Author: Denis Avetisyan
A new system intelligently manages memory to accelerate long-form AI interactions and reduce response times.
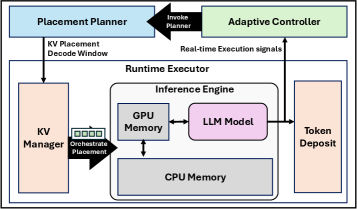
OrbitFlow dynamically reconfigures KV cache placement using integer linear programming to optimize long-context language model serving.
Serving long-context large language models (LLMs) presents a key challenge: fluctuating memory demands during inference often lead to performance bottlenecks and unmet service level objectives (SLOs). To address this, we introduce ORBITFLOW, a novel system for SLO-aware long-context LLM serving with fine-grained KV cache reconfiguration. ORBITFLOW utilizes an integer linear programming solver to dynamically optimize KV cache placement, adapting to runtime conditions and reducing costly data transfers. Our experiments demonstrate significant improvements in both SLO attainment and throughput – up to 66% and 3.3x, respectively – raising the question of how such adaptive memory management techniques can further unlock the potential of increasingly complex LLMs.
The LLM Serving Bottleneck: A Looming Crisis
The proliferation of Large Language Models (LLMs) is quickly transforming numerous fields, from automated content creation and sophisticated chatbots to advanced data analysis and code generation. This rapid adoption isn’t merely a technological trend; it represents a fundamental shift in how humans interact with machines and process information. Consequently, the demand for infrastructure capable of reliably and efficiently serving these models is escalating dramatically. Simply having a powerful LLM is insufficient; organizations require robust systems to handle concurrent requests, minimize latency, and scale resources dynamically to accommodate growing user bases and increasingly complex tasks. This need extends beyond simply deploying a model; it necessitates a complete ecosystem of tools and techniques for optimized performance, cost-effectiveness, and sustained operation as LLMs become integral components of everyday applications.
As Large Language Models become increasingly integrated into applications ranging from chatbots to code generation, conventional deployment strategies are facing significant hurdles. Early methods, designed for smaller models and modest user bases, struggle to cope with the sheer size of contemporary LLMs – often exceeding hundreds of billions of parameters – and the escalating volume of concurrent requests. This translates directly into higher latency, where response times become unacceptably slow for real-time applications, and substantial resource constraints, demanding ever-increasing computational power and memory. The core issue isn’t simply a matter of scaling up existing infrastructure; rather, the fundamental architecture of many serving systems proves inadequate for efficiently handling the unique demands of these massive models, creating a bottleneck that limits both performance and scalability.
The escalating deployment of Large Language Models hinges on breakthroughs in how these models are served – that is, how efficiently computational resources are allocated to process user requests. Traditional methods are quickly becoming inadequate as models grow in size and user demand intensifies, leading to unacceptable delays and exorbitant costs. Innovations in memory management are therefore crucial, exploring techniques like quantization, pruning, and offloading to optimize model storage and retrieval. Simultaneously, sophisticated request scheduling algorithms are needed to prioritize urgent tasks, batch similar requests, and distribute workload across available hardware. These combined advancements – smarter memory handling and intelligent request routing – are not merely performance enhancements, but fundamental requirements for realizing the full potential of LLMs in real-world applications, ensuring responsiveness and scalability as adoption continues to accelerate.
The KV Cache: A Necessary Evil
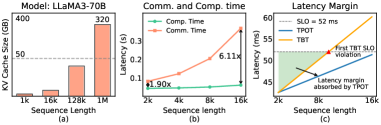
The Key-Value (KV) cache is integral to the efficient operation of Large Language Models (LLMs) by storing the key and value vectors generated during the attention mechanism. These vectors, representing contextual information for each token, are computationally expensive to recalculate repeatedly. By caching them, subsequent computations during decoding or inference can directly access these pre-computed representations, significantly reducing processing time and improving throughput. Specifically, during autoregressive generation, the KV cache stores the keys and values for all previous tokens in the sequence, allowing the model to attend to past context without recomputing attention weights for each new token generated. The size of the KV cache scales linearly with the sequence length and the model’s hidden dimension, making it a substantial memory consumer but a critical performance optimization.
The key-value (KV) cache stores the results of attention computations for each token in a sequence, enabling faster processing during decoding. However, the memory footprint of the KV cache scales linearly with sequence length and quadratically with the model’s hidden size. Consequently, large language models (LLMs) and extended sequence lengths rapidly exhaust available GPU memory, creating a performance bottleneck. For example, a model with a 32,000 hidden size and a sequence length of 2048 tokens requires approximately 256MB of GPU memory for the KV cache alone, excluding the memory required for model weights, activations, and other runtime data. This limitation restricts both the maximum supported sequence length and the batch size that can be processed concurrently.
KV offloading addresses GPU memory constraints by transferring less frequently accessed key-value pairs from GPU memory to Host memory (system RAM). While this increases the total available memory capacity, accessing data in Host memory incurs significantly higher latency compared to GPU memory access. Effective KV offloading requires careful management strategies, including intelligent caching policies to predict which key-value pairs will be needed next, prefetching data from Host memory to GPU memory before it is required, and optimized data transfer mechanisms to minimize the overhead associated with moving data between memory spaces. The trade-off between memory capacity and access latency is central to implementing a successful KV offloading solution.
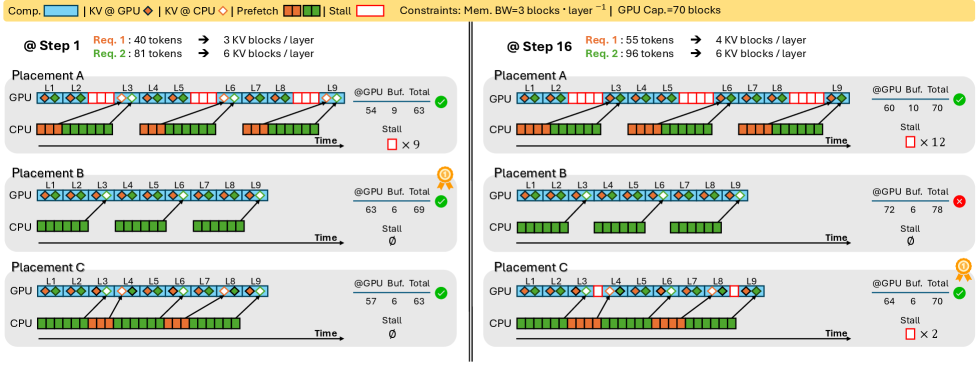
OrbitFlow: A Dynamic Patch for a Broken System
OrbitFlow implements a dynamic Key-Value (KV) cache management system for Large Language Model (LLM) serving. Unlike static allocation strategies, OrbitFlow continuously reconfigures the placement of KV cache entries between GPU and Host memory during inference. This dynamic adjustment is based on real-time workload characteristics and resource availability, allowing the system to prioritize frequently accessed tokens on the faster GPU memory while offloading less-used tokens to the Host memory. This approach directly addresses the memory bottleneck inherent in long-context LLM serving, enabling increased throughput – the number of processed requests per unit time – and reduced latency – the time taken to process a single request – compared to systems with fixed KV cache configurations.
OrbitFlow utilizes an Integer Linear Programming (ILP)-based solver to optimize Key-Value (KV) cache placement between GPU and Host memory. This solver dynamically assigns each KV entry to either GPU or Host memory based on predicted access patterns and resource constraints. The ILP formulation considers factors such as memory bandwidth, transfer costs, and computational requirements to minimize latency and maximize throughput. By strategically locating frequently accessed KV entries on the GPU and less frequently accessed entries in Host memory, OrbitFlow achieves a balance between fast access and efficient resource utilization, thereby improving overall LLM serving performance.
Token Deposit and the Pause-Resume Mechanism are employed by OrbitFlow to optimize request scheduling and maintain service stability under high load. Token Deposit pre-allocates necessary KV cache tokens, reducing contention during request processing and minimizing delays associated with dynamic allocation. The Pause-Resume Mechanism allows the system to temporarily pause accepting new requests when approaching resource limits, preventing performance degradation for existing requests. Once resources become available, the system resumes accepting requests, ensuring a controlled and predictable service level even during peak demand. This combination proactively manages resource allocation and request intake, preventing overload conditions and maintaining consistent performance.
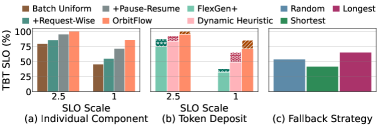
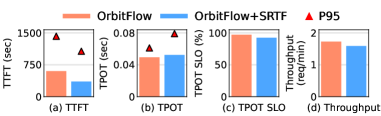
Performance evaluations demonstrate that OrbitFlow achieves substantial improvements in Service Level Objective (SLO) attainment for long-context Large Language Model (LLM) serving. Specifically, OrbitFlow has shown up to a 66% improvement in Time to First Token (TPOT) SLO attainment, indicating faster initial response times. Furthermore, the system achieves up to a 48% improvement in Total Batch Throughput (TBT) SLO attainment, signifying a considerable increase in the number of requests processed within a given timeframe. These gains were realized through dynamic KV cache management and optimized request scheduling, representing a significant advancement in the efficiency and scalability of LLM serving infrastructure.
OrbitFlow’s performance optimizations are achieved without introducing significant computational overhead from the ILP-based solver. Benchmarks indicate that solver execution time consistently accounts for less than 1% of the total runtime for LLM serving. This minimal overhead is critical for maintaining low latency and high throughput, as the solver operates in the control plane to optimize KV cache placement without directly impacting the data path or request processing speed. The low overhead ensures that OrbitFlow’s dynamic optimization capabilities can be deployed without introducing a noticeable performance regression compared to static allocation strategies.
OrbitFlow is designed for compatibility with prevalent large language model serving frameworks, including DeepSpeed, FlexGen, and Infinigen. This integration is achieved without requiring substantial code modifications to existing deployments. By operating as an extension to these established systems, OrbitFlow leverages their existing functionalities for memory management, tensor parallelism, and pipeline execution. This approach minimizes the barrier to adoption, allowing users to readily incorporate dynamic KV cache optimization into their current LLM infrastructure and benefit from performance improvements without significant engineering effort or system redesign.
The Inevitable Scaling: What Comes Next
Recent advancements in large language model (LLM) serving have been significantly impacted by OrbitFlow, a system engineered to enhance performance and scalability. This innovation allows for the deployment of increasingly complex and parameter-rich models-previously constrained by hardware limitations-and simultaneously supports a substantially larger number of user requests. By overcoming bottlenecks in traditional serving architectures, OrbitFlow unlocks the potential for real-time interactions with LLMs at scale, fostering more responsive and capable AI-driven applications. The ability to handle both model size and user concurrency represents a critical step towards democratizing access to powerful language technologies and enabling a broader range of use cases, from sophisticated chatbots to advanced content generation tools.
Efficient resource management is central to OrbitFlow’s design, directly impacting both operational expenses and environmental sustainability. The system meticulously optimizes memory allocation, minimizing waste and allowing larger language models to operate within existing hardware constraints. Furthermore, intelligent request scheduling prevents resource contention and maximizes throughput, reducing the need for over-provisioning. This dual focus on memory and scheduling not only lowers infrastructure costs associated with running large language models, but also significantly improves energy efficiency by decreasing the overall computational load and hardware demands-a crucial step toward more responsible and scalable AI deployment.
Recent advancements in large language model serving have yielded substantial performance gains, notably demonstrated by OrbitFlow. Evaluations indicate OrbitFlow achieves a remarkable 3.3 times increase in throughput compared to existing state-of-the-art methodologies. This heightened capacity translates directly into the ability to process a significantly larger volume of requests concurrently. Furthermore, the system demonstrably reduces P95 tail-based throughput latency – the time taken to serve 95% of requests – by 38%. This reduction in latency is crucial for applications demanding rapid response times, such as real-time chatbots and interactive AI assistants, ensuring a smoother and more responsive user experience even under heavy load. These improvements represent a significant step towards deploying and scaling increasingly sophisticated LLMs for a wider range of applications.
The core innovations driving OrbitFlow’s performance extend beyond large language models, offering benefits to diverse machine learning applications. Dynamic resource allocation, the system’s ability to intelligently distribute computational resources based on real-time demand, addresses a common bottleneck in many workloads. Similarly, OrbitFlow’s intelligent caching mechanisms – proactively storing frequently accessed data – reduce latency and improve throughput across various model types and sizes. This adaptability suggests that the principles underpinning OrbitFlow can be readily applied to areas such as computer vision, recommendation systems, and time-series analysis, potentially unlocking substantial gains in efficiency and responsiveness for a broader spectrum of machine learning deployments. The resulting improvements in resource utilization and reduced computational costs make these techniques valuable for both cloud-based and edge-device implementations.
The advent of genuinely scalable and responsive large language model (LLM) applications hinges on synergistic combinations of optimization techniques, and OrbitFlow represents a significant step forward in this direction. By integrating with established methods such as Tensor Parallelism – which distributes model computations across multiple devices – and dynamic Batching – which efficiently groups requests to maximize throughput – OrbitFlow unlocks substantial performance gains. This convergence isn’t simply additive; the system intelligently manages resources to ensure these techniques operate in harmony, preventing bottlenecks and maximizing utilization. Consequently, developers are empowered to deploy increasingly complex models capable of handling a dramatically larger volume of concurrent users, fostering a new era of interactive and real-time LLM-powered experiences, from advanced chatbots to sophisticated content creation tools.
The pursuit of elegant solutions in LLM serving invariably encounters the harsh realities of production. OrbitFlow, with its intricate dance of integer linear programming and fine-grained KV cache reconfiguration, embodies this tension. It attempts to tame long-context latency, a beast that consistently outpaces theoretical optimization. One recalls Dijkstra’s observation: “It’s always possible to do things wrong.” The system, while striving for peak efficiency, acknowledges the inherent unpredictability of real-world workloads. The paper’s focus on dynamic scheduling isn’t merely about performance; it’s a tacit admission that static configurations are a fantasy. Every carefully crafted algorithm will eventually meet an input it wasn’t designed for, and OrbitFlow prepares for that inevitability, prolonging the suffering, as it were, rather than pretending it can be avoided.
What’s Next?
OrbitFlow, with its meticulous approach to KV cache choreography, represents a logical escalation in the arms race against long-context latency. It will, predictably, encounter the usual battlefield realities. The elegance of integer linear programming will collide with the messy indeterminacy of production traffic; the perfectly modeled GPU will yield to fragmentation and unexpected contention. Every abstraction dies in production, and this one will likely expire amidst a flood of edge cases and unforeseen input distributions.
The immediate future will likely see a proliferation of similar systems, each attempting to refine the balance between model size, context length, and achievable throughput. However, the fundamental problem remains: we are attempting to force sequential architectures to handle inherently parallel information. The more interesting, though perhaps less tractable, path involves exploring genuinely parallel LLM serving architectures, or a complete re-evaluation of how ‘context’ is represented and processed.
Ultimately, OrbitFlow, and its successors, will become just another layer in the serving stack, a carefully tuned component that buys time until the next architectural limitation is reached. It’s a beautiful death, certainly, but a death nonetheless. The question isn’t whether it will be superseded, but when.
Original article: https://arxiv.org/pdf/2601.10729.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Forza Horizon 6: Find the Ohtani Treasure Chest Location
- NTE Drift Guide (& Best Car Mods for Drifting)
- Diablo 4 Best Loot Filter Codes
- Boruto: Ikemoto Has Already Hinted At Sasuke’s New Eye After Return
- LEGO Batman Legacy of the Dark Knight Batcave Minikits & WayneTech Caches
- USD RUB PREDICTION
- Where to Find Prescription in Where Winds Meet (Raw Leaf Porridge Quest)
- Top 10 Must-Watch Isekai Anime on Crunchyroll Revealed!
- Conduit Crystal Location In Subnautica 2
- GBP CNY PREDICTION
2026-01-20 19:03