Author: Denis Avetisyan
New research reveals how the internal dynamics of large language models evolve during reasoning, offering insights beyond simple token counting.
Recurrence Quantification Analysis is used to interpret the temporal dynamics of hidden states during Chain-of-Thought reasoning, demonstrating that complexity is encoded in the structure of representations.
Assessing the reasoning processes of large language models remains challenging as simply counting tokens fails to capture the nuances of their internal states. This work, ‘Is my model “mind blurting”? Interpreting the dynamics of reasoning tokens with Recurrence Quantification Analysis (RQA)’, introduces a novel approach-treating token generation as a dynamical system and applying Recurrence Quantification Analysis (RQA) to the resulting latent trajectories. We demonstrate that RQA metrics effectively quantify patterns of repetition and stalling in hidden representations, revealing an 8\% improvement in predicting task complexity beyond response length. Could a deeper understanding of these latent dynamics unlock more robust and interpretable reasoning capabilities in future models?
Unveiling the Limits of Complex Thought
Large Language Models (LLMs) demonstrate a remarkable capacity for text generation, often producing outputs that mimic human-level fluency and creativity. However, the mechanisms driving their apparent reasoning remain largely a “black box”. While these models can successfully navigate complex linguistic tasks, understanding how they arrive at specific conclusions proves challenging. This opacity hinders efforts to systematically improve their reliability and efficiency; without insight into the internal processing, identifying and correcting flawed reasoning becomes a process of trial and error. Consequently, progress towards truly robust and trustworthy artificial intelligence is slowed, as researchers struggle to move beyond superficial performance metrics and gain access to the underlying cognitive architecture of these powerful, yet enigmatic, systems.
Chain-of-Thought prompting, currently a leading technique for eliciting reasoning from Large Language Models, demonstrates diminishing returns as problems increase in difficulty. While initially successful in boosting performance on complex tasks by encouraging step-by-step explanations, this approach frequently encounters limitations with even moderate increases in problem intricacy. Studies reveal that the benefits of CoT plateau, and can even decline, due to the model’s tendency to generate superficially plausible but logically flawed reasoning chains. This suggests that LLMs don’t truly understand the underlying principles of inference, instead relying on pattern matching and statistical associations within their training data. Consequently, the method struggles with novel scenarios or those requiring abstract thought, highlighting a fundamental constraint in how these models currently approach logical problem-solving and raising questions about the scalability of CoT as a reliable reasoning engine.
Large language models, despite achieving state-of-the-art results on many standardized benchmarks, frequently demonstrate a surprising lack of robustness. These models can falter dramatically when presented with inputs that differ only subtly from those used during training, revealing a fragility that belies their apparent competence. This brittle behavior isn’t merely a matter of occasional errors; it suggests the models are often relying on superficial patterns and statistical correlations rather than genuine understanding of the underlying concepts. While a model might successfully solve a mathematical problem presented in one format, a slight rephrasing or change in variable names can lead to incorrect answers, highlighting a dependence on specific phrasing rather than abstract reasoning principles. Such sensitivity indicates that current LLMs may be exceptionally skilled at mimicking intelligence, but lack the deeper, more generalized understanding characteristic of true cognition.
Addressing the shortcomings of current Large Language Models requires moving beyond simply observing what they produce to understanding how they arrive at conclusions. A deeper, mechanistic understanding necessitates probing the internal dynamics of these models – examining the activation patterns, information flow, and representational structures that underpin their reasoning processes. This involves developing novel techniques to dissect the “black box,” potentially through methods like representational similarity analysis or causal tracing, to identify which internal computations correlate with successful or unsuccessful reasoning. Ultimately, such an approach promises to reveal the core limitations of current architectures and guide the development of more robust, reliable, and genuinely intelligent systems capable of true logical inference, rather than merely mimicking it.
Mapping the Dynamics of Thought
Mechanistic interpretability techniques are applied to Large Language Models (LLMs) performing Chain-of-Thought (CoT) reasoning by examining the evolution of their hidden states over time. This approach models the LLM’s internal processing as a dynamical system, where the hidden state at each layer represents the system’s state, and the transformations between layers define its evolution. By treating the sequence of hidden states as a trajectory in a high-dimensional space, we can apply tools from dynamical systems theory to characterize the reasoning process. This allows for quantitative analysis of how information is processed and transformed within the model during inference, moving beyond simply observing the input-output behavior to understanding the internal computational steps.
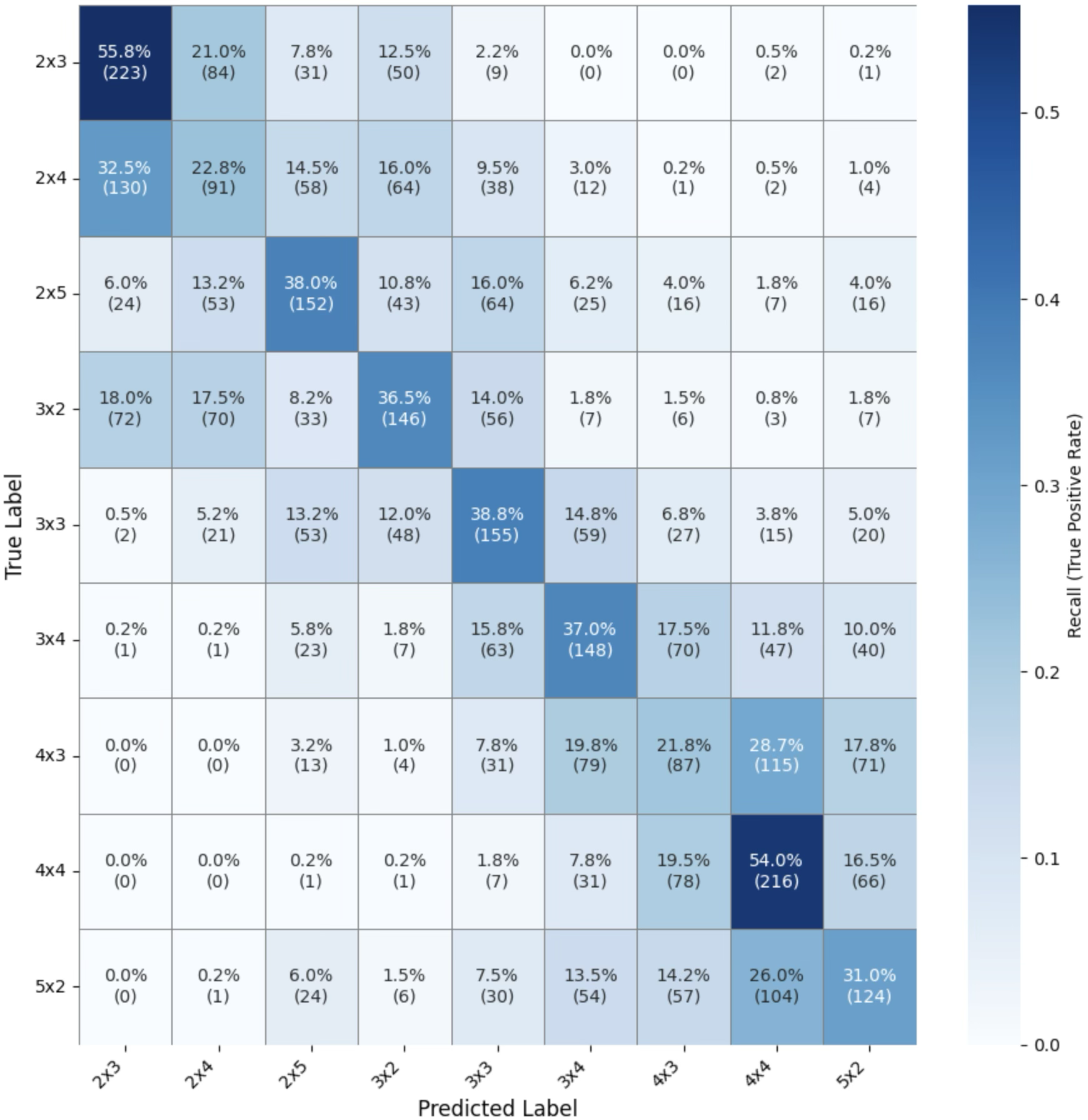
Recurrence Quantification Analysis (RQA) is a technique used to analyze the dynamics of complex systems by reconstructing a state space from time series data and quantifying the recurrence of states within that space. Specifically, RQA calculates metrics such as determinism, laminarity, and recurrence entropy to assess the predictability, stability, and complexity of the system’s trajectory. In the context of Large Language Models (LLMs), RQA is applied to the hidden-state trajectories generated during chain-of-thought reasoning; higher determinism suggests more predictable reasoning, while laminarity indicates the presence of stable, coherent structures in the state space. Variations in these metrics can therefore correlate with the quality and success of the LLM’s reasoning process, providing insights into how internal representations evolve during inference.
Recurrence Quantification Analysis (RQA) yields metrics that directly quantify characteristics of the hidden-state trajectories generated by large language models. Specifically, determinism measures the prevalence of state recurrence, indicating the predictability of the model’s internal dynamics; higher determinism suggests more predictable reasoning. Laminarity quantifies the degree to which recurrent states are organized into banded structures, reflecting the regularity and coherence of the trajectory; higher laminarity implies a more structured internal representation. Finally, recurrence entropy assesses the complexity of the recurrence plot, with lower values indicating simpler, more ordered dynamics, and higher values suggesting increased diversity and potentially exploratory reasoning. These metrics, when analyzed in conjunction, provide a quantifiable profile of the stability and diversity of the model’s internal representations during the inference process.
The final transformer layer within a Large Language Model (LLM) serves as the foundational source for the hidden-state trajectories used in our analysis of Chain-of-Thought (CoT) reasoning. These trajectories, representing the model’s internal processing, are directly derived from the activations of this layer as the model progresses through an inference task. Consequently, focusing analytical techniques, such as Recurrence Quantification Analysis (RQA), on the final transformer layer’s hidden states allows for the characterization of the model’s reasoning dynamics with a high degree of fidelity. Variations in these hidden states, as quantified by RQA metrics, are therefore strongly indicative of the model’s internal representation and stability during the reasoning process, making this layer a critical focal point for mechanistic interpretability efforts.
Quantifying Reasoning Efficiency Across Models
Recurrence Quantification Analysis (RQA) was applied to Large Language Models (LLMs) Deepseek R1 and OpenAI o3 to facilitate a comparative analysis of their reasoning processes. This analysis utilized the ZebraLogic Benchmark, a synthetically generated dataset comprising logic-grid puzzles designed to assess deductive reasoning capabilities. By quantifying the recurrence of state vectors within the LLMs’ internal representations during puzzle solving, RQA provides metrics to characterize the stability, complexity, and predictability of their reasoning dynamics, enabling a direct comparison of how each model approaches and resolves logical challenges presented by the benchmark.
Analysis of Recurrent Quantified Autoregressive (RQA) metrics was performed using a sliding window technique to observe the dynamic changes in reasoning behavior. This involved calculating RQA values over consecutive segments of the problem-solving process – the “window” – and shifting this window incrementally to cover the entire reasoning trajectory. This methodology enabled the capture of both transient fluctuations in reasoning, indicating potential shifts in strategy or increased difficulty, and longer-term trends, revealing overall improvements or deteriorations in reasoning efficiency. The window size and shift increment were determined empirically to balance temporal resolution with statistical stability, allowing for a detailed understanding of how reasoning dynamics evolve during problem-solving.
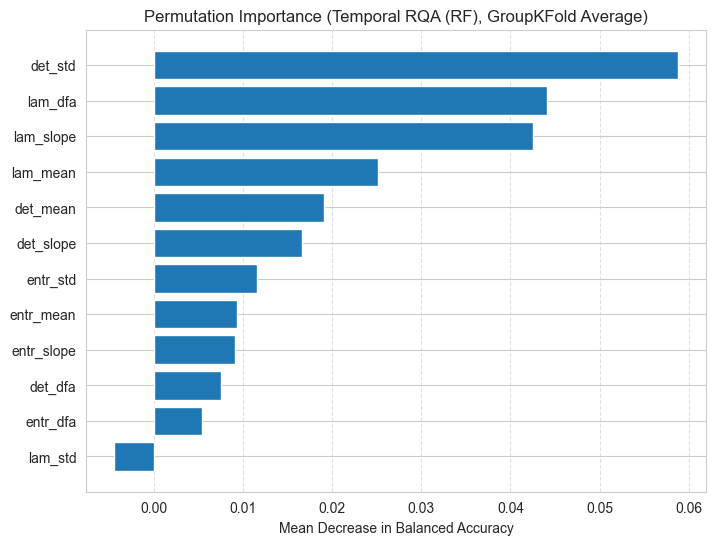
The Deterministic Finite Automaton (DFA) exponent, derived from Recurrence Quantification Analysis (RQA) of sliding window data, quantifies the degree of self-similarity in the temporal evolution of RQA metrics. Specifically, it measures the scaling behavior of recurrence rates, indicating how consistently the model’s reasoning process maintains its characteristics over time. A higher DFA exponent suggests greater stability and predictability in the reasoning trajectory, while a lower exponent indicates more erratic or fluctuating behavior. This metric enables assessment of the internal consistency of a language model’s problem-solving approach, revealing whether reasoning patterns are sustained or prone to divergence as the model progresses through a task.
Evaluation of task complexity classification demonstrates that features derived from Temporal Recurrence Quantification Analysis (RQA) outperform length-based baseline methods. Specifically, models utilizing Temporal RQA achieved an accuracy of 36.9%, representing an 8% improvement over the 29.0% accuracy of the baseline. This performance difference is statistically significant, as indicated by an average p-value of less than 0.005 across 7 out of 8 validation folds, suggesting a consistent and reliable advantage for the Temporal RQA approach.

Toward a Dynamic Understanding of Reasoning
Researchers are investigating the potential of continuous generative frameworks – including Diffusion Models and Flow Matching – to represent and even alter the step-by-step reasoning processes exhibited by large language models. These techniques, traditionally used for generating images and audio, offer a novel approach to modeling ‘Chain-of-Thought’ (CoT) trajectories as continuous data streams. By treating reasoning as a generative process, it becomes possible to not simply evaluate a model’s thought process, but to actively manipulate it – potentially guiding the model towards more accurate or efficient solutions. This framework allows for interpolation and extrapolation of reasoning paths, opening avenues for enhancing problem-solving capabilities and exploring the underlying dynamics of complex thought processes in artificial intelligence.
Beyond traditional metrics like accuracy and response length, information-theoretic approaches provide a nuanced method for evaluating the quality of reasoning processes in large language models. These techniques, rooted in quantifying information gain and uncertainty reduction, offer complementary perspectives by assessing how a model arrives at an answer, not just if it is correct. By analyzing the information exchanged throughout a chain-of-thought trajectory, researchers can gain insights into the efficiency and reliability of the reasoning steps. Measures such as Kullback-Leibler divergence can pinpoint moments of significant information gain or loss, revealing potential bottlenecks or flawed logic within the model’s reasoning process. This allows for a more granular understanding of model performance and facilitates the development of more robust and interpretable reasoning systems, moving beyond simple pass/fail evaluations towards a deeper understanding of cognitive processes within artificial intelligence.
A novel approach to evaluating the quality of reasoning, termed Temporal Reasoning Quality Assessment (RQA), has demonstrated remarkable predictive power. This method achieves an impressive 85.0% accuracy in binary prediction of answer correctness – a figure statistically comparable to the 85.58% accuracy obtained using the simpler metric of response length. This close alignment suggests that Temporal RQA effectively captures key characteristics of successful reasoning trajectories, offering a robust and potentially more nuanced alternative to relying solely on the length of a generated response as an indicator of problem-solving ability. The result highlights the potential for refining automated evaluation of complex reasoning processes beyond superficial textual features.
To rigorously investigate continuous generative frameworks and information-theoretic approaches to reasoning, a substantial dataset was generated utilizing the DeepSeek-Distill-7B-Qwen language model. This model served as a crucial engine for producing diverse and complex reasoning trajectories, allowing researchers to move beyond limited, manually curated datasets. The resulting data facilitated a detailed analysis of how different modeling techniques capture the nuances of thought processes, enabling a refinement of existing reasoning metrics and the development of novel approaches. By leveraging the generative capacity of DeepSeek-Distill-7B-Qwen, the study gained access to a wider spectrum of reasoning patterns, ultimately contributing to a more comprehensive understanding of the dynamics underlying complex problem-solving capabilities in artificial intelligence.
The study meticulously dissects the internal states of large language models, moving beyond superficial metrics like token count to examine the evolving structure of representations during reasoning. This approach aligns with Gauss’s assertion: “If others would think as hard as I do, I would not have so many discoveries.” The research demonstrates that complexity isn’t simply more computation, but a nuanced dynamic embedded within the temporal evolution of hidden states – a principle of elegant efficiency. Recurrence Quantification Analysis provides a lens to view this internal complexity, revealing that meaningful reasoning isn’t about generating lengthy outputs, but about the intricate patterns unfolding within the model’s latent space. It is a refinement of process, not merely an increase in quantity.
Where Do We Go From Here?
The application of Recurrence Quantification Analysis, as demonstrated, shifts the focus from mere token accounting to the underlying structural dynamics of reasoning. This is not merely a technical refinement, but a conceptual realignment. The initial promise of Chain-of-Thought prompting – the elicitation of ‘reasoning’ – implicitly assumed complexity resided in the quantity of steps. What remains, after applying a scalpel like RQA, suggests it is the quality of the state-space trajectory, the evolving relationships within latent representations, that truly signals cognitive effort.
However, the method reveals as much through subtraction as addition. Identifying diminished recurrence rates correlated with increased complexity only highlights the limitations of current metrics. Future work must confront the challenge of defining a null hypothesis for ‘mind blurting’ – what does a genuinely random state-space trajectory look like in a large language model? Without this benchmark, correlation risks masquerading as causation.
Ultimately, the pursuit of ‘reasoning’ in these systems may prove less about recreating human cognition and more about understanding the fundamental principles of dynamical systems themselves. The model isn’t the question; the state-space is the territory. What remains, after the noise is filtered, will dictate the true boundaries of artificial intelligence.
Original article: https://arxiv.org/pdf/2602.06266.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- One Piece Chapter 1180 Release Date And Where To Read
- All Shadow Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- New Avatar: The Last Airbender Movie Leaked Online
- Cassius Morten Armor Set Locations in Crimson Desert
- Grime 2 Map Unlock Guide: Find Seals & Fast Travel
- Euphoria Season 3 Release Date, Episode 1 Time, & Weekly Schedule
- Amber Alert Secrets & CDs In Crime Scene Cleaner Act 2
- All Golden Greed Armor Locations in Crimson Desert
2026-02-10 00:05