Author: Denis Avetisyan
A new study reveals how compressing information for retrieval-augmented generation can lead to critical context loss, impacting the quality of AI-powered summaries and responses.
Researchers demonstrate efficient overflow detection in compressed token representations by analyzing query-context interactions within joint embedding spaces.
Efficiently processing long contexts remains a critical challenge for large language models, yet compressing token sequences to extend context length risks losing task-relevant information. This paper, ‘Detecting Overflow in Compressed Token Representations for Retrieval-Augmented Generation’, defines and investigates ‘token overflow’-the point at which compression erases crucial data-and proposes a method for its detection. By analyzing query-context interactions in compressed representations, we demonstrate that overflow can be identified with 0.72 AUC-ROC using lightweight probing classifiers, offering a low-cost pre-LLM gating mechanism. Could this query-aware approach enable more robust and reliable retrieval-augmented generation systems by proactively mitigating compression-induced errors?
The Algorithmic Imperative: Retrieval-Augmented Generation
Retrieval-Augmented Generation presents a compelling alternative to the resource-intensive process of continuously re-training large language models. Instead of embedding all knowledge directly within the model’s parameters, RAG systems equip LLMs with the ability to access and incorporate information from external sources during inference. This approach allows for dynamic knowledge updates without altering the foundational model, offering significant advantages in scenarios where information is constantly evolving or highly specific. By retrieving relevant context from a database – encompassing documents, websites, or structured knowledge graphs – RAG effectively extends the LLM’s knowledge base on demand, enabling more informed and accurate responses to complex queries and fostering adaptability without the constraints of fixed training data.
While intuitively, providing a Large Language Model (LLM) with more information seems advantageous, studies reveal that performance doesn’t consistently improve with increased context. LLMs possess finite context windows – limitations on the amount of text they can effectively process – meaning that exceeding this capacity can lead to information overload and diminished accuracy. Furthermore, irrelevant or poorly-formatted data, often termed ‘noise’, can distract the model from critical signals, hindering its ability to perform complex reasoning. This is particularly evident in tasks requiring nuanced understanding or multi-step inference, where the signal-to-noise ratio becomes crucial; a surplus of extraneous information can effectively drown out the essential details needed for a correct response, ultimately degrading the model’s performance instead of enhancing it.
The scalability of Retrieval-Augmented Generation (RAG) is fundamentally linked to efficient information compression techniques. While providing Large Language Models (LLMs) with external knowledge enhances their capabilities, simply increasing the volume of retrieved context isn’t a viable solution due to inherent limitations in processing lengthy inputs. Effective compression isn’t merely about reducing token count; it requires discerning and preserving the most salient signals within the retrieved data. Sophisticated methods are being explored to distill relevant information, employing techniques like keyword extraction, sentence summarization, and even learning to identify and filter out potentially distracting or ‘noisy’ content. The challenge lies in striking a delicate balance – reducing the contextual burden on the LLM while simultaneously ensuring that critical details necessary for accurate reasoning and generation aren’t inadvertently discarded, ultimately allowing RAG systems to handle increasingly complex queries and vast knowledge domains.
Evaluations using datasets such as TriviaQA, SQuADv2, and HotpotQA have been instrumental in showcasing the capabilities of Retrieval-Augmented Generation, yet simultaneously reveal inherent limitations. While RAG systems consistently demonstrate improved performance on factoid question answering, these benchmarks also expose difficulties in scenarios demanding more complex reasoning or synthesis of information from multiple retrieved sources. Specifically, challenges arise when the retrieved context contains irrelevant or contradictory information – often referred to as ‘noise’ – hindering the LLM’s ability to accurately identify and utilize the most pertinent knowledge. Furthermore, current RAG approaches often struggle with questions requiring inference or the application of common sense, suggesting that simply providing more data does not automatically translate to deeper understanding or robust reasoning capabilities; instead, sophisticated methods for knowledge integration and contextual filtering are crucial for maximizing the benefits of external knowledge sources.
Contextual Reduction: From Brute Force to Vector Representation
Simple truncation of context windows, while computationally inexpensive, frequently results in the removal of crucial information necessary for accurate Large Language Model (LLM) performance. This discarded data can include preceding turns in a conversation, relevant details from source documents, or important contextual cues. Consequently, LLMs subjected to truncated inputs exhibit demonstrable drops in metrics such as answer relevance, factual accuracy, and coherence, particularly when the removed information contained key entities, relationships, or instructions influencing subsequent processing. The degree of performance degradation is directly correlated to the amount of valuable information lost during the truncation process, making it a suboptimal approach for managing lengthy contexts.
Soft compression techniques address the limitations of simple context truncation by converting variable-length context windows into fixed-size, dense vector representations. This is achieved through methods like dimensionality reduction or learned embeddings, allowing the Large Language Model (LLM) to access contextual information via its attention mechanism without being constrained by a maximum token limit. Unlike truncation, which discards information, these vector representations aim to preserve salient signals from the original context, enabling the model to retain crucial details while effectively managing input length. The resulting vectors are then incorporated into the LLM’s input sequence alongside the query, allowing the attention mechanism to weigh the compressed context appropriately during processing.
Hard compression techniques introduce deliberate information bottlenecks during context processing, requiring the Large Language Model (LLM) to actively select and prioritize the most relevant data. This is achieved through methods like fixed-length context windows or learned compression modules that reduce the input sequence length. Unlike truncation or soft compression, hard compression does not attempt to preserve all contextual information; instead, it forces the model to focus on a distilled representation, effectively acting as a regularization technique. The resulting prioritization encourages the LLM to develop a more robust understanding of core concepts and dependencies, potentially improving performance on tasks requiring reasoning and generalization despite a reduced context length.
Context compression methods, beyond merely shortening input sequences, fundamentally alter the paradigm of knowledge representation for Large Language Models (LLMs). Traditional approaches treated context as a linear string of tokens; however, techniques like soft and hard compression transform this into a dense, vector-based representation. This shift enables the LLM’s attention mechanism to access and prioritize information based on semantic similarity rather than positional proximity. Consequently, the model receives a distilled knowledge representation – not just a truncated version of the original context – allowing it to potentially retain crucial information and improve performance on tasks requiring long-range dependencies, despite a reduced input length.
Signal Degradation: Diagnosing and Quantifying Token Overflow
Token Overflow is a phenomenon wherein the process of compressing input tokens for Large Language Models (LLMs) results in a loss of task-relevant information. This loss doesn’t manifest as a complete absence of data, but rather as a degradation of the signal contained within the compressed tokens, effectively introducing noise. As a consequence, the LLM receives a distorted representation of the input context, leading to decreased performance on downstream tasks. The severity of Token Overflow is not uniform; certain input contexts are more susceptible to this information loss than others, impacting the model’s ability to accurately process and respond to complex queries.
Analysis demonstrates a correlation between context complexity and the incidence of Token Overflow. Specifically, both perplexity and context length are positively correlated with the likelihood of information loss during token compression. Higher perplexity indicates a less predictable context, increasing the difficulty of accurate compression. Similarly, longer contexts naturally present more opportunities for relevant signal degradation during the compression process. This suggests that challenging contexts, characterized by high perplexity or substantial length, are disproportionately susceptible to Token Overflow, leading to reduced performance in downstream tasks.
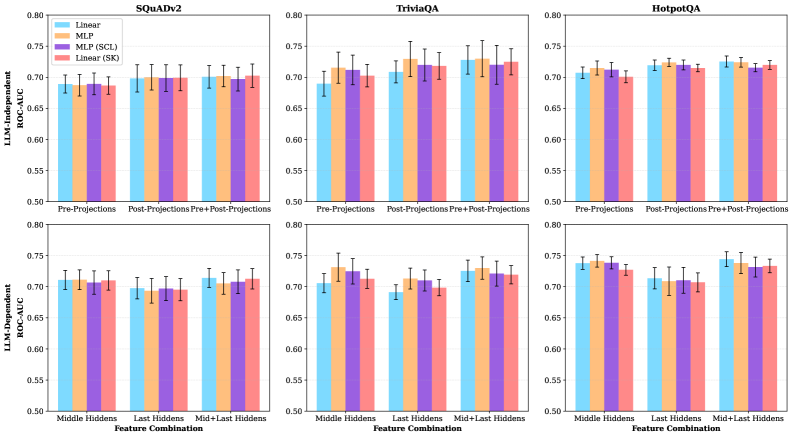
Token Overflow can be detected through analysis of token distributions following compression. Specifically, comparisons between compressed and uncompressed tokens reveal statistically significant differences across several metrics. Our analysis indicates variations ranging from 7% to 87% in measures such as Hoyer’s sparsity – quantifying the distribution’s concentration – spectral entropy, which assesses the complexity of the token distribution, and excess kurtosis, indicating the peakedness of the distribution relative to a normal distribution. These discrepancies suggest a loss of task-relevant signal during compression, confirming the occurrence of Token Overflow and enabling its quantitative assessment.
A Learned Probing Classifier offers a method for detecting Token Overflow independent of the Large Language Model (LLM) being used. This classifier is trained on combined query and context representations and achieves an Area Under the Receiver Operating Characteristic curve (AUC-ROC) of 0.72 when evaluating potential overflow instances prior to LLM inference. This performance represents a substantial improvement over methods relying solely on context analysis (AUC-ROC 0.64-0.69) or saturation statistics (AUC-ROC 0.52-0.58). The classifier’s performance is statistically comparable to other models utilizing joint query-context representations, which achieve AUC-ROC scores between 0.70 and 0.73.
xRAG: A Projection-Based Architecture for Robust Knowledge Integration
The xRAG architecture introduces a distinct method for compressing information used in Retrieval-Augmented Generation (RAG) systems. Rather than directly modifying the large language model (LLM) itself, xRAG employs a projection layer to translate document embeddings – numerical representations of text – into the LLM’s native input space. This strategic decoupling is crucial; it allows developers to experiment with and refine compression techniques independently of the LLM’s parameters, avoiding the costly and potentially destabilizing process of fine-tuning the model. By isolating compression as a separate, projectable component, xRAG unlocks greater flexibility in selecting and optimizing compression algorithms, enabling efficient knowledge integration without compromising the LLM’s core capabilities. This innovative approach not only streamlines the compression process but also facilitates broader compatibility with diverse data sources and RAG applications.
The xRAG architecture distinguishes itself through a deliberate separation of compression methodologies from the core Large Language Model (LLM). This decoupling fosters unprecedented flexibility, allowing developers to experiment with and integrate a wide spectrum of compression techniques – from simple truncation to sophisticated vector quantization and learned compression algorithms – without requiring costly or disruptive LLM fine-tuning. Consequently, xRAG promotes scalability; as data volumes grow or computational resources shift, alternative compression strategies can be implemented and swapped with minimal impact on the LLM’s performance or existing workflows. This adaptability not only streamlines the development process but also empowers systems to dynamically optimize compression based on specific task requirements and data characteristics, ensuring efficient resource utilization and sustained performance.
The xRAG architecture mitigates the pervasive issue of Token Overflow – a critical limitation in Retrieval-Augmented Generation (RAG) systems – by strategically projecting compressed embeddings directly into the Large Language Model’s (LLM) input space. This innovative approach doesn’t simply reduce the number of tokens; it fundamentally restructures the information to ensure semantic integrity is maintained throughout the compression process. By mapping compressed data into a format natively understood by the LLM, xRAG prevents the loss of crucial context or meaning that often accompanies traditional compression methods. Consequently, the LLM can effectively utilize the retrieved information, even when dealing with extensive datasets, without encountering the performance degradation or inaccuracies associated with exceeding token limits and ensuring the compressed data remains consistently actionable and reliable.
Retrieval-Augmented Generation (RAG) systems often encounter limitations due to token overflow, where exceeding the input token limit of a large language model (LLM) diminishes performance and introduces instability. The xRAG architecture directly addresses this challenge, demonstrably enhancing both the performance and reliability of RAG across diverse applications and datasets. By preventing the truncation or loss of crucial context caused by token overflow, xRAG ensures the LLM receives a complete and coherent information set for generating responses. This capability translates to improved accuracy, more relevant outputs, and a more consistent user experience, particularly in complex tasks requiring extensive knowledge retrieval and synthesis. Rigorous testing indicates that xRAG’s ability to maintain information integrity, even with large document sets, significantly outperforms traditional RAG approaches prone to context degradation from token limitations.
The pursuit of robust retrieval-augmented generation necessitates a rigorous understanding of representational limits. This work, focusing on overflow detection within compressed token spaces, aligns with a mathematical imperative for correctness. Brian Kernighan aptly stated, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” Similarly, this research doesn’t merely address a functional issue-token saturation-but dissects the underlying mathematical conditions that create it. The ability to efficiently detect overflow without relying on computationally expensive LLM inference demonstrates a commitment to provable correctness, a cornerstone of elegant algorithmic design, and sidesteps potential debugging nightmares within complex systems.
Beyond the Saturation Point
The demonstrated capacity to detect overflow in compressed token spaces without resorting to full language model inference represents a step towards a more principled understanding of retrieval-augmented generation. However, it does not resolve the underlying tension: the compression itself. While the method identifies where saturation occurs, it offers little to alleviate the fundamental information loss inherent in reducing complex semantic meaning to a limited representational capacity. Future work must address not merely the symptoms of overflow, but the disease itself-the relentless drive to minimize dimensionality at the expense of fidelity.
A fruitful avenue lies in exploring compression schemes that are provably lossless within defined bounds, or at least offer quantifiable guarantees regarding the preservation of query-context interaction. The current reliance on empirically observed saturation points feels…unsatisfactory. True elegance demands a solution rooted in mathematical necessity, not pragmatic observation. The identification of overflow is merely diagnostic; a complete theory will necessitate a predictive understanding of when and where information is irrevocably lost during compression.
Ultimately, the field must move beyond treating compression as a black box. The ideal is a system where the representational capacity is dynamically adjusted based on the complexity of the query and context, a self-regulating equilibrium between efficiency and semantic preservation. Only then can retrieval-augmented generation truly transcend its current limitations, achieving a harmonious balance between computational cost and cognitive fidelity.
Original article: https://arxiv.org/pdf/2602.12235.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- New Avatar: The Last Airbender Movie Leaked Online
- All Skyblazer Armor Locations in Crimson Desert
- Quantum Agents: Scaling Reinforcement Learning with Distributed Quantum Computing
- Boruto: Two Blue Vortex Chapter 33 Preview — The Final Battle Vs Mamushi Begins
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- One Piece Chapter 1180 Release Date And Where To Read
- Red Dead Redemption 3 Lead Protagonists Who Would Fulfill Every Gamer’s Wish List
- Euphoria Season 3 Release Date, Episode 1 Time, & Weekly Schedule
- All Shadow Armor Locations in Crimson Desert
- Cassius Morten Armor Set Locations in Crimson Desert
2026-02-15 16:17