Author: Denis Avetisyan
Researchers have developed a novel framework that enables privacy-preserving code generation using open-source AI models, shielding sensitive information from cloud observation.

NOIR combines split learning and differential privacy to protect both user prompts and generated code without sacrificing performance.
While large language models boost software development, they introduce intellectual property and data security risks by exposing client prompts and generated code to cloud service providers. To address this, we present ‘NOIR: Privacy-Preserving Generation of Code with Open-Source LLMs’, a novel framework employing split learning and local differential privacy to protect sensitive code generation processes. NOIR achieves this by encoding prompts locally, processing embeddings in the cloud, and decoding the final code client-side, while introducing a randomized tokenizer and indistinguishability mechanisms to defend against reconstruction attacks. Does this approach represent a viable path toward secure and private code generation with open-source LLMs without sacrificing performance?
Decoding the Leak: Intellectual Property in the Age of LLMs
Large language models are revolutionizing software development by automating code generation, dramatically increasing developer productivity and accelerating project timelines. However, this newfound efficiency comes with a substantial risk of intellectual property leakage. As developers increasingly rely on these models – often through cloud-based services – proprietary algorithms and sensitive code snippets are inadvertently exposed during the prompting and training processes. The very mechanism that enables rapid code creation – the LLM’s ability to learn from vast datasets – also means that confidential code can be unintentionally incorporated into the model’s knowledge base, potentially surfacing in outputs for other users. This creates a complex security challenge, demanding innovative strategies to safeguard valuable code assets within these increasingly prevalent generative workflows and mitigate the risk of unauthorized access or replication.
Conventional code security protocols, designed for a world of direct authorship and controlled distribution, struggle to address the unique vulnerabilities introduced by large language model-driven code generation. These systems often operate by predicting and completing code snippets, potentially recreating or closely approximating proprietary algorithms present in training data or user prompts. Standard methods like code obfuscation or access controls become less effective when intellectual property can be unintentionally “leaked” through the model’s output, even without direct code copying. Furthermore, the probabilistic nature of LLMs means that functionally equivalent, yet structurally different, code can be generated, bypassing signature-based detection systems. This necessitates a shift towards more sophisticated security paradigms, including watermarking techniques, differential privacy approaches, and runtime monitoring, to safeguard sensitive code within these evolving generative workflows.
The growing dependence on external Large Language Models (LLMs) significantly amplifies the challenges surrounding code intellectual property protection. Organizations are increasingly leveraging these powerful tools to accelerate development, yet this often involves transmitting proprietary source code and algorithms to third-party servers for processing. This data transfer introduces substantial risks of unauthorized access, replication, or use of sensitive information, as traditional security protocols are ill-equipped to address the unique vulnerabilities of these generative workflows. Consequently, a pressing need exists for innovative, privacy-preserving techniques – such as differential privacy, homomorphic encryption, or federated learning – that allow developers to harness the benefits of LLMs without compromising the confidentiality and integrity of their valuable code assets. Addressing these vulnerabilities is not merely a matter of legal compliance, but crucial for maintaining a competitive edge and fostering continued innovation within the software development landscape.
NOIR: Severing the Connection – A Privacy-Preserving Framework
NOIR leverages Split Learning, a machine learning technique that partitions a Large Language Model (LLM) between a client device and a remote cloud server. This distribution allows for model fine-tuning on the client’s local data without requiring that data to be transmitted to the cloud. Specifically, initial layers of the LLM reside on the client, processing input data and generating intermediate outputs. These outputs, rather than the raw data, are then sent to the cloud for completion by the remaining layers of the model. This approach minimizes data exposure, as sensitive information remains on the client device throughout the majority of the processing pipeline, and only transformed data is communicated externally.
NOIR’s privacy preservation relies on local differential privacy (LDP) applied to token embeddings prior to transmission from the client device. Specifically, the INDVocab technique is implemented, which randomizes these embeddings through the addition of carefully calibrated noise. This noise is generated locally, meaning the raw data never leaves the client. The magnitude of the added noise is determined by a privacy parameter ε, controlling the trade-off between privacy and utility; lower values of ε provide stronger privacy guarantees but potentially reduce model accuracy. By randomizing the embeddings at the point of data origin, NOIR ensures that even if the transmitted data is intercepted, it is extremely difficult to reconstruct the original sensitive input.
By partitioning the Large Language Model (LLM) and randomizing token embeddings with techniques like INDVocab, NOIR minimizes the potential for sensitive data reconstruction. This approach limits the information available to any single entity, whether the client or the cloud server. Specifically, the cloud only receives randomized embeddings, preventing direct access to original input tokens. Concurrently, the client retains control over a portion of the LLM and never transmits the complete, unencrypted data. This distributed architecture and embedding randomization effectively reduce the attack surface by mitigating risks associated with both data-in-transit and data-at-rest vulnerabilities, making it substantially more difficult to reverse-engineer private information from the processed data.
Under the Hood: Protecting Embeddings and Optimizing Fine-Tuning
INDVocab employs Adaptive Randomized Response (ARR) as a defense against Reconstruction Attacks targeting token embeddings. ARR introduces calibrated noise directly into the embedding vectors, effectively perturbing the data while maintaining utility for downstream tasks. The level of noise is adaptively adjusted based on the sensitivity of each embedding dimension, meaning dimensions containing more information crucial for reconstruction receive less noise than those with lower information content. This calibration is key to balancing privacy protection and model performance; excessive noise would degrade accuracy, while insufficient noise would leave the system vulnerable to attacks. By strategically adding noise, INDVocab disrupts the ability of adversaries to accurately reverse-engineer the original training data from the embeddings themselves.
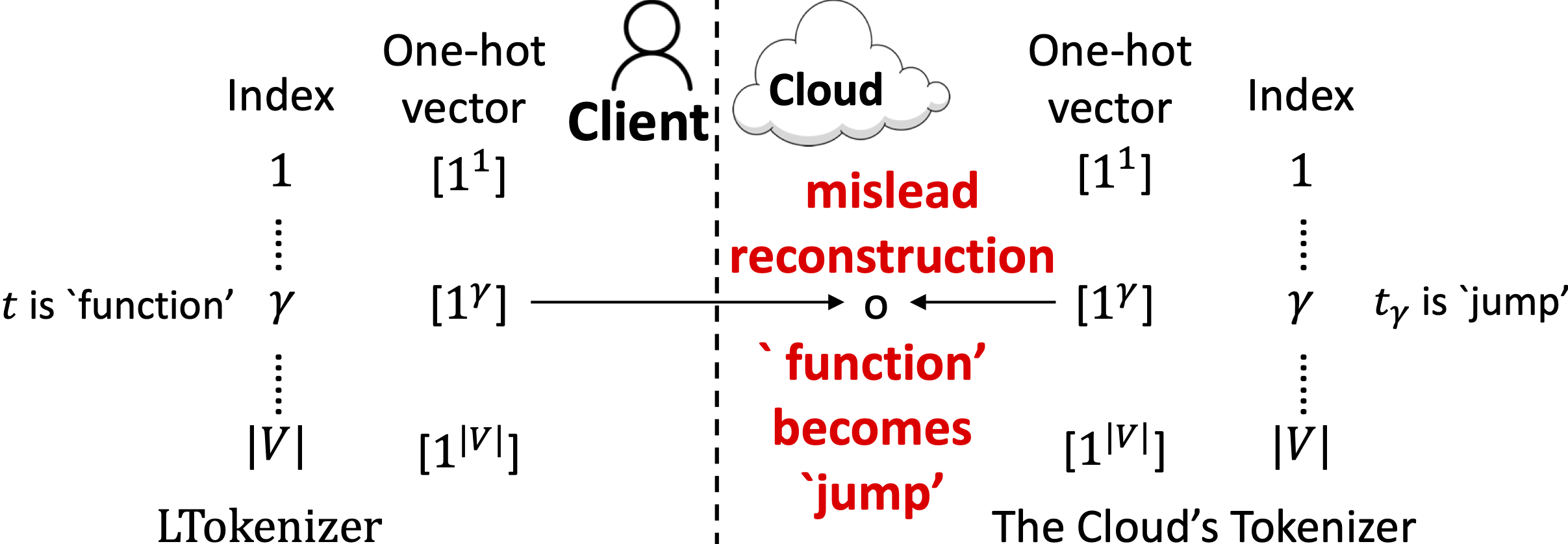
NOIR employs a Locally-aware Tokenizer (LTokenizer) to enhance data privacy during embedding processes. This tokenizer operates by randomly assigning tokens and their corresponding embeddings directly on the client-side, independent of a centralized vocabulary. By performing this randomization locally, the LTokenizer breaks the direct link between the original training data and the resulting embeddings. This obfuscation prevents attackers from reconstructing sensitive training information through analysis of the embedding space, as the token-embedding mappings are unique to each local instance and do not reflect the global training dataset distribution.
STuning employs Low-Rank Adaptation (LoRA) to enable efficient fine-tuning of large language models on local machines. LoRA minimizes the number of trainable parameters by introducing low-rank matrices to the model’s weight updates, thereby reducing both computational demands and the volume of data transmitted to cloud-based services. Benchmarks utilizing the CodeLlama-7B model demonstrate that this approach achieves up to a 71.9% reduction in fine-tuning costs compared to traditional full parameter fine-tuning, while maintaining comparable performance. This parameter-efficient technique allows for customization of models without requiring substantial cloud resources or data transfer.
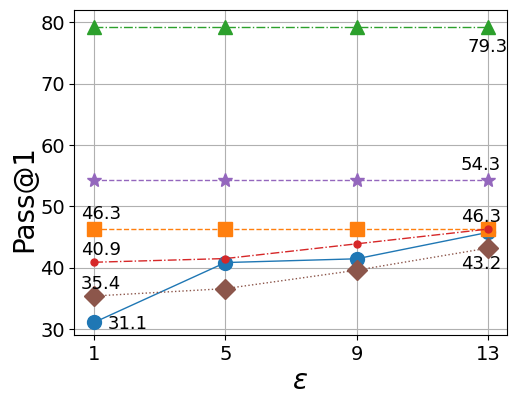
Performance Validated: A New Benchmark in Privacy-Preserving Code Generation
NOIR demonstrates a compelling balance between functionality and data security in code generation. Evaluations using the CodeLlama-7B model reveal that NOIR achieves an impressive Pass@1 score of up to 83.6%, indicating a high degree of code correctness – all while preserving strong privacy. This performance is maintained with only a marginal decrease compared to standard code generation methods, signifying that security does not come at a substantial cost to usability. The system’s architecture effectively safeguards sensitive information during the code creation process, establishing a robust solution for developers handling proprietary or confidential projects without compromising the quality of the generated code.
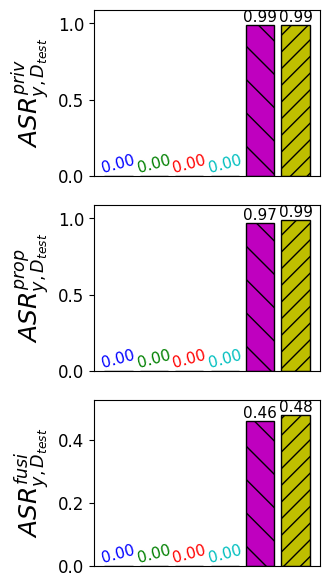
NOIR addresses a critical vulnerability in code generation models: the potential leakage of sensitive intellectual property embedded within training data. Traditional models inherently memorize aspects of their training set, creating a risk that proprietary code snippets or algorithms could be unintentionally reproduced. NOIR circumvents this by fundamentally separating the training data from the model itself; rather than directly encoding knowledge within the model’s parameters, it accesses data externally during inference. This decoupling ensures that even if the model were compromised, confidential information remains inaccessible, offering a robust security layer for applications dealing with sensitive or proprietary code generation tasks. The system thereby provides a pathway to leverage powerful generative AI without exposing valuable intellectual assets to potential breaches or unauthorized access.
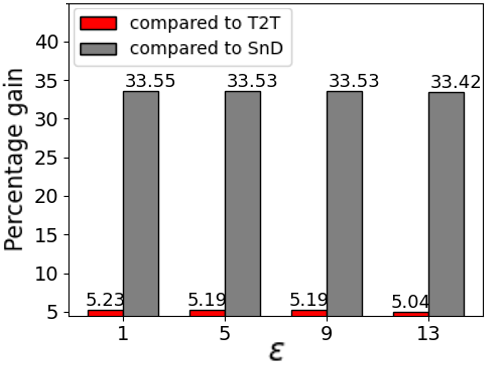
Recent evaluations demonstrate that NOIR establishes a new benchmark in privacy-preserving code generation, substantially exceeding the performance of current methods when defending against reconstruction attacks – attempts to extract sensitive training data from the model. This heightened security doesn’t come at a performance cost; instead, NOIR achieves a remarkable reduction in client-side computational demands, lowering inference and fine-tuning expenses by up to a factor of ten. Further contributing to cost efficiency, the system’s architecture – specifically, the strategic reduction of attention blocks – delivers a 15.6% decrease in cloud-based prompting and hosting expenditures, making secure and efficient code generation a practical reality for a wider range of applications.
The pursuit of secure code generation, as detailed in this framework, echoes a sentiment articulated by Grace Hopper: “It’s easier to ask forgiveness than it is to get permission.” NOIR’s approach to differential privacy and split learning isn’t about rigidly adhering to established security protocols, but about proactively testing the boundaries of what’s possible. By intentionally introducing noise and fragmenting the learning process, the framework challenges conventional assumptions about data exposure, recognizing that true security often arises from a willingness to explore potential vulnerabilities – a controlled demolition of the status quo, if you will. The reconstruction attacks mitigated by NOIR demonstrate that understanding system limitations necessitates actively probing those limits.
What Breaks Down Next?
The framework presented here, NOIR, establishes a functional barrier against observation-a neat trick. But the question isn’t whether the system can obscure, but what happens when someone actively tries to dismantle that obscurity. Reconstruction attacks, currently mitigated, will inevitably evolve. The immediate challenge isn’t simply stronger noise addition or more complex splitting; it’s anticipating the attacker’s understanding of the LLM’s tokenization process itself. Can an adversary leverage the inherent structure of code – the expectation of certain keywords, patterns, or even stylistic choices – to bypass differential privacy? The current work implicitly assumes a degree of randomness in code generation that may not hold under scrutiny.
Furthermore, the performance trade-offs, while acceptable now, represent a moving target. As LLMs grow in parameter count and complexity, the computational burden of split learning and differential privacy will increase exponentially. The true test won’t be maintaining current performance, but ensuring that privacy doesn’t become a prohibitive cost for genuinely useful code generation. The emphasis must shift from simply adding privacy to designing LLMs with inherent privacy properties – a fundamental restructuring of the architecture itself.
Ultimately, NOIR highlights a core tension: security as an afterthought is always vulnerable. The next iteration isn’t about refining the defenses, but questioning the fundamental premise. If the goal is truly private code generation, the real innovation will lie in LLMs that never need to reveal their internal state, even to themselves.
Original article: https://arxiv.org/pdf/2601.16354.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Forza Horizon 6: Find the Ohtani Treasure Chest Location
- NTE Drift Guide (& Best Car Mods for Drifting)
- LEGO Batman Legacy of the Dark Knight Batcave Minikits & WayneTech Caches
- New Steam Game is Like Pokemon If It Were a Sci-fi Shooter
- LEGO Batman Legacy – All Cauldron North Cluemaster Puzzle Solutions
- Skyblivion Gets Encouraging Development Update
- How to Open Locked Door in Tenryu River in Nioh 3 (Dirty Key)
- Sega’s “Super Game” is Said to Release Next Month, But Nothing is Known About It
- Dead as Disco Best Songs (Clear Beats & Stable BPMs)
- GameRant Daily Crossword (February 10, 2026)
2026-01-26 21:39