data types – to assess a model’s ability to generalize beyond the specific structure of its training data. Performance metrics derived from these datasets, including execution accuracy and logical form correctness, allow for quantitative comparison of different model architectures and training strategies.
Guiding the Model: The Art of Prompt Engineering
The accuracy of SQL queries generated by large language models (LLMs) such as GPT-3.5-turbo and GPT-4.5-turbo is heavily dependent on the quality of the input prompt. These LLMs, while capable of understanding natural language, do not inherently possess database schema knowledge or SQL syntax expertise. Consequently, poorly constructed prompts can lead to syntactically incorrect, semantically flawed, or inefficient SQL queries. Effective prompt engineering, therefore, involves carefully designing prompts that provide sufficient context, clear instructions, and, potentially, examples to guide the LLM towards generating the desired SQL output. This includes specifying the database schema, the desired query objective, and any relevant constraints or assumptions.
Prompt engineering for large language models utilizes a spectrum of techniques, beginning with simple prompt structures such as Basic Prompts which directly request a SQL query, Text Representation Prompts which present the database schema in natural language, and Code Representation Prompts which provide the schema as SQL code. More advanced strategies involve in-context learning, where the model is given examples to guide its response. Random In-Context Learning presents randomly selected examples, while Question Similarity Selection chooses examples based on semantic similarity to the input question. DAIL (Demonstration-Augmented In-Context Learning) Selection further refines this by prioritizing demonstrations that maximize performance on a held-out dataset, aiming to improve the model’s ability to generalize from the provided examples.
Refining the Approach: GAT-SQL’s Multi-Stage Design
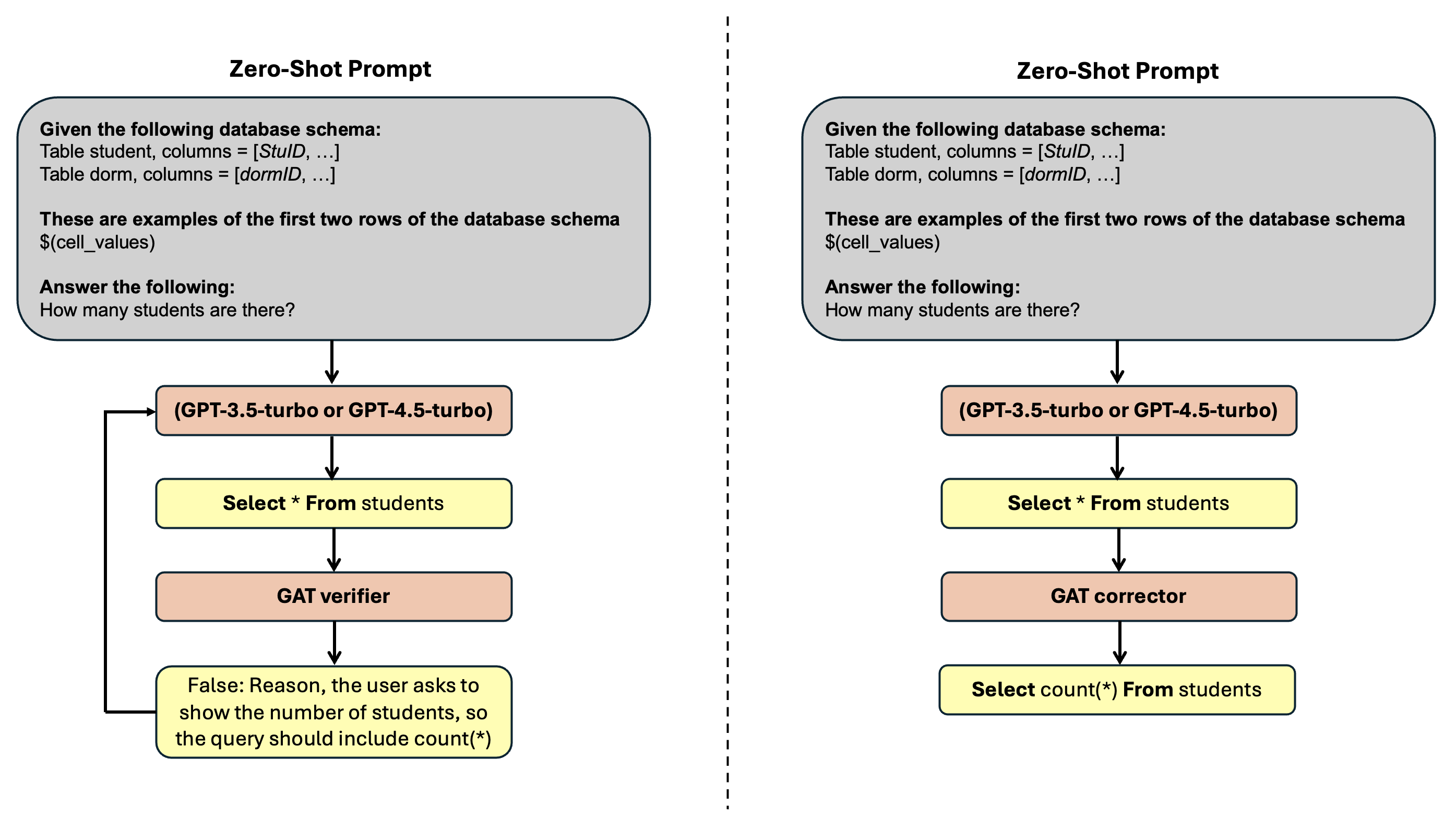
GAT-SQL employs a multi-stage prompt engineering approach to enhance SQL query generation. This system utilizes GAT Representation to initially translate natural language questions into an intermediate, structured representation facilitating accurate query construction. Subsequently, the GAT Reviser component refines this representation based on database schema information, ensuring semantic consistency and feasibility. Finally, the GAT Verifier assesses the generated SQL query against the database schema and question constraints, identifying and flagging potential errors before execution. This iterative process of representation, revision, and verification aims to mitigate common SQL generation issues and improve overall query accuracy.
GAT Corrector functions as a post-processing step in SQL query generation, employing a sequence-to-sequence model trained to identify and rectify syntactic and semantic errors within the initially generated SQL. This correction process involves analyzing the generated query against the database schema and natural language question, pinpointing inaccuracies such as incorrect column names, invalid joins, or flawed aggregation functions. The model then proposes and implements corrections, resulting in a syntactically valid and semantically accurate SQL query. Evaluations demonstrate that integrating GAT Corrector consistently improves the execution accuracy of generated SQL, particularly in complex query scenarios, by addressing errors that would otherwise lead to incorrect results or query failures.
Measuring Success: Accuracy and Conversational Flow
The effectiveness of the proposed approach is rigorously evaluated through established metrics – Execution Accuracy (EX) and Interaction Accuracy (IX). Execution Accuracy quantifies the correctness of the generated SQL queries by determining if they return the expected results when executed against the database. Critically, Interaction Accuracy goes beyond single queries, assessing the system’s capacity to accurately respond to a series of connected questions – a crucial test for real-world conversational database interactions. This metric reveals whether the system maintains context and builds upon prior responses to provide coherent and correct answers throughout a dialogue, demonstrating a deeper understanding than simple query fulfillment. These combined metrics provide a comprehensive measure of the system’s ability to both generate syntactically correct SQL and engage in meaningful, multi-turn conversations with a database.
Evaluations reveal that GAT-SQL consistently enhances the accuracy of SQL query generation and question answering. Across zero-shot experiments – where the model receives no prior examples – GAT-SQL achieves an average improvement of 1.9% in both Execution Accuracy (EX), measuring the correctness of generated SQL, and Interaction Accuracy (IX), assessing the ability to answer connected questions. This performance extends to in-context learning scenarios, where the model learns from a limited number of examples, yielding gains of 1.72% in EX and 0.92% in IX. Further analysis highlights the efficacy of the GAT Corrector component; in sentence meaning comparison tasks, it demonstrated a markedly lower error rate – only 3 errors per 100 sentences – compared to the 33 errors per 100 recorded by the GAT Verifier, indicating a substantial improvement in semantic understanding and correction capabilities.
The pursuit of accuracy in semantic parsing, as demonstrated by Ar-SParC and the GAT Corrector, benefits from a relentless simplification of approach. The study prioritizes functional correctness over elaborate construction, echoing a principle of structural honesty. Barbara Liskov observed, “Programs must be right first, then efficient.” This aligns with the paper’s focus on enhancing the reliability of text-to-SQL translation, even within the complexities of context-dependent queries and Arabic NLP. The GAT Corrector’s method is not about adding layers of sophistication, but rather refining the existing structure to minimize errors and maximize clarity.
Beyond the Query
The creation of Ar-SParC is not, as some might claim, a triumph. It is merely an acknowledgement of prior insufficiency. A dataset, however meticulously constructed, addresses only the symptoms of a deeper problem: the assumption that natural language can be reliably mapped onto formal logic. The observed gains from GAT Corrector are, therefore, not evidence of intelligence, but of cleverly disguised error mitigation. The system functions because it anticipates, and then circumvents, the inevitable failures of semantic parsing.
Future work will undoubtedly focus on scaling these techniques, applying them to other languages, and perhaps even attempting to address the inherent ambiguity of human communication. However, a more fruitful avenue may lie in questioning the premise itself. If robust text-to-SQL translation consistently eludes us, perhaps the goal is fundamentally misguided. The complexity introduced by context-dependent queries is not a challenge to be overcome, but a signal – a reminder that language is rarely, if ever, a precise instrument.
The true test will not be achieving higher accuracy on benchmark datasets, but in building systems that gracefully acknowledge their own limitations. A system that knows what it does not know is, paradoxically, closer to understanding than one that confidently returns a flawed result. The pursuit of perfection, in this field, is a distraction. Clarity, even if it means admitting defeat, is the only path forward.
Original article: https://arxiv.org/pdf/2511.20677.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- All Shadow Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- Best Bows in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- How to Craft the Elegant Carmine Armor in Crimson Desert
- Keeping Large AI Models Connected Through Network Chaos
- One Piece Chapter 1179 Preview: The Real Imu Arrives in Elbaf
2025-11-29 23:12