Author: Denis Avetisyan
A new co-design framework dramatically improves the performance of small language models on resource-constrained devices.
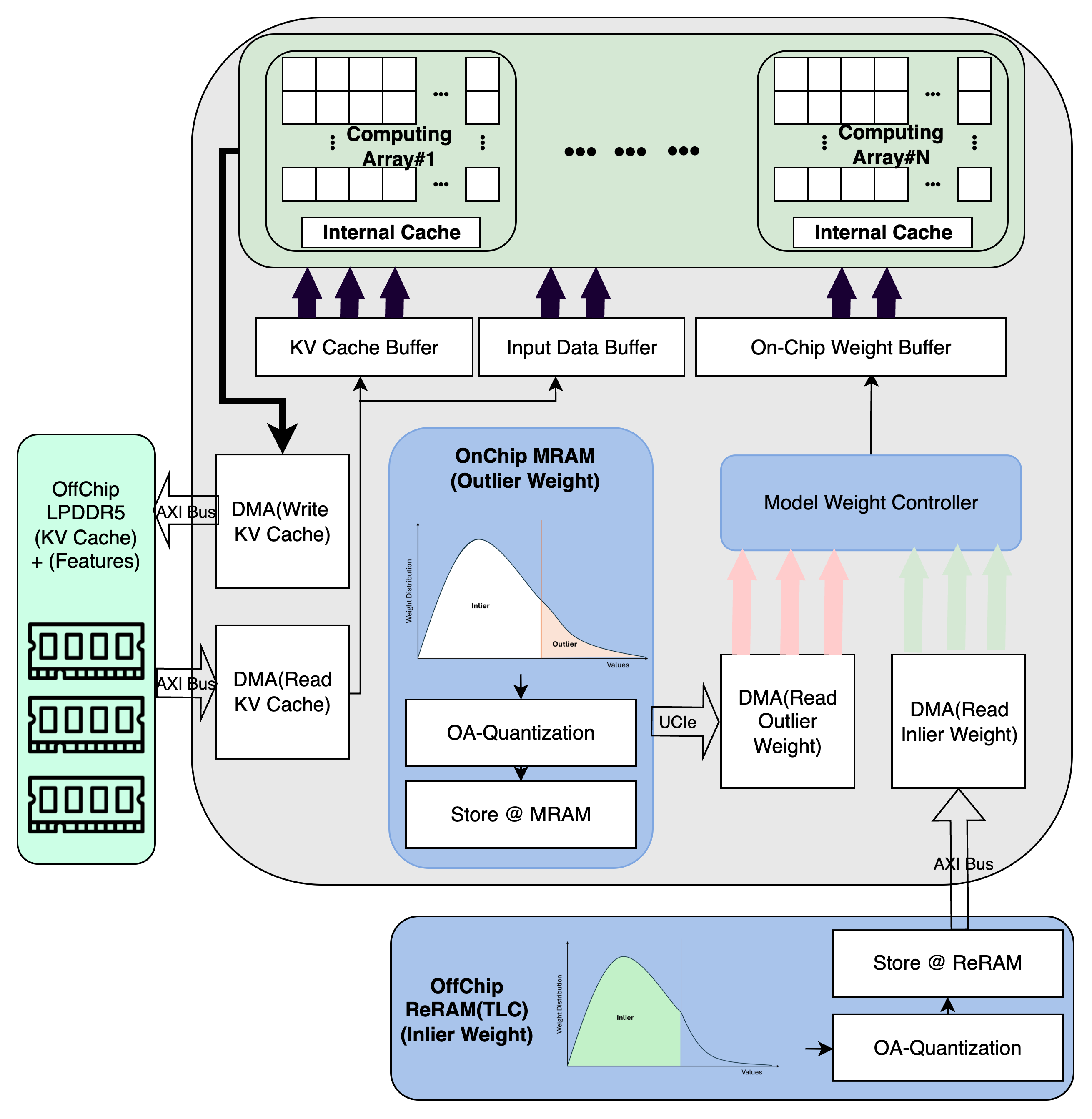
Outlier-aware quantization and the strategic use of emerging non-volatile memories enable efficient edge deployment of language processing.
Deploying increasingly complex small language models on edge devices presents a fundamental tension between performance demands and constrained resources. To address this, we introduce QMC: Efficient SLM Edge Inference via Outlier-Aware Quantization and Emergent Memories Co-Design, a novel co-design framework that strategically leverages heterogeneous non-volatile memory alongside a targeted quantization approach. QMC achieves significant gains in efficiency by preserving critical outlier weights in high-precision memory while quantizing inlier weights, resulting in up to 7.3x memory reduction and 11.7x energy savings. Will this synergistic hardware-algorithm optimization pave the way for truly pervasive, real-time generative AI on the edge?
The Challenge of Scale: Bridging the Gap to Pervasive Intelligence
Large Language Models, such as LLaMA, have demonstrated remarkable capabilities in natural language processing, achieving state-of-the-art results on a variety of benchmarks. However, this performance comes at a cost: these models are exceptionally large, often containing billions of parameters. This substantial size presents a significant hurdle for deployment on edge devices – smartphones, embedded systems, and other resource-constrained platforms. The memory and computational demands of running such models directly impact battery life, latency, and overall device functionality, effectively limiting the accessibility of advanced AI capabilities outside of powerful servers and data centers. Consequently, research is heavily focused on techniques to compress these models without substantially degrading their performance, paving the way for widespread integration of Large Language Models into everyday applications.
Conventional quantization methods, designed to compress large language models for deployment on resource-constrained devices, frequently encounter a critical trade-off between model size and performance. While these techniques reduce the number of bits required to represent a model’s weights and activations – thereby decreasing memory footprint and accelerating inference – aggressive quantization often leads to a substantial drop in accuracy. This degradation stems from the loss of information inherent in reducing precision; finer nuances in the model’s parameters are discarded, impacting its ability to generalize and perform complex tasks effectively. Consequently, many traditionally quantized models prove impractical for real-world applications where maintaining high fidelity is paramount, creating a significant barrier to widespread edge deployment despite the potential for efficiency gains.
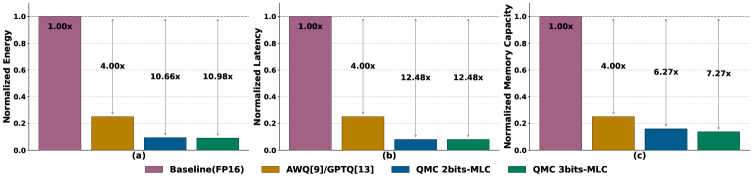
The deployment of large language models on resource-constrained edge devices presents a substantial challenge, demanding innovative strategies to reduce computational footprint without compromising performance. Quantization, a technique for reducing model precision, offers a potential solution, but conventional methods frequently result in unacceptable accuracy degradation. Recent advancements, however, demonstrate the possibility of minimizing precision effectively; specifically, Quantization-aware Model Compression (QMC) achieves up to a 7.27x reduction in memory usage compared to FP16, the standard floating-point format. This substantial compression addresses a critical barrier to wider adoption, enabling the execution of complex models on devices with limited memory and processing power, and opening new avenues for real-time, on-device artificial intelligence applications.
Precision-Focused Quantization: Addressing the Outlier Problem
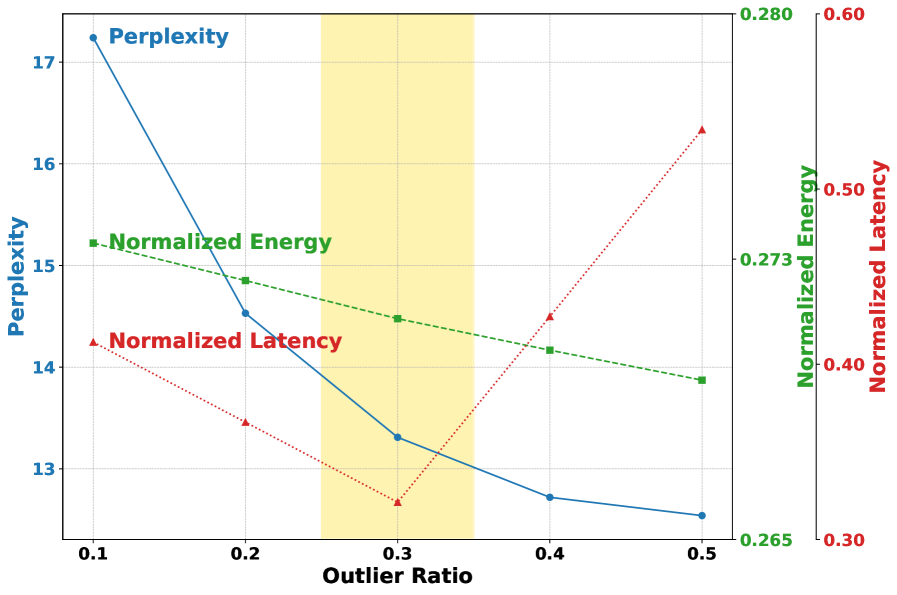
Outlier-Aware Quantization with Memory Co-design (QMC) improves upon standard uniform quantization techniques by specifically addressing the impact of large-magnitude weights, termed outliers, on model accuracy. Uniform quantization assigns the same number of bits to all weights, which can lead to significant quantization error for outliers due to their disproportionate influence on calculations. QMC identifies these critical weights – those with magnitudes exceeding a defined threshold – and preserves them at a higher precision than the majority of inlier weights. This selective preservation minimizes the overall accuracy loss associated with reduced precision, as the most impactful weights retain greater fidelity during the quantization process. The system then co-designs the memory architecture to efficiently store and access these weights with their varied bitwidths.
Quantization-aware Memory Co-design (QMC) employs a weight partitioning strategy that categorizes model weights by magnitude, distinguishing between outlier and inlier values. This separation enables the application of different quantization bit-widths to each group; larger bit-widths are assigned to outlier weights, which have a disproportionate impact on model accuracy, while inlier weights are quantized to lower precision levels. This tailored approach allows for a reduction in memory footprint and computational cost without incurring significant accuracy loss, as the preservation of critical outlier weights mitigates the effects of reduced precision in less sensitive inlier weights.
Quantization, the process of reducing the precision of numerical weights in a neural network, often results in accuracy loss. Outlier-Aware Quantization with Memory Co-design (QMC) mitigates this by recognizing that weights exhibit differing sensitivities; larger magnitude weights, or outliers, typically have a greater impact on model accuracy than smaller, inlier weights. QMC therefore applies a higher precision to these sensitive outliers while quantizing inlier weights to a lower precision. This tailored approach minimizes the overall accuracy degradation caused by quantization. Benchmarking demonstrates that systems utilizing this method achieve up to a 10.98x reduction in energy consumption compared to models retaining full FP16 precision, without significant accuracy loss.
Memory Co-design: Architecting for Efficiency and Precision
Quantized Model Compression (QMC) leverages emerging non-volatile memory technologies, specifically Magnetoresistive Random-Access Memory (MRAM) and Resistive Random-Access Memory (ReRAM), for weight storage. These technologies enable storing weights with varying precision levels; higher-precision storage is allocated to critical weights requiring greater accuracy, while lower-precision storage is used for less sensitive weights. This precision-based allocation is fundamental to QMC’s efficiency gains, allowing for a tailored memory footprint and reduced power consumption without significant accuracy loss. The use of these emerging memories contrasts with traditional DRAM or SRAM-based weight storage commonly found in neural network deployments.
Quantization-aware memory co-design (QMC) strategically allocates weight storage based on sensitivity; critical outlier weights, which disproportionately impact model accuracy, are stored in high-precision Magnetoresistive Random-Access Memory (MRAM). Conversely, less sensitive inlier weights are stored in lower-precision Resistive Random-Access Memory (ReRAM). This tiered approach reduces overall memory footprint by leveraging the density advantages of lower-precision storage for the majority of weights, while preserving accuracy by maintaining high precision for the most impactful values. The resulting heterogeneity directly minimizes power consumption as accessing and operating lower-precision ReRAM requires significantly less energy than high-precision MRAM.
Employing Multi-Level Cells (MLC) within Resistive Random-Access Memory (ReRAM) significantly increases storage density by storing multiple bits of information per memory cell. This technique maximizes the benefits derived from memory co-design strategies, allowing for a more compact representation of neural network weights. Specifically, this co-design approach, utilizing MLC-ReRAM, demonstrates a 12.48x improvement in latency when compared to traditional single-precision floating-point (FP16) implementations, indicating a substantial performance gain in memory access and data retrieval.
Real-World Impact: Deployment and Performance on Edge Devices
The successful deployment of sophisticated language models on resource-constrained edge devices hinges on techniques that minimize computational demands without sacrificing performance. Recent advancements demonstrate that combining Quantization-aware Model Compression (QMC) with efficient quantization formats – specifically INT4 and MXINT4 – allows models like Phi-2 and Hymba to operate effectively on platforms such as the NVIDIA Jetson AGX Orin. This synergistic approach dramatically reduces model size and computational complexity, enabling real-time inference directly on the device. By representing model weights and activations with fewer bits, QMC and these quantization formats unlock the potential for low-power, high-performance natural language processing applications previously limited to cloud-based infrastructure.
The convergence of quantization methods and compact model architectures yields small language models uniquely suited for deployment on resource-constrained edge devices. These models don’t merely function on such platforms – they deliver real-time inference capabilities, a critical requirement for responsive applications. This balance between computational efficiency and maintained accuracy allows for sophisticated natural language processing directly on the device, bypassing the need for cloud connectivity and associated latency. Consequently, applications like always-on voice assistants, localized data processing, and immediate responses in robotics become viable, all while minimizing energy consumption and maximizing user experience.
The development of highly efficient small language models unlocks a diverse array of practical applications, extending artificial intelligence beyond the cloud and into everyday devices. On-device natural language processing becomes feasible, enabling features like real-time translation and voice command recognition without relying on network connectivity. Furthermore, these advancements pave the way for truly low-power AI assistants capable of operating for extended periods on battery power. Quantization-aware model compression, specifically through techniques like QMC, demonstrably improves performance; studies indicate a 1.35x reduction in energy consumption and a 1.9x improvement in latency when compared to existing edge memory solutions, representing a significant step towards sustainable and responsive AI at the point of use.
Towards Robust and Efficient Edge AI: Future Directions
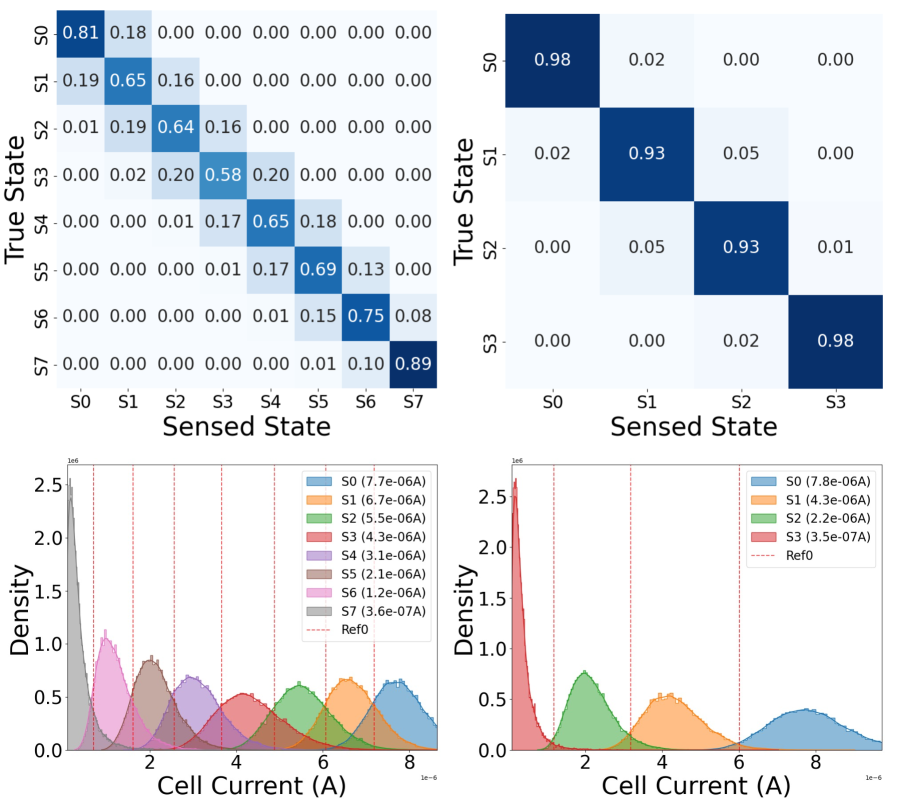
The increasing deployment of artificial intelligence on edge devices relies heavily on emerging non-volatile memories (eMEMs), but these technologies are inherently susceptible to device-level noise – variations in the physical characteristics of individual memory cells. This noise presents a significant challenge to the reliability of quantized neural networks, which compress model parameters to reduce storage and computational demands. Quantization, while efficient, amplifies the impact of these subtle device imperfections, potentially leading to inaccurate predictions and system failures. Researchers are actively investigating noise-aware training methodologies and robust quantization schemes to mitigate these effects, focusing on techniques that either correct for noise during inference or build resilience into the quantized models themselves. Successfully addressing device-level noise is therefore paramount to unlocking the full potential of edge AI and ensuring the dependable operation of intelligent systems in real-world applications.
Post-training quantization, a technique for compressing neural networks, often suffers from accuracy loss when reducing model precision. However, strategic optimization leveraging carefully selected calibration data can significantly mitigate this degradation. This process involves feeding a representative dataset – the calibration data – through the quantized model to fine-tune quantization parameters, such as scaling factors and zero points, for each layer. By analyzing the distribution of activations within this data, the system can minimize the information lost during the reduction of precision, preserving critical features for accurate inference. Recent advancements demonstrate that intelligent calibration data selection, focusing on samples that maximize the variance of activations, can lead to substantial improvements in model accuracy with minimal computational overhead, making quantized models more viable for resource-constrained edge devices.
The pursuit of increasingly capable edge AI is being significantly advanced by a convergence of state space models and quantization methodologies. Recent research highlights the potential of models like Mamba and Hymba – known for their efficient handling of sequential data – when paired with Quantized Memory Computing (QMC). This combination not only unlocks greater computational power at the edge but also dramatically reduces memory footprint; studies demonstrate QMC achieving an impressive 1.82x reduction in memory usage compared to existing emerging memory (eMEM) solutions. This efficiency is critical for deploying complex AI models on resource-constrained devices, paving the way for more responsive and intelligent applications in areas like IoT, robotics, and mobile computing. The synergistic effect suggests that future edge AI systems will increasingly rely on these combined approaches to deliver high performance with minimal energy consumption and hardware requirements.
The pursuit of efficient edge deployment, as detailed in this work, echoes a fundamental tenet of systems design: structure dictates behavior. This paper’s QMC framework, through its co-design of outlier-aware quantization and heterogeneous non-volatile memory, exemplifies how careful architectural choices can drastically improve performance. As Ken Thompson aptly stated, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” This sentiment applies equally to hardware-algorithm co-design; elegance lies not in intricate complexity, but in a streamlined structure that minimizes potential failure points and maximizes efficiency-a principle at the heart of QMC’s approach to small language model inference.
Where Do We Go From Here?
The pursuit of efficient edge deployment for small language models, as exemplified by this work, reveals a recurring truth: every new dependency is the hidden cost of freedom. While outlier-aware quantization and the co-design with emerging non-volatile memories offer compelling gains, they do not erase the fundamental tension between model complexity and resource constraints. Future investigations must move beyond simply minimizing the footprint of a given model; the focus should shift to architectures inherently suited to constrained environments. The very notion of “small” may prove insufficient if the underlying structure remains unnecessarily elaborate.
A crucial, largely unexplored area lies in the dynamic reconfiguration of quantized models. Static quantization, while effective, assumes a fixed computational landscape. However, edge devices operate in inherently variable conditions. Can we envision systems that adapt quantization levels – and even model structure – in real-time, trading off precision for power, or complexity for latency? This demands a deeper understanding of the information-theoretic limits of quantization in the context of natural language, and how those limits interact with the unique characteristics of emerging memory technologies.
Ultimately, the path forward isn’t merely about squeezing more performance from existing paradigms. It’s about recognizing that efficiency isn’t an attribute to be added to a system, but an emergent property of a well-integrated whole. The true challenge lies in designing systems where structure dictates behavior, fostering a symbiotic relationship between algorithm and hardware – a relationship built on simplicity, clarity, and a willingness to question fundamental assumptions.
Original article: https://arxiv.org/pdf/2601.14549.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Forza Horizon 6: Find the Ohtani Treasure Chest Location
- LEGO Batman Legacy of the Dark Knight Batcave Minikits & WayneTech Caches
- Diablo 4 Best Loot Filter Codes
- NTE Drift Guide (& Best Car Mods for Drifting)
- USD RUB PREDICTION
- USD CNY PREDICTION
- Cookie Run Kingdom Timeline of Fate Update Guide
- PS Plus Monthly Games for June 2026 Wish List
- Top 10 Must-Watch Isekai Anime on Crunchyroll Revealed!
- GBP CNY PREDICTION
2026-01-22 15:25