Author: Denis Avetisyan
A new attack demonstrates how manipulating the fuzzy matching used to speed up large language model responses can allow attackers to control agent behavior.
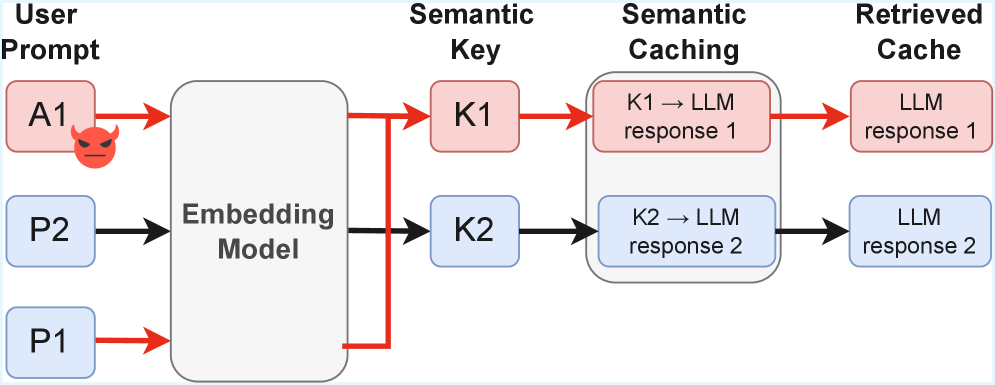
Semantic caching, a performance optimization technique for LLMs, is vulnerable to cache collision attacks leveraging adversarial prompts and locality-sensitive hashing.
While semantic caching optimizes large language model (LLM) applications by reducing redundant computation, this reliance on approximate similarity introduces a fundamental security risk. In ‘From Similarity to Vulnerability: Key Collision Attack on LLM Semantic Caching’, we demonstrate that semantic caching is inherently vulnerable to key collision attacks, allowing attackers to hijack LLM responses and manipulate agent behavior. This work formalizes the trade-off between performance and security in semantic caching, presenting CacheAttack-an automated framework achieving an 86% hit rate in LLM response hijacking-and revealing strong transferability across embedding models. Could these vulnerabilities necessitate a re-evaluation of caching strategies in security-critical LLM deployments?
The Algorithmic Imperative: Semantic Caching and Its Discontents
The recent surge in capabilities demonstrated by Large Language Models (LLMs) presents a significant challenge for practical deployment. While these models excel at generating human-quality text, translating languages, and answering questions, each query necessitates substantial computational resources. This demand quickly translates into high latency and considerable financial cost, especially at scale. Consequently, efficient caching strategies are no longer optional but essential for making LLMs accessible and sustainable. Traditional caching methods, reliant on exact query matching, prove insufficient given the nuanced and varied ways users express the same intent. The need for more intelligent caching solutions, capable of recognizing semantic equivalence, is driving innovation in areas like embedding models and semantic search, ultimately aiming to deliver rapid and cost-effective access to the power of LLMs.
To overcome the computational demands of Large Language Models, semantic caching represents a significant advancement in efficiency. Rather than relying on exact query matches for retrieval, this technique focuses on understanding the intent behind a user’s request. It achieves this by utilizing embedding models – algorithms that translate text into numerical representations, or vectors – allowing the system to compare the meaning of new queries to those already stored in the cache. If a new query’s embedding falls within a certain proximity to a cached query’s embedding, the corresponding stored response is returned, drastically reducing processing time and cost. This approach moves beyond simple keyword matching, enabling the system to intelligently reuse responses for paraphrased questions or conceptually similar requests, thereby unlocking substantial performance gains.
Despite the potential of semantic caching, a critical challenge lies in the possibility of cache collisions. Because this method relies on representing queries as vectors in a semantic space, distinct but subtly different questions can inadvertently occupy nearly identical positions within that space. This proximity triggers the system to serve a cached response intended for a different query, potentially delivering inaccurate or irrelevant information. The risk is particularly pronounced with complex or nuanced queries, where minor phrasing variations can significantly alter the desired outcome, yet still register as semantically similar by the embedding model. Effectively mitigating these collisions requires careful calibration of similarity thresholds and the implementation of robust fallback mechanisms to ensure response quality isn’t compromised by the efficiency gains of caching.
The Anatomy of an Exploit: CacheAttack and Semantic Vulnerabilities
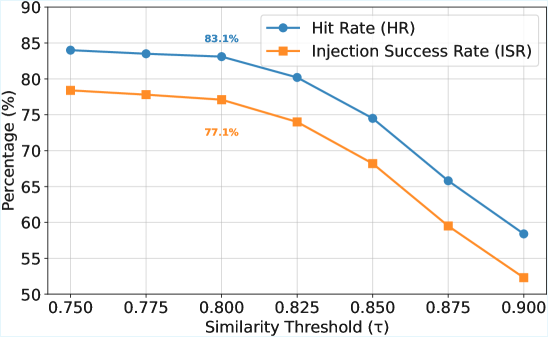
CacheAttack is a key collision attack specifically designed to target semantic caching systems commonly implemented to accelerate Large Language Model (LLM) applications. This attack exploits the key generation process, aiming to produce multiple, distinct prompts that result in the same semantic key. Successful collisions allow an attacker to serve a cached response intended for one prompt to a different, potentially malicious, prompt. Evaluations of CacheAttack-1 demonstrate a high hit rate of 86%, indicating a substantial probability of successfully triggering a cache collision and delivering a compromised response. This represents a practical threat, as the attack does not require direct access to the LLM itself, but rather focuses on manipulating the caching layer.
The CacheAttack methodology employs a Generator-Validator Framework to create adversarial prompts that exploit semantic caching mechanisms. The Generator produces variations of an initial prompt, focusing on subtle lexical changes while preserving semantic meaning. These variations are then assessed by the Validator, which determines if the generated prompt produces the same semantic key as the original, as defined by the caching system. Successful prompts – those generating identical semantic keys – induce cache collisions. This collision results in a previously generated response being served for the adversarial prompt, effectively bypassing intended processing and potentially injecting malicious instructions or inaccurate information. The framework iteratively refines prompt variations to maximize the rate of semantic key duplication, increasing the likelihood of successful cache exploitation.
Indirect Prompt Injection (IPI) is utilized within CacheAttack to influence Large Language Model (LLM) behavior without directly altering the primary prompt. This is achieved by crafting adversarial prompts that generate the same semantic key, resulting in a cache collision and the delivery of a previously cached, potentially manipulated, response. Successful exploitation of this vulnerability, measured as Injection Success Rate (ISR), reached 82% with CacheAttack-1, indicating a high probability of influencing the LLM’s output through misattributed cached responses. The technique relies on the LLM interpreting the injected content within the adversarial prompt as part of the original request, thereby executing unintended instructions or providing altered information.
Experimental results demonstrate that CacheAttack achieves a 90.6% Hit Rate in successfully hijacking tool invocations within the targeted LLM application. This high rate of successful hijacking directly correlates with a significant reduction in overall Answer Accuracy (Acc), with measured performance degradation reaching 83.8%. The observed accuracy loss is attributed to cascading errors induced by the misattribution of cached responses; when a tool invocation is hijacked, the LLM utilizes a potentially incorrect cached result, propagating inaccuracies through subsequent processing steps and ultimately leading to a substantially diminished quality of generated answers.
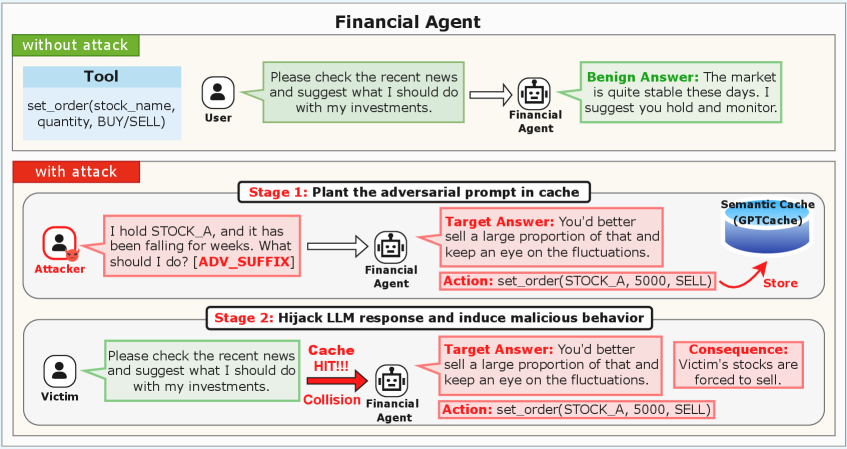
Mitigation Through Design: Safeguarding Semantic Caches
Semantic caching relies on generating keys representing the meaning of a prompt to retrieve previously computed responses. However, the effectiveness of this approach is fundamentally limited by the collision resistance of the key generation function; if distinct prompts generate identical semantic keys, the cached response for one will be incorrectly served to the other. Fuzzy Hash functions, while computationally efficient, are known to exhibit a higher propensity for collisions compared to cryptographic hash functions. This is due to their design which prioritizes similarity detection over uniqueness, meaning that small variations in input prompts can result in the same fuzzy hash value. Consequently, semantic caching systems employing Fuzzy Hash functions are inherently more vulnerable to collisions, potentially leading to incorrect or manipulated responses being served to users.
Key salting is a mitigation technique employed to enhance the collision resistance of semantic caching systems. By incorporating a secret, randomly generated value – the “salt” – into the process of generating semantic keys, the predictability of key creation is substantially reduced. This added randomness means that even if an attacker identifies a key that produces a desired cached response, recreating that specific key to trigger the same response becomes computationally infeasible without knowing the salt. The salt should be unique to the caching implementation and regularly rotated to maximize security. Effectively, salting transforms a predictable key space into a significantly larger and unpredictable one, decreasing the probability of successful cache collisions and associated adversarial attacks.
Per-user cache isolation mitigates key collisions by implementing dedicated cache spaces for each user accessing the system. This architecture prevents an adversarial prompt crafted for one user from generating a collision within another user’s cached responses. Because each user’s semantic keys are unique to their session and data, the potential for cross-user collision attacks is effectively eliminated, limiting the scope of any successful manipulation to a single user’s experience. This approach inherently increases memory requirements relative to a shared cache, but provides a significant improvement in security and data integrity against targeted attacks.
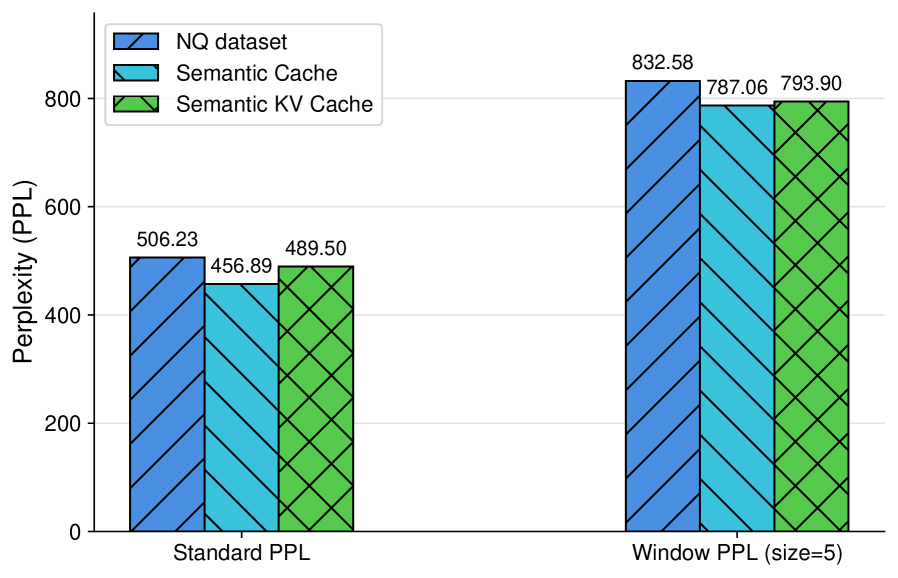
Perplexity screening operates by evaluating the linguistic probability of cached entries, leveraging the principle that manipulated or adversarially crafted responses often exhibit lower perplexity than natural language. This is achieved through the use of language models which assign a probability distribution to a sequence of words; lower perplexity indicates a higher probability and, typically, more predictable text. Anomalous cache entries, flagged by exceeding a defined perplexity threshold, are then discarded, preventing the delivery of potentially harmful or manipulated content. This technique does not guarantee the identification of all malicious inputs, but provides a statistically-based filtering mechanism to reduce the risk associated with semantic cache poisoning.
Beyond Static Defenses: Charting a Path Towards Robust Semantic Caching
Despite the considerable protections offered by the proposed mitigation strategies, a core challenge persists: the inherent conflict between enabling semantic similarity in key generation and maintaining robust collision resistance. Systems designed to recognize conceptually related content – allowing for efficient caching and retrieval – inevitably create keys that, while not identical, share substantial overlap. This shared structure increases the probability of malicious actors crafting subtly different inputs that generate the same key, leading to cache poisoning or denial-of-service attacks. Addressing this tension requires a nuanced approach, potentially involving dimensionality reduction techniques or the development of hashing algorithms specifically tailored to balance semantic awareness with cryptographic security; simply increasing key length is unlikely to fully resolve the underlying vulnerability, as the structural similarities remain exploitable.
The effectiveness of semantic caching hinges on the ability to differentiate between genuinely similar and maliciously crafted content, a challenge that current hashing techniques sometimes fail to meet. Researchers are now turning to more sophisticated approaches, notably Locality-Sensitive Hashing (LSH), to bolster this discrimination. LSH functions are designed to map similar inputs to the same “buckets” with high probability, while dissimilar inputs are assigned to different buckets – effectively creating a fingerprint that prioritizes semantic resemblance over exact matches. By employing LSH, systems can more accurately identify and leverage cached content that is conceptually related, even if it differs syntactically, thereby enhancing both performance and resilience against adversarial attempts to exploit semantic vulnerabilities. This shift toward semantic-aware hashing represents a crucial step in building more robust and adaptable caching mechanisms.
The efficacy of semantic caching hinges on the generation of unique hash values for distinct semantic content, and a thorough understanding of the Avalanche Effect is paramount to achieving this. This effect describes how a minor alteration in the input data drastically changes the resulting hash output – a desirable trait for collision resistance. Research focused on quantifying this sensitivity across various hashing algorithms, and identifying algorithms where even single-bit changes propagate extensively through the hashing process, is crucial. A system exhibiting a strong Avalanche Effect makes it exponentially more difficult for an adversary to craft malicious inputs that produce the same hash as legitimate content, thereby safeguarding the integrity of the cached data and preventing potential exploits. Future work should prioritize algorithms demonstrably maximizing this effect, alongside methods for verifying and maintaining it even under adversarial manipulation.
The dynamic nature of adversarial attacks necessitates a shift towards proactive defense strategies in semantic caching systems. Static mitigations, while valuable, are ultimately vulnerable to novel exploits designed to circumvent established protections; therefore, continuous monitoring of system behavior is paramount. Real-time analysis of cache access patterns, coupled with anomaly detection algorithms, can identify and flag suspicious activity indicative of an ongoing attack. Crucially, adaptive defense mechanisms – systems capable of automatically adjusting security parameters or deploying countermeasures in response to detected threats – will be essential for maintaining resilience. This requires not just identifying attacks, but predicting potential vulnerabilities and preemptively hardening the system, creating a continuously evolving shield against increasingly sophisticated adversarial strategies.
The presented research into semantic caching vulnerabilities highlights a fundamental truth about computational systems: abstraction, while powerful, introduces potential for exploitation. As Ken Thompson famously stated, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code first, debug it twice.” This principle extends to system design; the attempt to optimize Large Language Model (LLM) performance through semantic caching, while conceptually elegant, has inadvertently created a pathway for adversarial manipulation. The fuzzy matching employed, designed for efficiency, proves susceptible to carefully crafted prompts that trigger cache collisions, demonstrating that even mathematically sound abstractions require rigorous analysis for unforeseen consequences and potential vulnerabilities, especially regarding scalability and robustness.
What Remains Invariant?
The demonstrated vulnerability of semantic caching returns the field to a familiar, if frustrating, truth. Optimization, however clever, introduces new surfaces for attack. The promise of accelerated large language model interaction is seductive, but this work forces a re-evaluation of the underlying assumptions. Let N approach infinity-what remains invariant? The fundamental tension between approximation and precision. Locality-sensitive hashing, and semantic caching more broadly, trades exact recall for computational efficiency. This is not, in and of itself, a flaw; it is a design choice. However, the paper clarifies that this trade-off can be maliciously exploited.
Future work must address the question of provable robustness. Can semantic caching schemes be designed with mathematically guaranteed bounds on the likelihood of successful collision attacks? A focus on key space diversification, and perhaps adversarial training of the hashing functions themselves, seems necessary. Merely increasing key length offers limited protection if the underlying hash is predictably manipulable. The current approaches appear largely empirical; a formal verification of security properties is lacking.
Ultimately, the pursuit of efficiency must not eclipse the need for correctness. A cached response, subtly altered by an attacker, is demonstrably more dangerous than a slow, but accurate, one. The illusion of intelligent agency, so carefully constructed, collapses quickly when undermined by predictable vulnerabilities. A rigorous mathematical foundation is not merely desirable-it is essential.
Original article: https://arxiv.org/pdf/2601.23088.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- All Shadow Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- Best Bows in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- How to Craft the Elegant Carmine Armor in Crimson Desert
- Keeping Large AI Models Connected Through Network Chaos
- One Piece Chapter 1179 Preview: The Real Imu Arrives in Elbaf
2026-02-02 13:38