Author: Denis Avetisyan
A new framework treats service reliability as code, enabling microservices to dynamically adapt and maintain performance based on defined objectives.
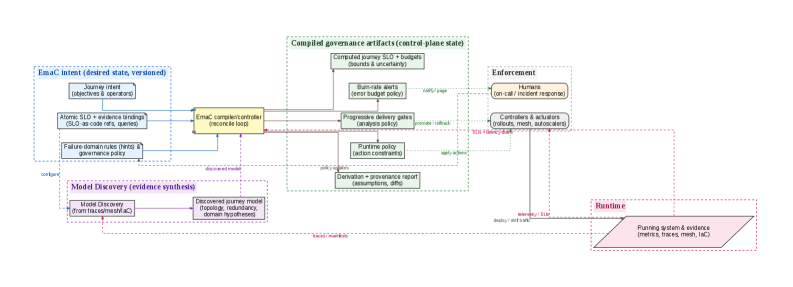
This paper introduces Emergence-as-Code (EmaC), a system for deriving and governing journey-level resilience in microservice architectures through compiled SLOs based on intent, evidence, and compositional semantics.
While per-service reliability is increasingly codified via SLOs, the end-to-end user experience in modern microservice architectures remains vulnerable due to emergent behaviors arising from complex interactions and shared failure domains. This paper introduces Emergence-as-Code for Self-Governing Reliable Systems, a framework that treats journey-level SLOs not as externally maintained targets, but as compiled artifacts derived from declared intent, operational evidence, and explicit compositional semantics. By binding journey objectives to underlying service metrics and telemetry, EmaC enables automated derivation of bounded SLOs and control-plane actions-such as rollout gates and burn-rate alerts-managed via a GitOps workflow. Could this approach finally bridge the gap between individual service reliability and holistic user experience, enabling truly self-governing resilient systems?
The Inevitable Chaos of Distributed Systems
Modern microservice architectures, designed for scalability and resilience, often present a paradox of unpredictability. While each individual service may function reliably in isolation, the intricate web of interactions and shared dependencies between them can give rise to emergent system behaviors. These behaviors, not explicitly programmed or easily anticipated, stem from the complex interplay of numerous components, where a minor disruption in one area can cascade into unexpected consequences across the entire system. This interconnectedness creates a challenge for developers and operators, as traditional debugging methods focused on individual services prove inadequate for diagnosing issues that manifest only at the system level. The sheer volume of potential interaction states makes comprehensive testing difficult, and the dynamic nature of these systems means that previously undetected issues can surface even after thorough validation, demanding new approaches to system observability and control.
Conventional monitoring strategies often concentrate on the performance of individual microservices in isolation, a methodology proving increasingly inadequate in modern, distributed systems. While these tools excel at identifying issues within a specific service, they frequently fail to detect emergent problems arising from the interactions between those services. This creates a critical blind spot, as cascading failures or unexpected bottlenecks impacting an entire end-to-end user journey-such as a complex e-commerce transaction-can go unnoticed until reported by affected customers. The inherent complexity of these systems means that a seemingly healthy collection of individual services doesn’t guarantee a reliable overall experience, highlighting the need for monitoring approaches that prioritize the holistic system behavior rather than isolated component health.
Contemporary systems increasingly demand a move beyond simply reacting to failures and towards actively shaping system behavior to meet predefined goals. Traditional monitoring, focused on individual service health, proves insufficient in the face of emergent issues arising from the intricate web of dependencies within modern architectures. Instead, a proactive approach centers on defining and controlling system-level objectives – such as successful transaction rates or acceptable latency – and then dynamically adjusting system parameters to maintain these objectives. This necessitates sophisticated control mechanisms, often leveraging techniques like automated scaling, traffic shaping, and even self-healing capabilities, to anticipate and prevent issues before they impact the user experience. By shifting the focus from detecting symptoms to managing outcomes, organizations can build more resilient and predictable systems capable of adapting to changing conditions and delivering consistent performance.
Emergence-as-Code: Defining System Behavior
Emergence-as-Code (EmaC) provides operators with a declarative interface for defining system journey behavior through codified specifications. This interface allows for the explicit definition of desired objectives, control flow logic-including branching and looping-and governance policies, all expressed as code. By utilizing a code-based definition, journey characteristics are version controlled, auditable, and repeatable. The codified specifications detail not just what should happen during a journey, but also how the system should react to various conditions and adhere to pre-defined constraints, moving beyond simple configuration to comprehensive behavioral definition.
EmaC facilitates automation by translating high-level operational intent into executable actions predicated on system-level Service Level Objectives (SLOs). This is achieved through the definition of desired behavior as code, allowing the system to dynamically respond to variations in operating conditions without manual intervention. Rather than reacting to incidents, EmaC proactively adjusts system behavior to maintain SLO compliance, effectively preempting potential performance degradation or failures. This proactive adaptation encompasses resource allocation, workload distribution, and configuration adjustments, all governed by the codified intent and continuously evaluated against defined SLOs.
The Emergence-as-Code (EmaC) paradigm leverages a MAPE-K (Monitor, Analyze, Plan, Execute, Knowledge) loop for continuous journey reliability. This loop functions by first monitoring system behavior and relevant metrics; analyzing collected data to identify deviations from defined objectives or predicted outcomes; planning corrective or adaptive actions based on the analysis; executing the planned actions within the system; and finally, knowledge-updating the system’s understanding of the environment and refining future planning based on the results of executed actions. This iterative process allows EmaC to proactively address issues and maintain desired journey behavior without manual intervention, improving overall system stability and predictability.
Traditional systems monitoring identifies issues after they occur, providing reactive alerts. Emergence-as-Code (EmaC) shifts this paradigm by actively influencing system behavior to prevent undesirable outcomes. Instead of passively observing emergent properties, EmaC allows operators to define desired system states and enforce them through automated control loops. This is achieved by codifying objectives and policies that govern how the system responds to changing conditions, effectively steering emergent behavior towards predictable and reliable outcomes aligned with defined Service Level Objectives (SLOs). The result is a proactive system capable of self-regulation and consistent performance, rather than simply reporting on deviations from expected behavior.
Operationalizing EmaC: From Intent to Action
EmaC’s operational logic is predicated on the continuous ingestion and analysis of real-time network telemetry. This data encompasses network topology information, detailing the relationships between network components; routing data, which indicates the paths traffic takes; and performance data, including metrics like latency, throughput, and packet loss. By monitoring these elements, EmaC dynamically adapts its automated actions to address changing network conditions. This responsiveness allows EmaC to mitigate performance degradation, reroute traffic around failures, and optimize resource allocation without manual intervention, ensuring consistent service delivery despite network volatility.
EmaC defines journey execution through the combination of real-time evidence – encompassing network topology, routing information, and performance telemetry – and a set of pre-defined, codified control-flow operators. These operators, representing actions like path selection, resource allocation, and traffic shaping, are applied to the incoming evidence to determine the appropriate course of action for each network journey. The codified nature of these operators ensures repeatability and predictability in EmaC’s response to changing network conditions, while the combination with real-time data allows for dynamic adjustment of the execution path to consistently meet defined service level objectives.
EmaC employs interval bound calculations to quantify uncertainty surrounding key performance indicators (KPIs) and facilitate informed automation. For metrics such as availability and tail latency, EmaC determines both optimistic and pessimistic bounds, representing best-case and worst-case scenarios, respectively. These bounds are not static; they are dynamically calculated based on real-time telemetry and historical data. The resulting intervals provide a range of probable outcomes, enabling EmaC to assess risk and make proactive adjustments to maintain desired service levels. Decision-making processes utilize these intervals to determine when corrective actions are necessary, balancing performance goals with potential disruptions and ensuring resilience within the system.
Evaluations detailed in the paper demonstrate the feasibility of utilizing EmaC to achieve specific performance targets for defined journey objectives. Results indicate a sustained journey objective availability of greater than or equal to 99.9% is achievable through EmaC’s automated control mechanisms. Furthermore, the research confirms the ability to maintain a journey objective p99 latency – representing the 99th percentile of response times – at or below 400 milliseconds. These figures were obtained through simulated and, where possible, live network testing, validating EmaC’s efficacy in meeting stringent performance requirements.
EmaC in Action: Integrating with Modern Tooling
EmaC fundamentally shifts operational management by embracing GitOps principles, treating all infrastructure and application configurations as declarative code stored within a version control system. This approach provides a complete audit trail of every change, fostering transparency and accountability. By managing configurations as code, EmaC enables automated, repeatable deployments, significantly reducing the risk of human error and simplifying rollback procedures. The integration with Git also facilitates collaborative workflows, allowing teams to review and approve changes before they are applied to the live environment, ultimately enhancing system stability and resilience. This codified approach isn’t simply about tracking changes; it’s about building a robust, self-documenting, and easily auditable system for managing complex applications and infrastructure.
EmaC’s intelligent automation relies heavily on a robust foundation of observability, achieved through the integration of tools like Prometheus and OpenTelemetry. These systems continuously collect and transmit crucial telemetry data – metrics, logs, and traces – providing EmaC with real-time insights into system performance and behavior. Prometheus serves as a powerful monitoring and alerting toolkit, while OpenTelemetry standardizes the generation and collection of telemetry, ensuring consistency and interoperability across diverse microservice architectures. This data isn’t merely observed; it directly fuels EmaC’s decision-making processes, enabling it to dynamically adapt to changing conditions, optimize resource allocation, and proactively address potential issues before they impact users. Essentially, EmaC transforms raw telemetry into actionable intelligence, moving beyond simple monitoring to achieve true autonomous operation.
EmaC leverages the power of distributed tracing, facilitated by OpenTelemetry, to gain deep visibility into the lifecycle of every request within a system. This capability moves beyond simple monitoring by reconstructing the entire journey of a request as it traverses multiple services and components. Through OpenTelemetry’s standardized instrumentation, EmaC can pinpoint the precise location of performance bottlenecks – whether it’s a slow database query, a congested network connection, or inefficient code – enabling proactive optimization and ensuring consistently reliable service delivery. By understanding these request flows, EmaC not only identifies problems but also provides the contextual data needed for intelligent remediation and automated adjustments, ultimately enhancing the user experience and reducing operational overhead.
EmaC extends beyond simple monitoring by embracing Service Level Objectives (SLOs) as code, fundamentally shifting how application reliability is managed. Leveraging the OpenSLO standard and tools like Sloth and Pyrra, EmaC allows organizations to define desired service performance directly within their codebase. This approach automates the process of determining when a service is failing to meet its objectives, triggering alerts and initiating remediation actions without manual intervention. By codifying SLOs, teams gain increased transparency, consistency, and a proactive stance toward maintaining application health, ultimately reducing mean time to resolution and bolstering user experience. The system doesn’t just report on problems; it actively works to resolve them based on pre-defined, version-controlled objectives.
The Future of Reliable Journeys with EmaC
Conventional systems often struggle with emergent behavior – unpredictable outcomes arising from complex interactions between components. EmaC addresses this challenge by shifting the focus from simply reacting to failures to anticipating and managing these behaviors before they manifest as disruptions. It achieves this through a comprehensive modeling approach that maps potential interactions and defines desired system states, allowing for preemptive adjustments and resource allocation. This proactive stance not only enhances system reliability by minimizing downtime but also bolsters resilience, enabling the system to gracefully adapt to unforeseen circumstances and maintain consistent performance even under stress. By fundamentally changing how systems are governed, EmaC moves beyond damage control to deliver truly dependable and robust operational experiences.
Traditional systems often demand significant operational resources dedicated to responding to incidents after they occur, creating a cycle of firefighting and reactive fixes. The implementation of EmaC fundamentally alters this paradigm by prioritizing preemptive analysis and mitigation of potential issues. Through continuous monitoring and intelligent prediction of emergent behaviors, EmaC allows teams to address vulnerabilities before they manifest as disruptions. This shift from reactive incident response to proactive problem prevention not only minimizes downtime and service degradation but also substantially reduces the ongoing operational overhead associated with constant troubleshooting and remediation, freeing up valuable resources for innovation and strategic initiatives.
EmaC introduces a fundamentally different approach to system management through its declarative framework. Instead of specifying how a system should behave – a common characteristic of traditional imperative systems – EmaC focuses on defining the desired state. This shift dramatically reduces complexity, as engineers articulate outcomes rather than meticulously crafting step-by-step instructions. Consequently, systems built with EmaC become inherently more transparent and predictable; understanding the overall logic requires grasping the intended state, not tracing intricate control flows. This simplicity extends to maintenance and scaling; modifications are made by adjusting the desired state, with EmaC handling the underlying implementation details. The result is a system that is not only easier to manage but also more adaptable to evolving requirements, fostering continuous innovation and reducing the risk of cascading failures.
The promise of consistently reliable digital journeys is now within reach for organizations leveraging EmaC. By fundamentally shifting the approach to system management, EmaC doesn’t merely address incidents as they arise, but actively prevents them, creating a more stable and predictable experience for end-users. This proactive stance translates directly into heightened customer satisfaction, fostering loyalty and positive brand perception. Beyond the immediate benefits to customer experience, EmaC’s efficiency gains streamline operations, reduce costs associated with downtime and remediation, and ultimately drive improved business outcomes by allowing resources to be focused on innovation and growth rather than constant firefighting.
The pursuit of self-governing systems, as outlined in this paper, feels predictably optimistic. Treating journey SLOs as compiled artifacts – a neat trick, certainly – will inevitably encounter the realities of production. One recalls Donald Davies’ observation: “The real problem is that people build systems they can’t think about.” This isn’t a critique of the Emergence-as-Code framework itself, but a recognition that even elegantly defined compositional semantics will be stressed by unforeseen interactions. The ambition to derive resilience at the journey level is commendable, yet the inherent complexity of microservice architectures suggests that failure domains will always find novel ways to manifest, regardless of how meticulously they’re modeled. It’s a beautiful theory, and one likely to be proven… eventually.
What’s Next?
The proposition of compiling Service Level Objectives-treating desired system behavior as a deployed artifact-feels less like innovation and more like accelerating the inevitable. Each layer of abstraction, each attempt to ‘simplify’ operational complexity, merely shifts the failure modes. The elegance of ‘Emergence-as-Code’ will be tested, predictably, not in contrived examples, but by production’s unique capacity for chaos. The framework assumes a level of intent clarity that rarely survives contact with actual requirements-a clean, declarative specification is a myth.
Future work will inevitably focus on tooling-building systems to manage the complexity that EmaC seeks to formalize. This feels…circular. The real challenge isn’t defining ‘journey SLOs’-it’s acknowledging that failure domains aren’t neatly composable, that interactions between microservices defy elegant prediction. The next iteration won’t be about better compilation; it will be about more sophisticated post-mortem analysis-trying to understand how the system deviated from its compiled intent.
One anticipates a proliferation of ‘SLO diffs’-version control for system failures. The field will chase observability, seeking to instrument everything in a desperate attempt to retroactively justify the abstractions. Documentation, of course, will remain a managerial fiction. CI is the temple-and it prays nothing breaks. The fundamental problem-that systems are complex adaptive phenomena-will not be solved by code, but merely obscured by it.
Original article: https://arxiv.org/pdf/2602.05458.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- One Piece Chapter 1180 Release Date And Where To Read
- All Shadow Armor Locations in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- How to Beat Stonewalker Antiquum at the Gate of Truth in Crimson Desert
- All Icewing Armor Locations in Crimson Desert
- Black Sun Shield Location In Crimson Desert (Buried Treasure Quest)
2026-02-07 23:07