Author: Denis Avetisyan
A new review reveals that determining if a specific record was used to train a model from tabular data is surprisingly difficult, despite growing concerns about data privacy.
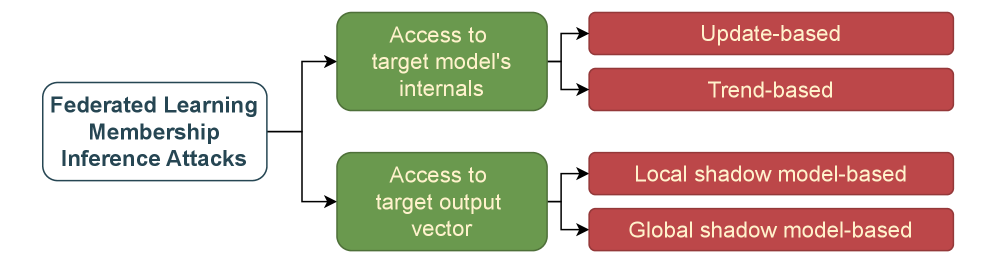
This systematic review analyzes the challenges and limitations of membership inference attacks on tabular data in both centralized and federated learning environments.
Despite the increasing reliance on machine learning models trained on sensitive tabular data, evaluating privacy risks remains a significant challenge. This paper, ‘SoK: Challenges in Tabular Membership Inference Attacks’, systematically investigates the efficacy of membership inference attacks (MIAs) in both centralized and federated learning scenarios, revealing generally limited attack performance on tabular datasets. Notably, our analysis demonstrates a disproportionate vulnerability of single-outs-records with unique characteristics-even with modest attack success rates. Given these findings, how can we develop more robust privacy evaluations and defenses tailored to the specific characteristics of tabular data and mitigate the risks posed by seemingly ineffective, yet revealing, MIAs?
The Evolving Paradox of Data and Intelligence
The proliferation of artificial intelligence across diverse sectors, from streamlining everyday recommendations to enabling complex autonomous systems, is fundamentally reshaping the landscape of data privacy. While these advancements offer undeniable benefits, they simultaneously introduce novel vulnerabilities previously unseen in traditional data handling. Machine learning models, by their very nature, require vast datasets to achieve optimal performance, often incorporating highly sensitive personal information. This reliance creates a paradox: the more powerful and personalized these AI systems become, the greater the risk of exposing individuals to privacy breaches, necessitating a re-evaluation of existing data protection strategies and the development of new, AI-specific safeguards to ensure responsible innovation.
While regulations like the General Data Protection Regulation (GDPR) establish frameworks for data privacy, their efficacy is increasingly challenged by the capabilities of modern machine learning. These regulations typically focus on controlling data collection and usage, but often struggle to address the nuanced ways in which machine learning models can infer sensitive information – even without directly accessing it. A model trained on seemingly anonymized data can still reveal patterns that expose individual identities or characteristics, circumventing traditional protections. This is particularly concerning as machine learning algorithms become more complex and capable of extracting subtle insights from data, rendering existing regulatory approaches less effective at safeguarding personal information in the age of artificial intelligence.
Membership Inference Attacks (MIAs) represent a significant and growing threat to data privacy in the age of machine learning. These attacks don’t seek to extract the content of an individual’s data, but rather to determine if their information was even used in the training of a particular model. An attacker, through carefully crafted queries and analysis of the model’s outputs, can statistically infer whether a specific record contributed to the learning process. This is particularly concerning because even publicly available models can be vulnerable, and successful inference reveals a breach of confidentiality – confirming data participation without revealing the data itself. While seemingly subtle, confirmation of data usage can have serious consequences, potentially exposing individuals to discrimination, identity theft, or other harms, even if the model appears secure against traditional data extraction methods.
While often overshadowed by concerns surrounding images and text, tabular data – structured information like medical records, financial transactions, and census information – is increasingly prevalent in applications powered by machine learning, simultaneously heightening the risk posed by membership inference attacks. Though current attack success rates on tabular datasets are typically modest, this should not be interpreted as a lack of danger; the sheer volume of sensitive tabular data being collected and analyzed, coupled with the potential for even limited information leakage to cause significant harm – such as revealing an individual’s participation in a study or their financial status – makes these attacks particularly relevant. Even a small probability of successful inference can translate into a substantial number of compromised records given the scale of modern datasets, demanding proactive mitigation strategies and a careful assessment of privacy risks beyond simply focusing on high-success-rate attack vectors.
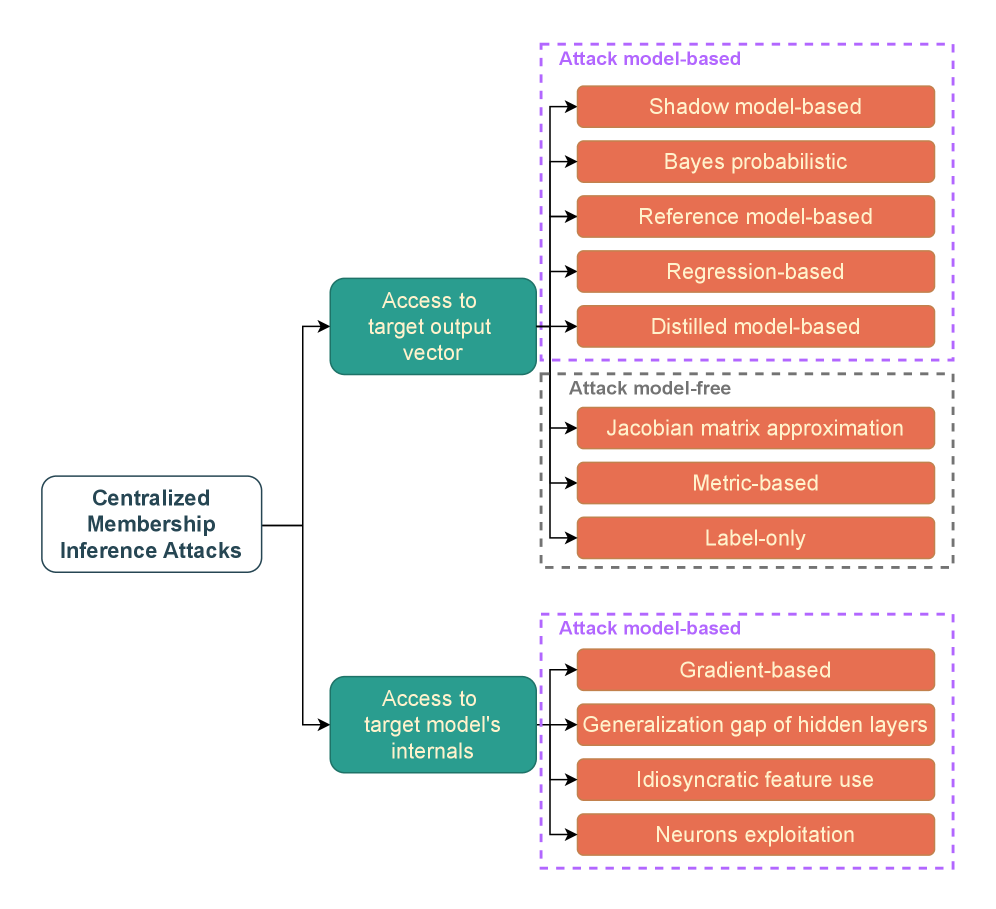
Deconstructing the Mechanics of Data Revelation
Membership inference attacks (MIAs) function by analyzing the observable behavior of a machine learning model to determine whether a specific data point was used during its training phase. These attacks do not require knowledge of the model’s internal parameters or the training dataset itself; instead, they rely on identifying statistical patterns in the model’s outputs – such as prediction probabilities or confidence scores – that differ when querying data the model has seen versus data it has not. The core principle is that models tend to exhibit different responses to training data compared to unseen data, creating a discernible signal that an attacker can exploit to infer membership. This inference is based on the observation that a model will generally be more “confident” or produce more predictable outputs for data it was trained on, even if that data is subsequently modified or presented in a different context.
Membership inference attacks frequently utilize a ‘shadow model’ technique to circumvent the need for direct access to the target model. This involves training a separate model, the shadow model, on a dataset statistically similar to the target model’s training data. By observing the shadow model’s predictions on a given data point and comparing them to the target model’s predictions (obtained via API queries), an attacker can infer whether the data point was likely used in the target model’s training set. The rationale is that if a data point was part of the training data, both models will exhibit similar predictive behavior; discrepancies suggest the point was not used during training. The shadow model serves as a proxy, allowing inference without reverse engineering or direct probing of the target model’s parameters.
Membership inference attacks are viable against both offline and online learning scenarios, though vulnerability is contingent on shadow model training procedures. In offline learning, if the shadow model is trained on a dataset with similar statistical properties to the target model’s training data, it can effectively mimic the target’s behavior and facilitate accurate membership prediction. For online learning, the shadow model’s update frequency and the similarity of its update process to the target model are critical; infrequent or dissimilar updates reduce the shadow model’s fidelity and weaken the attack. Furthermore, the size and representativeness of the shadow model’s training data significantly impact its ability to generalize and accurately reflect the target model’s responses, regardless of whether learning is performed offline or online.
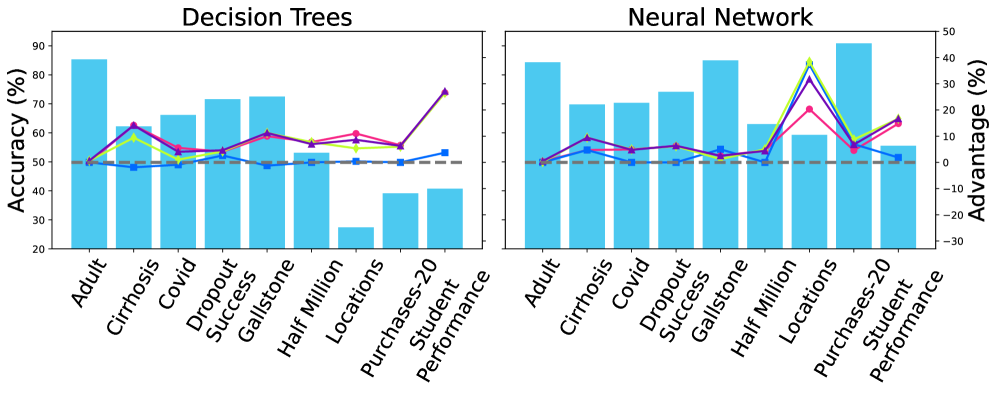
Membership inference attack (MIA) success is correlated with model overfitting and the degree of transferability between the target and shadow models; however, empirical results demonstrate that, across a range of datasets and model architectures, the Area Under the Curve (AUC) as a performance metric typically remains only marginally above 0.5, indicating performance little better than random chance. Overfitting increases the likelihood of the model memorizing specific training examples, creating detectable patterns exploitable by MIAs. Furthermore, a higher degree of transferability – meaning the shadow model closely replicates the target model’s behavior – strengthens the correlation between predictions and allows for more accurate membership inference. Despite these amplifying factors, consistent achievement of statistically significant attack success rates remains challenging, suggesting inherent limitations in current attack methodologies or robust defenses within typical machine learning models.
Strategies for Preserving Data Integrity
Data augmentation techniques artificially expand the size of a training dataset by creating modified versions of existing data points. These modifications can include transformations such as rotations, translations, scaling, or the addition of noise. By increasing the diversity of the training data, the model is exposed to a wider range of variations, reducing the likelihood that an attacker can uniquely identify specific data points used during training. This makes it more difficult to reconstruct sensitive information from the model’s parameters or outputs, as the model has learned from a broader, less identifiable distribution of data. The effectiveness of data augmentation is dependent on the specific transformations applied and their relevance to the underlying data distribution.
Pruning techniques in machine learning reduce model complexity by systematically removing parameters – weights, neurons, or even entire layers – deemed unimportant to the model’s predictive performance. This reduction in model size directly limits the model’s memorization capacity, decreasing its ability to overfit to specific training examples and thus reducing the risk of exposing sensitive information contained within those examples. There are various pruning strategies, including magnitude-based pruning, which removes connections with low weight values, and structured pruning, which removes entire filters or channels. While pruning can improve generalization and reduce computational cost, careful calibration is necessary to avoid significant accuracy loss; excessive pruning can degrade model performance and may not adequately protect against all privacy attacks.
Federated Learning (FL) is a distributed machine learning technique that allows model training on a decentralized network of devices or servers holding local data samples, without exchanging those data samples. This is achieved by training models locally on each device, and then aggregating only model updates – such as gradients or model weights – to create a global model. While FL inherently enhances data privacy by avoiding direct data sharing, successful implementation necessitates addressing several challenges. These include statistical heterogeneity across client datasets (non-IID data), communication constraints due to bandwidth limitations, and the potential for adversarial attacks targeting the aggregation process or individual client models. Furthermore, ensuring the security of model updates during transmission and protecting against malicious clients requires robust cryptographic techniques and secure aggregation protocols.
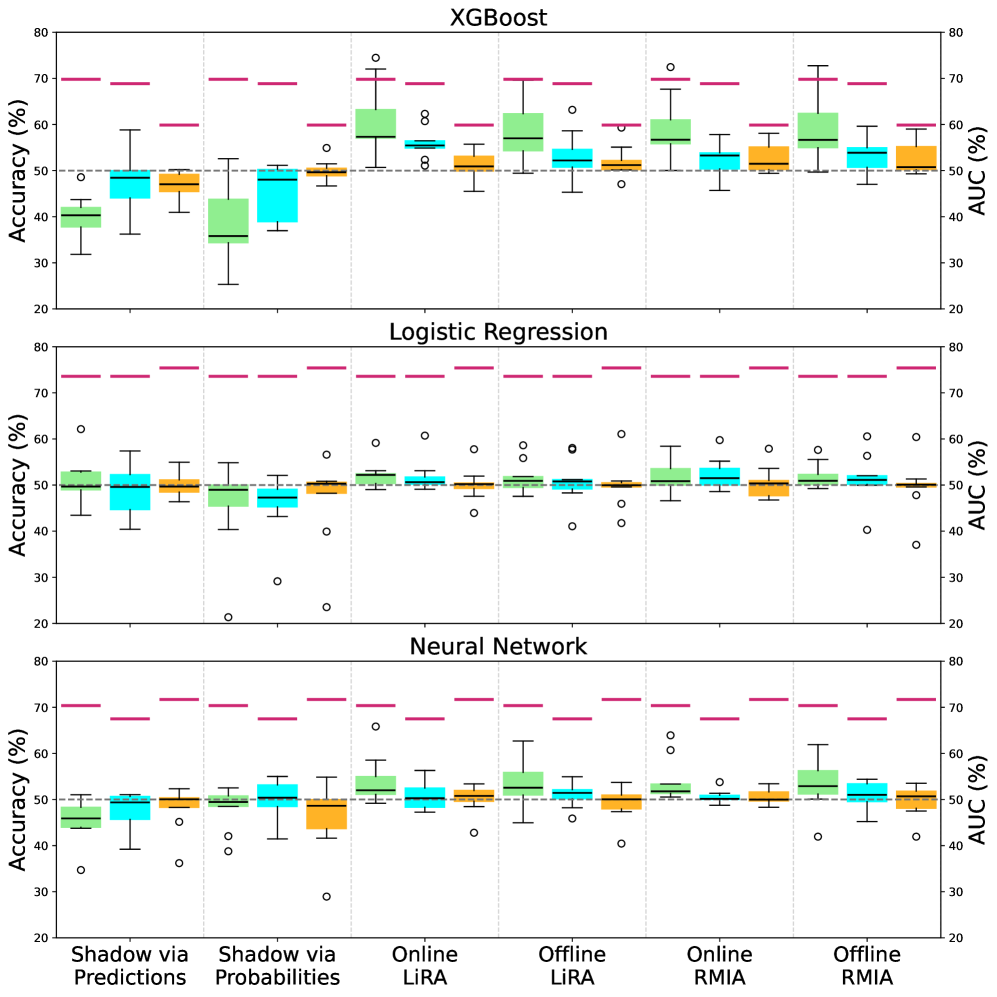
The integration of Federated Learning (FL) with Differential Privacy (DP) enhances data privacy by intentionally adding statistical noise during model training. This noise can be applied to either the model parameters themselves or to the training process, effectively obscuring the contribution of any single data point and limiting the potential for re-identification. However, current implementations of this combined approach demonstrate performance limitations; specifically, True Positive Rate at 1% False Positive Rate (TPR@1%FPR) remains consistently low when evaluated across various datasets, indicating a trade-off between privacy gains and model accuracy.

Navigating the Shifting Landscape of Data Governance
The convergence of the Artificial Intelligence Act and the General Data Protection Regulation is establishing a new benchmark for accountability in the development and deployment of AI systems. These regulations collectively prioritize responsible data handling, demanding that AI applications are built upon principles of transparency, fairness, and privacy by design. This framework moves beyond simply preventing data breaches; it necessitates a comprehensive assessment of potential risks associated with AI, including biases embedded within datasets and the potential for discriminatory outcomes. By mandating data minimization, purpose limitation, and the right to explanation, the AI Act and GDPR are fostering an environment where innovation is balanced with robust safeguards for fundamental rights, ultimately aiming to build public trust in the rapidly evolving field of artificial intelligence.
The persistent evolution of Model Inversion Attacks (MIAs) necessitates a dynamic interplay between defensive strategies and detection methodologies. As adversarial techniques become increasingly sophisticated, static safeguards prove insufficient; instead, researchers are actively developing novel approaches like differential privacy, federated learning, and adversarial training to fortify AI systems against data extraction. Simultaneously, advancements in attack detection focus on identifying anomalous patterns and behaviors indicative of MIA attempts, employing techniques such as anomaly detection and machine learning-based classifiers. This ongoing cycle of attack and defense isn’t merely reactive; it drives innovation in both privacy-enhancing technologies and security protocols, ultimately shaping a more resilient and trustworthy AI ecosystem where data confidentiality isn’t a static guarantee, but a continuously reinforced state.
The vulnerability of uniquely identifiable individuals to Membership Inference Attacks (MIAs) presents a significant privacy challenge, even when overall attack success rates appear low. These ‘single-out’ attacks don’t require widespread data breaches to be effective; instead, they focus on confirming the presence of specific individuals within a dataset. Research indicates that MIAs can successfully capture a surprisingly large proportion of data points relating to these uniquely identifiable people, even if the overall accuracy of the attack across the entire dataset remains modest. This is because the attacker only needs to correctly identify a few key data points to compromise an individual’s privacy, highlighting the need for particularly robust privacy-enhancing technologies and differential privacy mechanisms focused on protecting these vulnerable populations from targeted data extraction.
Effective data governance isn’t simply about compliance; it’s the foundational element for realizing artificial intelligence’s transformative benefits while upholding ethical principles and individual liberties. A static, rules-based approach quickly becomes obsolete in the face of rapidly evolving AI capabilities and increasingly sophisticated data manipulation techniques. Instead, organizations must embrace a dynamic framework-one that anticipates potential risks, proactively adapts to new threats, and prioritizes continuous monitoring and improvement. This necessitates not only technical safeguards, such as differential privacy and federated learning, but also a robust ethical review process, transparent data handling practices, and a commitment to accountability. By prioritizing responsible data stewardship, institutions can build public trust in AI systems, encourage innovation, and ensure that this powerful technology serves humanity’s best interests.
The systematic investigation into membership inference attacks on tabular data reveals a landscape where current privacy evaluations often fall short. The study demonstrates limited attack performance, suggesting a fragile equilibrium between data utility and privacy-a transient state destined for change. This aligns with Donald Davies’ observation that “every architecture lives a life, and we are just witnesses.” The relentless march of improved attack strategies will inevitably erode existing defenses, forcing a continual reassessment of privacy guarantees. Just as systems age and decay, so too will current privacy mechanisms, requiring proactive adaptation rather than reactive patching. The core idea of the paper – the need for more robust privacy evaluations – acknowledges this inherent impermanence.
What’s Next?
The limited efficacy of membership inference attacks against tabular data, as this work demonstrates, is not a testament to inherent security, but rather a consequence of the current attack landscape failing to fully mature. Each delay in achieving consistently strong attacks is, in effect, the price of understanding the subtle ways in which data’s history is-or isn’t-encoded within model parameters. The field appears focused on immediate breaches, when the true challenge lies in anticipating the long-term erosion of privacy as models accumulate knowledge.
Current evaluations, often fixated on worst-case scenarios, neglect the gradual decay of privacy over multiple model updates or deployments. Architecture without history is fragile and ephemeral; a system deemed secure today may be trivially compromised tomorrow if its evolution isn’t considered. Future work must move beyond single-point assessments and embrace a more dynamic view of privacy, accounting for the compounding effects of data usage and model refinement.
Federated learning, presented as a privacy-preserving paradigm, appears largely reliant on aspiration rather than demonstrable robustness. The study reveals a continued vulnerability, hinting that decentralization alone is insufficient defense. The pursuit of truly resilient systems demands a deeper engagement with the fundamental tension between utility and anonymity, recognizing that every feature learned is a potential vector for re-identification.
Original article: https://arxiv.org/pdf/2601.15874.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Shadow Armor Locations in Crimson Desert
- Jujutsu Kaisen Season 3 Episode 12 Release Date
- Dark Marksman Armor Locations in Crimson Desert
- Keeping AI Agents on Track: A New Approach to Reliable Action
- How to Beat Antumbra’s Sword (Sanctum of Absolution) in Crimson Desert
- Top 5 Militaristic Civs in Civilization 7
- Sega Reveals Official Sonic Timeline: From Prehistoric to Modern Era
- Sakuga: The Hidden Art Driving Anime’s Stunning Visual Revolution!
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Best Weapons, Armor, and Accessories to Get Early in Crimson Desert
2026-01-24 19:14