Author: Denis Avetisyan
New research quantifies the minimal performance trade-off inherent in universal vector quantization techniques.
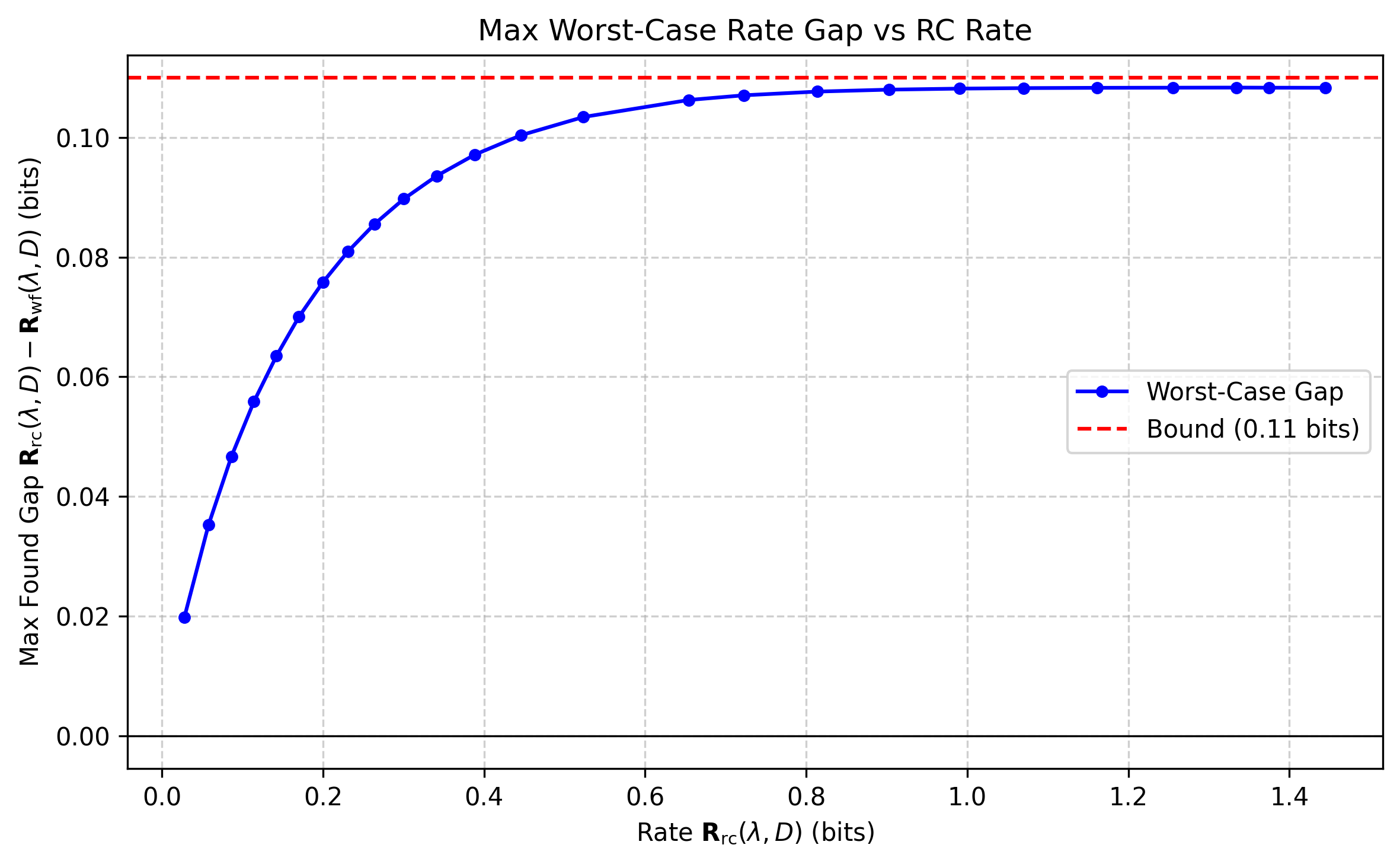
A theoretical analysis demonstrates that the price of achieving universality in vector quantization is bounded by a maximum of 0.11 bits.
Achieving optimal low-precision weight quantization in large language models typically demands tailoring to the specific statistics of input data, a computationally prohibitive requirement. This paper, titled ‘Price of universality in vector quantization is at most 0.11 bit’, addresses this challenge by proving the existence of a universal codebook capable of near-optimal performance across all possible input statistics. Specifically, the authors demonstrate that such a codebook incurs only a marginal performance loss – at most 0.11 bits per dimension – compared to a fully adapted solution. While the proof is non-constructive, this result raises the intriguing possibility of developing a standardized, universally effective low-precision storage format for neural network weights – but how might one actually construct such a codebook?
Decoding the Illusion: LLMs and the Problem of Fabricated Reality
Despite their remarkable ability to generate human-quality text, large language models (LLMs) are prone to “hallucination”-the confident presentation of factually incorrect or entirely fabricated information. This isn’t simply a matter of occasional errors; LLMs can construct plausible-sounding narratives detached from reality, even when prompted with straightforward queries. The root of this issue lies in the models’ training process, which prioritizes statistical patterns and fluency over strict adherence to truth. They excel at predicting the most likely continuation of a text sequence, but lack an inherent mechanism to verify the truthfulness of that continuation. Consequently, LLMs can seamlessly weave falsehoods into otherwise coherent responses, posing a significant challenge to their deployment in applications demanding reliable and accurate information, such as medical diagnosis or legal research.
The propensity of large language models to “hallucinate” – generating plausible but inaccurate information – poses a significant challenge to their deployment in fields demanding precision. Applications such as medical diagnosis, legal research, and financial analysis critically rely on factual correctness; an erroneous statement, even subtly presented, can have substantial consequences. This unreliability isn’t merely a matter of inconvenience, but a fundamental barrier to trust; users are less likely to adopt systems that cannot consistently deliver verifiable information. Consequently, ongoing research prioritizes methods for enhancing the grounding of LLM responses, aiming to minimize these inaccuracies and build confidence in their outputs, especially where real-world implications are significant.
Despite advancements in training and architecture, current techniques for ensuring factual accuracy in large language models remain imperfect. While methods like retrieval-augmented generation and reinforcement learning from human feedback attempt to anchor responses in reliable sources, they often falter when faced with nuanced queries or information gaps. These approaches struggle with consistent grounding, meaning a model might provide accurate information in one instance but confidently fabricate details in another, even when addressing similar topics. This inconsistency stems from the inherent probabilistic nature of LLMs – they predict the most likely continuation of a text sequence, not necessarily the true one. Consequently, a pressing need exists for more robust solutions that move beyond superficial fact-checking and genuinely integrate verifiable knowledge into the core generation process, fostering greater trust and reliability in these increasingly powerful systems.
Anchoring Reality: Retrieval-Augmented Generation as a Countermeasure
Retrieval-Augmented Generation (RAG) addresses the issue of hallucination in Large Language Models (LLMs) by supplementing their pre-trained knowledge with information retrieved from external sources during the response generation process. LLMs, while capable of generating fluent text, are prone to fabricating information or providing responses not grounded in factual data. RAG mitigates this by first identifying relevant documents or data points from a designated Knowledge Source – such as a vector database, document repository, or API – based on the user’s query. This retrieved context is then incorporated into the prompt presented to the LLM, effectively providing a factual basis for the generated response and reducing the likelihood of producing unsupported or inaccurate statements.
Retrieval-augmented generation (RAG) functions by first identifying relevant information from external knowledge sources based on a user query. This retrieved context is then incorporated directly into the prompt presented to the large language model (LLM). By providing the LLM with specific, verifiable data as part of its input, RAG reduces the likelihood of generating responses based solely on the LLM’s pre-trained parameters and mitigates the production of factually incorrect or unsupported statements. The LLM then uses this augmented prompt to formulate its response, effectively grounding its output in external evidence rather than relying on potentially inaccurate internal knowledge.
The performance of Retrieval-Augmented Generation (RAG) systems is directly correlated with the efficiency of knowledge source storage and retrieval mechanisms. Robust architectural solutions are required to manage potentially large volumes of data, necessitating consideration of data structures like vector databases which enable semantic search and efficient similarity matching. Effective indexing strategies, optimized for both speed and scalability, are crucial for minimizing retrieval latency. Furthermore, the architecture must support frequent updates to the knowledge source without significant performance degradation, and handle diverse data formats effectively. Considerations include choosing appropriate embedding models to represent knowledge, and implementing caching layers to reduce redundant database queries.
The Architecture of Meaning: Vector Databases and Embedding Models
Vector databases are purpose-built for storing and efficiently querying high-dimensional vector embeddings, which are numerical representations of data derived from models like those used in Retrieval-Augmented Generation (RAG) systems. Unlike traditional databases optimized for exact match searches, vector databases utilize approximate nearest neighbor (ANN) algorithms to identify vectors that are semantically similar to a query vector, even if there’s no direct keyword overlap. This capability is achieved by indexing the vectors in a way that allows for rapid similarity calculations based on distance metrics such as cosine similarity or Euclidean distance. The database returns results based on these similarity scores, enabling RAG systems to retrieve relevant information based on the meaning of the query rather than simply matching keywords, thereby significantly improving the quality and relevance of generated responses.
Embedding models are a core component of semantic search, functioning by transforming text data – whether queries or documents – into numerical vector representations. These vectors capture the semantic meaning of the text, placing similar concepts closer together in a multi-dimensional vector space. This allows a vector database to perform similarity searches based on meaning rather than exact keyword matches; a query for “best running shoes” will return results discussing “comfortable athletic footwear” even without those specific keywords. The models utilize machine learning techniques, often based on transformer architectures, to analyze contextual relationships within the text and generate these vectors, enabling the identification of relevant information based on conceptual similarity.
Traditional keyword-based search relies on exact matches between query terms and indexed content, leading to missed results when semantic meaning differs or synonyms are used. Vector-based retrieval, conversely, assesses the semantic similarity between the query and the content using vector embeddings. This allows for the identification of relevant documents even without keyword overlap, increasing recall. Furthermore, optimized vector databases employ approximate nearest neighbor (ANN) search algorithms, drastically reducing search latency compared to the linear scans often required by keyword-based systems, particularly within large datasets. Benchmarks demonstrate that vector search can achieve orders of magnitude faster retrieval times with improved precision, especially for complex or nuanced queries.
Beyond Accuracy: Measuring the Reliability of RAG Systems
Evaluating Retrieval-Augmented Generation (RAG) systems demands a robust suite of evaluation metrics that move beyond simple accuracy checks. These systems aren’t merely assessed on if they answer correctly, but crucially, how they arrive at that answer. Comprehensive evaluation necessitates quantifying both the relevance of the retrieved context – ensuring the information sourced is pertinent to the query – and the faithfulness of the Large Language Model’s (LLM) response, verifying it doesn’t hallucinate or contradict the provided knowledge. This dual assessment is vital; a system might retrieve highly relevant documents, yet still generate an unfaithful response, or conversely, provide a faithful answer based on irrelevant information. By meticulously measuring these aspects, developers can pinpoint weaknesses in the retrieval or generation stages, iteratively refining RAG systems to deliver trustworthy and well-grounded outputs.
Evaluating Retrieval-Augmented Generation (RAG) systems demands a nuanced approach to measurement, hinging on metrics that dissect the interplay between retrieved information and generated responses. Specifically, Context Relevance assesses whether the retrieved documents actually pertain to the user’s query, while Context Precision determines the proportion of retrieved context that is genuinely useful. Crucially, Answer Relevance gauges if the LLM’s response addresses the query, and Faithfulness – perhaps the most critical metric – verifies that the response is entirely grounded in the provided context, avoiding hallucinations or the introduction of unsupported claims. These interconnected metrics collectively offer a comprehensive evaluation, allowing developers to pinpoint weaknesses in the RAG pipeline and ensure the system consistently delivers accurate, reliable, and knowledge-based answers.
The pursuit of robust Retrieval-Augmented Generation (RAG) systems hinges on the precise quantification of performance metrics; accurate measurement isn’t merely about assigning a score, but fundamentally about driving iterative improvement and building user trust. By meticulously evaluating factors like context relevance and answer faithfulness, developers can pinpoint specific weaknesses within a RAG pipeline – perhaps a flawed retrieval strategy or an LLM prone to hallucination. This granular understanding facilitates targeted optimization, allowing for adjustments to retrieval parameters, prompt engineering, or even the selection of a more appropriate large language model. Consequently, a commitment to rigorous evaluation translates directly into systems capable of delivering not just any response, but responses that are demonstrably grounded in verifiable knowledge, fostering reliability and ultimately, informed decision-making.
The pursuit of efficient data representation, as detailed in the article’s analysis of vector quantization, echoes a fundamental principle of systems understanding: reduction to essential components. One dissects a complex mechanism not to dismantle it, but to grasp its core functionality. This mirrors Tim Bern-Lee’s sentiment: “The Web is more a social creation than a technical one.” The article, focused on minimizing the ‘price of universality’ in data compression, reveals an underlying desire to make information accessible – a distinctly social goal. By rigorously testing the limits of quantization, the research effectively reverse-engineers the boundaries of efficient communication, much like probing the architecture of the web itself.
What’s Next?
Establishing a quantifiable upper bound on the cost of universality-0.11 bits, in this instance-feels less like a final answer and more like a particularly elegant challenge. The immediate temptation is to seek compression schemes dancing ever closer to this theoretical limit, but that misses the point. The true prize isn’t squeezing the last drop of efficiency; it’s understanding why 0.11 bits resists further reduction. What fundamental constraint, lurking within the structure of information itself, dictates this price?
Future work should not prioritize incremental improvements in quantization. Instead, it needs to aggressively probe the boundaries of the assumptions underpinning this result. Are there classes of data for which this bound is demonstrably loose? Can the definition of “universality” be subtly altered to circumvent it? The pursuit of better compression will continue, of course, but it will be driven by the shadow of this new constraint.
Ultimately, the best hack is understanding why it worked. Every patch is a philosophical confession of imperfection. This bound isn’t a ceiling; it’s a map highlighting the contours of our ignorance. The real work begins where the map ends – in the territory of the unknown.
Original article: https://arxiv.org/pdf/2602.05790.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- One Piece Chapter 1180 Release Date And Where To Read
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- All Shadow Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- How to Beat Stonewalker Antiquum at the Gate of Truth in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- Black Sun Shield Location In Crimson Desert (Buried Treasure Quest)
- Re:Zero Season 4 Episode 1 Release Date, Where to Watch
2026-02-07 16:36