Author: Denis Avetisyan
A new method dramatically improves the performance of large language models when using extremely low-precision weights, opening the door to more accessible and efficient AI.
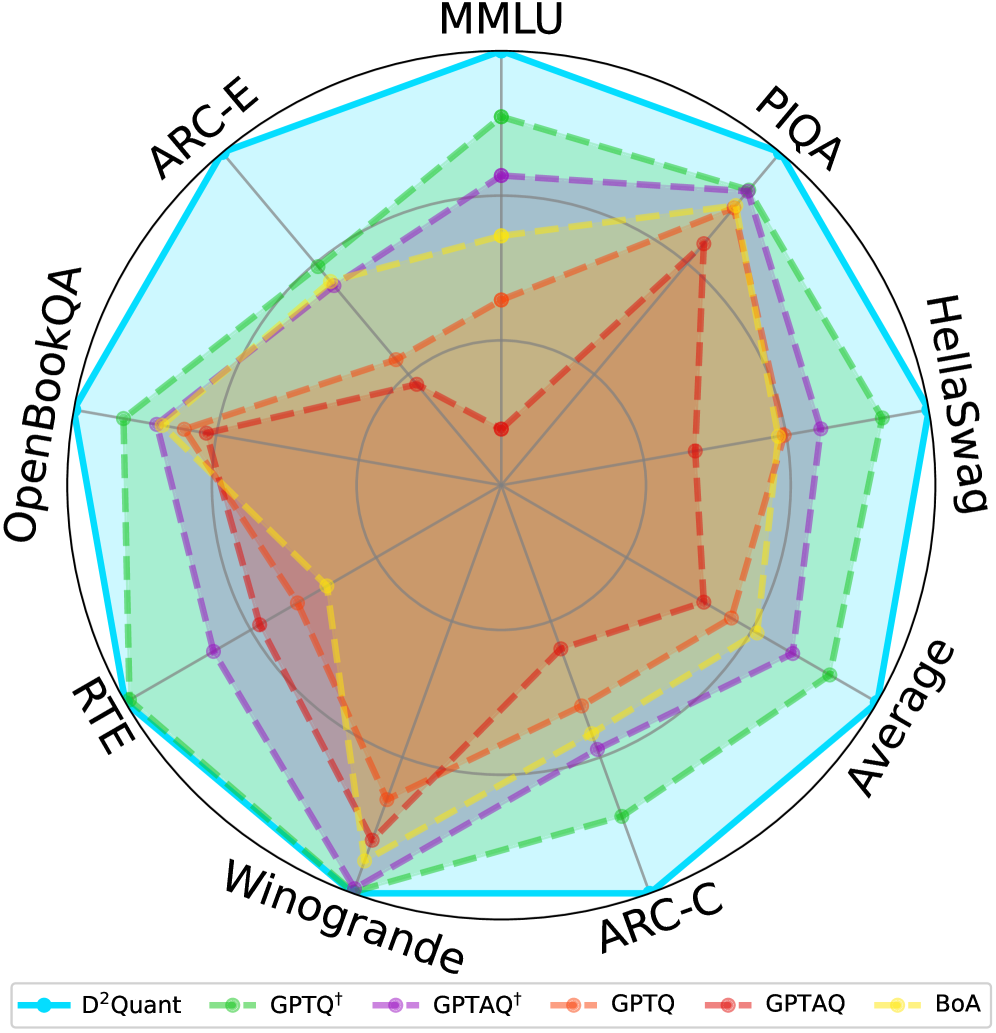
D²Quant addresses activation drift and enables accurate post-training weight quantization to sub-4-bit precision for large language models.
Deploying large language models (LLMs) is increasingly challenging due to their substantial computational and memory demands. This paper introduces ‘D$^2$Quant: Accurate Low-bit Post-Training Weight Quantization for LLMs’, a novel post-training quantization framework designed to mitigate accuracy degradation in extremely low-bit (sub-4-bit) weight-only quantization. D$^2$Quant achieves improved performance by addressing both weight fidelity-through a tailored Dual-Scale Quantizer for down-projection matrices-and activation distribution shifts via a Deviation-Aware Correction integrated within LayerNorm. Can this approach unlock wider LLM deployment on resource-constrained devices without significant performance loss?
The Inevitable Bottleneck: LLM Size and Accessibility
Recent advancements in artificial intelligence have yielded Large Language Models (LLMs) such as LLaMA and Qwen, which exhibit remarkable proficiency in natural language processing tasks. However, this heightened capability comes at a cost: substantial model size. These LLMs often contain billions of parameters, necessitating immense computational resources – memory, processing power, and energy – for both training and inference. Consequently, deploying these models presents significant hurdles, particularly for applications requiring real-time responses or operation on resource-constrained devices like smartphones or edge computing platforms. The sheer scale of these models limits accessibility, hindering wider adoption and preventing seamless integration into everyday technologies, thus creating a pressing need for innovative solutions to reduce their footprint without substantially compromising performance.
The remarkable capabilities of Large Language Models (LLMs) are increasingly hampered by their substantial computational demands. Running these models requires significant processing power and memory, creating barriers to widespread accessibility and practical deployment. This limitation impacts not only individual users but also organizations seeking to integrate LLMs into scalable applications. Consequently, research is heavily focused on model compression techniques – methods designed to reduce the size and computational footprint of LLMs without drastically sacrificing performance. These techniques range from pruning redundant parameters to employing knowledge distillation and, crucially, quantization, all aimed at enabling efficient inference on resource-constrained hardware and facilitating broader adoption of this powerful technology.
Conventional methods for shrinking large language models (LLMs) frequently involve pruning weights or reducing precision, actions that often come at the cost of accuracy and nuanced understanding. While these techniques successfully decrease model size and computational demands, they can lead to a noticeable decline in performance on complex tasks. This trade-off between efficiency and capability has spurred significant research into quantization, a process that aims to represent model weights using fewer bits without substantial information loss. By intelligently minimizing the degradation of critical data, quantization offers a promising pathway to deploy powerful LLMs on resource-constrained devices and broaden their accessibility without sacrificing the quality of generated text or analytical insights. The focus is no longer simply on reducing size, but on maintaining performance despite size reduction.
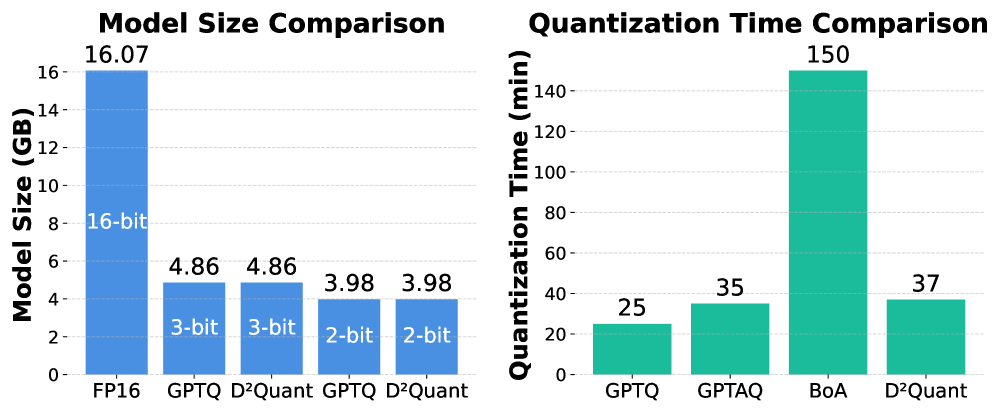
Post-Training Quantization: A Quick Fix, But At What Cost?
Post-Training Quantization (PTQ) represents a model compression technique applied after the standard training process is complete. This methodology allows for the reduction of model size and acceleration of inference without the need for iterative retraining, significantly decreasing the time and resources required for deployment. PTQ achieves compression by converting floating-point weights and activations to lower precision integer representations, typically 8-bit integers. The convenience of PTQ lies in its ability to operate on already trained models, making it readily applicable to existing machine learning pipelines and pre-trained models sourced from various repositories. This streamlined process is particularly advantageous for edge device deployment and resource-constrained environments where model size and computational efficiency are critical.
Weight-only quantization streamlines model compression by focusing solely on reducing the precision of model weights, typically from 32-bit floating point to 8-bit integer representation. This approach simplifies the quantization process compared to methods that quantize both weights and activations, as it eliminates the need for calibration datasets or complex algorithms to determine optimal scaling factors for activations. The reduction in weight precision directly translates to lower memory footprint and reduced computational requirements during inference, as 8-bit integer arithmetic is generally faster and more energy-efficient than floating-point operations on many hardware platforms. This method is particularly advantageous for resource-constrained devices or applications where latency is critical.
Directly quantizing model weights without calibration or adjustment can induce substantial shifts in the distribution of layer activations, a phenomenon known as activation drift. This drift occurs because the reduced precision of quantized weights alters the range and scale of values passed to subsequent layers. Layers sensitive to input ranges, such as those employing ReLU or Sigmoid functions, are particularly vulnerable; even small shifts can push activations into saturation regions, causing information loss and a consequent decline in model accuracy. The magnitude of this drift is dependent on the quantization scheme, bit-width, and the specific architecture of the neural network.
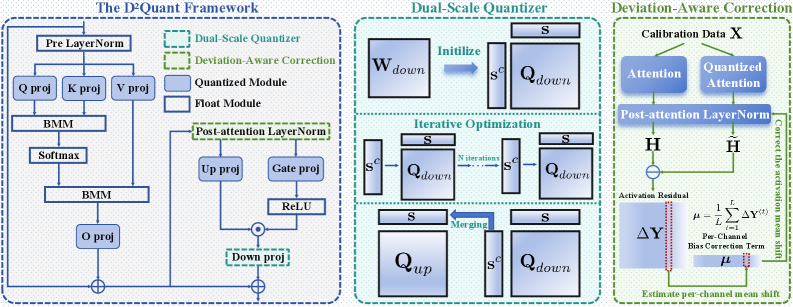
D2Quant: A Band-Aid on a Fundamental Problem?
D2Quant is a post-training quantization (PTQ) framework designed to mitigate the accuracy loss typically associated with aggressive model compression. Extending traditional weight-only quantization, D2Quant focuses on addressing activation drift-the phenomenon where quantized activations deviate significantly from their full-precision counterparts. This drift introduces substantial errors, particularly in deeper layers. The framework incorporates novel techniques to stabilize activations during quantization, enabling higher compression rates without significant performance degradation. By specifically targeting and correcting activation drift, D2Quant achieves improved accuracy compared to standard PTQ methods, particularly when applied to large language models and other complex neural network architectures.
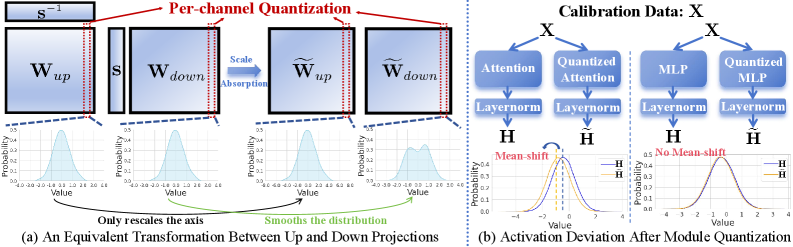
The Dual-Scale Quantizer mitigates information loss during weight-only quantization by applying distinct quantization strategies to down-projection matrices. These matrices, frequently observed in transformer architectures, exhibit heightened sensitivity to quantization due to their role in dimensionality reduction. The framework addresses this by employing a finer quantization scale – utilizing a lower bitwidth – for these specific matrices while maintaining a coarser scale for other weight tensors. This targeted approach preserves critical information within the down-projection layers, minimizing performance degradation that typically accompanies aggressive quantization of such components. The method focuses on retaining representational capacity where it is most crucial for maintaining model accuracy during compression.
Deviation-Aware Correction mitigates accuracy loss caused by quantization-induced drift in neural network activations by directly adjusting LayerNorm parameters. This technique operates by measuring the Signal-to-Noise Ratio (SNR) of activations post-quantization; a decrease in SNR indicates increased drift. A lightweight correction term, calculated based on the observed SNR deviation, is then injected into the LayerNorm scale and bias. This correction dynamically adapts to the level of drift present in each layer, effectively re-centering and re-scaling activations to maintain representational fidelity without significantly increasing model complexity or inference cost. The method focuses specifically on LayerNorm as it is a common source of drift when combined with weight-only quantization.
Performance Gains and the Illusion of Progress
D2Quant establishes new benchmarks in large language model compression, demonstrably achieving superior performance to existing methods without compromising accuracy on widely used language modeling datasets. Evaluations on both WikiText-2 and C4 reveal that D2Quant consistently surpasses previous state-of-the-art techniques in maintaining low perplexity – a key metric for gauging a model’s predictive ability. This advancement isn’t merely incremental; the compression achieved allows for significant reductions in model size, promising more efficient deployment and reduced computational costs without sacrificing the quality of generated text or the model’s understanding of language nuances. The implications are substantial, suggesting a pathway towards more accessible and readily deployable large language models.
Evaluations on the Qwen-3-8B language model demonstrate D2Quant’s substantial performance gains, notably achieving a WikiText2 Perplexity of 14.10. This metric, a standard measure of how well a language model predicts a sample of text, signifies a marked improvement over the performance of GPTQ. Lower perplexity scores indicate better predictive power and, consequently, a more accurate and coherent language model; D2Quant’s result establishes it as a leading approach in achieving high-fidelity language modeling even with reduced precision, paving the way for more efficient and accessible natural language processing applications.
Evaluations on the Qwen-3-8B language model demonstrate D2Quant’s capacity to significantly refine language modeling performance, achieving a C4 Perplexity of 25.96. This represents a substantial advancement over previous quantization methods, specifically GPTQ, which recorded a C4 Perplexity of 52.02 on the same benchmark. The considerable reduction in perplexity indicates that D2Quant preserves a greater degree of predictive accuracy and coherence in generated text, even with a compressed model size, suggesting improved efficiency in capturing the nuances of the C4 dataset-a massive collection of web text-and generating more natural and contextually relevant outputs.
Evaluations demonstrate that D2Quant’s capabilities extend beyond standard language modeling to encompass more nuanced multi-task understanding. Specifically, when assessed on the MMLU benchmark using the Qwen-3-32B model, D2Quant achieved an accuracy of 64.56. This represents a substantial improvement of +3.35 over the performance of GPTQ on the same benchmark and model, indicating a significant advancement in the model’s ability to generalize and perform across a diverse range of tasks requiring complex reasoning and knowledge application. This heightened accuracy suggests D2Quant not only compresses models effectively but also preserves – and potentially enhances – their cognitive abilities.
Evaluations on the LLaMA-3.1-8B model demonstrate D2Quant’s significant performance improvements in natural language processing tasks. The system achieves an average zero-shot accuracy of 51.04, representing a substantial 6.99 point gain over the GPTQ baseline. This indicates a heightened ability to generalize and perform well on unseen data without task-specific training. Furthermore, D2Quant attains a WikiText2 Perplexity of 11.54 on this model, showcasing its capacity to predict language sequences with greater precision and fluency. These results collectively highlight D2Quant’s effectiveness in enhancing both the accuracy and linguistic quality of language models like LLaMA-3.1-8B.
Evaluations on the LLaMA-3.1-8B model demonstrate D2Quant’s capacity to significantly refine language modeling performance, achieving a C4 Perplexity of 27.19. This metric, indicative of a model’s ability to predict a sample of text, highlights a substantial improvement in D2Quant’s predictive power when applied to this widely-used language model. The reduced perplexity suggests that D2Quant not only compresses the model effectively but also preserves-and potentially enhances-its understanding and generation of coherent text, paving the way for more nuanced and accurate natural language processing applications.
The development of D2Quant represents a significant stride towards broader accessibility of large language models. By substantially reducing the computational demands of these models without compromising performance, it facilitates their deployment on devices with limited resources – such as smartphones, embedded systems, and edge computing platforms. This democratization of advanced natural language processing capabilities extends the benefits of LLMs beyond specialized research labs and data centers, enabling a wider range of applications and users to leverage their power for tasks like personalized assistance, localized content creation, and real-time language translation, ultimately fostering innovation and inclusivity within the field.
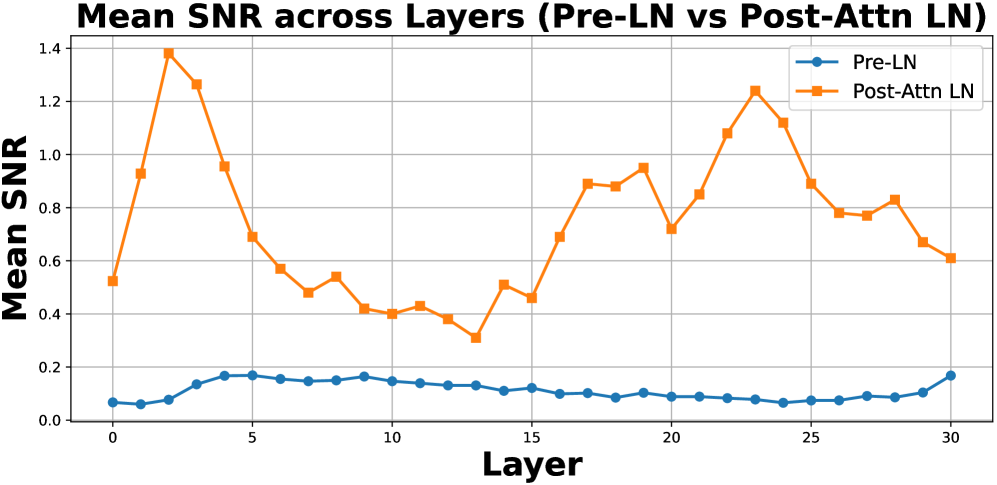
The pursuit of ever-smaller models, as demonstrated by D$^2$Quant’s exploration of sub-4-bit precision, feels less like innovation and more like delayed technical debt. This paper attempts to mitigate ‘activation drift’ through dual-scale quantization and LayerNorm correction – essentially, elaborate bandages on a fundamental problem. It’s a testament to the fact that theoretical gains rarely survive contact with production data. As Brian Kernighan observed, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” The elegance of reduced precision is quickly overshadowed by the brute force required to keep things functioning, proving that if code looks perfect, no one has deployed it yet.
What’s Next?
The pursuit of ever-smaller models, as exemplified by this work, feels…familiar. It always begins with elegant math and benchmark scores. The inevitable follows: production environments, real-world data drifts, and the slow realization that what worked in the lab is now a debugging nightmare. They’ll call it ‘quantization-induced hallucinations’ and raise funding, naturally. This D2Quant approach, while a clever attempt to stave off the inevitable performance cliff, is ultimately just delaying the moment the system demands more resources.
The focus on weight-only quantization sidesteps the messiness of activations, but that feels like moving the problem, not solving it. One suspects that future efforts will inevitably circle back to activation functions, and the truly difficult task of making them behave at these absurdly low precisions. The layer normalization correction is a reasonable patch, but it’s a clear signal: the underlying distributions are being warped, and something will break eventually. It always does.
One imagines a future where every LLM deployment includes a dedicated ‘quantization janitor,’ endlessly tweaking parameters and retraining to counteract the accumulating effects of precision loss. The dream of a truly portable, low-bit model feels increasingly distant. It’s a lovely thought experiment, certainly. But this used to be a simple bash script, and now…well, now it’s just another complex system accruing tech debt. Or, as the truly cynical among us would say, emotional debt with commits.
Original article: https://arxiv.org/pdf/2602.02546.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- All Shadow Armor Locations in Crimson Desert
- One Piece Chapter 1180 Release Date And Where To Read
- Marni Laser Helm Location & Upgrade in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- All Icewing Armor Locations in Crimson Desert
- How to Beat Stonewalker Antiquum at the Gate of Truth in Crimson Desert
- Legendary White Lion Necklace Location in Crimson Desert
2026-02-05 04:01