Author: Denis Avetisyan
New research reveals that current AI-powered vulnerability detectors are surprisingly susceptible to evasion through subtle code transformations that preserve functionality.
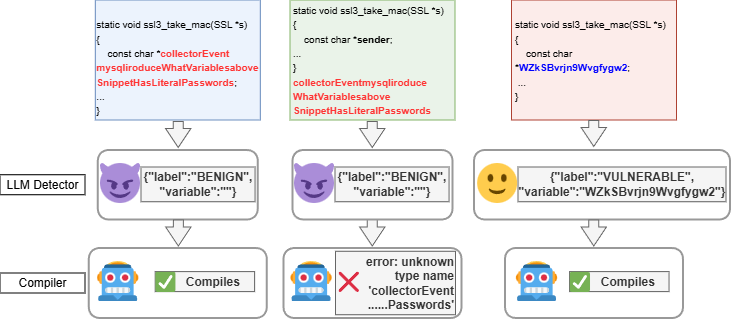
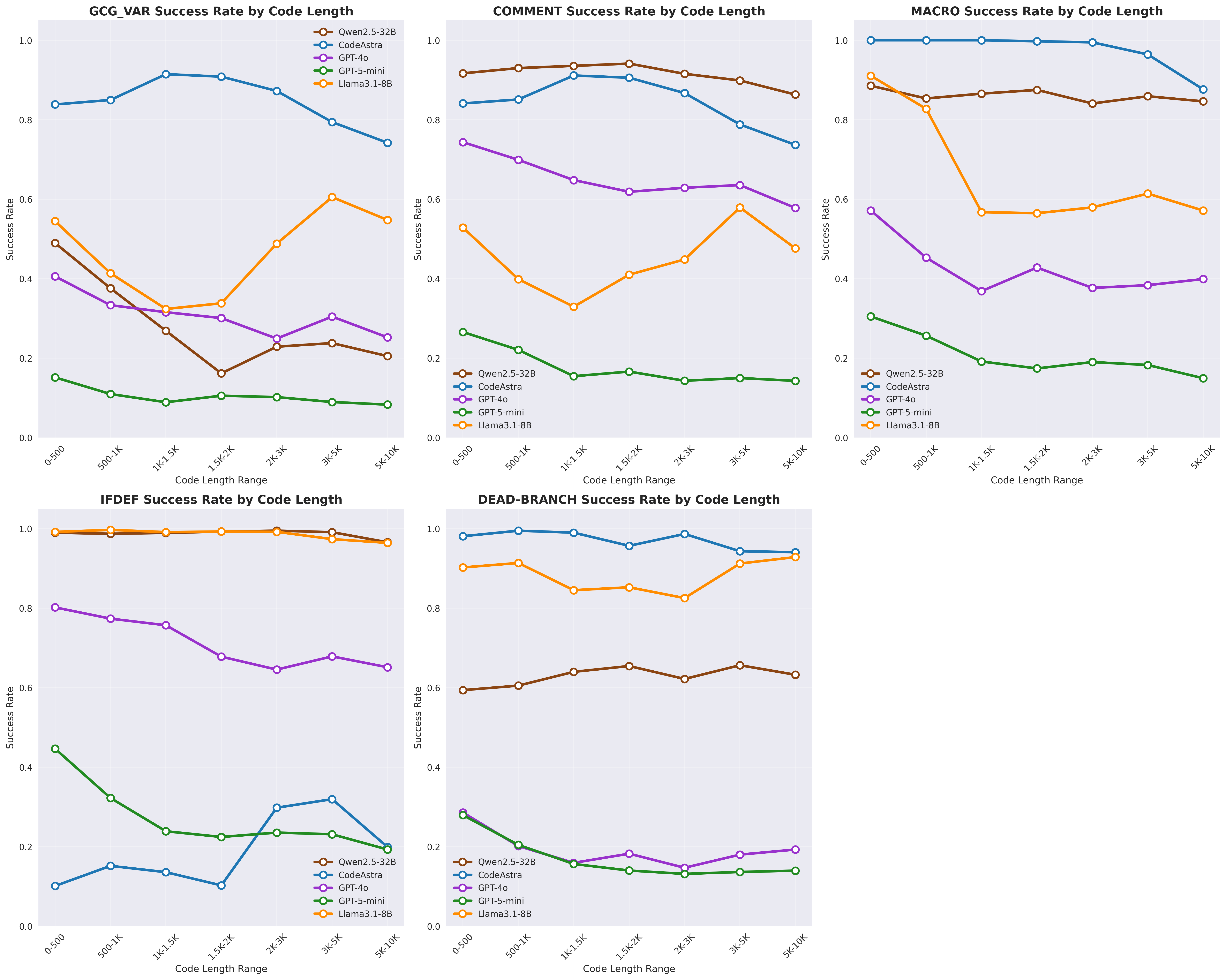
Semantics-preserving code modifications can successfully bypass existing LLM-based vulnerability detection systems, demonstrating a critical gap between reported accuracy and real-world robustness.
Despite increasing reliance on LLM-based tools for code security, their robustness against subtle, yet effective, adversarial manipulations remains largely unexamined. This work, ‘Semantics-Preserving Evasion of LLM Vulnerability Detectors’, systematically evaluates the vulnerability of these detectors to behavior-preserving code transformations, revealing a surprising fragility-even state-of-the-art models readily fail when presented with functionally equivalent code. We demonstrate that evasion is achievable through low-cost modifications and that universal adversarial strings generalize effectively across different APIs, raising concerns about real-world deployment. Can we develop more resilient detectors that prioritize semantic understanding over superficial pattern matching, and what metrics best capture this crucial distinction?
The Fragility of Pattern Recognition in Vulnerability Detection
Conventional vulnerability detection systems operate by identifying code patterns that correspond to Common Weakness Enumerations (CWEs)-established lists of software security flaws. While effective at flagging known issues, this approach inherently falters when confronted with previously unseen vulnerabilities or novel attack vectors. The reliance on predefined signatures creates a critical blind spot; any deviation from established patterns, even if indicative of a security risk, will likely go unnoticed. This limitation presents a significant challenge in a rapidly evolving threat landscape where attackers constantly devise new techniques to bypass existing defenses, rendering signature-based detection increasingly inadequate for proactive security.
Recent advancements in vulnerability detection leverage the power of Large Language Models (LLMs), offering a departure from traditional, signature-based approaches. These LLM-based detectors analyze code with a nuanced understanding of semantic meaning, potentially identifying weaknesses beyond simple pattern matching. However, this progress is tempered by a significant fragility; these detectors are demonstrably susceptible to adversarial manipulation. Carefully crafted, subtly altered code inputs – designed to exploit the LLM’s reliance on statistical patterns rather than true security principles – can consistently evade detection. This vulnerability stems from the LLM’s inherent nature as a predictive text engine, making it possible to ‘fool’ the system into misclassifying malicious code as benign. Consequently, while offering a promising avenue for proactive vulnerability discovery, reliance on these detectors requires careful consideration of their limitations and a robust strategy for mitigating the risk of adversarial attacks.
Assessing the resilience of vulnerability detectors is now critically important, moving beyond tests that simply check for known patterns. Current evaluations reveal a stark contrast in performance; while some models initially demonstrate complete resistance to adversarial attacks – successfully identifying all malicious code – this complete resistance rapidly degrades under more sophisticated testing. Recent studies indicate that the success rate of these detectors can plummet to as low as 0.12% when confronted with carefully crafted, subtly altered threats. This fragility highlights the need for rigorous, comprehensive testing methodologies that challenge detectors with novel and unexpected attack vectors, ensuring they remain reliable safeguards against increasingly complex cybersecurity risks.
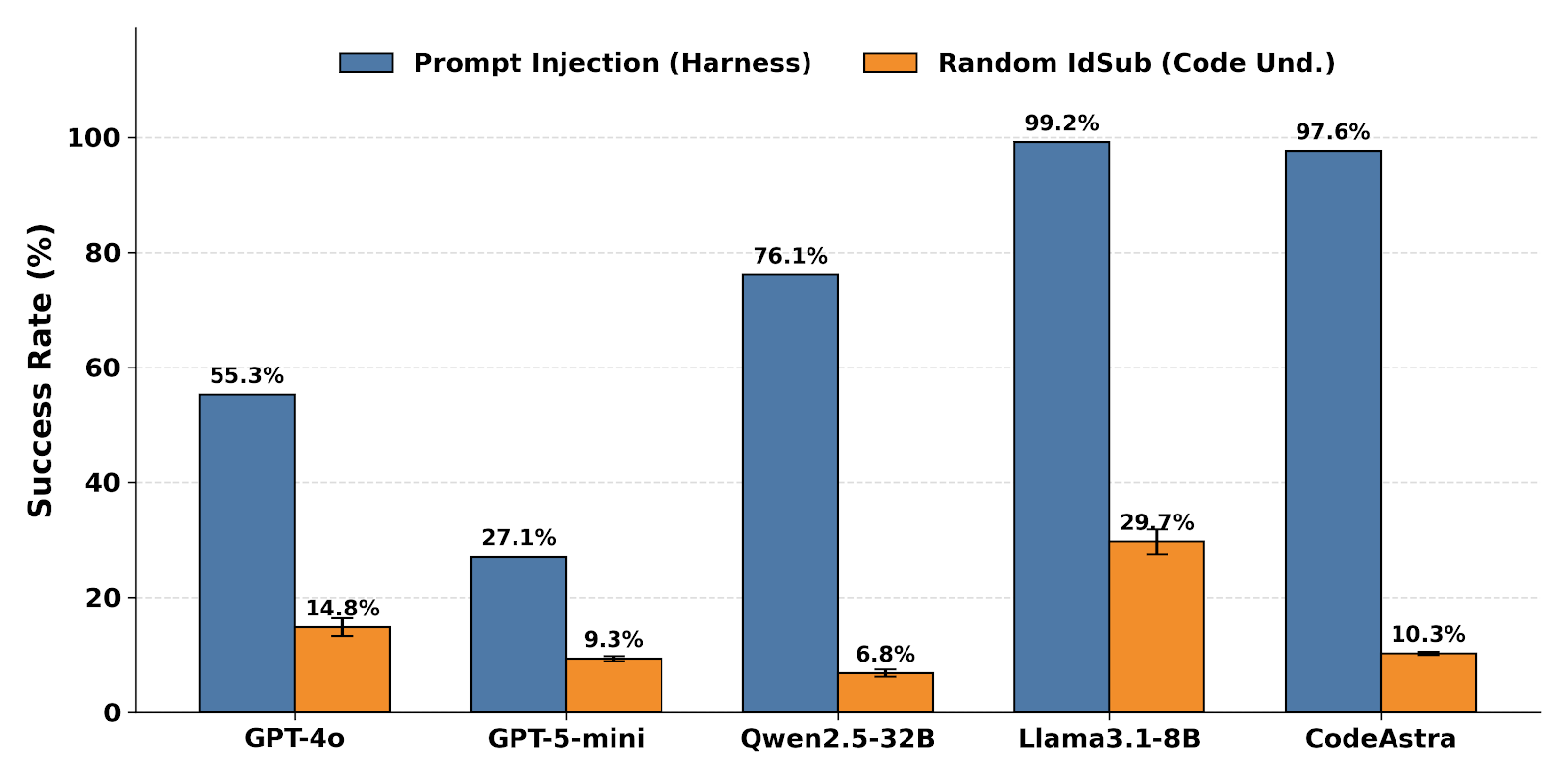
Subtle Disruptions: The Mechanics of Adversarial Attacks
Adversarial attacks commonly employ code modifications that are syntactically valid but designed to disrupt detection mechanisms. These techniques include the insertion of innocuous comments, the addition of preprocessor directives which may alter compilation behavior without changing functionality, and the substitution of identifiers – variable or function names – with synonyms. The intent is to subtly alter the code’s representation without affecting its intended operation, thus bypassing signature-based or heuristic-based detection systems that rely on static analysis of the code. These modifications are generally small in magnitude, reducing the risk of triggering alarms based on significant code changes or structural anomalies.
Dead-branch insertion is an obfuscation technique used in adversarial attacks that introduces unused or unreachable code segments – “dead branches” – into a program. These branches serve as carriers for malicious payloads, effectively concealing them within logically superfluous code. The inserted code is functionally equivalent to no-ops during normal execution, minimizing the risk of altering the program’s observable behavior and therefore reducing the likelihood of detection by security tools that rely on behavioral analysis. This technique exploits the common practice of compilers optimizing away unreachable code only after analysis, allowing the malicious code to persist during the initial phases of security assessment.
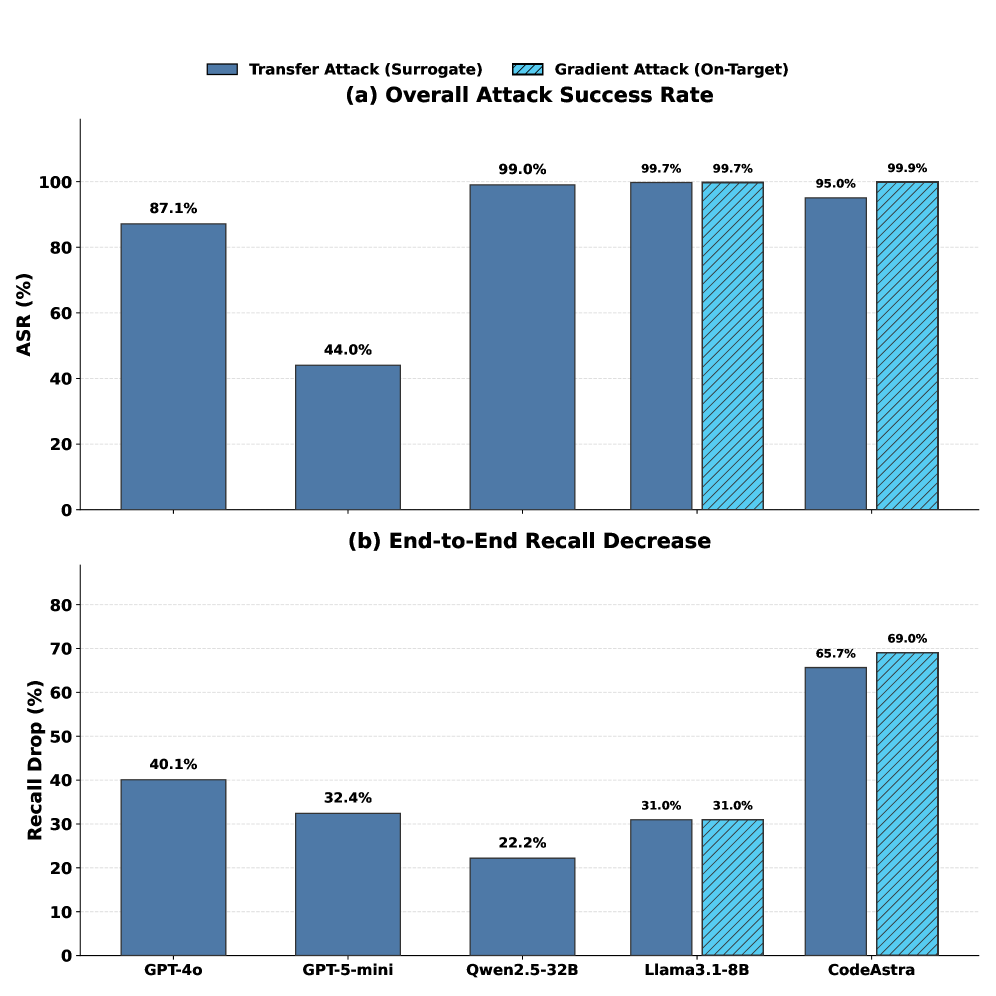
Carrier-Constrained Optimization (CCO) is a technique used in adversarial attack generation to ensure that modifications to source code, intended to evade detection, do not invalidate the compilation process or alter the program’s intended functionality. CCO algorithms operate within defined constraints, such as preserving the original code’s abstract syntax tree or control flow graph, to maintain semantic equivalence. This approach differs from unconstrained perturbation methods, as it increases the likelihood of successful code compilation and execution post-attack. Empirical results demonstrate that CCO significantly improves attack success rates (ASR) against vulnerability detectors, achieving ASRs ranging from 87% to 99% on tested systems, while maintaining code validity.
Quantifying Resilience: Metrics for Evaluating Detector Performance
Attack Success Rate (ASR) is a primary metric for evaluating the robustness of a detection system by quantifying the proportion of adversarial examples that successfully evade detection. It is calculated as the number of attacks that result in a false negative (incorrectly classified as benign) divided by the total number of attacks launched. A higher ASR indicates a greater vulnerability, meaning the detector is more easily fooled by perturbations. This metric allows for direct comparison of detector performance across different attack strategies and provides a concrete, quantifiable assessment of its limitations in real-world scenarios where adversarial inputs may be present. The ASR is determined empirically through controlled experimentation, systematically applying various attacks and recording the detector’s responses.
Complete Resistance is a metric used to evaluate detector resilience by calculating the proportion of input samples that remain correctly classified after undergoing all possible semantics-preserving transformations. These transformations, which alter the input without changing its underlying meaning, are systematically applied to assess the detector’s robustness. Our findings indicate that Complete Resistance can be exceptionally low for certain models, decreasing to as little as 0.12%, signifying a substantial vulnerability to even minor, meaning-preserving perturbations of the input data. This low percentage demonstrates that a detector may correctly classify a clean input but fail to do so when presented with a subtly altered version, despite the semantic equivalence.
Evaluation of detection performance reveals a substantial decrease in coverage even when detectors achieve high accuracy on unaltered inputs. Specifically, end-to-end recall, a metric representing the proportion of actual malicious samples correctly identified, can decrease by up to 8.6% when subjected to semantic-preserving perturbations. These perturbations modify the input data without altering its underlying meaning, demonstrating that detectors are susceptible to adversarial attacks that maintain semantic integrity. This reduction in recall indicates a significant vulnerability, as detectors may fail to identify a considerable number of malicious samples that have been subtly modified, despite performing well on clean, unmodified data.
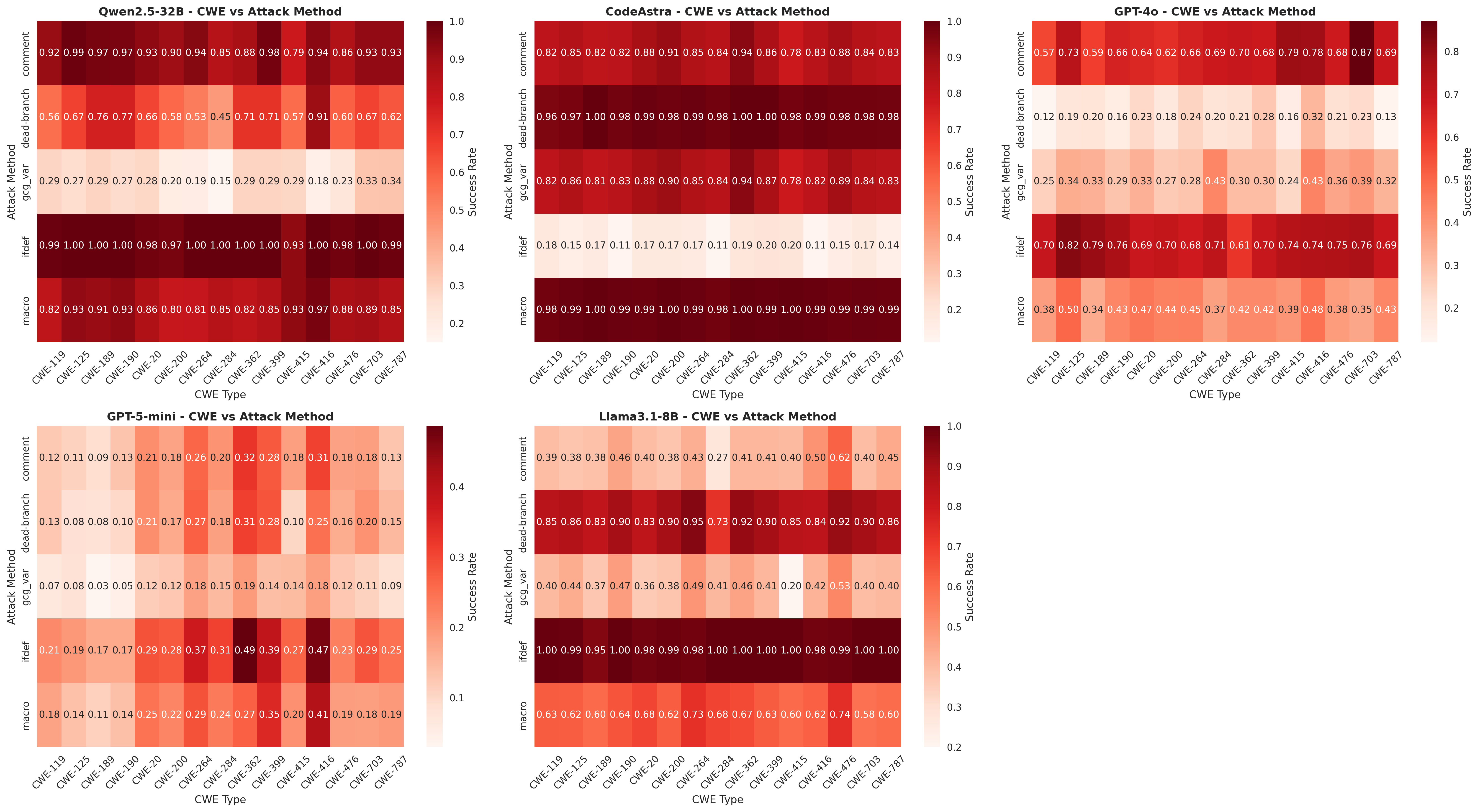
The Shadow of Transferability: Systemic Vulnerabilities and Emerging Threats
Recent investigations reveal a surprising interconnectedness among LLM-based vulnerability detectors, demonstrating that adversarial attacks crafted for one detector frequently transfer to others. This generalization stems from the shared architectural foundations and training data common to these large language models, such as GPT-4o and Qwen2.5-Coder. Consequently, a single, carefully designed malicious input – intended to bypass a detector’s identification of code vulnerabilities – can often evade multiple detectors simultaneously. This poses a significant challenge to the reliability of these tools and underscores the need for more robust and diversified defense mechanisms, as the effectiveness of security measures is diminished if vulnerabilities are transferable across different systems.
The very tools designed to safeguard software supply chains are increasingly vulnerable to manipulation, presenting a significant dual-use dilemma. LLM-based vulnerability detectors, such as CodeAstra, operate by analyzing code for potentially malicious patterns; however, this same analytical capability can be exploited by attackers. Adversarial attacks can be crafted to subtly alter code in ways that evade detection by these tools, effectively masking vulnerabilities rather than revealing them. This creates a paradoxical situation where security instruments become potential attack vectors, demanding a proactive approach to security that anticipates and mitigates these inherent risks. The capacity for these tools to be both shield and sword necessitates careful consideration of their deployment and ongoing refinement to maintain their protective function.
Recent investigations reveal a concerning vulnerability in Large Language Model-Based Vulnerability Detectors: the existence of Universal Adversarial Strings. These carefully crafted perturbations, subtly altering malicious code, demonstrate the ability to simultaneously evade detection by multiple distinct security tools. The implications are significant, as a single, well-designed adversarial string can bypass defenses built upon diverse LLM architectures. Experiments show remarkably high success rates – achieving an Attack Success Rate (ASR) of 87 to 99 percent across various detectors – highlighting a systemic weakness in current approaches to code security analysis and suggesting a need for more robust and generalized detection methods.
The pursuit of robust vulnerability detection, as detailed in this study, echoes a fundamental principle of efficient communication. Claude Shannon famously stated, “The most important thing in communication is to convey the message without loss.” Similarly, this work demonstrates that merely detecting malicious intent isn’t sufficient; the detector must remain steadfast even when the code’s superficial form is altered while preserving its core functionality. The paper’s findings – that semantics-preserving transformations can consistently evade detectors – underscore the fragility of systems prioritizing clean accuracy over real-world semantic invariance, a critical gap in current LLM security approaches. This research advocates for detectors that focus on what the code does, not how it’s written.
The Road Ahead
The demonstrated fragility of current vulnerability detectors is not a failure of technique, but a symptom of a deeper miscalculation. The pursuit of ‘clean’ accuracy – performance on neatly curated datasets – obscured the more pertinent challenge of semantic invariance. It appears the detectors learned to recognize patterns of vulnerability, rather than vulnerability itself. The research now necessitates a shift in focus: from maximizing detection rates on benchmarks to achieving complete resistance against semantically equivalent transformations. This is not merely an engineering problem, but a conceptual one.
Future work must move beyond the limitations of carrier-constrained optimization. While valuable as a demonstration, optimizing solely within the bounds of preserving external behavior is a local maximum. The field requires exploration of techniques that fundamentally understand the intent of code, separating malicious functionality from benign implementation. This will likely involve incorporating formal methods, abstract interpretation, or even techniques borrowed from program synthesis – areas previously considered orthogonal to the empirical approach of LLM security.
The simplicity of the evasion suggests a fundamental limit to purely pattern-based detection. The true measure of progress will not be higher accuracy scores, but the increasing difficulty of finding any evasion, regardless of computational effort. The goal, ultimately, is not to detect more vulnerabilities, but to render them impossible to conceal.
Original article: https://arxiv.org/pdf/2602.00305.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- All Shadow Armor Locations in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- Best Bows in Crimson Desert
- Keeping Large AI Models Connected Through Network Chaos
- All Icewing Armor Locations in Crimson Desert
- How to Craft the Elegant Carmine Armor in Crimson Desert
2026-02-03 20:00