Author: Denis Avetisyan
Researchers have developed a novel method to make image-and-text AI models more resilient to carefully crafted adversarial inputs designed to mislead them.
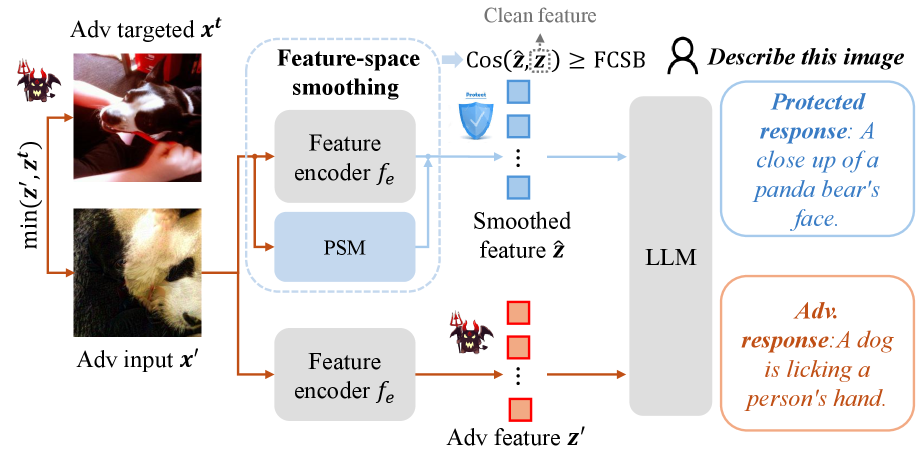
This paper introduces Feature-space Smoothing with a Purifier and Smoothness Mapper (FS-PSM) to certify the robustness of multimodal large language models through improved Gaussian robustness and smoothed feature representations.
Despite the impressive capabilities of multimodal large language models, they remain vulnerable to subtle, adversarial perturbations that can drastically alter their predictions. This paper, ‘Provable Robustness in Multimodal Large Language Models via Feature Space Smoothing’, addresses this critical limitation by introducing a certified defense framework that guarantees robustness in feature representations. Specifically, the authors propose Feature-space Smoothing with a Purifier and Smoothness Mapper (FS-PSM) to demonstrably improve resilience against \ell_2-bounded attacks without requiring model retraining. Can this approach pave the way for deploying more reliable and trustworthy multimodal AI systems in real-world applications?
The Fragility of Perception in Multimodal Systems
The rapid integration of Multimodal Large Language Models (MLLMs) into diverse applications, from image captioning to robotic control, is occurring alongside a growing recognition of their fragility. These models, despite demonstrating impressive capabilities, can be surprisingly susceptible to even minor alterations in their input data – subtle perturbations that would likely be ignored by human perception. A slightly altered image, a barely audible noise in an accompanying audio stream, or a minor change in text formatting can all be enough to cause an MLLM to generate a completely incorrect or misleading response. This vulnerability isn’t merely a theoretical concern; it represents a substantial obstacle to deploying MLLMs in real-world scenarios where reliability and consistency are paramount, particularly in fields like autonomous driving or medical diagnosis where erroneous outputs could have severe consequences.
Current strategies designed to protect multimodal large language models (MLLMs) from adversarial attacks demonstrate limited adaptability when confronted with realistic data corruption. While these defenses may perform well under specific, contrived perturbations used during training, their efficacy sharply declines when exposed to Gaussian noise – a common type of statistical noise that closely resembles the imperfections inherent in real-world sensors like cameras and microphones. This lack of generalization stems from an over-reliance on learning specific attack patterns rather than developing a robust understanding of underlying data features. Consequently, even slight variations in noise distribution – the kind naturally occurring in everyday environments – can render these defenses ineffective, highlighting a critical vulnerability that hinders the deployment of MLLMs in applications where reliability and safety are paramount.
The inherent fragility of multimodal large language models poses a critical impediment to their implementation in domains where reliability is paramount. Applications such as autonomous vehicle navigation, medical diagnosis, and robotic surgery demand unwavering performance, yet even minor, imperceptible alterations to input data – akin to real-world sensor inaccuracies – can induce catastrophic failures in these models. This susceptibility isn’t merely a theoretical concern; it directly impacts the feasibility of deploying MLLMs in safety-critical systems, necessitating robust defenses that transcend simple adversarial training and account for the nuanced imperfections of authentic data streams. Until these vulnerabilities are adequately addressed, the promise of truly intelligent, adaptable systems operating in complex environments remains largely unrealized.
Stabilizing Perception: The Principle of Feature-Space Smoothing
Feature-space smoothing (FS) improves the robustness of Multimodal Large Language Models (MLLMs) by directly addressing the vulnerability of the FeatureEncoder to variations in input data. This is achieved by explicitly reducing the encoder’s sensitivity to noise present in the input features. Rather than altering the model’s weights through techniques like adversarial training, FS modifies the feature representations themselves, effectively creating a more stable and less reactive input to the subsequent layers. This reduction in sensitivity minimizes the impact of small, potentially malicious, perturbations, thereby increasing the model’s resilience to both adversarial attacks and naturally occurring data noise.
Feature-space smoothing (FS) distinguishes itself from adversarial training by operating directly on the intermediate feature representations extracted by the Multimodal Large Language Model (MLLM). This contrasts with adversarial training, which modifies model weights through exposure to adversarial examples. By manipulating the feature space itself – the numerical representation of the input – FS reduces the impact of perturbations without requiring extensive retraining or the generation of adversarial examples. This direct manipulation of features results in a more parameter-efficient defense, requiring fewer computational resources and offering a potentially higher degree of robustness against a wider range of input distortions compared to methods solely reliant on weight adjustments.
Smoothing features within the Multi-Modal Large Language Model (MLLM) feature space directly reduces the impact of both adversarial attacks and Gaussian perturbations on model performance. Adversarial attacks, constructed to intentionally mislead the model, rely on precise feature values; smoothing these values diminishes the effectiveness of these manipulations. Similarly, Gaussian perturbations, representing random noise added to input features, have a lessened effect because the smoothed feature space reduces the magnitude of these changes relative to the overall feature distribution. This technique effectively increases the robustness of the model by decreasing its sensitivity to small, malicious, or naturally occurring variations in input data, resulting in more stable and predictable outputs.
Introducing PSM: A Modular Approach to Robust Multimodal Perception
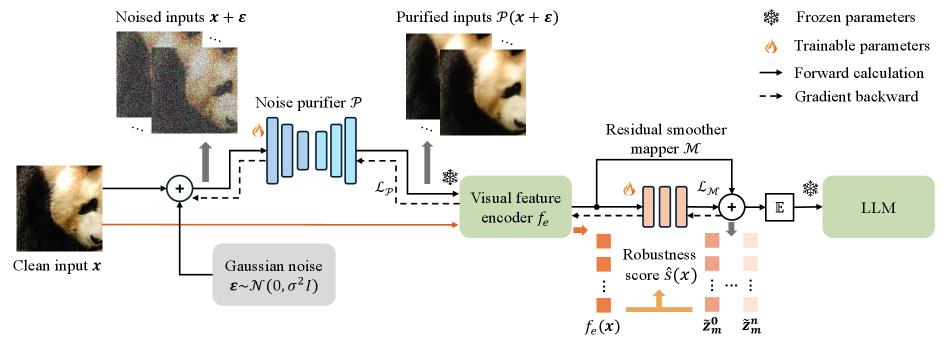
The Purifier and Smoothness Mapper (PSM) represents a modular advancement in multi-modal large language model (MLLM) architecture by combining two distinct functional components. The core principle of PSM is to enhance model resilience and performance through proactive noise reduction and feature refinement. This is achieved by integrating a noise purification stage, utilizing diffusion modeling techniques to mitigate the impact of Gaussian perturbations introduced during data processing, with a subsequent feature smoothing mechanism. The feature smoothing component employs methods such as Layer Normalization and Feature-wise Linear Modulation (FiLM) to standardize and recalibrate feature representations, ultimately promoting improved generalization and robustness in downstream tasks.
The Purifier component within PSM employs a DiffusionModel to mitigate the impact of Gaussian noise introduced during the feature extraction process. This probabilistic model operates by iteratively reversing a diffusion process, effectively learning to remove noise and reconstruct the original, clean feature representation. Specifically, the DiffusionModel is trained to predict and subtract the added Gaussian perturbations, thereby enhancing the quality and reliability of the features passed to subsequent modules. This denoising step is crucial for improving robustness against noisy inputs and promoting more stable performance in Multimodal Large Language Models (MLLMs).
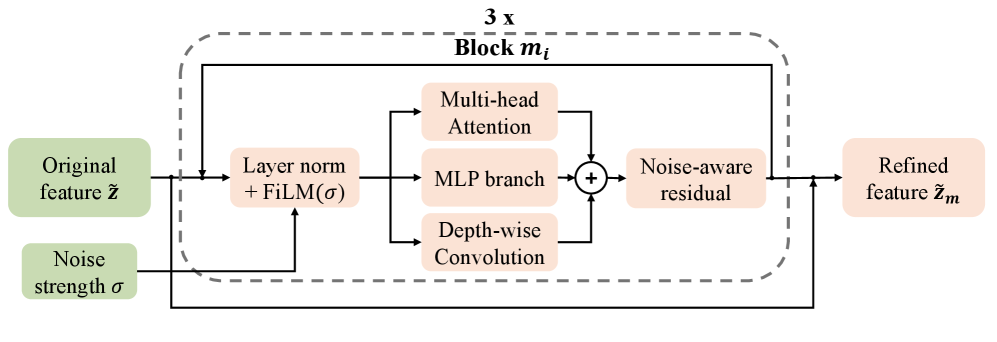
The Smoothness Mapper component employs Layer Normalization (LayerNorm) and Feature-wise Linear Modulation (FiLM) to refine feature representations, thereby improving model robustness and generalization capabilities. LayerNorm normalizes the activations across the feature dimension, reducing internal covariate shift and stabilizing training. FiLM dynamically adjusts the feature activations using learned affine transformations – specifically, scaling and shifting – conditioned on the input. This allows the model to adapt its feature processing based on the specific input, leading to improved performance on unseen data and increased resilience to distributional shifts. The combination of these techniques results in smoother, more consistent feature spaces, facilitating more reliable downstream processing and ultimately enhancing overall model performance.
The Purifier and Smoothness Mapper (PSM) is architected as a plug-and-play module to facilitate seamless integration into existing Multimodal Large Language Model (MLLM) frameworks. This modular design avoids the need for extensive retraining or architectural modifications to the base MLLM. Implementation involves connecting the PSM module between the input data stream and the initial feature extraction layers of the MLLM. Standardized input and output tensors are utilized to ensure compatibility with a wide range of MLLM architectures, and the module’s parameters are independent of the core MLLM weights, enabling flexible deployment and experimentation without impacting the pre-trained model’s performance.
Quantifying and Validating the Gains in Robustness
Evaluations reveal that Projected Smoothing Method (PSM) substantially enhances Gaussian robustness in multimodal large language models. This improvement is rigorously quantified using the Feature Cosine Similarity Bound (FCSB), a metric that assesses the similarity of feature representations under Gaussian noise. Higher FCSB values indicate greater resilience to adversarial perturbations. The study demonstrates that PSM effectively increases this similarity, thereby strengthening the model’s ability to maintain accurate predictions even when input data is subjected to noise designed to mislead it. This quantifiable increase in robustness, as measured by the FCSB, provides a solid foundation for building more reliable and secure multimodal systems.
Evaluations demonstrate a significant advancement in multimodal large language model (MLLM) resilience through the combined application of Patch-based Smoothing Mechanism (PSM) and Frequency-Aware Representation Enhancement (FARE). Specifically, when subjected to a strong adversarial attack – characterized by a perturbation level of \epsilon = 32/255 – the LLaVA-1.5-7B model, fortified by PSM and FARE, achieves an image classification accuracy of 48.4%. This performance represents a substantial improvement over baseline models and highlights the effectiveness of the combined approach in maintaining accurate image understanding even under considerable distortion, offering a promising pathway towards reliable MLLM deployments in challenging real-world scenarios.
Evaluations reveal a particularly strong defense against adversarial attacks when employing a combined strategy of Projected Smoothing Method (PSM) and the TeCoA defense mechanism on the LLaVA-1.5-7B model. Under a strong attack-characterized by a perturbation magnitude of \epsilon = 32/255-this configuration achieved an impressively low Attack Success Rate (ASR) of only 9.6%. This figure represents the lowest ASR observed across all tested defense configurations, signifying a substantial improvement in the model’s resilience against malicious inputs designed to induce incorrect classifications. The demonstrated efficacy suggests a heightened capacity to maintain reliable performance even when subjected to deliberate attempts at manipulation, highlighting the potential of PSM + TeCoA for securing multimodal large language model deployments.
Investigations into the relationship between sampling strategy and certified robustness reveal a clear, albeit nuanced, correlation. Increasing the number of samples – specifically, raising the parameter n_0 from 0 to 16 – resulted in a measurable expansion of the Certified Radius ℛ, growing from approximately 0.595 to 0.728. This increase indicates a heightened capacity to withstand adversarial perturbations within a defined neighborhood of the input data. However, this enhanced robustness is not without cost; a larger sampling number necessitates greater computational resources, presenting a trade-off between the level of certified safety and the efficiency of the model. Consequently, careful calibration of n_0 is crucial to achieving an optimal balance between verifiable security and practical deployment constraints.
The advancements in robustness facilitated by techniques like PSM and TeCoA are not merely incremental improvements in performance, but foundational steps towards \text{CertifiedRobustness}. This emerging paradigm shifts the focus from empirically demonstrating resilience to mathematically guaranteeing safety in Multimodal Large Language Model (MLLM) deployments. By establishing verifiable bounds on model behavior under adversarial conditions, CertifiedRobustness offers a crucial layer of assurance for applications where reliability is paramount-such as autonomous systems, medical diagnosis, and financial modeling. Unlike traditional robustness evaluations, which rely on testing against a limited set of attacks, certification provides a formal, provable guarantee that the model will perform correctly within defined boundaries, regardless of the specific perturbation applied. This capability is poised to unlock the wider adoption of MLLMs in safety-critical domains by addressing concerns about unpredictable or malicious inputs and fostering trust in their decision-making processes.
The pursuit of provable robustness, as detailed in this work, echoes a fundamental principle of systemic design. The framework, Feature-space Smoothing with a Purifier and Smoothness Mapper (FS-PSM), doesn’t merely address adversarial vulnerabilities but actively reshapes the feature space itself. This aligns with Donald Davies’ observation that, “Simplicity is prerequisite for reliability.” By smoothing representations and focusing on Gaussian robustness, the system aims to create inherent stability, acknowledging that a holistic approach – understanding the interplay of features – is crucial. The paper’s focus on smoothing isn’t just a technical fix; it’s a structural one, reinforcing the idea that clarity in design scales far beyond computational power.
Beyond Certified Defenses
The pursuit of provable robustness, as demonstrated by Feature-space Smoothing with a Purifier and Smoothness Mapper, inevitably reveals the limitations inherent in attempting to fortify complex systems through localized interventions. Smoothing feature representations, while effective in enhancing Gaussian robustness, addresses a symptom rather than the underlying fragility. The architecture of multimodal large language models, a labyrinth of interconnected parameters, dictates vulnerability; a singular ‘defense’ is, at best, a temporary reprieve. The system will adapt, and new attack vectors will emerge.
Future work must shift focus from patching vulnerabilities to understanding the fundamental principles governing adversarial susceptibility. A more holistic approach, examining the interplay between model architecture, training data, and the very nature of representation, is crucial. Simply increasing certified radii, while a measurable metric, risks becoming an exercise in diminishing returns – a constant escalation without addressing the root cause.
The true challenge lies not in building impenetrable fortresses, but in designing systems that gracefully degrade under perturbation, that possess an inherent resilience born of simplicity and clarity. It demands a reevaluation of the prevailing paradigm, moving away from the pursuit of perfect accuracy towards an acceptance of controlled imperfection – a principle, perhaps, more aligned with the elegance of natural systems.
Original article: https://arxiv.org/pdf/2601.16200.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Shadow Armor Locations in Crimson Desert
- Jujutsu Kaisen Season 3 Episode 12 Release Date
- Dark Marksman Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Keeping AI Agents on Track: A New Approach to Reliable Action
- How to Beat Antumbra’s Sword (Sanctum of Absolution) in Crimson Desert
- Top 5 Militaristic Civs in Civilization 7
- Sakuga: The Hidden Art Driving Anime’s Stunning Visual Revolution!
- Sega Reveals Official Sonic Timeline: From Prehistoric to Modern Era
- How To Beat Ator Archon of Antumbra In Crimson Desert
2026-01-25 20:19