Author: Denis Avetisyan
Researchers have developed a new method for concealing messages within text that is both demonstrably secure and remarkably resistant to detection.
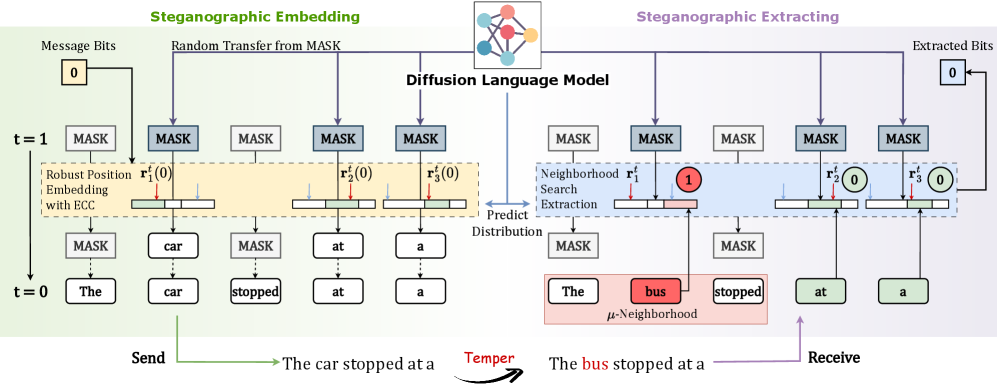
This paper introduces STEAD, a provably secure linguistic steganography technique leveraging diffusion language models, error correction, and a neighborhood search strategy to defend against adversarial attacks.
While existing provably secure linguistic steganography methods leveraging autoregressive language models are vulnerable to error propagation under adversarial tampering, this work introduces ‘STEAD: Robust Provably Secure Linguistic Steganography with Diffusion Language Model’, a novel approach utilizing diffusion language models to enhance robustness. STEAD achieves this through robust text embedding locations combined with error-correcting codes and innovative extraction strategies, including pseudo-random error correction and neighborhood search. Theoretical proofs and experimental results demonstrate STEAD’s resilience to token-level attacks and segmentation ambiguities-but how might these techniques be further extended to withstand more sophisticated, semantic-level manipulations of covert communication?
The Precarious Nature of Hidden Messages
Conventional steganographic techniques, designed to conceal messages within seemingly innocuous text, exhibit a surprising fragility. These methods typically embed information by subtly altering the least significant bits of characters or utilizing synonymous word substitutions; however, even minor modifications to the cover text – a simple typo, reformatting, or even automated grammar correction – can disrupt the hidden message and render it unrecoverable. This vulnerability stems from the reliance on precise data alignment and the expectation of an unaltered carrier; any deviation from the original text throws off the decoding process, effectively destroying the embedded information. Consequently, traditional approaches are ill-suited for real-world applications where text is often subject to editing, transmission errors, or automated processing, highlighting a critical need for more robust steganographic solutions.
The process of tokenization, fundamental to many digital steganographic techniques, introduces a surprising fragility to hidden messages. This stems from the fact that a single stretch of text can be broken down into discrete units – tokens – in multiple valid ways. Consider a sentence like, “The cat sat on the mat.” While seemingly straightforward, variations in how a computer algorithm splits this into tokens – perhaps separating “sat on” as one unit, or treating each word individually – can drastically alter the encoded message. This inherent ambiguity means that even if the cover text remains superficially unchanged, a slightly different tokenization during decoding can yield an entirely different – and incorrect – secret message. Consequently, a robust steganographic system must account for these variations, a challenge that necessitates innovative approaches beyond traditional methods that assume a fixed and consistent tokenization scheme.
Recognizing the susceptibility of current steganographic techniques to even slight textual changes, researchers are actively developing methods focused on resilience and data integrity. These novel approaches move beyond simply concealing messages within cover text and instead prioritize maintaining message recoverability despite manipulation. Strategies include leveraging semantic understanding of language to embed information in a way that resists paraphrasing, utilizing error-correcting codes to rebuild damaged messages, and employing cryptographic techniques to verify message authenticity. The goal is to create steganographic systems capable of withstanding common text alterations – such as editing, reformatting, or even translation – ensuring that hidden communications remain secure and accessible even when the cover text is not perfectly preserved. This pursuit of robustness represents a critical shift in steganography, moving from concealment to reliable communication.
![Tokenization ambiguity, as demonstrated by [qi2024provably], can occur when a steganographic message embedding](https://arxiv.org/html/2601.14778v1/x30.png)
A Diffusion-Based Path to Resilience
STEAD utilizes a Diffusion Language Model (DLM) for message embedding due to the DLM’s inherent ability to generate text through iterative refinement of noise. This generative process allows for subtle modifications to token probabilities without drastically altering the overall text quality or semantic meaning. Furthermore, DLMs support parallel sampling, which significantly accelerates the embedding process by enabling the simultaneous generation of multiple text variations. This parallelization is crucial for practical application, allowing STEAD to efficiently embed messages within textual data at scale, leveraging the DLM’s computational advantages.
Message-Driven Pseudo-Random Number (PRN) Sampling is the foundational mechanism by which STEAD embeds data. This technique operates by modulating the probability distribution of the next token generated by the Diffusion Language Model (DLM). Specifically, a pseudo-random number generator, seeded by the message to be hidden, is used to slightly bias the probabilities associated with each token in the vocabulary. These alterations are designed to be statistically insignificant when considered in isolation, avoiding noticeable deviations in text quality or perplexity, yet cumulatively encode the message within the generated text. The PRN sequence determines the magnitude and direction of these probability adjustments, ensuring the message influences the token selection process without creating easily detectable patterns.
STEAD utilizes the inherent probabilistic nature of Diffusion Language Models (DLMs) to conceal information. DLMs, when generating text, assign probabilities to each possible subsequent token; STEAD modulates these probabilities in a statistically imperceptible manner to encode the message. This is achieved without altering the core semantic content or significantly impacting perplexity, effectively camouflaging the message within the noise of the generative process. The encoded message is therefore not stored as explicit data, but rather as subtle shifts in the statistical distribution of the generated text, making detection challenging without knowledge of the encoding mechanism and the original message.
Reinforcing Integrity Through Error Correction
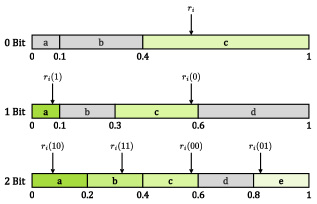
STEAD utilizes Error Correction Coding (ECC) as a fundamental component of its design to mitigate the impact of both unintentional transmission errors and deliberate adversarial attacks. ECC introduces redundancy into the data, allowing the receiver to detect and correct a limited number of errors without requiring retransmission or compromising data integrity. This is achieved by encoding the original data with additional bits, enabling the decoding algorithm to reconstruct the intended message even if some of the transmitted bits are corrupted or altered. The specific ECC implementation within STEAD is selected for its efficiency in correcting bit flips, insertions, and deletions common in noisy communication channels and adversarial scenarios, thereby ensuring reliable data extraction.
STEAD employs a Repetition Code as a foundational error correction mechanism, specifically designed to mitigate the impact of minor text modifications during data transmission or storage. This code operates by replicating each data bit multiple times; for example, a single ‘1’ might be represented as ‘111’. The receiver then utilizes a majority voting scheme to determine the original bit value, effectively overriding single-bit errors. While this approach introduces redundancy, it provides a simple yet effective layer of defense against common transmission errors and small-scale adversarial manipulations, increasing the likelihood of accurate data retrieval even with imperfect data streams.
Neighborhood Search within STEAD functions as an error correction mechanism specifically targeting insertion and deletion errors. This method doesn’t rely on simple redundancy but instead intelligently assesses the contextual probability of different text sequences to identify and rectify discrepancies. Evaluations demonstrate STEAD achieves near 100% accuracy in extracting the original data, even when subjected to moderate levels of tampering involving insertions or deletions. It is important to note this performance is bounded by theoretical limits; extremely high tampering intensities will eventually exceed the capacity of the algorithm to correctly reconstruct the original data.
Towards Provably Robust Communication
STEAD marks a considerable advancement in the field of steganography by striving for provable security – a guarantee that hidden messages remain concealed even under rigorous scrutiny. This novel approach builds upon established principles from autoregressive models, traditionally used in areas like natural language processing, and adapts them to the challenges of concealing data within images. By leveraging the strengths of these models, STEAD aims to move beyond traditional steganographic techniques that often rely on perceptual similarity and are vulnerable to statistical attacks. The system’s design incorporates mathematical proofs to demonstrate the security of the embedding process, offering a level of assurance previously unattainable in steganography and paving the way for reliable, covert communication channels.
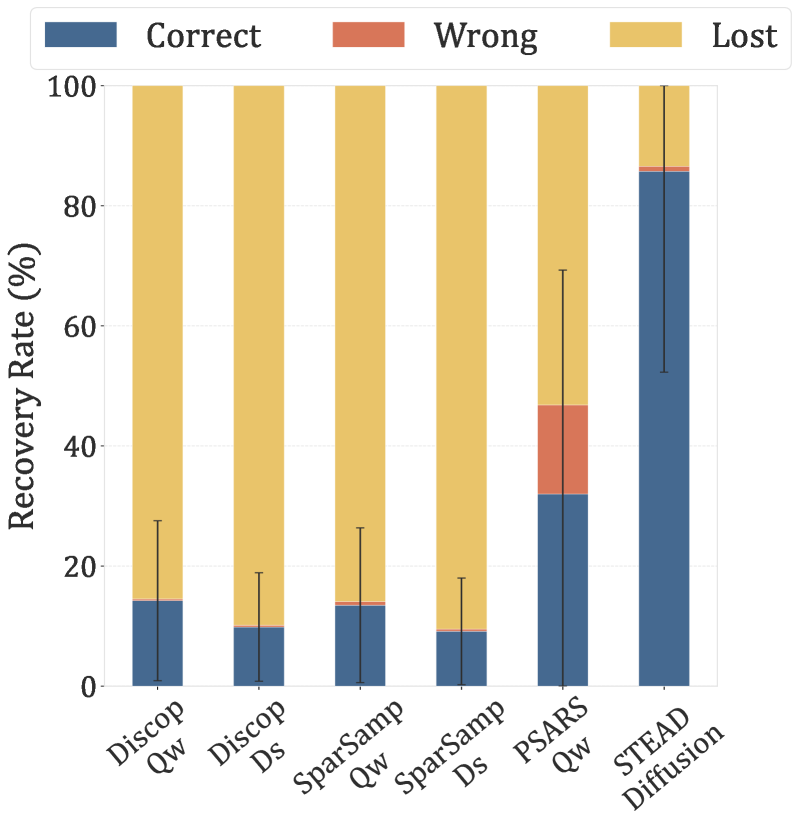
Recent advancements in steganography have yielded a system, STEAD, which achieves a notably improved extraction accuracy of 82.63% when subjected to sophisticated, combined attacks. This performance leap is attributable to a unique integration of three core technologies: diffusion models – known for their ability to generate high-quality, subtly altered data – coupled with both robust and intelligent error correction techniques. Robust error correction provides a foundational layer of defense against common distortions, while the intelligent component dynamically adapts to the specific characteristics of the attack, maximizing the recovery of the hidden message. By synergistically combining these approaches, STEAD not only surpasses existing methods in resilience but also establishes a new benchmark for secure communication and covert data transmission.
The architecture of STEAD establishes a foundational level of resilience in steganographic communication by guaranteeing a minimum of 33 robust positions – designated as Ns – within the carrier image. This threshold isn’t merely a technical specification; it represents a quantifiable baseline for embedding hidden data while maintaining integrity even when subjected to alterations in prompting or across diverse datasets. Consequently, STEAD’s performance directly impacts the feasibility of secure communication channels, providing a tangible improvement in data protection strategies and opening avenues for reliable covert messaging in scenarios ranging from private correspondence to sensitive data transmission, where the undetectability and preservation of hidden information are paramount.
The pursuit of provably secure steganography, as demonstrated by STEAD, often leads engineers down paths of unnecessary complexity. They construct elaborate systems, believing intricacy equates to security. Yet, as Grace Hopper observed, “It’s easier to ask forgiveness than it is to get permission.” This sentiment applies perfectly; STEAD’s innovative use of Diffusion Language Models and error correction coding, while sophisticated, ultimately aims to conceal information simply and reliably. The elegance lies not in the layers of defense, but in the seamless integration – a testament to the power of finding the most direct route to a solution, even if it means bypassing conventional norms. They called it a framework to hide the panic, but STEAD suggests a more deliberate, and mercifully clear, design.
The Road Ahead
The pursuit of perfect concealment invariably reveals the limits of both language and perception. STEAD offers a demonstrable improvement in provable security, yet the very act of formalizing steganography introduces new vulnerabilities. The current framework, reliant on diffusion models and error correction, presumes a relatively static threat model. Future work must confront adaptive adversaries-those who understand the encoding process and attempt to dismantle it at a foundational level.
A pertinent, though uncomfortable, question arises: how much robustness is necessary? Each layer of error correction, each iteration of the diffusion process, incurs a cost – a subtle degradation of linguistic naturalness. The ideal system does not merely resist detection, but dissolves within the noise of ordinary communication. Further investigation should focus on minimizing this trade-off, perhaps by exploring alternative encoding strategies that prioritize plausibility over absolute security.
Ultimately, the enduring challenge lies not in building more complex systems, but in recognizing the inherent fragility of information. The true measure of STEAD, or any similar method, will not be its ability to withstand attack, but its elegant acceptance of eventual compromise. The goal is not immortality, but a fleeting, beautiful illusion of it.
Original article: https://arxiv.org/pdf/2601.14778.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Forza Horizon 6: Find the Ohtani Treasure Chest Location
- NTE Drift Guide (& Best Car Mods for Drifting)
- LEGO Batman Legacy of the Dark Knight Batcave Minikits & WayneTech Caches
- Skyblivion Gets Encouraging Development Update
- Sega’s “Super Game” is Said to Release Next Month, But Nothing is Known About It
- How to Open Locked Door in Tenryu River in Nioh 3 (Dirty Key)
- New Steam Game is Like Pokemon If It Were a Sci-fi Shooter
- LEGO Batman Legacy – All Cauldron North Cluemaster Puzzle Solutions
- GameRant Daily Crossword (February 10, 2026)
- Dead as Disco Best Songs (Clear Beats & Stable BPMs)
2026-01-22 18:14