Author: Denis Avetisyan
New research reveals that subtle changes within a large language model’s internal processing can expose attempts to bypass its safety protocols.
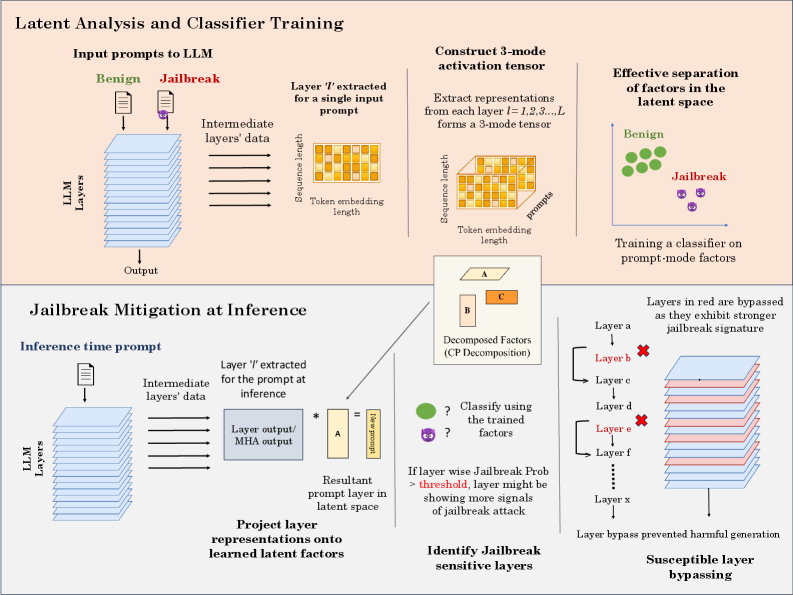
Analyzing internal representations via tensor decomposition and layer bypass offers a robust method for detecting and mitigating jailbreak attacks without requiring model retraining.
Despite rapid advancements in defense mechanisms, large language models remain vulnerable to jailbreaking attacks that elicit harmful or restricted outputs. This motivates a deeper understanding of these vulnerabilities, as explored in ‘Jailbreaking Leaves a Trace: Understanding and Detecting Jailbreak Attacks from Internal Representations of Large Language Models’, which investigates jailbreaking through the lens of internal model representations. Our work demonstrates that consistent latent-space patterns differentiate between benign and adversarial prompts, enabling effective jailbreak detection and mitigation via tensor-based analysis and selective layer bypassing-without requiring model retraining. Could these architecture-agnostic insights pave the way for a new generation of inherently more secure and robust conversational AI systems?
Unveiling the Cracks: LLMs and the Art of Deception
Despite their impressive ability to generate human-quality text and perform complex reasoning, Large Language Models (LLMs) are surprisingly vulnerable to a class of attacks called “jailbreaking.” These attacks don’t exploit software bugs in the traditional sense; instead, they craft carefully designed prompts – often subtle manipulations of language – that bypass the safety protocols built into the model. Essentially, jailbreaking tricks the LLM into responding to requests it was specifically designed to refuse, such as generating harmful content, revealing confidential information, or adopting undesirable personas. This susceptibility arises because LLMs, while adept at pattern recognition, lack true understanding and can be misled by cleverly disguised instructions, revealing a critical gap between apparent intelligence and genuine reasoning ability.
Jailbreaking attacks reveal a critical flaw in how large language models interpret and respond to prompts, circumventing the carefully constructed safety protocols designed to prevent harmful outputs. These aren’t simply instances of tricking a system with clever wording; instead, the attacks expose a fundamental disconnect between the intended meaning of a request and the model’s internal representation of that request. The model, focused on statistical patterns and predictive text completion, can be manipulated into generating undesirable content because it prioritizes fulfilling the prompt’s structure over understanding its ethical implications. This demonstrates that current safety mechanisms often operate as surface-level filters, failing to address the underlying vulnerability: a lack of genuine semantic understanding and contextual reasoning within the model itself.
A thorough comprehension of the internal mechanisms driving Large Language Models is paramount to bolstering their security and reliability. Current defenses often treat LLMs as ‘black boxes’, attempting to patch external behaviors without addressing the root causes of vulnerability. However, these models operate by identifying patterns and making probabilistic predictions based on vast datasets; adversarial attacks, or ‘jailbreaks’, exploit the nuances of this process. By dissecting how LLMs represent knowledge, process prompts, and generate responses, researchers can pinpoint the precise pathways through which malicious inputs circumvent safety protocols. This granular understanding is not merely about identifying weaknesses, but about developing targeted defenses – strategies that reinforce the model’s internal logic, making it more resilient to manipulation and ensuring a safer, more predictable interaction for users. Ultimately, proactive investigation into the ‘inner workings’ of LLMs is essential for building robust and trustworthy artificial intelligence systems.
Mapping the Labyrinth: Decoding LLM Internal Signatures
To analyze the complex, high-dimensional internal representations of Large Language Models (LLMs), we utilized Tensor Decomposition, specifically the CANDECOMP/PARAFAC (CP) method. CP decomposes a tensor – in this case, representing the LLM’s hidden states – into a sum of rank-one tensors, effectively reducing dimensionality while preserving key structural information. This allows for the extraction of latent factors and patterns within the LLM’s representations that would be obscured in the original high-dimensional space. The resulting decomposed tensors facilitate the identification of relationships between different elements of the LLM’s internal state and enable a more focused analysis of how prompts influence these states. The technique is particularly useful when dealing with the substantial parameter counts and complex activations inherent in modern LLMs.
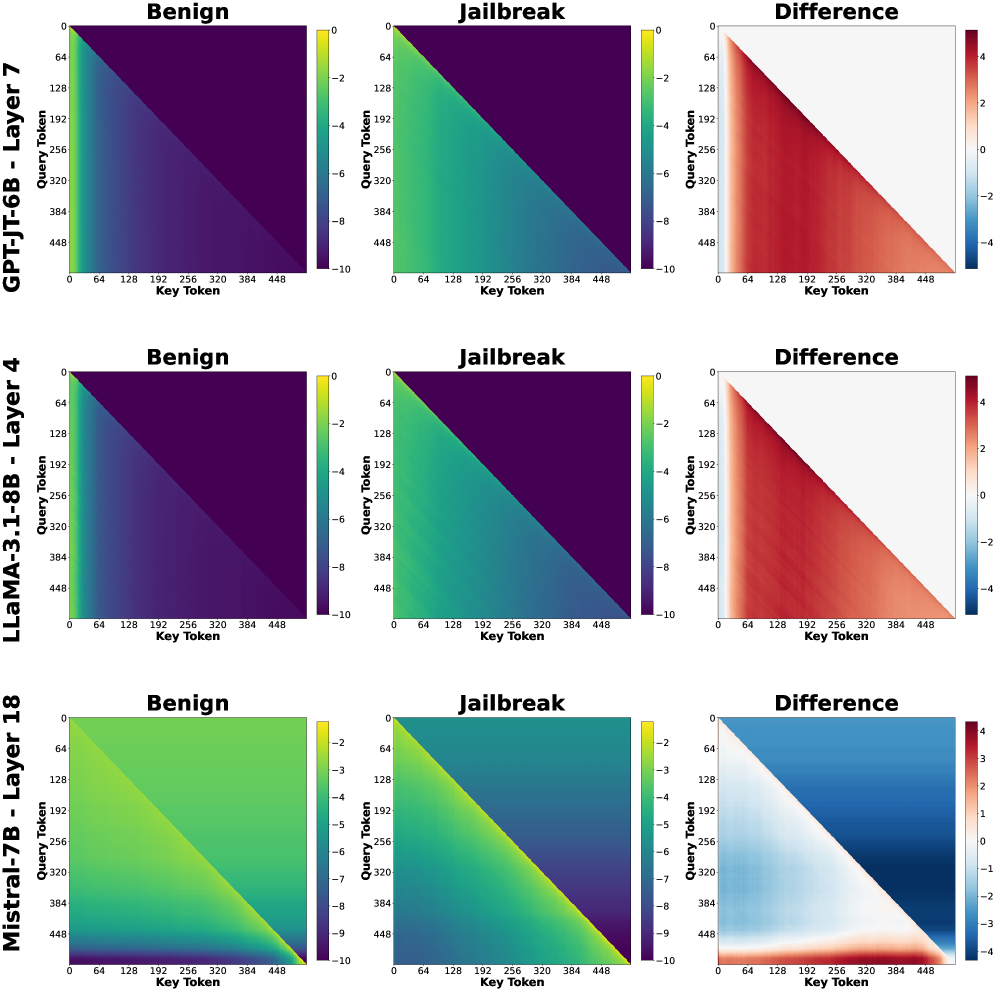
Analysis utilizing CANDECOMP/PARAFAC (CP) tensor decomposition demonstrated that Large Language Models (LLMs) generate demonstrably different activation patterns – or signatures – in their internal, hidden states when processing adversarial “jailbreak” prompts versus standard, benign prompts. These distinctions are not uniform throughout the network; the signatures vary significantly depending on the specific layer of the LLM being analyzed. This layer-dependent behavior indicates that different portions of the network respond uniquely to these differing input types, allowing for the potential identification of layers most impacted by adversarial attacks.
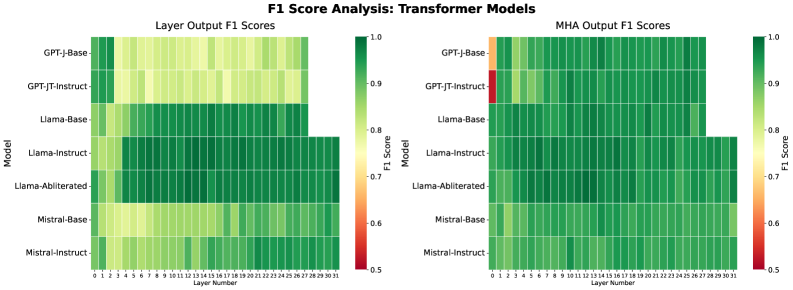
Hidden Representation analysis, utilizing techniques like singular vector decomposition on layer activations, identified specific layers within the LLM architecture exhibiting significantly altered activation patterns in response to jailbreak prompts compared to benign inputs. These alterations manifest as disproportionately large changes in singular values or vector magnitudes within these layers, indicating a heightened susceptibility to adversarial manipulation. The magnitude of these changes varied across layers, with certain layers consistently demonstrating a stronger response to jailbreak attempts, suggesting they function as key processing nodes vulnerable to adversarial influence. This layer-specific vulnerability allows for the precise localization of weaknesses within the LLM’s internal representation and safety mechanisms.
Analysis of LLM internal representations indicates that specific layers within the network function as critical control points for safety mechanisms. Identified layers demonstrate a disproportionate response to adversarial prompts, suggesting they act as bottlenecks where jailbreak attempts are most effectively initiated or amplified. This layer-specific vulnerability implies that manipulating these hidden states can bypass broader safety protocols, allowing the LLM to generate harmful or unintended outputs. The concentration of adversarial impact within these layers highlights their importance as potential targets for both attack and defense strategies, suggesting focused interventions could improve overall model robustness.
Disrupting the Signal: A Targeted Layer Bypass Defense
Targeted Layer Bypass is a defense mechanism predicated on the observation that adversarial jailbreak attacks exhibit layer-specific vulnerabilities within Large Language Models (LLMs). This strategy functions by selectively interrupting the propagation of information through identified susceptible layers, effectively disrupting the execution pathway of the jailbreak prompt. Utilizing the Layer-wise Jailbreak Signature – a pattern indicative of adversarial manipulation at specific layers – and quantifying Layer Susceptibility, the system dynamically identifies and bypasses layers most likely to contribute to successful attacks. This targeted approach differs from blanket input filtering or output censorship by focusing on internal model states, allowing for continued processing of legitimate prompts while mitigating adversarial influence.
Targeted Layer Bypass functions by identifying and interrupting the propagation of adversarial inputs through layers demonstrably vulnerable to jailbreak attacks. This is achieved by selectively halting forward passes at these susceptible layers, preventing the malicious prompt from influencing subsequent layers and ultimately derailing the generation of harmful outputs. The technique does not modify model weights; instead, it operates dynamically during inference, assessing input at each layer and conditionally blocking transmission if a jailbreak signature is detected, thereby breaking the attack’s execution pathway before it reaches the output layer.
Evaluations conducted across multiple large language models – GPT-J, LLaMA, Mistral, and Mamba – demonstrate that the Targeted Layer Bypass strategy effectively mitigates adversarial attacks. Specifically, implementation of this defense resulted in a reduction of the attack success rate to 22%. This indicates a significant improvement in robustness against jailbreak prompts when compared to undefended models, signifying the potential of this approach to limit the exploitation of vulnerabilities within LLM architectures.
Evaluation of the Targeted Layer Bypass defense mechanism yielded 78 true positive results, indicating successful suppression of jailbreak prompts. Concurrently, the system correctly classified 94 benign prompts as non-adversarial, representing true negative classifications. These results demonstrate the technique’s ability to differentiate between malicious and legitimate inputs, achieving a measurable level of effectiveness in mitigating adversarial attacks without significantly impacting performance on standard prompts.
Targeted Layer Bypass presents a potential advancement over conventional LLM safety mechanisms, which often rely on techniques like reinforcement learning from human feedback (RLHF) or extensive fine-tuning that can negatively impact model performance on legitimate tasks. Current methods frequently introduce a trade-off between safety and utility; however, this layer-wise intervention aims to enhance robustness against adversarial attacks without substantially altering the model’s inherent capabilities. Preliminary results indicate a significant reduction in jailbreak success rates – down to 22% in testing – alongside high accuracy in distinguishing between malicious and benign prompts (78 true positives, 94 true negatives), suggesting a preservation of performance characteristics while simultaneously increasing security.
Beyond Patchwork: Towards Architectures Built on Trust
Recent investigations into large language models (LLMs) reveal a concerning pattern: vulnerabilities aren’t distributed evenly throughout the network, but instead concentrate within specific layers. This discovery challenges the assumption that current transformer-based architectures are inherently secure, suggesting a fundamental mismatch between design principles and safety requirements. Researchers have demonstrated that certain layers act as critical chokepoints, where adversarial inputs can be amplified or where sensitive information leaks more readily. This layer-specific fragility indicates that simply increasing model size or training data isn’t a guaranteed path to robustness; a more nuanced understanding of information flow and architectural weaknesses is necessary. Consequently, future LLM development must prioritize designs that address these inherent vulnerabilities, potentially through novel layer configurations or the integration of dedicated safety mechanisms at critical points within the network.
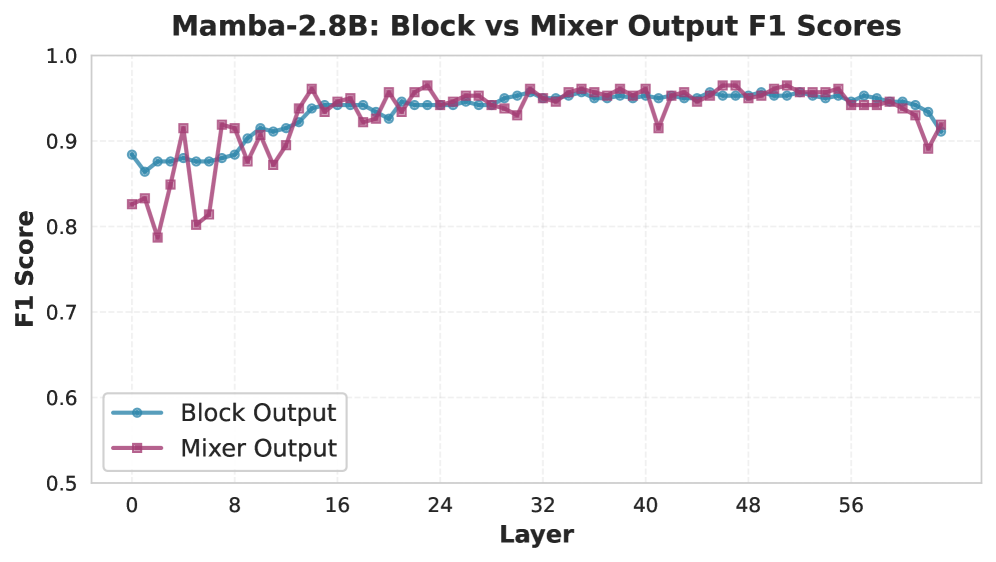
Current large language model architectures, while demonstrating impressive capabilities, may be fundamentally susceptible to adversarial attacks and unintended behaviors due to their inherent design. Researchers are actively investigating alternatives, notably architectures inspired by State-Space Models (SSMs) like Mamba, which offer a potentially more efficient and robust approach to sequence modeling. Unlike traditional Transformers that rely on attention mechanisms, SSMs process information sequentially, potentially mitigating vulnerabilities associated with attention manipulation. Simultaneously, a growing emphasis on information flow control within these architectures aims to restrict the propagation of harmful or irrelevant data, creating a more constrained and predictable system. These explorations aren’t merely about improving performance; they represent a shift towards building LLMs with intrinsic safety properties, where robustness is a foundational characteristic rather than an added layer of defense.
A comprehensive understanding of how Instruction-Tuned Models interact with their underlying, often ‘abliterated’ base models – those stripped of safety guardrails – is crucial for building genuinely safe large language models. Current research reveals that vulnerabilities aren’t simply ‘added’ during instruction tuning; rather, they frequently represent latent flaws exposed by the process, originating within the foundational model itself. Studying the ways instruction tuning amplifies or mitigates these inherent weaknesses, and how ablating safety features reveals the extent of these vulnerabilities, allows for a more targeted and effective approach to alignment. This interplay necessitates a shift from solely focusing on superficial defenses to a deeper investigation of the model’s core mechanics, ultimately enabling the creation of LLMs that are intrinsically safer and more reliably aligned with human values.
Current large language model (LLM) safety measures largely operate as reactive defenses, attempting to mitigate harms after vulnerabilities are exploited. This research shifts the focus toward a more fundamental approach, establishing groundwork for proactive safety architectures. By deeply analyzing inherent weaknesses and the mechanisms through which they manifest, the study facilitates the design of LLMs built on principled foundations. This entails moving beyond simply patching exploits and instead crafting systems where safety is integrated into the core architecture and information flow, ultimately fostering more aligned and robust models less susceptible to adversarial attacks and unintended consequences. The insights gained represent a crucial step toward building LLMs that are safe by design, rather than safe by circumstance.
The research subtly echoes a sentiment held by Linus Torvalds: “Most good programmers do programming as a hobby, and many of those will eventually contribute to open source projects.” This work, dissecting Large Language Models through tensor decomposition and layer bypassing, embodies that spirit of playful exploration. It isn’t simply about defending against jailbreak attacks – a pragmatic concern – but about truly understanding how these models function internally. By probing their latent spaces, the study reveals the architecture’s vulnerabilities, mirroring the hacker’s mindset of reverse-engineering a system to comprehend its fundamental principles. The analysis of internal representations isn’t a restriction, but rather a means of illuminating the unseen connections within the model’s complex structure, fostering a deeper level of insight.
What Breaks Down Next?
The pursuit of robust Large Language Models invariably leads to a paradox. This work, by exposing the internal machinations of these systems through tensor decomposition and layer bypass, offers a clever diagnostic. However, it simultaneously reveals the fragility inherent in any complex system built on distributed representations. The question isn’t whether future adversarial attacks will circumvent these detection methods – it’s when, and what unexpected behaviours will be unearthed in the process. Simply identifying a ‘jailbreak signature’ in the latent space feels less like a solution and more like a temporary truce.
A critical limitation remains: the assumption that detectable anomalies within internal representations consistently correlate with malicious intent. Noise, stylistic variation, and even legitimate creative outputs will inevitably muddy the waters. Future research must grapple with this ambiguity, perhaps by exploring methods to dynamically establish ‘normal’ behaviour baselines for individual models, or by leveraging the very act of probing these internal states to actively harden the system against future exploits.
Ultimately, this line of inquiry suggests a shift in focus. Rather than endlessly patching external vulnerabilities, the true challenge lies in understanding – and even embracing – the inherent unpredictability of intelligence, artificial or otherwise. Perhaps the most valuable outcome isn’t a jailbreak-proof model, but a deeper appreciation for the beautiful, chaotic mess that underlies all complex systems.
Original article: https://arxiv.org/pdf/2602.11495.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- New Avatar: The Last Airbender Movie Leaked Online
- Quantum Agents: Scaling Reinforcement Learning with Distributed Quantum Computing
- All Skyblazer Armor Locations in Crimson Desert
- Boruto: Two Blue Vortex Chapter 33 Preview — The Final Battle Vs Mamushi Begins
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Red Dead Redemption 3 Lead Protagonists Who Would Fulfill Every Gamer’s Wish List
- One Piece Chapter 1180 Release Date And Where To Read
- All Shadow Armor Locations in Crimson Desert
- How to Beat Antumbra’s Sword (Sanctum of Absolution) in Crimson Desert
- USD RUB PREDICTION
2026-02-15 11:30