Author: Denis Avetisyan
A standardized taxonomy for research software supply chains is crucial for consistently evaluating vulnerabilities and mitigating risks in academic and scientific computing.
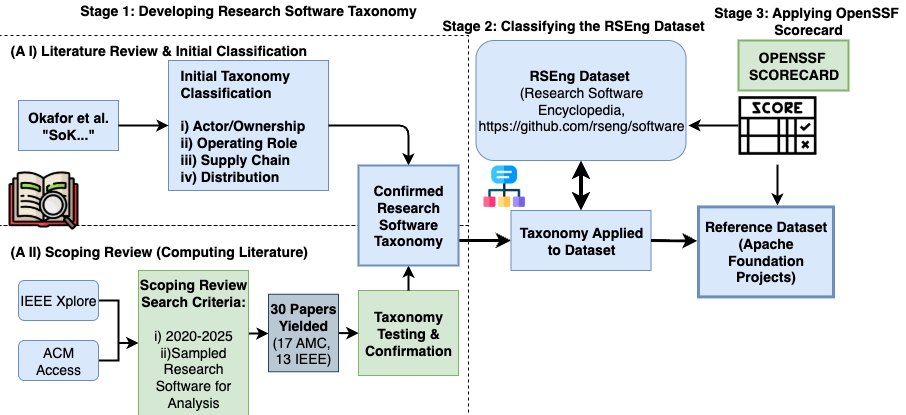
This paper introduces a taxonomy and methodology for operationalizing research software supply chain security, leveraging repository mining and tools like the OpenSSF Scorecard.
Empirical studies of research software security are hampered by inconsistent definitions of the software itself. In ‘Operationalizing Research Software for Supply Chain Security’, we address this challenge by introducing a taxonomy designed to standardize operational boundaries for analyzing the research software supply chain (RSSC). This taxonomy, derived from a scoping review and operationalized on a large corpus from the Research Software Encyclopedia, enables a harmonized approach to identifying and classifying relevant software components. How can this taxonomy-aware stratification improve the accuracy and comparability of security assessments across the RSSC?
The Fragile Foundation: Research Software and its Dependencies
Contemporary research endeavors are fundamentally interwoven with sophisticated software, establishing a digital infrastructure comparable in importance to traditional laboratory equipment or data repositories. This reliance extends far beyond simple data analysis; software now governs experimental design, data acquisition, instrument control, and increasingly, the very interpretation of results. The shift towards computational methods has accelerated dramatically across all scientific disciplines, meaning that a significant portion of modern scientific discovery is mediated-and therefore dependent-on the correct functioning of these complex systems. Consequently, the integrity of research is no longer solely determined by experimental rigor, but also by the robustness and reliability of the software tools employed, creating a critical need for careful evaluation and management of this burgeoning digital ecosystem.
Research software isn’t built in isolation; it functions as a complex assembly of countless external components-a “Research Software Supply Chain.” These components range from common programming languages and statistical libraries to specialized databases and operating system utilities. While this modularity accelerates discovery, it simultaneously introduces vulnerabilities. Each external dependency represents a potential point of failure, susceptible to bugs, security exploits, or even malicious code injection. A compromised component can cascade through the entire research pipeline, impacting data integrity, analysis accuracy, and ultimately, the reliability of published findings. Recognizing this intricate network of dependencies is therefore paramount, demanding proactive strategies for supply chain risk management within the research ecosystem.
The bedrock of credible scientific results rests increasingly on the transparency and verifiability of computational processes. Because modern research software rarely operates in isolation, a comprehensive understanding of its dependencies is paramount; these interconnected components – libraries, datasets, and even specific hardware – form a complex web that directly impacts the reproducibility of findings. Failure to account for these dependencies introduces hidden variables and potential sources of error, undermining the ability of other researchers to independently validate published work. Thorough documentation of the entire software supply chain, including versioning and licensing information, isn’t merely good practice, but a necessary step toward building trust and ensuring the long-term reliability of the scientific record. Ultimately, recognizing and managing these dependencies is fundamental to fostering a robust and trustworthy research ecosystem.
Charting a Course: Towards a Standardized Taxonomy
The absence of a consistent, standardized classification system for research software presents significant challenges to the scientific community. Currently, software is described using inconsistent terminology and varying levels of detail, making effective discovery difficult. This lack of standardization impedes comparative analysis of tools with similar functionality and hinders the reuse of existing software components, leading to redundant development efforts and reduced efficiency. Consequently, researchers expend considerable time and resources identifying appropriate tools and verifying their suitability for specific tasks, rather than focusing on their primary research objectives. The current situation limits interoperability and slows the overall pace of scientific progress.
The proposed Taxonomy for research software utilizes a multi-faceted categorization system. Software is classified according to its primary function – the specific research task it performs – as well as its dependencies, detailing required libraries, platforms, and input data formats. Further categorization considers inherent characteristics such as programming language, license type, data storage methods, and computational requirements. This structured approach allows for precise identification and differentiation of software tools, facilitating effective comparison and promoting interoperability within the research landscape. The taxonomy is designed to be extensible, accommodating new software and evolving research methodologies.
Systematic ‘Repository Mining’ leverages the proposed taxonomy to programmatically identify and analyze research software components across diverse repositories. This process involves parsing metadata and code characteristics – as defined within the taxonomy’s categorization scheme – to build a searchable index of functionality, dependencies, and attributes. The resulting data enables quantitative analysis of the research software ecosystem, facilitating the identification of redundant tools, gaps in functionality, and potential opportunities for code reuse and collaboration. Automated extraction and categorization, guided by the taxonomy, significantly reduce the manual effort required for comprehensive ecosystem assessment and promotes a more data-driven approach to research software development and curation.
Validating the Framework: Scoping Review and the RSE Corpus
A scoping review of relevant literature was undertaken to establish the validity of the taxonomy’s categorization scheme and definitions. This review systematically examined existing research on research software and related classifications to ensure alignment between the proposed taxonomy and established knowledge. The process involved identifying key themes and concepts within the literature and comparing them to the taxonomy’s categories, enabling refinement of definitions and adjustments to the categorization structure as needed. The scoping review served as a crucial step in ensuring the taxonomy’s theoretical grounding and its potential for consistent application in subsequent analysis.
The Research Software Encyclopedia (RSE Corpus) provided the primary dataset for practical application and evaluation of the developed taxonomy. This corpus comprises 6,966 individual entries detailing various research software packages. Each entry contains metadata relevant to software functionality, development practices, and community engagement, allowing for systematic analysis against the taxonomy’s defined categories. The size and breadth of the RSE Corpus facilitated a robust assessment of the taxonomy’s coverage across the research software landscape and enabled quantitative metrics regarding its applicability and effectiveness.
Application of the developed taxonomy to the 6,966 entries within the Research Software Encyclopedia (RSE Corpus) facilitated a quantitative assessment of its practical utility. The OpenSSF Scorecard was successfully computed for 85.2% of the corpus entries, providing a measurable evaluation of research software characteristics. Analysis of the computed scores allowed for the identification of specific areas where the taxonomy’s coverage could be enhanced, and indicated potential gaps in the categorization of existing research software. This data-driven approach ensured the taxonomy’s relevance and effectiveness in representing the landscape of research software.
Assessing the Vulnerabilities: Security Posture and Ecosystem Risk
A comprehensive security analysis was conducted on research software repositories to evaluate their inherent security practices. This assessment utilized tools such as the OpenSSF Scorecard, which provides a standardized metric for evaluating project security posture based on factors like vulnerability scanning, code review processes, and dependency management. By applying these techniques, researchers were able to systematically quantify the security health of a large corpus of software, identifying areas of strength and weakness within the research software ecosystem. The resulting data offers a crucial baseline understanding of security maturity and highlights opportunities for targeted intervention and improvement across the supply chain.
A comprehensive evaluation of 6,966 research software repositories demonstrated a significant correlation between maintenance model and security posture. Projects sustained by a collaborative community exhibited a notably higher median OpenSSF Scorecard score of 3.6, indicating stronger security practices, when contrasted with projects maintained by individual developers, which averaged a score of 2.7. This suggests that distributed development and review processes inherent in community-driven projects foster a more robust approach to identifying and mitigating vulnerabilities, potentially due to broader expertise and increased scrutiny of the codebase. The findings underscore the value of collaborative governance in enhancing the security of research software and highlight a potential risk factor associated with solely individually maintained repositories.
The governance landscape of research software is notably fragmented, with a surprisingly small proportion – just 10.0% – benefiting from the oversight of established communities or foundations. Analysis reveals that research groups and laboratories currently represent the largest single category of actors maintaining these projects, accounting for 28.8% of all entries. This concentration within academic settings suggests a reliance on often-limited resources and potentially inconsistent security practices, as these groups may lack dedicated personnel or expertise in software supply chain security. The prevalence of individually or small-group maintained projects, coupled with limited formal governance, highlights a critical vulnerability within the research software ecosystem and underscores the need for enhanced collaboration and shared responsibility.
The comprehensive security posture assessment of research software repositories revealed significant vulnerabilities potentially impacting the broader scientific supply chain. Analysis indicated a concerning lack of consistent security practices, particularly within individually maintained projects, which generally exhibited lower OpenSSF Scorecard scores compared to those with broader community involvement. This suggests a heightened risk for these projects, potentially leading to compromised code or data integrity. Consequently, the findings informed a series of actionable recommendations focused on fostering greater community governance, encouraging the adoption of standardized security tools and practices, and promoting increased awareness of supply chain vulnerabilities within the research software ecosystem. These improvements aim to fortify the reliability and trustworthiness of scientific outputs reliant on these software components, ultimately bolstering the integrity of research itself.
The pursuit of standardized taxonomies, as detailed in the research regarding research software supply chains, inherently acknowledges the transient nature of all systems. Vinton Cerf observed, “The Internet is not just a network of networks; it’s a reflection of humanity.” This sentiment resonates deeply with the work presented; vulnerabilities aren’t static flaws, but rather emergent properties within a constantly evolving system. The taxonomy itself isn’t a final solution, but a framework for understanding-and gracefully accommodating-the inevitable changes and incidents that mark the maturation of any complex technological endeavor. It’s a recognition that time, as a medium, introduces both errors and the opportunities to refine and secure the system.
What Lies Ahead?
This effort to categorize the research software supply chain, while a necessary step toward measurable security, merely illuminates the inherent temporality of all architectures. The taxonomy itself will, inevitably, require refinement as the landscape shifts – vulnerabilities discovered, tools deprecated, and new dependencies emerge. Every attempt at standardization is, ultimately, a snapshot of a transient system.
The focus now drifts toward the practical challenge of automating the application of this taxonomy at scale. Repository mining, though promising, exposes the limitations of relying on metadata-or its absence. The true cost lies not in identifying known vulnerabilities, but in anticipating those concealed within the unexamined layers of dependencies. Improvements to scoring systems, like the OpenSSF Scorecard, age faster than one can fully understand their implications, creating a perpetual cycle of assessment and reassessment.
The field should expect increasing complexity, not simplification. The research software supply chain isn’t a problem to be solved, but a system to be observed. The goal isn’t to prevent decay, but to understand its patterns-and to build tools that gracefully accommodate the inevitable erosion of security over time.
Original article: https://arxiv.org/pdf/2601.20980.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- All Shadow Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- Best Bows in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- How to Craft the Elegant Carmine Armor in Crimson Desert
- Keeping Large AI Models Connected Through Network Chaos
- One Piece Chapter 1179 Preview: The Real Imu Arrives in Elbaf
2026-02-01 02:09