Author: Denis Avetisyan
A new approach dynamically adjusts model parameters during processing, boosting speed and reducing memory demands without sacrificing performance.
ChunkWise LoRA introduces adaptive sequence partitioning to optimize low-rank adaptation and accelerate inference in transformer models.
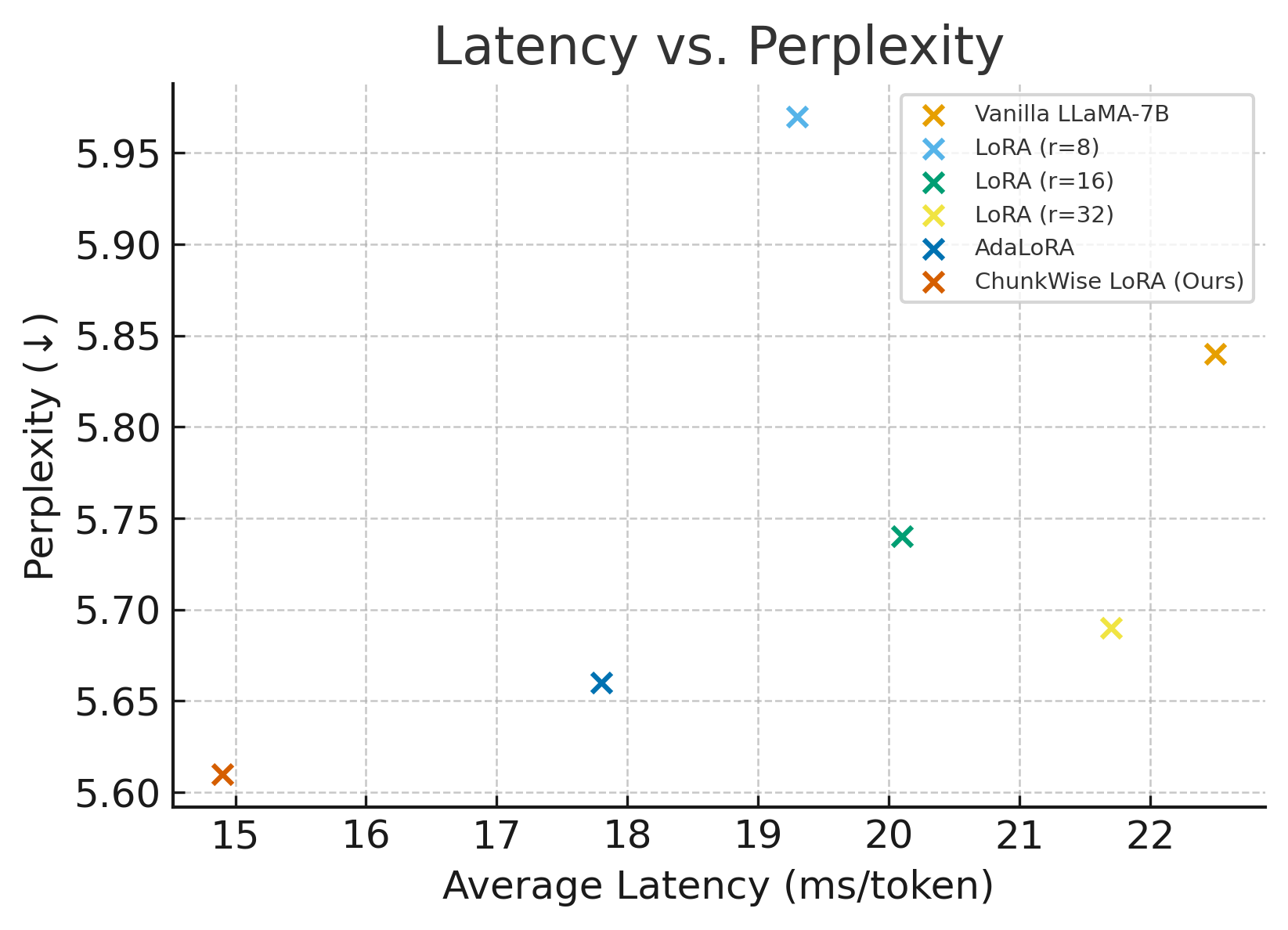
While low-rank adaptation (LoRA) has become a cornerstone of efficient large language model (LLM) fine-tuning, existing methods often apply uniform rank configurations, overlooking the varying computational demands of different input tokens. This work introduces ‘ChunkWise LoRA: Adaptive Sequence Partitioning for Memory-Efficient Low-Rank Adaptation and Accelerated LLM Inference’, a dynamic framework that partitions input sequences into variable-length chunks and assigns each a tailored low-rank configuration based on token complexity. By adaptively adjusting the LoRA rank per chunk, we achieve substantial reductions in both latency and memory footprint-up to 34% and 38%, respectively-without sacrificing performance. Could this approach unlock even greater efficiencies and enable the deployment of LLMs on resource-constrained devices?
The Scaling Challenge: Unlocking Contextual Understanding
The remarkable capabilities of Large Language Models stem from the Transformer architecture, yet a fundamental limitation hinders their continued progress: quadratic scaling with sequence length. This means the computational resources – and therefore cost and time – required to process text increase at a rate proportional to the square of the input sequence length. Essentially, doubling the length of a document more than quadruples the processing demand. This poses a significant bottleneck, restricting the size of context windows – the amount of text the model can effectively consider at once – and making it prohibitively expensive to process lengthy documents or engage in complex reasoning that demands comprehensive contextual understanding. While advancements in model size have yielded impressive results, overcoming this quadratic scaling challenge is crucial to unlocking the full potential of these models and enabling their application to more complex, real-world scenarios.
The inherent quadratic scaling of large language models presents a practical barrier to handling complex tasks. As the length of the input sequence increases, the computational demands – and therefore the cost – grow disproportionately, quickly exceeding available resources. This limitation directly constrains the context window – the amount of text the model can effectively consider at once – which is crucial for tasks requiring sustained reasoning, nuanced understanding, or the processing of lengthy documents. Consequently, performance deteriorates when faced with scenarios like summarizing extensive legal contracts, analyzing detailed scientific reports, or engaging in prolonged, coherent dialogue, as the model struggles to maintain relevant information from earlier parts of the input due to these computational and memory constraints.
While techniques like BitFit, Prompt Tuning, and Prefix Tuning have emerged as valuable strategies for adapting large language models to specific tasks, they primarily offer incremental improvements rather than a solution to the core computational bottleneck. These parameter-efficient methods reduce the number of trainable parameters – lessening the burden on memory and processing – but they do not alter the fundamental quadratic relationship between sequence length and computational cost inherent in the Transformer architecture. Consequently, performance still degrades significantly as input sequences grow, limiting the ability of these models to effectively process lengthy documents or engage in complex reasoning that demands a broad contextual understanding. Essentially, these methods act as optimizations within the existing scaling limitations, rather than breakthroughs that overcome them, highlighting the ongoing need for architectural innovations that address the root cause of the problem.
Realizing the complete capabilities of Large Language Models, and specifically those within the LLaMA family, hinges on overcoming current architectural and computational limitations. While model size continues to grow, the associated costs of training and deploying these systems are becoming increasingly prohibitive, restricting access and hindering broader application. Innovative approaches to model architecture, such as sparse attention mechanisms or state space models, promise to reduce the quadratic complexity inherent in the Transformer architecture. Simultaneously, advancements in inference techniques – including quantization, pruning, and knowledge distillation – are crucial for enabling efficient deployment on resource-constrained devices and facilitating real-time processing of lengthy inputs. These combined efforts are not merely incremental improvements, but fundamental necessities for unlocking the next generation of truly powerful and accessible language technologies.
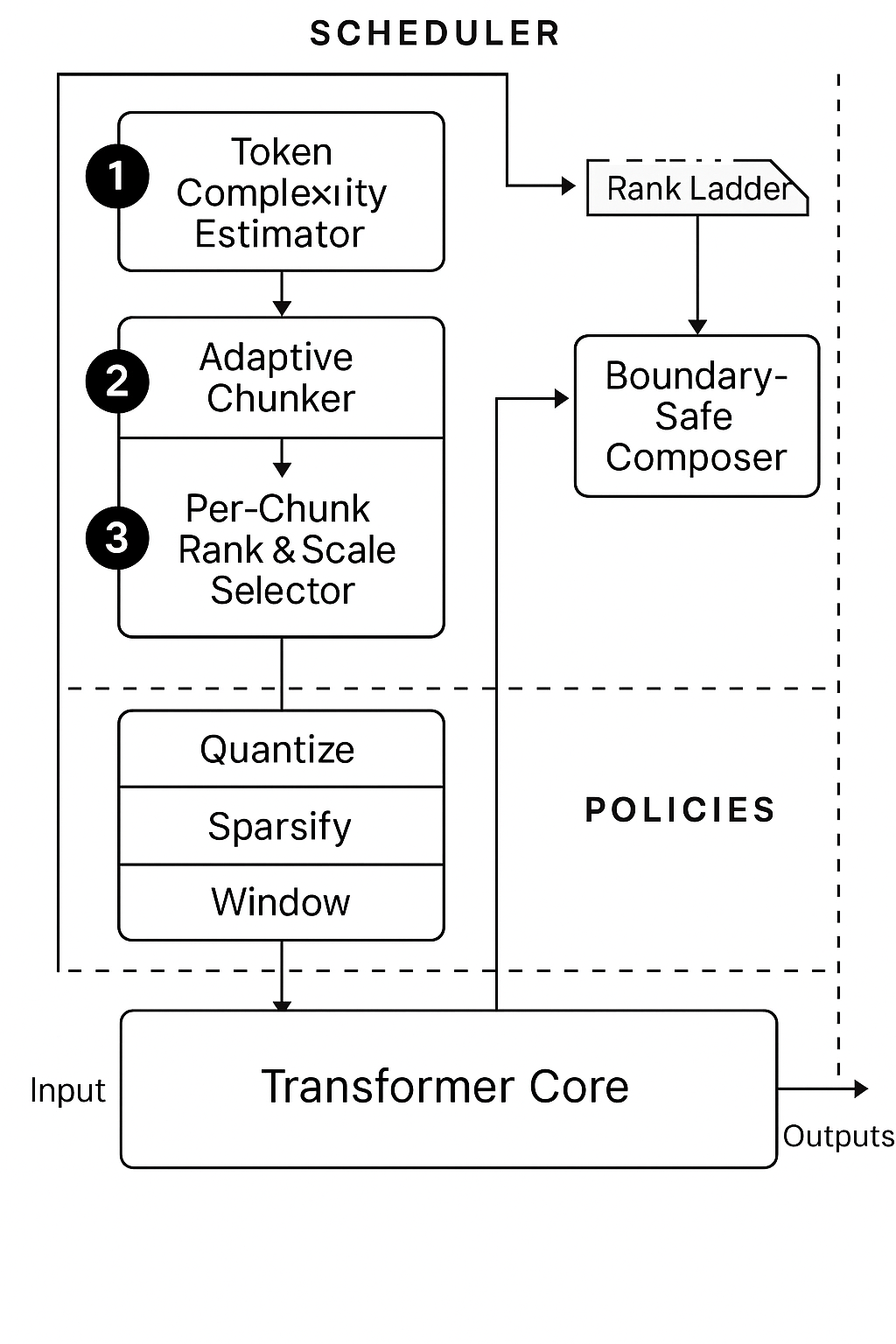
Adaptive Chunking: Deconstructing Complexity
Partitioning input sequences into variable-length chunks offers substantial benefits for large language model processing. This technique enables parallelization, allowing multiple chunks to be processed simultaneously and reducing overall processing time. Furthermore, by operating on smaller subsequences, the memory footprint is significantly decreased, addressing a key limitation when handling extensive input data. Variable-length chunking optimizes resource utilization by adapting to the inherent structure of the input sequence, unlike fixed-size chunking which may lead to inefficient padding or truncation. This approach is particularly effective when combined with techniques that tailor computational resources to each individual chunk.
The Adaptive Chunker is a method of sequence partitioning that moves beyond fixed-length segmentation by dynamically grouping tokens based on an assessment of their inherent complexity. This assessment, typically involving metrics like token entropy or the difficulty of predicting subsequent tokens, allows the chunker to create variable-length groups. Tokens exhibiting higher complexity, or those requiring more computational effort for processing, are grouped into smaller chunks. Conversely, simpler, more predictable tokens are consolidated into larger chunks. This adaptive approach optimizes resource allocation by ensuring that each chunk receives an appropriate level of computational attention, thereby increasing processing efficiency and reducing overall resource consumption.
Effective processing of partitioned input sequences requires that each chunk possess sufficient computational capacity to handle its complexity; simply dividing a longer sequence into chunks does not inherently address resource allocation. Chunks containing more complex information or requiring more nuanced processing necessitate a greater share of available parameters. Parameter-efficient methods, such as low-rank adaptation (LoRA), offer a solution by enabling selective parameter updates specific to each chunk, avoiding the computational cost of fine-tuning all parameters for every segment of the input. This allows for a dynamic allocation of capacity, ensuring that more demanding chunks receive the necessary resources while minimizing overall computational overhead.
ChunkWise LoRA addresses the challenge of varying computational demands across different segments of a partitioned input sequence. This technique applies Low-Rank Adaptation (LoRA) not to the entire model, but independently to each chunk generated by the adaptive chunker. By selectively applying low-rank updates – parameter matrices with reduced dimensionality – to each chunk, the model’s capacity is dynamically allocated based on the complexity of that specific segment. This results in a more efficient use of computational resources and potentially improved performance, as simpler chunks require fewer parameters to process while complex chunks receive increased representational power without impacting the entire model. The method facilitates parameter-efficient fine-tuning by only updating a small fraction of the total parameters for each chunk, minimizing memory requirements and training time.
Seamless Integration: Bridging the Gaps
The Boundary-Safe Composer addresses the potential for artifacts arising from chunk-based processing by implementing a smooth integration strategy between adjacent chunks. This is achieved through overlap and blending during the composition phase, effectively mitigating abrupt transitions that could introduce discontinuities in the generated output. By considering contextual information spanning chunk boundaries, the composer preserves coherence and ensures a fluid, natural progression, preventing the noticeable seams or disruptions often associated with segmented processing techniques. This approach is critical for maintaining the overall quality and consistency of the generated sequence, particularly in applications sensitive to subtle contextual cues.
The KV-Cache Policy Controller enhances performance by implementing dynamic cache management at the chunk level. This controller selectively applies quantization and sparsification techniques to key-value (KV) cache entries based on observed usage patterns and computational constraints within each chunk. Quantization reduces the precision of the cached values, decreasing memory footprint and bandwidth requirements, while sparsification removes less significant entries, further reducing storage needs. These adjustments are performed adaptively to balance memory savings with potential accuracy loss, ensuring optimized performance without substantial degradation in output quality.
Sequence-Aware Scheduling optimizes large language model inference by coordinating the division of input sequences into chunks with the selection of Low-Rank Adaptation (LoRA) parameters for each chunk. This process couples the chunking strategy directly with per-chunk LoRA rank and scale settings, allowing for dynamic adjustment of computational load. By evaluating each chunk independently, the system can assign lower LoRA ranks to less complex segments, reducing the number of trainable parameters and associated memory requirements. Conversely, more demanding chunks receive higher LoRA ranks to maintain accuracy. This adaptive approach minimizes overall computational cost while preserving model performance, as it avoids applying high-precision LoRA to all segments of the input sequence.
Linearization error serves as a critical metric in the adaptive process of reducing KV-cache capacity; it quantifies the deviation introduced by approximating full-precision attention with reduced-precision or sparse representations. This error is actively monitored and used to dynamically adjust the level of capacity reduction applied to each chunk, guaranteeing that reductions remain within acceptable accuracy thresholds. Simultaneously, the integration of FlashAttention significantly enhances computational efficiency by reordering attention computations to reduce memory accesses and improve parallelism, thereby mitigating the performance overhead associated with large sequence lengths and maintaining overall throughput during adaptive cache management.
Accelerating the Future: Expanding LLM Capabilities
ChunkWise LoRA achieves accelerated inference speeds by strategically partitioning long input sequences into manageable chunks, thereby lessening the computational load typically associated with processing extensive text. This technique addresses a core bottleneck in large language model (LLM) performance, as the computational cost of attention mechanisms scales quadratically with sequence length. By focusing computations on these smaller, independent segments, ChunkWise LoRA significantly reduces the demands on memory and processing power. The result is a more efficient workflow, allowing for faster response times and the ability to handle longer, more complex prompts without sacrificing speed or accuracy – a critical advancement for real-time applications and detailed content generation.
To optimize large language model (LLM) processing, a dynamic resource allocation system intelligently distributes computational effort based on the complexity of individual text segments. This system, driven by a Token Complexity Estimator, assesses the difficulty presented by each ‘chunk’ of text, predicting the computational resources required for accurate processing. The Per-Chunk Rank Selector then leverages this information to assign a higher rank – and therefore more processing power – to the more challenging segments, while less demanding sections receive fewer resources. This adaptive approach avoids the inefficiencies of uniformly applying the same computational load to every token, resulting in faster inference and reduced memory usage without compromising accuracy. By focusing resources where they are most needed, the system unlocks the potential for more efficient and scalable LLM applications.
The performance gains achieved through ChunkWise LoRA are not isolated; the methodology is designed for synergistic compatibility with established optimization techniques. Specifically, integrating Mixed-Precision training and INT8 Quantization further amplifies the speed and efficiency benefits. Mixed-Precision reduces memory footprint and accelerates computation by employing lower-precision floating-point formats where appropriate, while INT8 Quantization represents weights and activations using 8-bit integers, dramatically decreasing memory usage and boosting throughput. This seamless integration allows for substantial reductions in both computational load and memory requirements, creating a powerful combination that unlocks even greater potential for deploying large language models on resource-constrained hardware and scaling inference to meet increasing demands.
ChunkWise LoRA demonstrably reshapes the landscape of large language model (LLM) efficiency, achieving a remarkably low latency of 14.9 ms/token and a streamlined memory footprint of just 9.1 GB – substantial gains over current methodologies. This performance isn’t merely about speed; the reduced computational demands unlock advanced techniques such as Speculative Decoding and Token Merging. Speculative Decoding allows the model to predict future tokens and verify them in parallel, while Token Merging reduces sequence length, both contributing to faster and more efficient processing. Consequently, these capabilities broaden the scope of LLM applications, making them viable for real-time interactions, resource-constrained environments, and complex tasks previously considered computationally prohibitive.
Toward a Democratized Future: Scalable and Accessible Language Modeling
ChunkWise LoRA offers a compelling solution to the inherent scaling challenges faced by large language models. Traditional methods often struggle with lengthy input sequences due to computational demands, but this innovative approach dynamically adjusts its processing based on the complexity within the text. By dividing input into variable-sized ‘chunks’ and applying Low-Rank Adaptation (LoRA) to each, the model efficiently focuses resources where they are most needed. This not only reduces computational load but also allows for effective reasoning and generation across extended contexts, paving the way for more sophisticated applications in areas like real-time dialogue and complex document analysis. The technique demonstrates a marked improvement in handling long-form content without sacrificing performance, representing a critical advancement towards truly scalable and accessible language modeling.
This innovative approach to language modeling moves beyond static parameter adjustments, instead dynamically tailoring its computational effort to the inherent complexity of each input sequence. By focusing resources where they are most needed – intricate reasoning tasks or lengthy passages of text – the system achieves greater efficiency without sacrificing performance. This adaptability is particularly crucial for applications demanding real-time responses, such as interactive dialogue systems or live translation services, and it simultaneously opens doors to more sophisticated long-form content generation and complex problem-solving that were previously computationally prohibitive. Consequently, a system that intelligently allocates resources based on input characteristics represents a significant advancement in making powerful language models both accessible and versatile.
Continued development surrounding ChunkWise LoRA centers on several key areas poised to further enhance its efficiency and applicability. Researchers are actively investigating more sophisticated chunking strategies, aiming to dynamically adjust segment sizes based on linguistic structure and contextual relevance – potentially improving the model’s capacity to capture long-range dependencies. Simultaneously, efforts are dedicated to optimizing the rank selection process, exploring algorithms that intelligently determine the optimal number of parameters to adapt for each chunk, balancing performance gains with computational cost. Crucially, this work doesn’t exist in isolation; ongoing research seeks to integrate ChunkWise LoRA with complementary acceleration techniques, such as quantization and pruning, to achieve even greater speedups and reduce memory footprint – ultimately paving the way for deployment on resource-constrained devices and broader accessibility to powerful language modeling capabilities.
The advent of ChunkWise LoRA and related advancements in efficient language modeling isn’t merely a technical improvement; it signals a potential shift in access to artificial intelligence. Historically, the immense computational demands of large language models have concentrated their benefits within the reach of well-resourced institutions. However, by significantly reducing the resources required for both training and deployment, this work paves the way for a more equitable distribution of AI capabilities. Smaller organizations, independent researchers, and even individual developers can now realistically explore and implement powerful language models, fostering innovation and addressing diverse needs previously beyond their reach. This democratization promises to unlock a wider spectrum of applications, from personalized education and localized content creation to specialized tools for niche industries, ultimately amplifying the transformative potential of language models across society.
The pursuit of efficient large language model inference necessitates a holistic understanding of system boundaries. ChunkWise LoRA exemplifies this principle by acknowledging that not all tokens demand equal computational resources. The framework’s adaptive partitioning, driven by token complexity, mirrors an organism’s ability to allocate energy where it’s most needed. This resonates with the insight of Claude Shannon, who observed that “The most important thing in communication is to convey the meaning, not merely to transmit the signal.” ChunkWise LoRA isn’t simply about accelerating inference; it’s about intelligently managing resources to ensure meaningful computation without wasteful expenditure, thereby fortifying the system against potential weaknesses arising from unbalanced demands.
Future Directions
ChunkWise LoRA, in its attempt to sculpt adaptation around the inherent complexities of language, highlights a familiar truth: efficiency often demands a willingness to sacrifice uniformity. The framework elegantly addresses the variable demands of different tokens, but the very notion of ‘complexity’ remains a proxy. Future work will undoubtedly probe more direct measures of information content, perhaps drawing from principles of algorithmic information theory – though translating theoretical minimums into practical gains is, as always, the challenge. It is a comforting thought that cleverness is often fragility, and a truly robust system will likely avoid excessive optimization.
The adaptive partitioning introduced here invites consideration beyond LoRA. The principle – modulating computational effort based on local input characteristics – seems generally applicable to the broader architecture of transformers. One imagines a future where layers themselves dynamically adjust their capacity, or attention mechanisms become truly sparse, not merely in terms of connections, but in terms of actual computation performed. Such systems, however, demand a shift in thinking: we are accustomed to optimizing for peak performance, but increasingly, the art lies in gracefully managing limitations.
Ultimately, the pursuit of efficient inference is not merely about speed or memory. It is about acknowledging the fundamental limits of computation and designing systems that operate within those limits, not against them. This work is a step in that direction – a reminder that the most profound innovations often arise from accepting constraints, and that architecture, at its core, is the art of choosing what to sacrifice.
Original article: https://arxiv.org/pdf/2601.21109.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Shadow Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Best Bows in Crimson Desert
- All Skyblazer Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- Wings of Iron Walkthrough in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- How to Craft the Elegant Carmine Armor in Crimson Desert
- Keeping Large AI Models Connected Through Network Chaos
2026-01-31 21:13