Author: Denis Avetisyan
Researchers have developed a novel technique to predict relationships within complex knowledge graphs, offering improved accuracy and adaptability to unseen data.
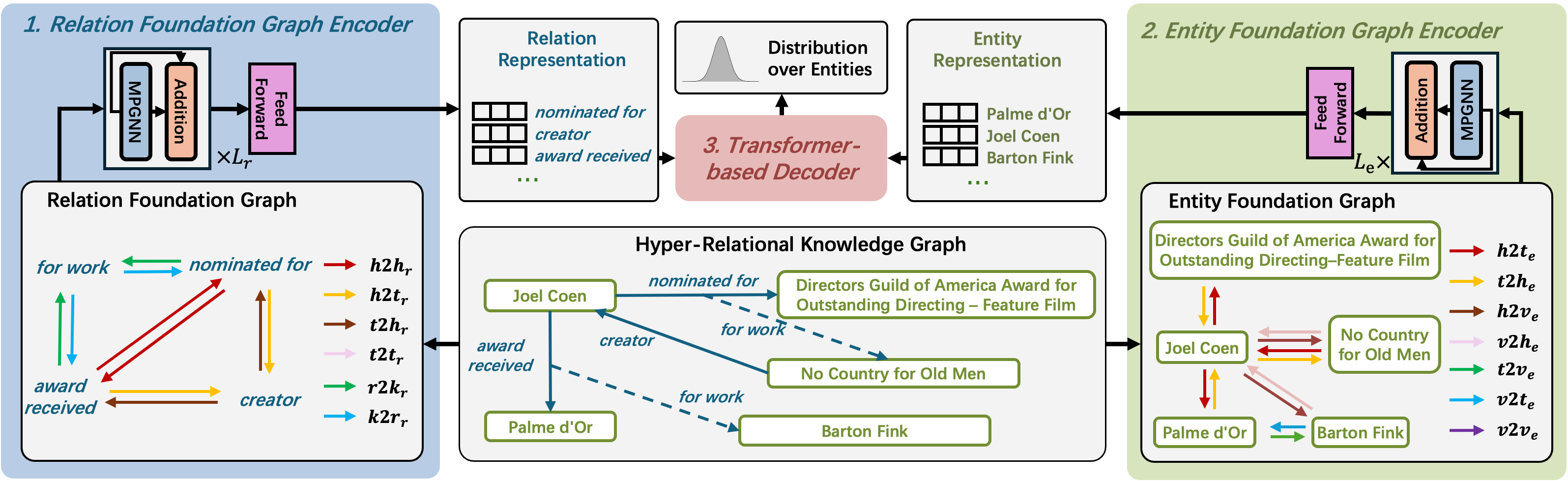
This paper introduces THOR, a fully-inductive link prediction method for hyper-relational knowledge graphs leveraging foundation graphs and neural Bellman-Ford networks.
While knowledge graphs excel at representing relational data, existing link prediction techniques struggle with generalizability to unseen vocabularies and the increasingly complex semantics of hyper-relational facts. To address these limitations, we introduce THOR-an inducTive link prediction technique for Hyper-relational knOwledge gRaphs-which leverages foundation graphs and a transformer decoder to learn transferable structural representations. Our approach achieves state-of-the-art performance, yielding significant improvements over existing rule-based, semi-inductive, and fully-inductive methods across 12 datasets. Can these foundation graphs and inductive reasoning capabilities unlock broader knowledge transfer and reasoning across diverse hyper-relational knowledge domains?
Beyond Simple Facts: The Limits of Triple-Based Knowledge
Conventional knowledge graphs, while powerful tools for organizing information, often fall short in capturing the complexities inherent in real-world knowledge. These graphs typically represent facts as simple triples – subject, predicate, and object – for example, “Paris is the capital of France.” This structure, though effective for basic assertions, lacks the capacity to express qualifiers, context, or uncertainty. Consequently, crucial nuances are lost; the statement about Paris doesn’t convey when it became the capital, or the historical conditions surrounding that transition. This simplification limits the graph’s ability to model ambiguous or multifaceted relationships, hindering its usefulness in tasks requiring a deeper understanding of the information it contains. The limitations of these triple-based systems are becoming increasingly apparent as knowledge graphs are applied to more sophisticated applications, necessitating a move towards more expressive representations.
Traditional knowledge graphs often depict information as simple subject-predicate-object triples – for example, “Paris is the capital of France.” However, this structure struggles to capture the full complexity of real-world knowledge, overlooking crucial qualifiers and context. Hyper-relational knowledge graphs address this limitation by extending these triples with additional relational properties, effectively adding layers of detail. Instead of merely stating a relationship, these graphs can specify how that relationship holds true – “Paris is the official capital of France,” or “Paris was the capital of France during the French Revolution.” This nuanced approach allows for a far more expressive and detailed understanding of entities and their connections, moving beyond simple assertions to capture the conditions, certainty, and source of information surrounding each fact, ultimately enabling more accurate and sophisticated reasoning.
While hyper-relational knowledge graphs offer a significantly more nuanced representation of information than traditional triples, this increased complexity introduces substantial challenges for automated reasoning and link prediction. Existing algorithms, designed to operate on simpler structures, often struggle with the ambiguity and increased dimensionality of hyper-relations. Effectively discerning valid connections requires not only identifying relevant entities but also correctly interpreting the qualifiers that define the precise nature of their relationship-a task demanding more sophisticated computational models. The sheer volume of possible hyper-relations can also lead to data sparsity issues, hindering the ability to generalize from observed patterns. Consequently, developing new techniques capable of navigating and leveraging this richer semantic landscape is crucial to unlock the full potential of hyper-relational knowledge graphs and facilitate accurate, reliable knowledge discovery.

Deconstructing Knowledge: The Foundation Graph Approach
Scaling hyper-relational knowledge reasoning requires decomposing the overall knowledge graph into two foundational components: Entity Foundation Graphs and Relation Foundation Graphs. Entity Foundation Graphs focus on the core attributes and characteristics of individual entities within the knowledge base, establishing a standardized representation of what each entity is. Relation Foundation Graphs, conversely, define the fundamental types of relationships that can exist between entities, detailing how entities connect. This decomposition allows for modularity and efficiency; complex knowledge can be represented as compositions of these foundational elements, reducing redundancy and enabling focused reasoning on specific entity types or relation types without processing the entire graph. The separation facilitates independent optimization and maintenance of entity and relation definitions, contributing to scalability and improved performance in knowledge-driven applications.
Entity Foundation Graphs and Relation Foundation Graphs function by explicitly modeling the inherent structure within individual facts and the relationships between those relationships. Intra-fact dynamics are captured by representing each fact as a standardized subject-predicate-object triple, while inter-relation dynamics are modeled by treating relations themselves as entities with their own properties and connections to other relations – effectively a graph of relations. This decomposition yields a compressed representation of core knowledge because redundant or implied information within complex facts and relation networks is explicitly stated or structurally represented, minimizing storage requirements and computational overhead. The resulting graphs facilitate efficient traversal and reasoning by focusing on these fundamental components rather than the entirety of the knowledge graph.
Decomposing knowledge representation into Entity Foundation Graphs and Relation Foundation Graphs directly addresses computational complexity in knowledge reasoning. Traditional knowledge graphs often suffer from exponential growth in relation types and entity attributes, leading to increased memory requirements and processing time for tasks like link prediction. By isolating core entities and relations into these foundational components, the search space for potential connections is dramatically reduced. This simplification enables more efficient algorithms for identifying missing links, leading to improved accuracy in link prediction while simultaneously decreasing computational demands on both storage and processing capabilities. The focused representation minimizes redundant calculations and allows for scalable inference across large knowledge bases.
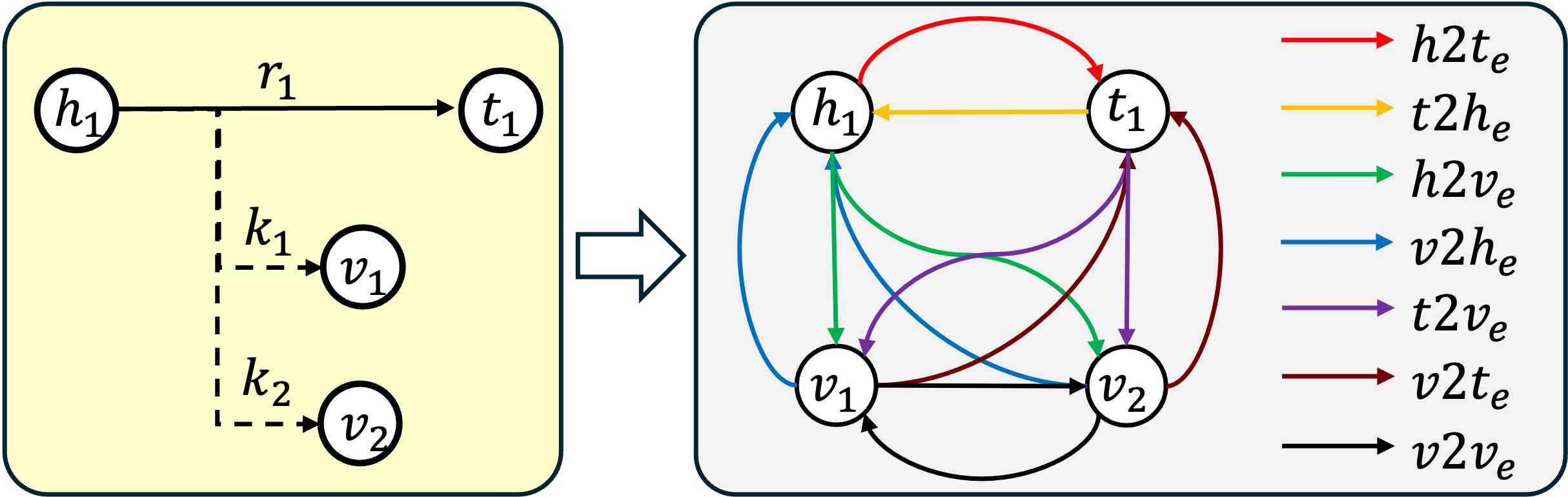
THOR: A Pragmatic Solution for Link Prediction
THOR addresses link prediction in hyper-relational knowledge graphs by utilizing a fully-inductive approach, meaning it can generalize to previously unseen entities and relations without retraining. This is achieved through the construction of two distinct foundation graphs: an Entity Foundation Graph which represents all entities in the knowledge graph, and a Relation Foundation Graph representing all relations. These graphs serve as a foundational representation of the knowledge, allowing the model to reason about entities and relations independently before considering their specific interactions within the main knowledge graph. This separation facilitates generalization and enables predictions for novel combinations of entities and relations not present in the training data.
NBFNet, utilized within THOR, is a graph neural network specifically designed to encode both Entity and Relation Foundation Graphs through path-based message passing. This architecture operates by iteratively aggregating information along paths within the graph, allowing the model to capture complex relational dependencies between entities. The network employs a neighborhood aggregation scheme where each node’s representation is updated based on the features of its neighbors connected by defined paths. This path-based approach contrasts with node-centric methods, enabling NBFNet to explicitly model how information flows through relationships, rather than solely relying on immediate adjacency. The resulting encoded representations capture crucial relational information necessary for downstream link prediction tasks, effectively leveraging the structural knowledge embedded within the foundation graphs.
Following the encoding of Entity and Relation Foundation Graphs via NBFNet, a Transformer Decoder is utilized to predict missing links. This decoder takes the encoded representations as input and learns to map them to a probability distribution over possible relations, effectively scoring potential connections between entities. Crucially, the Transformer architecture enables generalization to previously unseen entities and relations; by learning relational patterns from the foundation graphs, the decoder can infer likely links even when encountering novel combinations. This capability stems from the attention mechanism inherent in Transformers, which allows the model to focus on the most relevant parts of the encoded representations when making predictions, facilitating robust performance on inductive link prediction tasks.
Double equivariance in THOR ensures prediction consistency under both entity and relation permutations. This means that reordering the entities involved in a potential link, or swapping the roles of different relations, will not alter the model’s predicted probability for that link’s existence. Mathematically, this property is crucial for generalization to unseen data, as it enforces that the model learns relational patterns independent of specific entity or relation identifiers. Achieving this requires specific architectural constraints within the NBFNet and Transformer Decoder components, preventing the model from encoding positional biases that would violate equivariance.
Validation: Performance Across Diverse Knowledge Graphs
Evaluation of THOR utilized three hyper-relational knowledge graph datasets: WD20K, WDSPLIT100, and JFFI. WD20K comprises 20,000 entities and relations sourced from Wikidata, providing a substantial scale for assessment. WDSPLIT100 is a partitioned version of Wikidata, designed for evaluating inductive link prediction capabilities. JFFI, the Joint Finance-Fraud Investigation dataset, represents a more specialized knowledge graph focused on financial crime, offering a distinct evaluation context. These datasets collectively provide a diverse testbed for THOR, encompassing variations in scale, domain specificity, and inductive versus transductive settings.
Evaluation of THOR against established inductive link prediction methods demonstrates significant performance gains. Specifically, THOR achieved a 66.1% improvement in Mean Reciprocal Rank (MRR) compared to the highest-performing rule-based technique, a 55.9% improvement over the best semi-inductive method, and a 20.4% improvement over the top-performing fully-inductive approach. These results indicate a consistent and substantial advantage for THOR across different inductive learning paradigms, highlighting its effectiveness in predicting relationships within knowledge graphs.
Evaluation of THOR on cross-domain fully-inductive tasks demonstrates a Mean Reciprocal Rank (MRR) improvement of 32.5% compared to baseline models. This performance metric indicates a substantial gain in the ability to accurately predict missing relationships when applied to knowledge graphs with entities and relations not encountered during training. The observed improvement highlights THOR’s capacity to generalize and effectively perform link prediction in scenarios requiring zero-shot transfer across distinct knowledge domains.
THOR’s architecture demonstrates strong generalization capabilities to previously unseen entities and relations within knowledge graphs. This is crucial for practical deployment in real-world scenarios where knowledge graphs are rarely complete or static; new entities and relations are constantly being added. The model’s performance on tasks requiring inference about these novel elements indicates its adaptability and reduces the need for frequent retraining or manual updates when the knowledge graph evolves. This characteristic distinguishes THOR from methods reliant on pre-defined entity and relation sets, making it suitable for dynamic knowledge bases and applications such as open information extraction and continual learning.
Towards Truly Adaptive Knowledge Systems
THOR’s architecture signifies a notable advancement in the pursuit of knowledge systems capable of both scale and adaptation, moving beyond traditional, static knowledge bases. By grounding its operations in a foundational model, THOR achieves a flexibility previously unavailable, allowing it to incorporate new information and adjust to evolving data landscapes with relative ease. This approach contrasts with systems requiring extensive retraining for even minor updates, positioning THOR as a potentially self-improving entity. The system isn’t merely storing facts; it’s learning to understand relationships within knowledge, which allows for more robust reasoning and a greater capacity to generalize beyond the explicitly stated information – a crucial step towards truly intelligent systems capable of navigating the complexities of real-world knowledge.
Ongoing development prioritizes expanding the foundational architecture to accommodate increasingly intricate and evolving knowledge graphs. Current research investigates methods for seamlessly integrating new information and adapting to shifts in existing knowledge without requiring complete retraining, a crucial step towards true scalability. This includes exploring techniques for dynamic graph construction, allowing the system to learn and refine its understanding of relationships in real-time. The ultimate goal is to create a knowledge system capable of not only storing vast amounts of information, but also of reasoning effectively with it, even as the underlying knowledge landscape changes – effectively mirroring the dynamic nature of real-world information.
The THOR architecture not only achieves state-of-the-art accuracy in knowledge-intensive tasks but also maintains a commendable level of computational efficiency. Empirical evaluations reveal that training THOR on the JFFIv1 dataset requires approximately 104 seconds per epoch, a figure comparable to the 48 seconds per epoch observed with the ULTRA model. Furthermore, during inference, THOR completes tasks in roughly 18 seconds, demonstrating a relatively small increase over ULTRA’s 6 seconds. This balance between performance and speed suggests that THOR presents a viable pathway toward deploying large-scale knowledge systems without prohibitive computational costs, potentially broadening its applicability across diverse resource environments and enabling real-time interactions.
The advancements embodied by this knowledge system architecture extend beyond mere performance metrics, promising substantial progress in several critical application areas. Specifically, improved capabilities in question answering will allow systems to not just retrieve information, but to synthesize it and provide nuanced, contextually relevant responses. Furthermore, enhanced reasoning abilities will enable these systems to draw inferences and solve complex problems that previously required human intervention. Perhaps most significantly, the architecture facilitates a new era of knowledge discovery, allowing automated exploration of vast datasets to identify previously unknown relationships and insights – potentially accelerating scientific breakthroughs and informing decision-making across diverse fields. This confluence of capabilities positions the system as a powerful tool for navigating and interpreting the increasingly complex information landscape.
The pursuit of ever-more-complex knowledge representation, as demonstrated by THOR and its focus on hyper-relational graphs, feels…predictable. It’s the natural escalation. One builds a beautiful, theoretically sound system – in this case, leveraging foundation graphs and neural Bellman-Ford networks for inductive link prediction – and production promptly reveals its limitations. As Claude Shannon observed, “The most important innovation we can make is to communicate effectively.” This paper attempts an elegant communication within the knowledge graph itself, but the real test will be its resilience when faced with the messy, incomplete data reality throws its way. The claim of improved generalizability feels less like a triumph and more like a temporary reprieve from the inevitable accumulation of tech debt.
What’s Next?
The pursuit of ‘inductive’ link prediction, as exemplified by THOR, invariably circles back to the question of what constitutes genuine generalization. A model that performs well on unseen entities and relations is, after all, only untested until it encounters the first genuinely novel combination. The reliance on ‘foundation graphs’ feels less like a solution and more like a deferral of complexity – a beautifully engineered way to push the boundaries of what’s memorized, rather than understood. One anticipates the inevitable entropy as these foundations become saturated with edge cases, each requiring yet another layer of abstraction.
The claim of ‘double equivariance’ is, predictably, a siren song. Elegant on paper, it will likely prove brittle when confronted with the subtle, undocumented biases inherent in any real-world knowledge graph. Production systems rarely respect theoretical symmetries. Furthermore, the current focus on graph structure seems to implicitly assume that relations themselves are static. Any system truly capable of reasoning will need to account for the fact that relationships change – and that predicting those changes is a far more difficult problem than simply inferring existing ones.
Better one well-understood, explicitly-defined knowledge representation than a hundred models chasing phantom generalizability. The field seems determined to build increasingly complex architectures atop inherently flawed data. The logs, as always, will tell the tale.
Original article: https://arxiv.org/pdf/2602.05424.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- One Piece Chapter 1180 Release Date And Where To Read
- All Shadow Armor Locations in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- How to Beat Stonewalker Antiquum at the Gate of Truth in Crimson Desert
- All Icewing Armor Locations in Crimson Desert
- Black Sun Shield Location In Crimson Desert (Buried Treasure Quest)
2026-02-08 02:33