Author: Denis Avetisyan
As large language models move to open, distributed networks, ensuring reliable performance in the face of malicious actors becomes paramount.
This review explores adaptive and robust mechanisms for proving quality in decentralized LLM inference networks, focusing on Byzantine fault tolerance, cost-aware incentives, and adversarial machine learning defenses.
Decentralized large language model inference networks, while promising, are vulnerable to unreliable quality assessment due to evaluator heterogeneity and potential malicious behavior. This paper, ‘Adaptive and Robust Cost-Aware Proof of Quality for Decentralized LLM Inference Networks’, addresses this challenge by extending cost-aware Proof of Quality mechanisms with robust aggregation rules and adaptive trust weighting. Our findings demonstrate that employing techniques like median and trimmed mean aggregation, alongside dynamically updated evaluator weights, significantly improves consensus alignment with ground truth and reduces susceptibility to adversarial attacks. Ultimately, how can we best balance the trade-offs between evaluator reward, sampling size, and robustness in open, resource-constrained decentralized inference systems?
Decentralized Inference: Navigating the Challenges of Trust
Decentralized Large Language Model (LLM) inference presents a compelling pathway to scalability, allowing for the distribution of computational load across numerous nodes and potentially unlocking significantly higher throughput. However, this architectural shift introduces substantial challenges to maintaining output quality and reliability. Unlike centralized systems where a single entity controls and validates results, decentralized inference disperses responsibility, creating vulnerabilities to inconsistent performance and the propagation of errors. Ensuring the trustworthiness of outputs requires innovative approaches, as traditional quality control methods – reliant on central oversight – are fundamentally incompatible with the distributed nature of these systems. The very benefits of decentralization – increased resilience and reduced single points of failure – simultaneously complicate the task of verifying the accuracy and impartiality of generated text, necessitating new mechanisms for consensus and validation across a potentially untrusted network.
The shift towards decentralized Large Language Model (LLM) inference fundamentally disrupts established quality control protocols. Historically, verifying LLM outputs relied on centralized authorities – single entities responsible for evaluating and correcting responses. This approach is untenable in a distributed system where inference tasks are spread across numerous independent nodes. The very architecture of decentralized inference-designed for resilience and scalability-precludes a central point of oversight. Consequently, new verification methods are crucial, ones that can assess output quality without compromising the system’s distributed nature. These novel techniques must move beyond singular evaluations and embrace mechanisms for aggregating assessments from multiple sources, potentially leveraging cryptographic proofs or incentivized feedback loops to establish trust and reliability in a trustless environment.
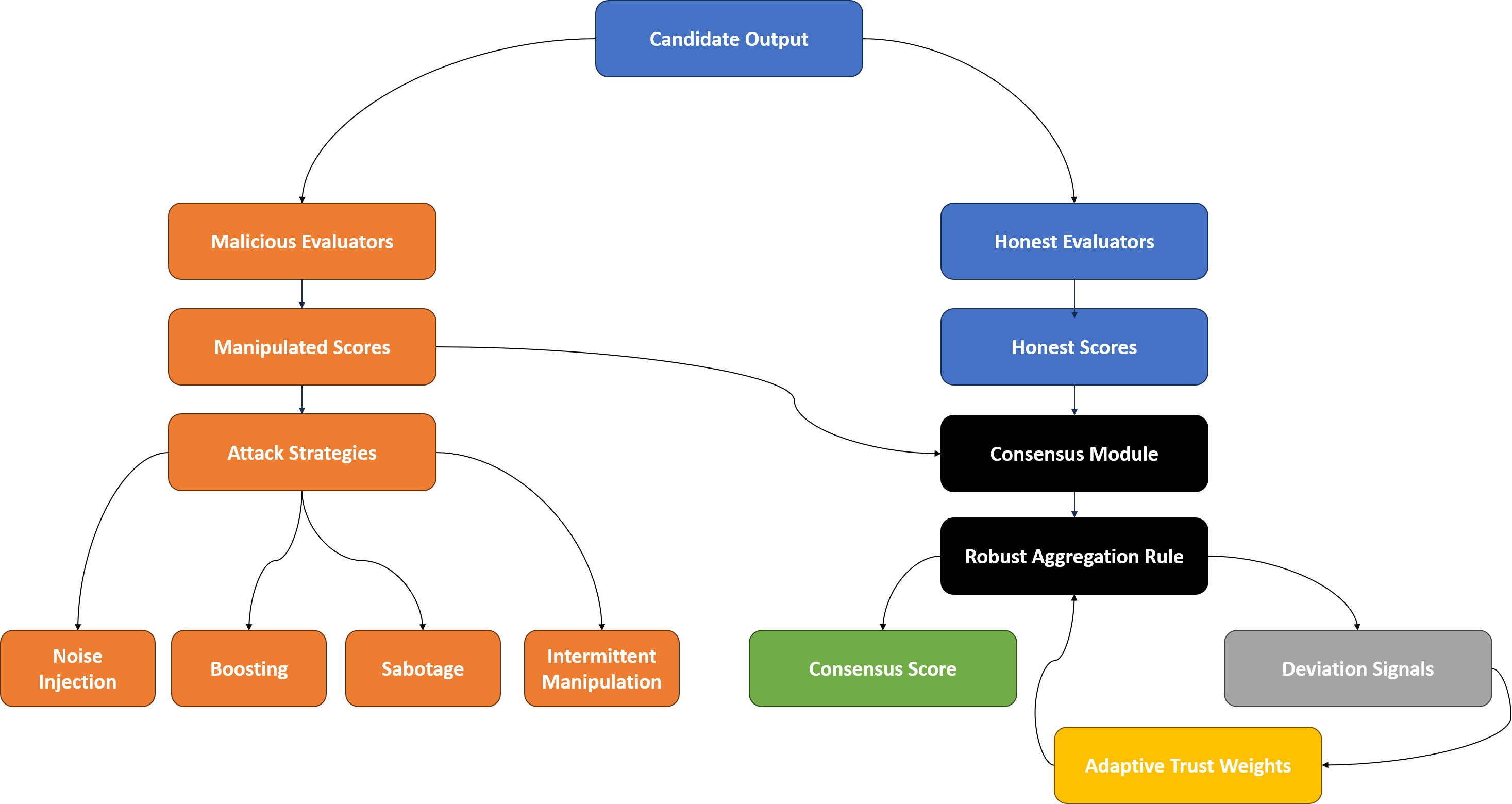
Decentralized inference systems, while offering scalability, are inherently vulnerable to compromised evaluations due to the potential for malicious actors and compromised nodes. Unlike centralized systems where evaluations can be rigorously controlled, a distributed network presents opportunities for biased or inaccurate assessments to proliferate. A single compromised node, or a coordinated attack leveraging multiple malicious participants, could skew evaluation metrics, falsely validating poor model performance or, conversely, artificially inflating the scores of substandard outputs. Consequently, robust defense mechanisms are crucial; these include cryptographic verification of evaluation results, reputation systems for nodes performing evaluations, and incentive structures that reward honest assessments while penalizing malicious behavior. Addressing this vulnerability is not merely about ensuring the accuracy of evaluations, but safeguarding the integrity and trustworthiness of the entire decentralized inference process.
Proof of Quality: A System for Distributed Validation
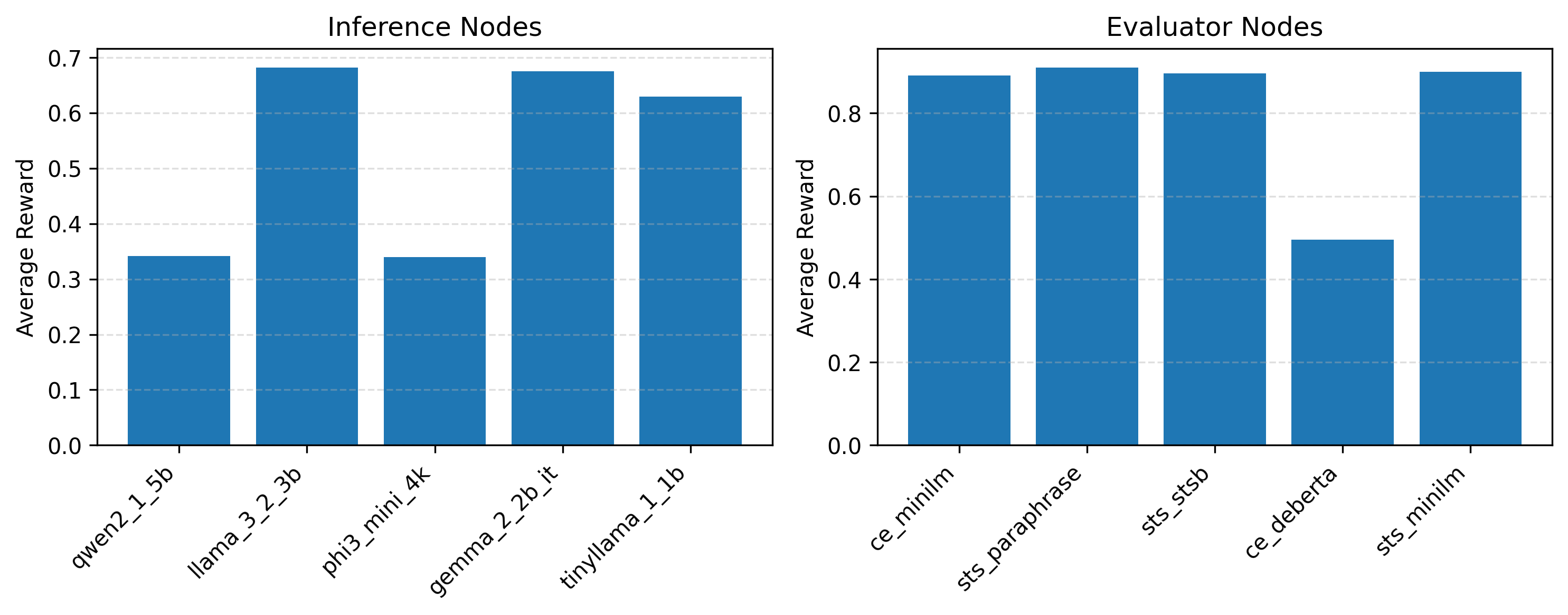
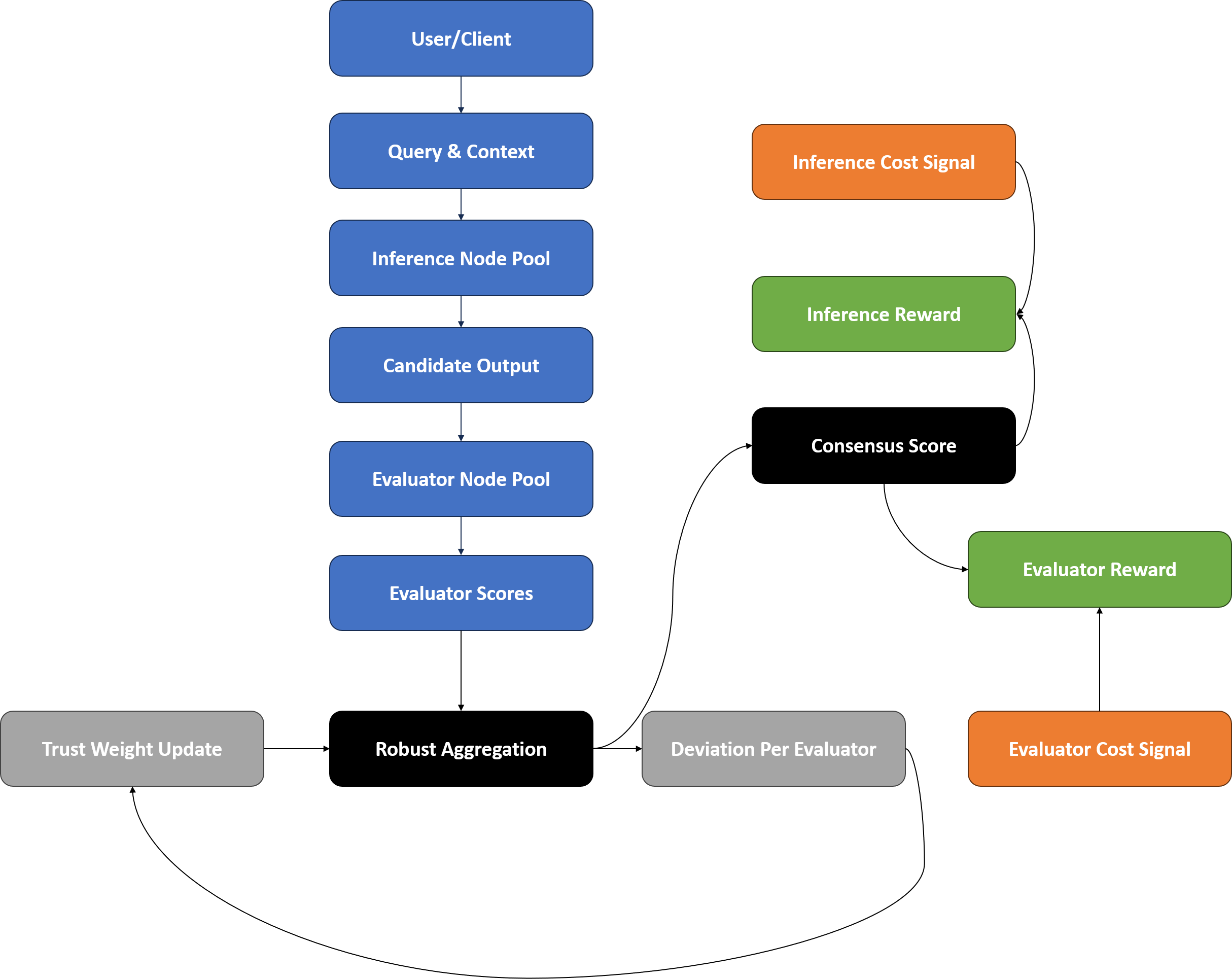
The ‘Proof of Quality’ system utilizes a distributed network of ‘Evaluator Nodes’ to provide a decentralized assessment of Large Language Model (LLM) outputs. These nodes operate independently and concurrently, each receiving the same LLM-generated text for evaluation. This architecture eliminates single points of failure and reduces the risk of biased evaluations inherent in centralized quality control systems. The network’s distributed nature ensures scalability and resilience; additional Evaluator Nodes can be added to increase throughput and maintain consistent performance under varying loads. Data from each node is aggregated to establish a collective quality score, representing a consensus assessment of the LLM’s output.
The Proof of Quality system leverages both Bi-Encoder and Cross-Encoder models to assess Large Language Model outputs via differing architectural approaches. Bi-Encoders compute embeddings for both the LLM-generated text and the prompt independently, allowing for efficient similarity scoring and scalability to large datasets. Conversely, Cross-Encoders process the prompt and generated text as a single input sequence, enabling a more nuanced understanding of context and relationships, but at a higher computational cost. Utilizing both models in concert provides a more robust and multifaceted evaluation of output quality, mitigating the biases inherent in any single assessment method and offering a broader perspective on veracity and relevance.
A consensus-based scoring system is implemented by aggregating evaluations from multiple independent Evaluator Nodes. Each node assesses LLM-generated text and provides a quality score, reflecting both veracity and relevance to the prompt. These individual scores are then combined using a defined algorithm – currently a weighted average – to produce a single, composite score. This aggregation mitigates the impact of individual evaluator biases or inaccuracies, yielding a more robust and reliable assessment of output quality than could be achieved with a single evaluator. The weighting algorithm allows for prioritization of certain evaluator models or expertise, if desired, further refining the consensus score.
Resilience Through Aggregation and Adaptive Trust
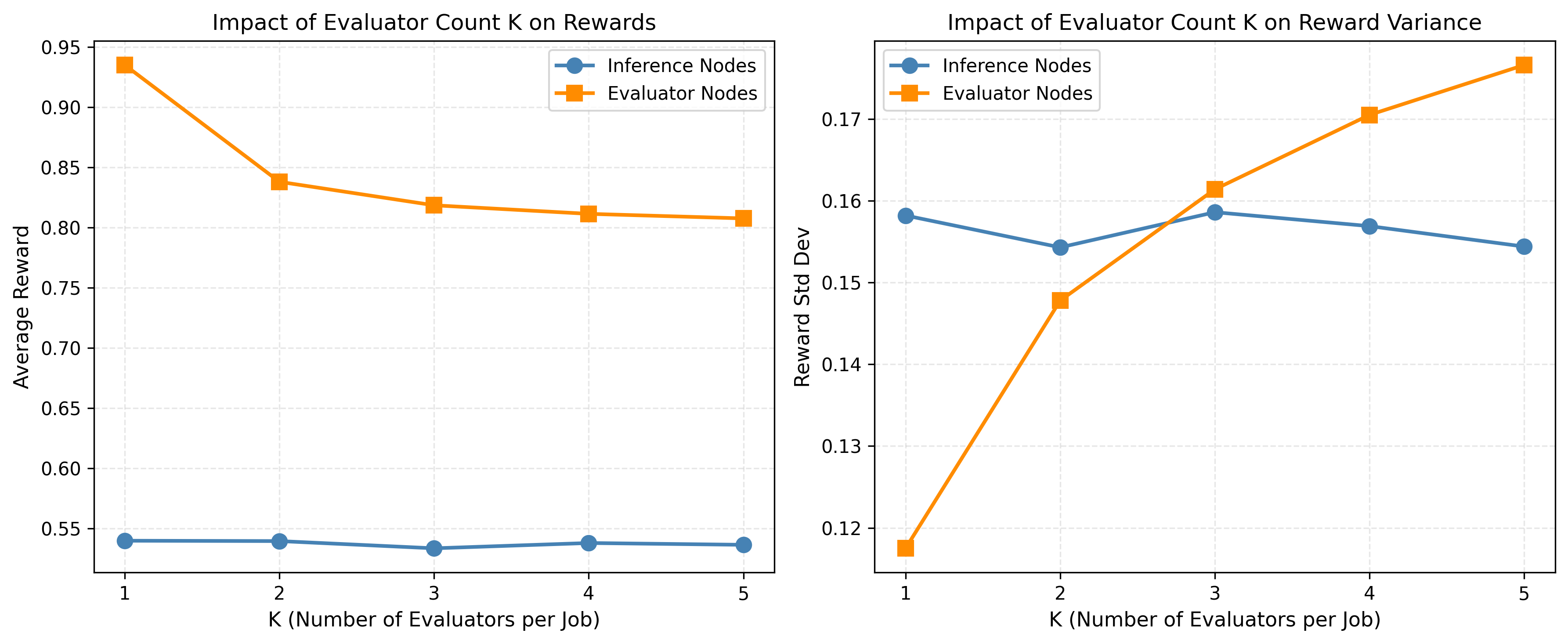
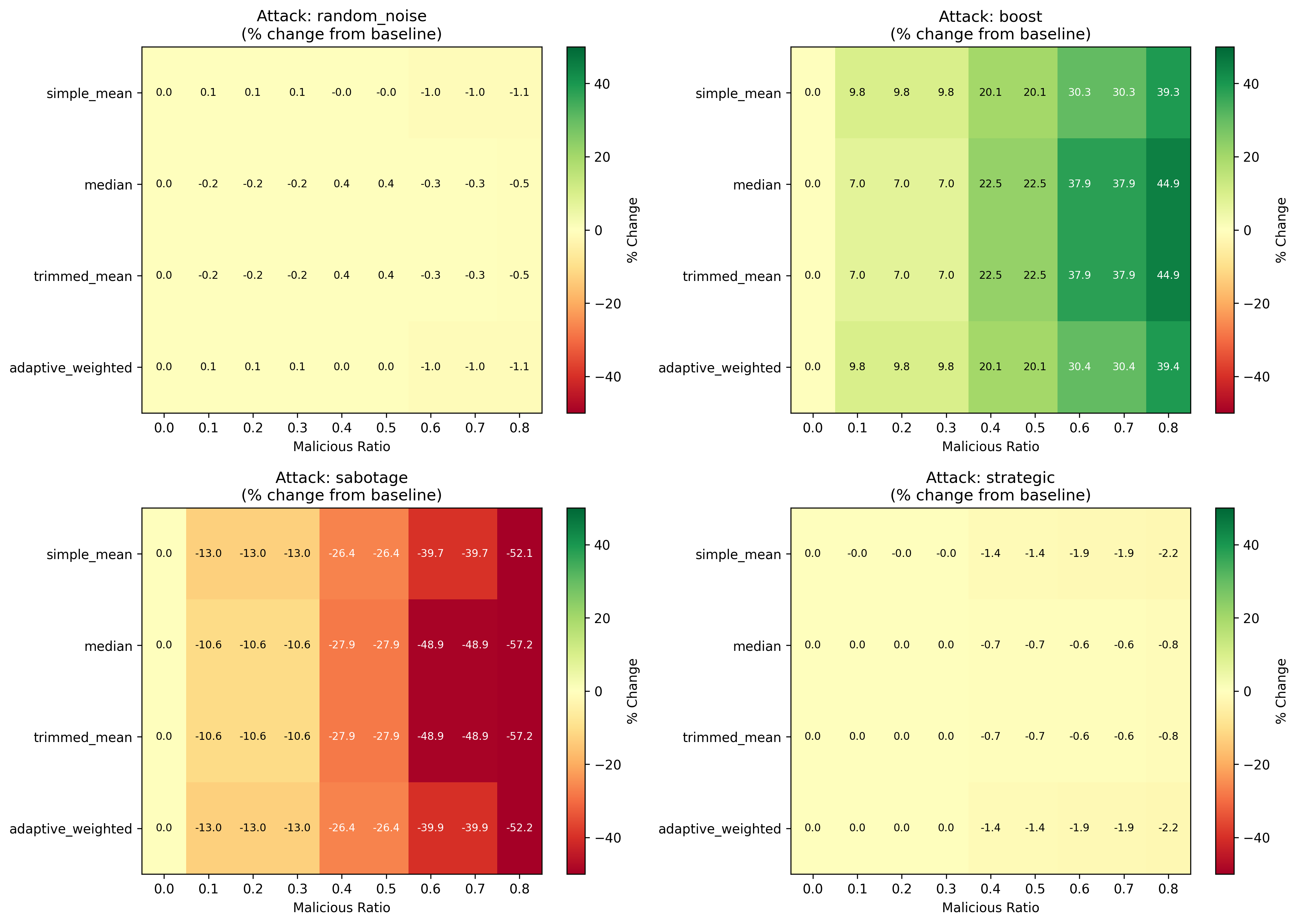
Robust aggregation techniques, specifically the Median and Trimmed Mean, are implemented to counter the effects of adversarial evaluators. These methods function by reducing the impact of outlier scores that may result from malicious or intentionally skewed evaluations. The Median calculates the central value of a dataset, effectively ignoring extreme values, while the Trimmed Mean removes a predetermined percentage of the highest and lowest scores before calculating the average. This approach ensures that the aggregated score more accurately reflects the genuine quality of the evaluated content, as it is less susceptible to manipulation by a small number of adversarial inputs. Experimental results indicate a correlation of 0.748 between median aggregation and ground truth, exceeding the performance of simple mean averaging which achieved a correlation of 0.581.
Robust aggregation techniques, specifically median and trimmed mean averaging, are implemented to mitigate the effects of malicious or unreliable evaluators. These methods function by reducing the impact of outlier scores and skewed evaluations, thereby increasing the likelihood that the final consensus accurately reflects the true quality of the assessed content. Empirical results demonstrate the effectiveness of median aggregation, achieving a correlation coefficient of 0.748 with ground truth data; this represents a substantial improvement over simple mean averaging, which yields a correlation of only 0.581 under the same conditions.
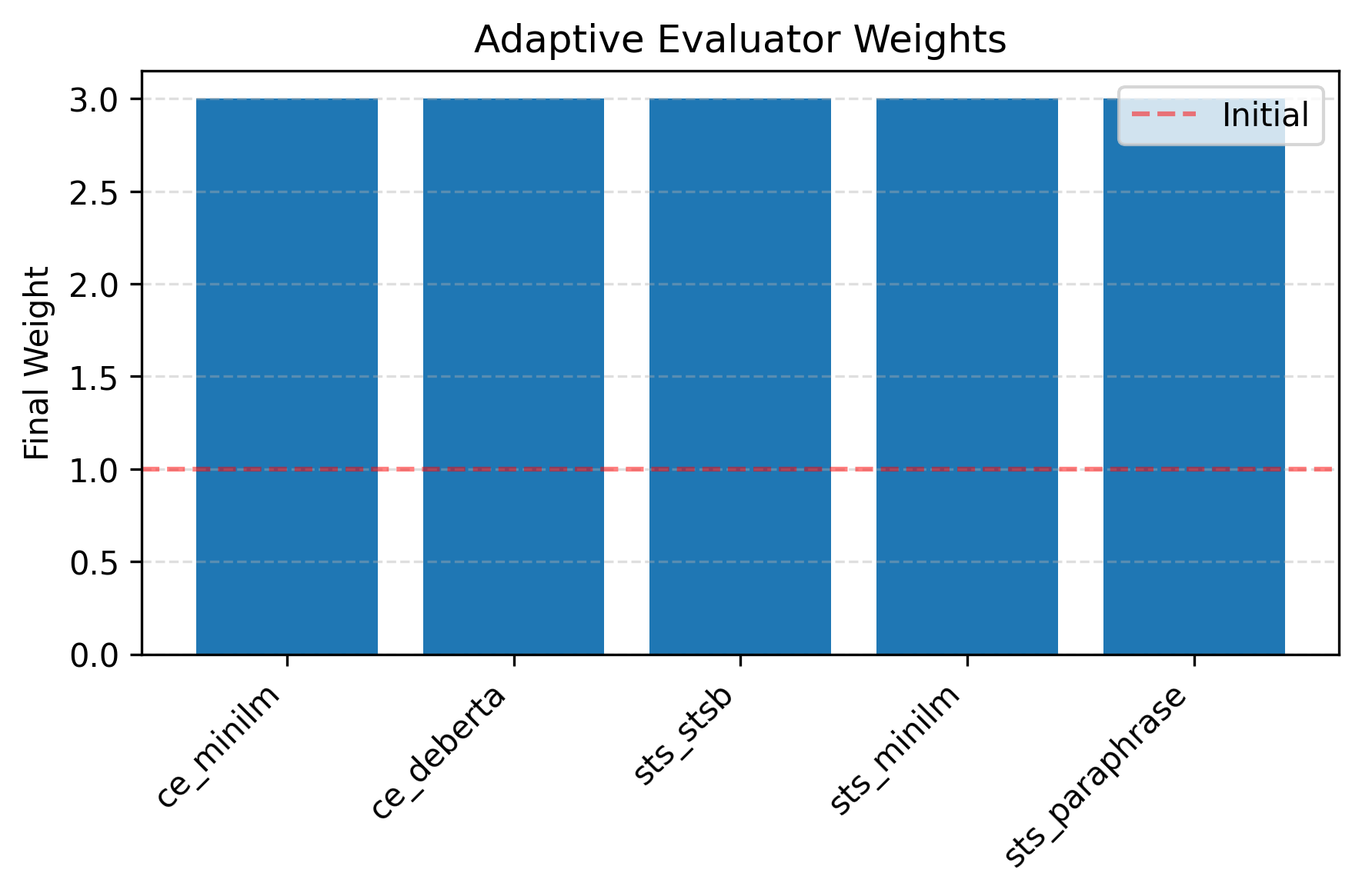
Trust Weighting is implemented to modulate the impact of individual evaluators during aggregation, leveraging a ‘Deviation Signal’ that quantifies historical reliability. This signal measures the degree to which an evaluator’s scores diverge from the consensus of other evaluators over time; higher divergence indicates lower trustworthiness. Evaluator weights are then dynamically adjusted inversely proportional to their Deviation Signal, reducing the influence of consistently unreliable sources and increasing the contribution of those with a proven track record of alignment with the collective assessment. This approach enables the system to adapt to varying evaluator behavior and mitigate the effects of both intentional manipulation and unintentional inconsistencies in scoring.
Balancing Quality and Cost: An Incentive-Driven System
The system’s core innovation lies in its ‘Proof of Quality’ framework, which isn’t simply about verifying correctness, but about actively encouraging both accurate assessments and responsible resource allocation. This is achieved through a ‘Cost-Aware Reward’ mechanism that directly incentivizes operators of ‘Inference Nodes’ and ‘Evaluator Nodes’ to prioritize high-quality evaluations while minimizing computational expense. By tying rewards to both the reliability of outputs-measured by metrics like ROUGE and token-level F1 scores-and the cost of achieving those results, the system fosters a dynamic equilibrium. This approach moves beyond traditional quality control, establishing a self-regulating cycle where efficiency and accuracy are mutually reinforcing, ultimately optimizing overall performance and value.
The system’s architecture directly incentivizes contributions from both ‘Inference Node’ and ‘Evaluator Node’ operators, fostering a collaborative environment focused on optimal performance. Operators of Inference Nodes receive rewards proportional to the quality and speed of their generated outputs, while Evaluator Node operators are compensated based on the accuracy and reliability of their assessments. This dual-incentive structure encourages a virtuous cycle: high-quality inferences attract more accurate evaluations, which in turn provides feedback for further improving inference quality. Consequently, the network self-optimizes, achieving both heightened output accuracy and efficient resource allocation as operators are directly motivated to contribute to the overall system’s success.
The system achieves a crucial equilibrium between dependable results and economical operation by integrating established quality benchmarks – specifically, ROUGE and token-level F1 scores – with careful cost analysis. This ensures that high-quality evaluations aren’t simply prioritized, but are also attained with mindful resource allocation. Importantly, testing reveals a consistent stability in inference rewards even when the number of evaluator samples (KK) changes, suggesting the system’s inherent resilience and ability to maintain performance under diverse conditions – a key indicator of its robust design and potential for scalability.
Towards a Future of Secure and Scalable AI
Recent advancements reveal the practical potential of constructing decentralized Large Language Model (LLM) inference systems that prioritize both security and scalability. This research demonstrates a pathway towards AI deployments resistant to common vulnerabilities, including malicious attacks and the unreliability of individual participants. By distributing the computational load and employing novel consensus mechanisms, these systems minimize single points of failure and enhance robustness. The architecture enables verifiable computation, ensuring the integrity of AI outputs even when operating within a trustless environment – a crucial step toward broader AI adoption and accessibility, particularly in scenarios demanding high levels of data privacy and security.
Ongoing development centers on enhancing the ‘Trust Weighting’ algorithm, a crucial component in ensuring the reliability of decentralized AI systems. This refinement aims to more accurately assess the credibility of individual inference nodes, assigning higher weight to those with proven track records and lower weight to potentially compromised or unreliable sources. Simultaneously, research is actively exploring advanced techniques for identifying and neutralizing ‘Sybil Attacks’, where a malicious actor creates numerous fake identities to manipulate the system. These sophisticated detection methods move beyond simple IP address blocking, incorporating behavioral analysis and cryptographic verification to distinguish legitimate nodes from malicious imposters, ultimately bolstering the resilience and trustworthiness of the entire AI infrastructure.
The development of decentralized large language model (LLM) inference systems promises a paradigm shift in artificial intelligence deployment, enabling operation within trustless environments where no central authority is required. This foundational change unlocks possibilities previously hampered by reliance on single points of failure or control, potentially democratizing access to powerful AI tools. By distributing computational workload and verification across a network, these systems circumvent traditional barriers to entry, fostering innovation from a wider range of contributors and lowering costs for end-users. The implications extend beyond mere technological advancement; a truly decentralized AI ecosystem could empower individuals and communities, enabling novel applications in fields like data privacy, censorship resistance, and equitable access to information – ultimately fostering a more inclusive and accessible future for artificial intelligence.
The pursuit of reliable decentralized inference networks, as detailed in the study, necessitates a rigorous approach to quality assessment. This demands more than simply aggregating evaluations; it requires discerning signal from noise, especially when facing potentially adversarial actors. Ada Lovelace observed, “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform.” This sentiment mirrors the core concept of robust aggregation; the system’s reliability isn’t inherent, but constructed through carefully designed mechanisms-trust weighting and Byzantine Fault Tolerance-that filter malicious inputs and ensure the final output reflects genuine quality, guided by pre-defined, trustworthy parameters. The system merely executes what it is instructed, and the quality of that execution depends entirely on the integrity of the instructions and the filters applied.
Further Refinements
The pursuit of decentralized inference networks, fortified against adversarial evaluation, reveals a familiar truth: security is not a property, but a process of asymptotic approach. This work establishes a framework, but the devil, predictably, resides in the details of implementation and scale. The adaptive trust weighting, while promising, demands careful consideration of its own vulnerabilities – a weighting scheme, however nuanced, remains susceptible to manipulation if the underlying signals are sufficiently corrupted or subtly biased.
Future investigations should move beyond idealized Byzantine fault tolerance models. Real-world deployments will encounter not simply malicious actors, but imperfect actors – those with limited computational resources, fluctuating network connectivity, or simply differing interpretations of ‘quality.’ A robust system must gracefully degrade in the face of these realities, rather than collapsing into inaction. The economic incentives, currently framed as cost-awareness, require deeper scrutiny – are these truly aligned with fostering reliable evaluation, or merely encouraging a race to the bottom?
Ultimately, the challenge lies not in eliminating all uncertainty – an impossible task – but in building systems that are acceptably uncertain. The focus should shift from absolute proof of quality to probabilistic guarantees, accepting a defined level of risk in exchange for scalability and efficiency. The elegance of a solution is not measured by its complexity, but by its parsimony – by how much can be removed, and yet still function.
Original article: https://arxiv.org/pdf/2601.21189.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- NTE Drift Guide (& Best Car Mods for Drifting)
- All Aswang Evidence & Weaknesses in Phasmophobia
- Where to Find Prescription in Where Winds Meet (Raw Leaf Porridge Quest)
- Conduit Crystal Location In Subnautica 2
- Diablo 4 Best Loot Filter Codes
- How to Get Necrolei Cyst & Strong Acid in Subnautica 2
- How to Get the Wunderbarrage in Totenreich (BO7 Zombies)
- Best Burst & Full Auto Builds for the M16A4 in BF6
- Boruto: Ikemoto Has Already Hinted At Sasuke’s New Eye After Return
- USD RUB PREDICTION
2026-01-31 06:05