Author: Denis Avetisyan
A new framework tackles the challenge of information retrieval when search terms are vague, incomplete, or don’t quite capture what users intend.

QUARK leverages query-anchored aggregation and recovery hypotheses to improve retrieval robustness under non-faithful query conditions.
Real-world information retrieval systems often struggle when user queries are ambiguous, incomplete, or simply don’t accurately reflect their underlying information need. To address this challenge, we introduce ‘QUARK: Robust Retrieval under Non-Faithful Queries via Query-Anchored Aggregation’, a training-free framework that enhances retrieval performance by explicitly modeling query uncertainty through the generation of plausible “recovery hypotheses.” QUARK robustly aggregates signals from these hypotheses, anchoring them to the original query to prevent semantic drift and improve both recall and ranking quality. Does this approach of principled aggregation, grounded in the original query, represent a key step towards more resilient and accurate information access?
The Fundamental Disconnect: Queries and Intent
Conventional information retrieval systems frequently encounter difficulties when a user’s expressed query fails to fully capture their actual information need, often resulting in a cascade of irrelevant search results. This disconnect arises because the textual query acts as a proxy for a more complex, nuanced intent; the system interprets the literal words rather than the underlying concept the user seeks. Consequently, even a well-engineered system can return documents that match the query’s keywords but miss the mark in terms of fulfilling the user’s genuine objective. This mismatch isn’t simply a matter of inconvenience; it represents a fundamental challenge in bridging the gap between how humans formulate requests and how machines process them, demanding increasingly sophisticated approaches to understand and interpret user intent beyond the surface level of the query itself.
The difficulty in retrieving relevant information often begins not with the data itself, but with the initial query presented by the user. Human language is inherently ambiguous; a single phrase can carry multiple interpretations, and users don’t always precisely translate their underlying information need into search terms. This imprecision is then compounded by the ‘Recall Process’ – the system’s attempt to identify potentially relevant documents – which inevitably introduces ‘Recall Noise’. This noise consists of documents that superficially match the query but don’t truly address the user’s intent, effectively diluting the signal of genuinely relevant results and creating a fundamental challenge for information retrieval systems.
A fundamental challenge in information retrieval lies in the imperfect translation of a user’s need into a query, and the subsequent distortion that occurs during the search process. Users often struggle to precisely articulate their information need, leading to queries that are ambiguous or incomplete; this initial imprecision sets the stage for further divergence. The ‘Recall Process’ itself introduces what is known as ‘Recall Noise’ – extraneous or irrelevant information that gets pulled into the search results alongside potentially useful content. This noise effectively obscures the signal of the user’s true intent, causing a drift between what was asked for and what is returned. Consequently, retrieval systems may present results that, while technically matching the query terms, fail to satisfy the underlying information need, highlighting the necessity for systems capable of understanding intent beyond keyword matching.
Semantic drift represents a fundamental challenge in information retrieval, describing the phenomenon where initial user intent, as expressed in a query, gradually diverges from the meaning of the returned results. This isn’t a simple case of irrelevance; rather, the retrieved documents subtly shift the focus, leading the user down unintended paths and potentially missing truly relevant information. The process begins with an imperfect query and is amplified by the retrieval system itself, which, while aiming to be comprehensive, can introduce documents that are tangentially related but ultimately distort the original information need. Consequently, even a seemingly accurate initial search can quickly devolve into a cascade of mismatched results, necessitating the development of more sophisticated retrieval methods capable of preserving and prioritizing the user’s core intent throughout the search process.
Reconstructing Intent: Recovery Hypotheses
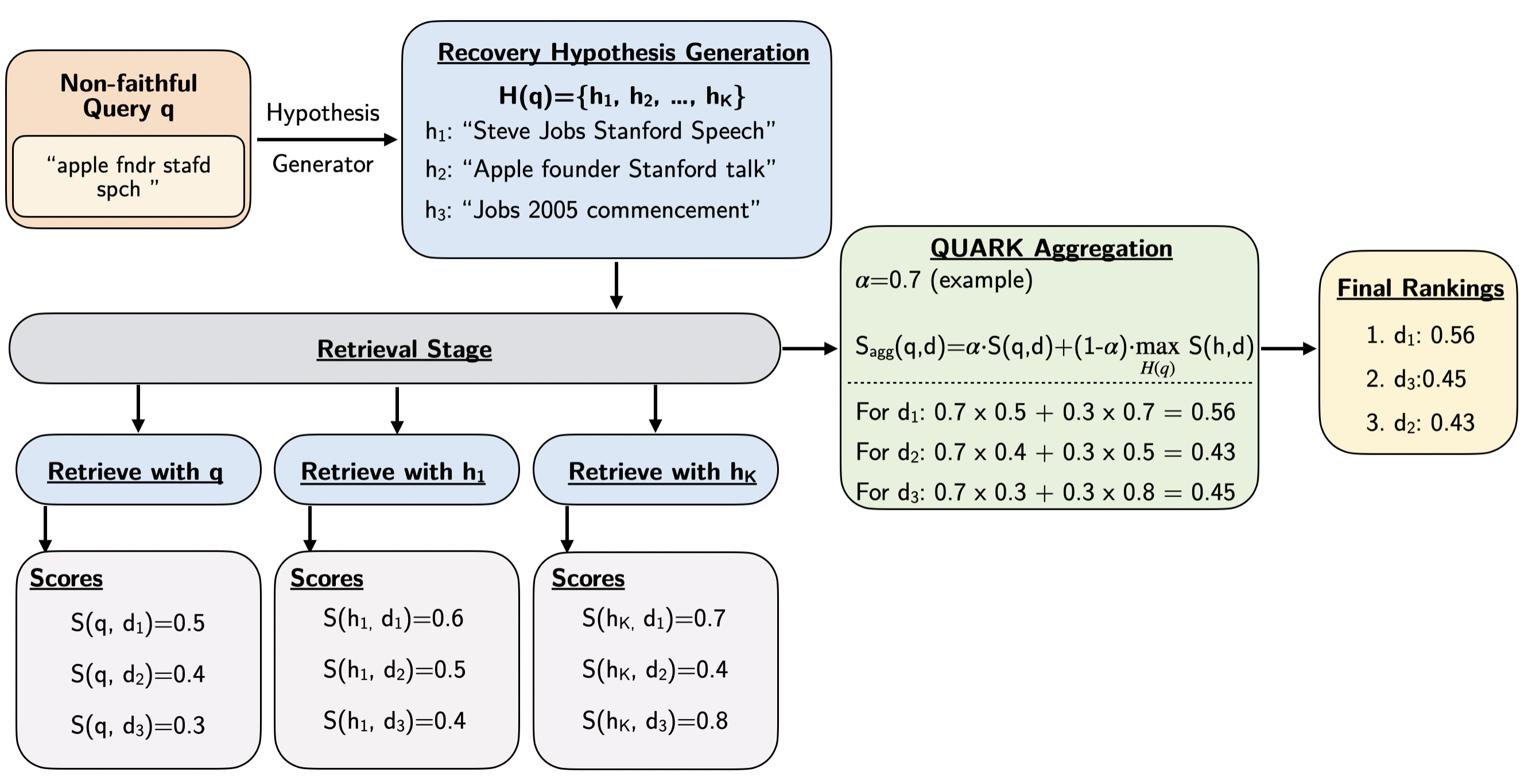
The proposed framework addresses instances of non-faithful queries – those where the initial query does not accurately reflect the user’s underlying information need – by generating ‘Recovery Hypotheses’. These hypotheses are reformulated expressions of the original query, created to explore alternative interpretations and potentially correct misinterpretations introduced during the initial query formulation. The generation of these hypotheses serves as a core mechanism for disambiguation, allowing the system to consider multiple possible user intents beyond the literal wording of the input query. This approach proactively mitigates issues arising from ambiguous phrasing, spelling errors, or incomplete information within the original query, ultimately improving the accuracy of information retrieval.
Recovery hypotheses function as reinterpretations of a user’s initial query, specifically designed to address instances where the original query may not accurately reflect the user’s underlying information need. These hypotheses are generated with the understanding that queries can be distorted through ambiguity, imprecise language, or incomplete information. By systematically exploring plausible alternative expressions, the framework aims to identify the ‘Latent User Intent’ – the actual information the user is seeking – even when it isn’t directly stated in the original query. This process acknowledges that a single query may have multiple valid interpretations and attempts to capture a broader range of potential meanings.
Recovery hypotheses are generated through the utilization of Large Language Models (LLMs) employing a prompt-based approach. These models, pre-trained on extensive text corpora, can paraphrase and re-articulate the initial query to produce variations reflecting potential user intent. The diversity of generated hypotheses is controlled through parameters such as temperature and top-p sampling, which influence the randomness and breadth of the LLM’s output. Relevance is maintained by conditioning the LLM on the original query and, optionally, any available contextual information, ensuring generated hypotheses remain within the scope of the user’s information need. The automated nature of this process allows for the scalable generation of multiple recovery hypotheses, overcoming the limitations of manual approaches.
The consideration of multiple recovery hypotheses allows for a more nuanced understanding of user intent than single-interpretation methods. By generating a set of plausible reformulations of the original query, the system avoids reliance on potentially inaccurate initial parsing. This expanded representation acknowledges ambiguity and facilitates a broader search for relevant information, increasing the likelihood of satisfying the user’s underlying information need, even if the original query was poorly formulated or contained errors. The resulting hypothesis set functions as a probabilistic model of intent, where each hypothesis represents a possible interpretation with associated relevance scores.
QUARK: Anchoring Retrieval Through Query-Focused Aggregation
QUARK utilizes a process termed ‘Query-Anchored Aggregation’ to consolidate retrieval evidence generated from various recovery hypotheses. This technique differs from standard aggregation methods by explicitly weighting each hypothesis’s contribution based on its relevance to the original user query. Specifically, QUARK calculates a similarity score between the query and the reformulated search derived from each hypothesis; this score then serves as a weighting factor during the aggregation phase. The resulting aggregated signal prioritizes hypotheses that remain closely aligned with the initial query intent, ensuring the final retrieval results are grounded in the user’s original information need and minimizing the impact of potentially divergent or irrelevant hypotheses.
QUARK distinguishes itself from unanchored aggregation methods by maintaining a strong connection to the original user query during the retrieval process. Unanchored aggregation can potentially dilute the query’s intent as it combines signals from multiple recovery hypotheses without explicit prioritization. QUARK, however, incorporates mechanisms to ensure the final retrieval results are consistently aligned with the initial query expression. This is achieved by weighting or filtering retrieval signals based on their relevance to the original query, preventing the system from drifting towards semantically related but ultimately unintended information. This prioritization is a core component of QUARK’s design, contributing to improved performance and relevance of retrieved documents.
Query-Anchored Aggregation, as implemented in QUARK, combines information from multiple retrieval hypotheses by weighting each hypothesis’ contribution based on its relevance to the original query. This method avoids semantic drift by consistently referencing the initial query as a central anchor point during the aggregation process. Specifically, hypotheses that align strongly with the query’s intent receive greater weight, while those that diverge are comparatively downweighted. This ensures that the final aggregated retrieval result remains closely tied to the user’s original information need, even when incorporating diverse perspectives from multiple hypotheses.
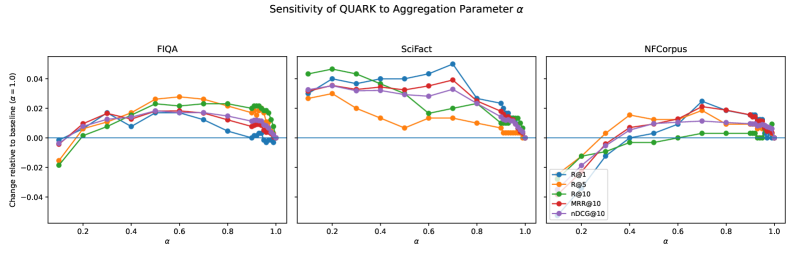
Evaluations of QUARK consistently show improvements in information retrieval ranking metrics. Specifically, Mean Reciprocal Rank at 10 (MRR@10), Normalized Discounted Cumulative Gain at 10 (nDCG@10), and Recall at 10 (Recall@10) were all demonstrably improved across the SciFact, NFCorpus, and FiQA datasets. These gains were achieved utilizing multiple retrieval models – BM25, Dense-1, and Dense-2 – without any requirement for fine-tuning the underlying retriever components, indicating the framework’s adaptability and efficiency.
Towards Robust and Reliable Information Access
The advent of QUARK marks a considerable advancement in the field of robust retrieval, directly tackling the widespread issue of non-faithful queries – those that superficially resemble relevant information requests but lack genuine semantic alignment. Traditional information retrieval systems often struggle with such queries, returning results that, while containing keywords, fail to address the user’s underlying intent. QUARK distinguishes itself by employing a novel framework designed to discern true information needs from misleading query formulations, thereby mitigating the impact of lexical ambiguity and noise. This capability is achieved through a multifaceted approach that prioritizes semantic understanding and contextual relevance, enabling the system to deliver more accurate and trustworthy results, even when faced with poorly constructed or intentionally deceptive queries. Consequently, QUARK represents not merely an incremental improvement, but a fundamental shift toward more reliable and user-centric information access.
The pursuit of seamless information access hinges on effective ad-hoc retrieval – the ability to swiftly deliver relevant results to on-demand queries. Current systems often struggle with the nuances of natural language, leading to frustratingly inaccurate or incomplete responses. This framework directly addresses this challenge by bolstering retrieval performance in these critical scenarios, where users expect immediate and precise answers. By prioritizing accuracy and speed, it promises a markedly improved user experience, fostering greater confidence in information systems and unlocking new avenues for knowledge discovery – particularly in applications like search engines, question answering, and digital assistants where time and relevance are paramount.
The advent of QUARK signifies a leap forward in the capacity to navigate the complexities of real-world information seeking. Traditional retrieval systems often struggle with queries that are poorly worded, contain irrelevant terms, or express ambiguous intent; these ‘noisy’ queries yield unsatisfactory results, hindering effective knowledge discovery. QUARK directly tackles this challenge by employing a novel framework designed to discern the underlying information need even when expressed imperfectly. This improved ability to interpret user intent unlocks access to previously hidden knowledge, facilitates more nuanced searches, and ultimately empowers users to explore information landscapes with greater confidence and precision. By minimizing the impact of query ambiguity, QUARK not only enhances the efficiency of information retrieval but also broadens the scope of what is discoverable, fostering innovation and deeper understanding across diverse domains.
Evaluations demonstrate that QUARK consistently elevates the performance of information retrieval systems, achieving statistically significant gains across several key metrics. Specifically, improvements are observed in Mean Reciprocal Rank at 10 (MRR@10), Normalized Discounted Cumulative Gain at 10 (nDCG@10), and Recall at 10 (Recall@10). Critically, these enhancements aren’t limited to a single dataset or retrieval model; QUARK’s effectiveness has been validated across diverse benchmarks and in conjunction with various state-of-the-art retrievers. This broad applicability suggests that QUARK isn’t merely optimizing for specific conditions, but rather providing a foundational improvement to the retrieval process itself, promising more reliable and accurate information access across a wide range of applications.
The pursuit of reliable information retrieval, as detailed in this work on QUARK, fundamentally mirrors a commitment to deterministic systems. The framework’s emphasis on generating and aggregating recovery hypotheses, anchoring them to the original query, directly addresses the unreliability introduced by ‘non-faithful queries’ and ‘recall noise’. This mirrors the spirit of Claude Shannon, who famously stated: “The most important thing in a good experiment is to look for ways to disprove your hypothesis.” QUARK doesn’t simply accept query ambiguity; it actively seeks alternative interpretations, validating and integrating them to produce a more robust and reproducible outcome. The algorithm’s success hinges on a provable, deterministic process for handling uncertainty, aligning with the principle that a result must be verifiable to be trustworthy.
Where Do We Go From Here?
The introduction of QUARK represents a pragmatic acknowledgement of a persistent failing in information retrieval: the assumption of query perfection. To address non-faithful queries without resorting to the black art of retraining, through query-anchored aggregation, is a conceptually sound maneuver. However, it skirts the deeper question of what constitutes a faithful query, and whether such a thing can ever be truly guaranteed in the face of human imprecision. The generation of recovery hypotheses, while effective, remains a heuristic; a cleverly disguised form of educated guessing. The elegance lies not in the method itself, but in its explicit avoidance of statistical generalization – a refreshing departure from the prevailing trends.
Future work must confront the limitations inherent in defining ‘latent intent’ solely through query manipulation. The framework currently operates on the signal, not the source of the noise. Investigating methods to explicitly model and mitigate the causes of non-faithful queries – cognitive biases, ambiguous language, flawed information seeking strategies – promises a more robust, and perhaps more theoretically satisfying, solution. To treat the symptom is useful; to understand the disease is paramount.
Ultimately, the field must resist the temptation to optimize without analysis. The proliferation of increasingly complex retrieval models, evaluated solely on benchmark datasets, risks obscuring fundamental flaws. A return to first principles – a rigorous examination of the information need itself – remains the most intellectually honest path forward.
Original article: https://arxiv.org/pdf/2601.21049.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Shadow Armor Locations in Crimson Desert
- Best Bows in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- Wings of Iron Walkthrough in Crimson Desert
- How to Craft the Elegant Carmine Armor in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- All Skyblazer Armor Locations in Crimson Desert
- How To Beat Ator Archon of Antumbra In Crimson Desert
- Keeping Large AI Models Connected Through Network Chaos
2026-01-30 14:51