Author: Denis Avetisyan
A new system embeds schema-aware watermarks directly into assessment documents to proactively deter AI-assisted cheating and establish clear authorship signals.
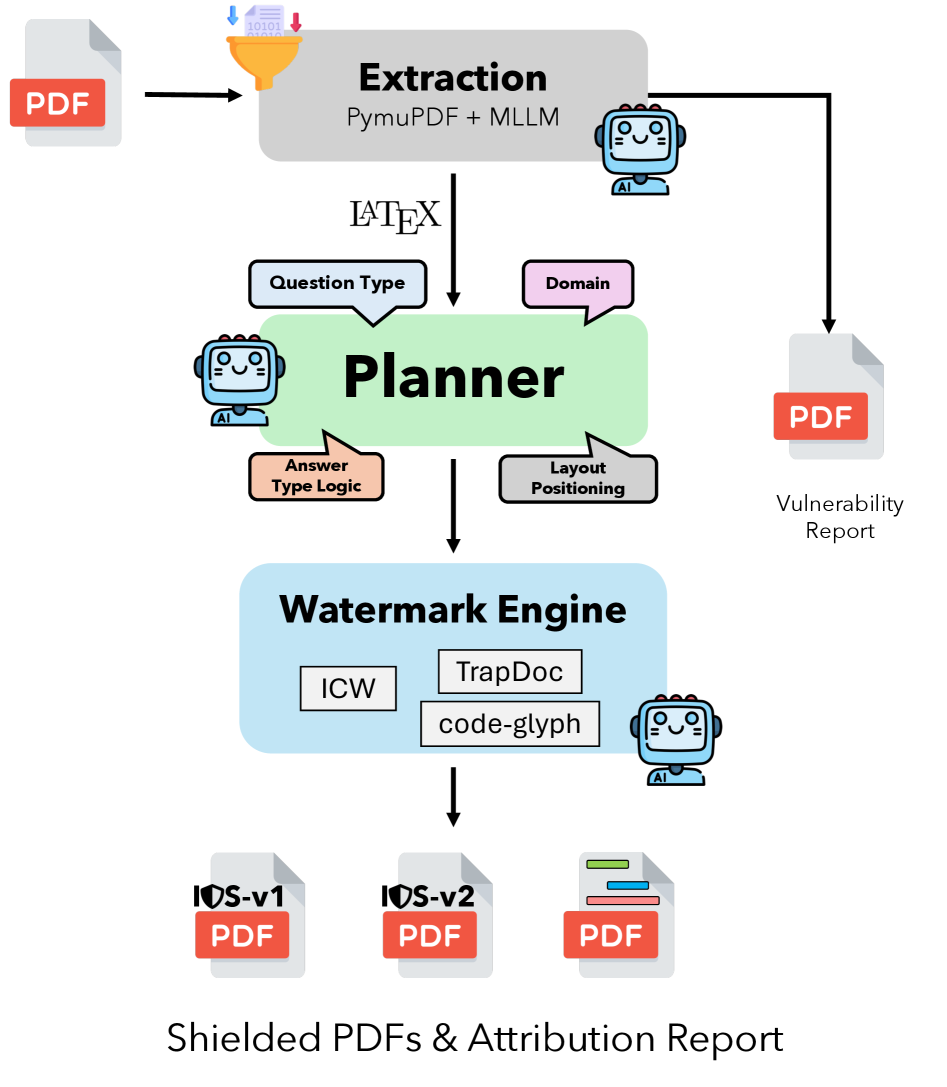
Integrity Shield utilizes document-layer watermarking to provide interpretable evidence of original work and combat the misuse of large language models in assessments.
The increasing sophistication of large language models presents a paradox: while offering powerful educational tools, they simultaneously threaten academic integrity by solving entire assessments. Addressing this challenge, ‘Integrity Shield A System for Ethical AI Use & Authorship Transparency in Assessments’ introduces a document-layer watermarking system that embeds schema-aware signatures into assessment PDFs, effectively preventing AI-assisted cheating. Across diverse exam types, this approach achieves high blocking rates and reliable detection of watermarked content, offering a proactive alternative to post-hoc AI detection. Could this system pave the way for a more trustworthy and equitable assessment landscape in the age of advanced AI?
The Inevitable Erosion of Scholarly Trust
The rapid evolution of Large Language Models (LLMs) is fundamentally reshaping the landscape of academic integrity. These increasingly sophisticated AI systems, trained on vast datasets of text and code, can now generate remarkably human-like writing, making it difficult to distinguish between original student work and AI-generated content. While offering potential benefits for research and learning, LLMs also present a significant challenge as they can readily complete assignments, write essays, and even answer complex questions with a level of fluency previously unattainable by automated tools. This capability introduces a novel form of plagiarism and necessitates a reevaluation of traditional assessment methods, pushing educators to prioritize higher-order thinking skills and authentic learning experiences that are less susceptible to AI circumvention. The sheer accessibility and improving quality of these models demand proactive strategies to safeguard the value of academic credentials and ensure genuine intellectual development.
The efficacy of long-standing assessment techniques is rapidly diminishing as artificial intelligence capabilities advance. Previously reliable methods – such as essays, take-home exams, and even some in-class writing assignments – are now susceptible to circumvention through sophisticated Large Language Models. These models can generate coherent and contextually relevant text, making AI-produced work increasingly difficult to distinguish from human-authored submissions. This vulnerability extends beyond simple plagiarism detection, as AI can synthesize information and formulate arguments, effectively completing assignments without demonstrating genuine understanding of the subject matter. Consequently, educators face a growing challenge in accurately gauging student comprehension and upholding academic integrity, necessitating a reevaluation of assessment strategies to prioritize critical thinking, application of knowledge, and uniquely human skills.
The pervasive availability of instant answers, fueled by advancements in artificial intelligence, presents a significant threat to the development of deep, conceptual understanding. Rather than engaging in the cognitive effort required to truly learn and internalize information, students increasingly rely on readily accessible responses, fostering a pattern of surface-level comprehension. This shift compromises not only the acquisition of knowledge, but also the cultivation of critical thinking skills, problem-solving abilities, and the capacity for independent intellectual exploration – all essential components of a robust education. The consequence is a potential devaluation of genuine learning, where the ability to find an answer eclipses the understanding of the underlying principles, ultimately hindering long-term academic and professional success.
A Subtle Signal Within the Structure
Integrity Shield operates as a document-layer watermarking system, meaning watermarks are embedded directly within the structure of the assessment document itself, rather than being visually apparent. This contrasts with traditional watermarking techniques that alter the visible content. The system is specifically designed to identify responses likely generated with the assistance of large language models (LLMs) during assessments. By analyzing subtle patterns introduced during document creation, Integrity Shield aims to differentiate between human-authored text and text produced by AI. The watermarks are imperceptible to the user and do not affect the readability or functionality of the assessment, while still providing a traceable signal for detection purposes.
Integrity Shield employs schema-aware watermarks to enhance detection accuracy across diverse assessment formats. Unlike traditional watermarking methods that apply a uniform signal, this system analyzes the structure of each question type – Multiple Choice Questions (MCQ), True/False, and Long-Form Questions – and adjusts the watermark accordingly. For MCQs and True/False, watermarks are embedded within the selectable options or statement phrasing. Long-Form Questions leverage more complex watermarking patterns integrated into sentence structure and paragraph flow. This adaptive approach ensures watermark robustness against paraphrasing and manipulation techniques while minimizing impact on readability and maintaining signal strength specific to each question schema.
The Integrity Shield system employs an LLM-Driven Planner to optimize watermark application by analyzing both the layout and content of each assessment question. This dynamic assignment of watermark ‘plans’ moves beyond static watermarking approaches; the planner selects a specific strategy-varying in watermark density, pattern, and placement-tailored to the question type and textual structure. This adaptive methodology is designed to maximize the watermark’s signal strength, making it more detectable by the system’s verification tools, while simultaneously enhancing its resilience against attempts at removal or manipulation through paraphrasing or content alteration. The planner considers factors such as question length, the presence of lists or tables, and the complexity of the language used to determine the most effective watermarking approach for each individual question within an assessment.
The Ghost in the Machine: Embedding the Signal
The PDF Watermark Engine implements a pre-defined watermark plan through three core techniques: Hidden Text Injection, Glyph Remapping, and Overlay Application. Hidden Text Injection inserts imperceptible text strings into the PDF’s metadata or content streams. Glyph Remapping subtly alters character representations by substituting visually identical glyphs with alternate forms. Overlay Application introduces a translucent layer containing the watermark data, positioned to avoid obscuring assessment content. These methods are applied algorithmically to the PDF’s internal structure, ensuring consistent and accurate watermark embedding as defined by the selected plan.
The watermark embedding process modifies the PDF’s internal object streams and cross-reference table without altering the rendered visual content. Specifically, changes are made to non-rendering attributes of PDF objects, such as annotations, embedded fonts, or color spaces, and to the arrangement of internal objects. These alterations do not affect the glyph outlines or raster data responsible for the visible text and images, thereby preserving the document’s original appearance and ensuring full readability for users and compatibility with standard PDF viewers and processing tools. The resulting modifications are designed to be imperceptible to standard visual inspection and remain consistent across different PDF rendering engines.
Document-Layer Watermarking embeds the identifying signal directly within the PDF’s internal object structure – specifically within the content streams and cross-reference tables – rather than applying it as a visible or superficial layer. This approach differs from image-based watermarks or those applied as external annotations. By integrating the signal at this fundamental level, common AI manipulation techniques, such as copy-paste alterations, re-rendering, or OCR processing, are less effective at removing or obscuring the watermark because these methods typically operate on the visible presentation layer and do not reconstruct the underlying document structure. The signal persists even after significant document modifications that preserve the core PDF format.
The Calibration of Trust: Detecting AI Reliance
The Authorship and Calibration Service functions by meticulously examining student submissions and contrasting their linguistic patterns with a database of pre-established watermark signatures. This process doesn’t seek to identify plagiarism in the traditional sense, but rather to detect the subtle, statistically-derived traces left by AI language models. The system operates on the principle that even paraphrased AI-generated text retains identifiable characteristics, allowing it to differentiate between human and machine authorship with a high degree of accuracy. By comparing responses against these stored signatures, the service can effectively flag potentially AI-assisted work, providing educators with valuable insights into the authenticity of student contributions and enabling a more nuanced assessment of learning outcomes.
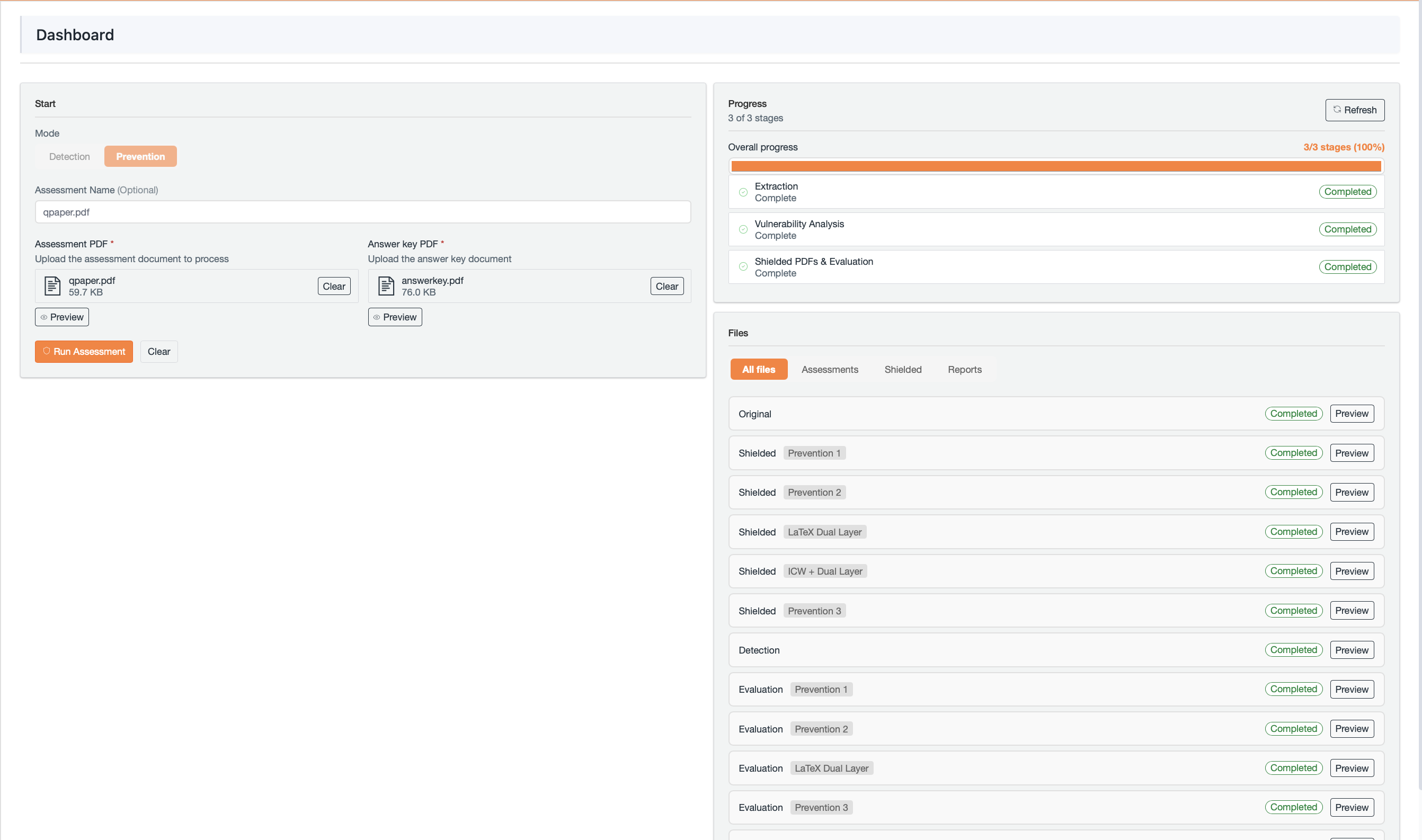
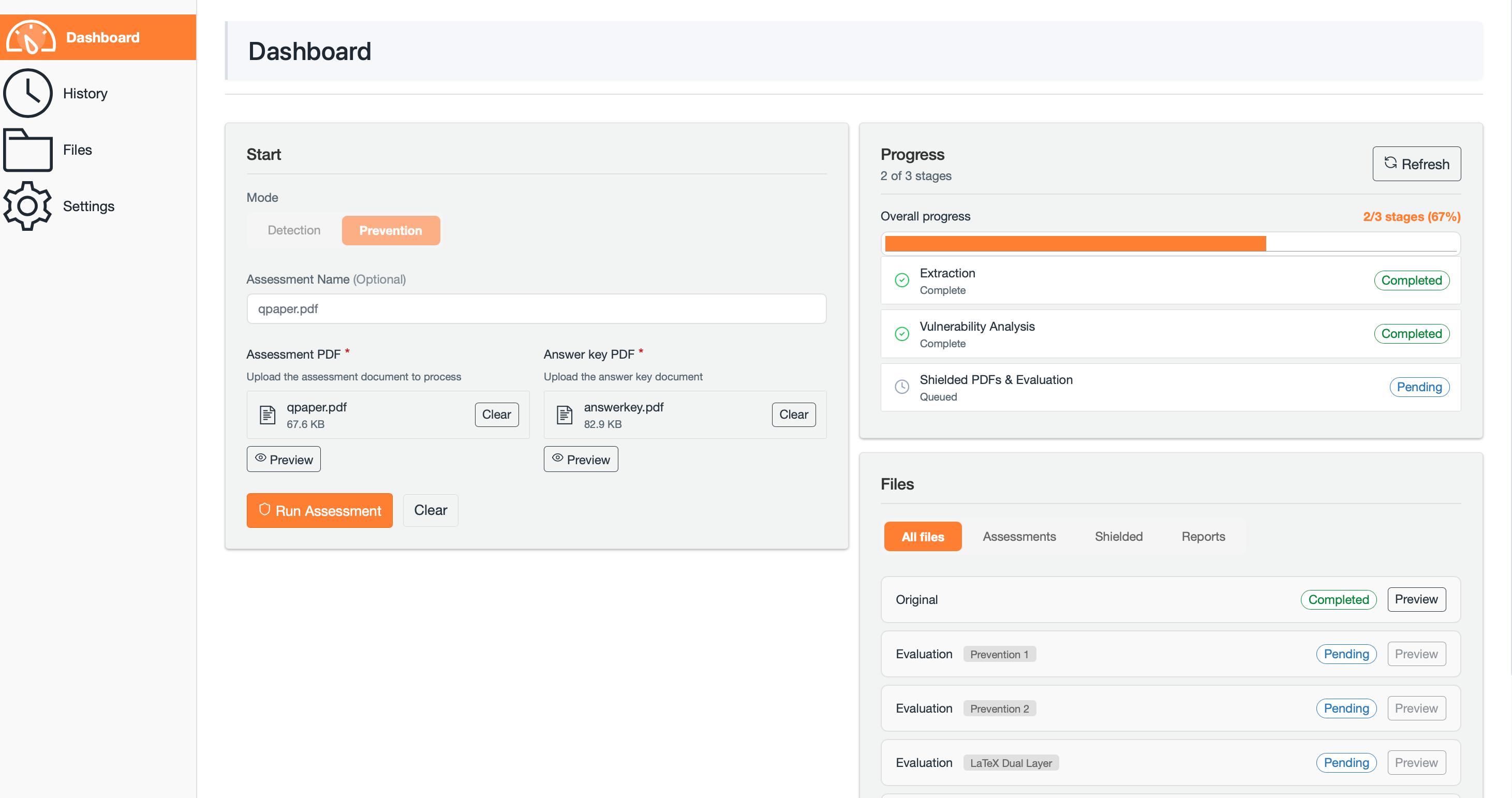
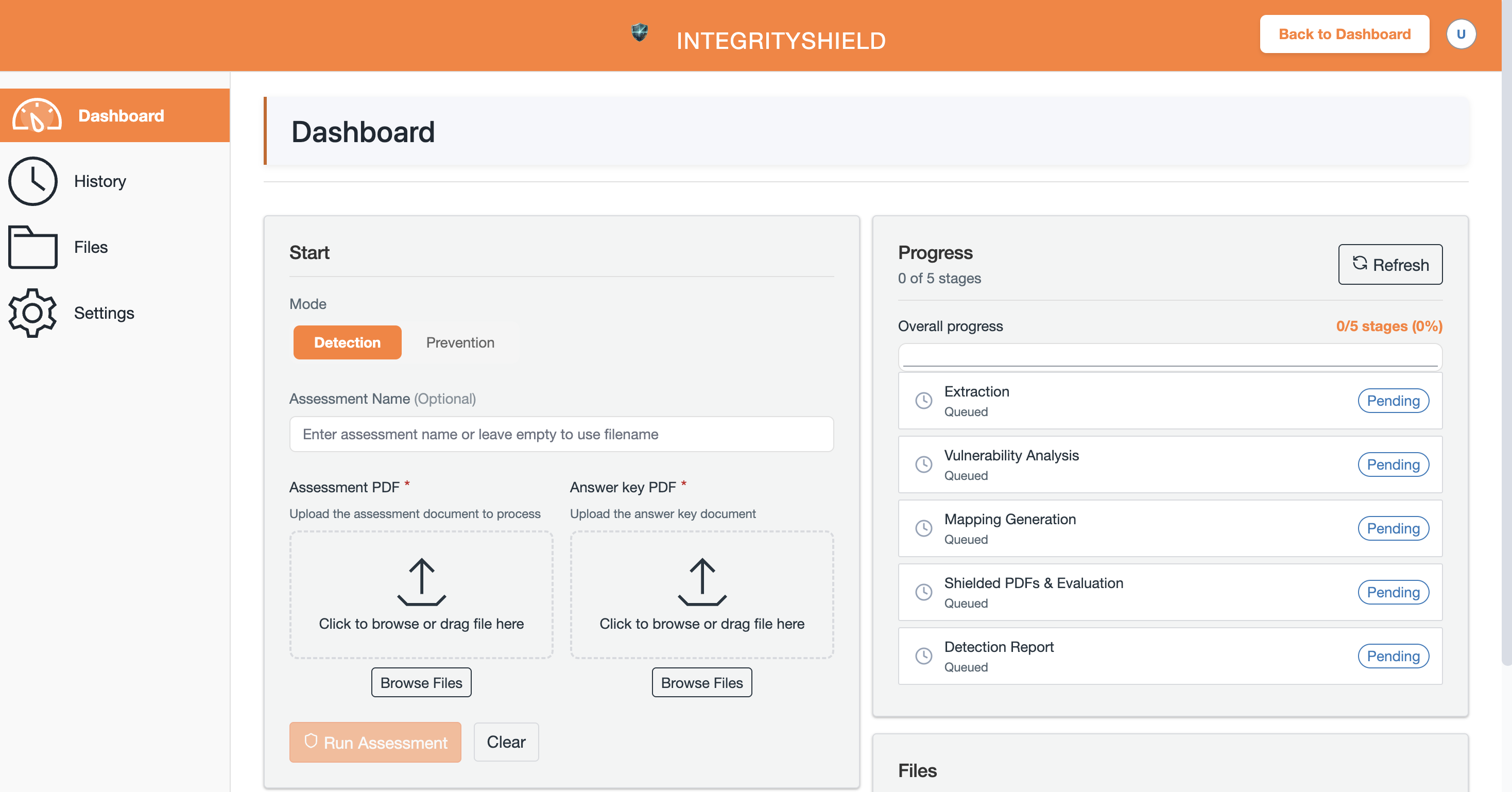
The efficacy of the Integrity Shield system is rigorously quantified through two key metrics: Detection Rate and Prevention Rate. Detection Rate measures the system’s consistent ability to recover embedded watermark signatures within student responses, ensuring accurate identification of AI-generated text. Complementing this, Prevention Rate assesses the system’s success in hindering AI models from correctly answering exam questions. Evaluations demonstrate that Integrity Shield achieves remarkably high scores in both areas – consistently preventing AI solutions with a rate of 91-94% and reliably detecting watermarks across various AI models with 89-93% accuracy. These results highlight the system’s robust performance and its potential to maintain academic integrity by both discouraging AI use and verifying authorship.
Rigorous evaluations pitted the watermark-based detection system against a suite of cutting-edge large language models, including GPT-5, Claude Sonnet-4.5, Grok-4.1, and Gemini-2.5 Flash, to assess its resilience. Results indicate a substantial performance decrease in these models when confronted with watermarked questions, with an average reduction in answer accuracy ranging from 85 to 90% across diverse question formats. This significant accuracy drop demonstrates the system’s ability to effectively disrupt the utility of AI-generated responses, confirming its potential as a robust tool for maintaining academic integrity and ensuring genuine assessment of student understanding. The consistent performance across multiple models highlights the watermark’s broad applicability and resistance to circumvention by varying AI architectures.
The pursuit of assessment integrity, as detailed within Integrity Shield, reveals a familiar pattern. Systems designed to control often reveal their inherent limitations. The document-layer watermarking approach, while innovative, isn’t about eliminating the possibility of circumvention-it’s about raising the cost and creating a traceable signal. As Donald Davies observed, “The art of systems design isn’t about creating perfect solutions, but about building systems that fail gracefully and reveal their failures.” This echoes the core concept of the system; it doesn’t promise a cheat-proof environment, but a demonstrable record of authorship and a means to understand how a system was compromised. Every architectural choice, even one focused on ethical AI use, is a prophecy of future adaptation-and ultimately, a temporary reprieve from the inevitable chaos.
What’s Next?
Integrity Shield addresses a symptom, not the disease. The impulse to outsource cognition will not be deterred by watermarks, only redirected. Each iteration of schema-aware signatures invites a corresponding evolution in adversarial prompting, a dance of increasingly subtle obfuscation. Long-term stability is not a feature here, but a period of quiet before the next, more sophisticated bypass emerges. The system’s value, then, lies not in absolute prevention, but in raising the cost of circumvention – a temporary, localized increase in entropy.
The true challenge isn’t detecting AI-assisted work, but redefining “assessment” itself. Current models implicitly assume a singular, traceable author. This is becoming a historical artifact. Future systems will need to assess collaboration with AI, not merely authorship. Signals of intent, the process of knowledge construction, and the critical evaluation of generated content – these will be the relevant metrics. The document-layer watermark may become a quaint relic, a footnote in the archaeology of educational technology.
Consider, too, the metadata. Every signature, every detection attempt, creates a new data point, ripe for aggregation and analysis. This isn’t about protecting assessment integrity; it’s about building a comprehensive profile of student behavior. The system doesn’t merely flag potential cheating; it builds a model of how students attempt to learn-and, inevitably, to game the system. Stability here isn’t a virtue; it’s the prelude to unforeseen consequences.
Original article: https://arxiv.org/pdf/2601.11093.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Limits of Thought: Can We Compress Reasoning in AI?
- Genshin Impact Dev Teases New Open-World MMO With Realistic Graphics
- Sega Reveals Official Sonic Timeline: From Prehistoric to Modern Era
- Where to Pack and Sell Trade Goods in Crimson Desert
- ARC Raiders Boss Defends Controversial AI Usage
- Who Can You Romance In GreedFall 2: The Dying World?
- ETH PREDICTION. ETH cryptocurrency
- Best Weapons, Armor, and Accessories to Get Early in Crimson Desert
- Top 10 Must-Watch Isekai Anime on Crunchyroll Revealed!
- Best Build for Operator in Risk of Rain 2 Alloyed Collective
2026-01-20 15:57