Author: Denis Avetisyan
A new approach to managing embedding tables minimizes conflicts and ensures models stay up-to-date in large-scale recommendation systems.
This paper introduces Multi-Probe Zero Collision Hash (MPZCH), an algorithm leveraging efficient linear probing and configurable eviction policies to mitigate hash collisions and enhance embedding freshness.
Large-scale recommendation systems rely heavily on embedding tables, yet traditional hash-based indexing methods increasingly suffer from collisions as the number of unique IDs grows. The paper ‘Multi-Probe Zero Collision Hash (MPZCH): Mitigating Embedding Collisions and Enhancing Model Freshness in Large-Scale Recommenders’ introduces a novel approach, MPZCH, that effectively eliminates these collisions and improves embedding freshness through configurable linear probing and active eviction policies. By preventing stale embedding inheritance, MPZCH ensures new features learn effectively while maintaining production-scale efficiency comparable to existing methods. Could this technique unlock even greater personalization and model accuracy in the next generation of recommender systems?
The Inevitable Fracture: Collisions in Embedding Tables
Modern recommendation systems frequently utilize embedding tables to transform categorical features – such as user IDs, item IDs, or genres – into dense vector representations suitable for machine learning models. However, the sheer scale of these systems, often dealing with millions or even billions of unique categories, introduces a fundamental challenge: hash collisions. Because embedding tables rely on hashing functions to map categorical IDs to specific vector locations, it’s inevitable that different IDs will occasionally map to the same location, a phenomenon known as a collision. This forces the model to represent distinct entities with a single, shared embedding, effectively blurring the distinction between them and leading to a degradation in performance, reduced accuracy, and diminished ability to generalize to unseen data. The frequency of these collisions increases as the embedding table grows, creating a significant obstacle to building highly effective and scalable recommendation engines.
When numerous items compete for a limited number of embedding vectors, hash collisions become unavoidable, and these events fundamentally compromise the quality of learned representations. This occurs because distinct categorical IDs, representing genuinely different entities, are forced to share the same embedding vector, effectively blurring the distinctions the model needs to make. Consequently, the model struggles to accurately predict preferences or characteristics associated with these colliding IDs, leading to decreased accuracy and a diminished ability to generalize to unseen data. The shared representation hinders the model’s capacity to discern subtle differences, ultimately impacting the reliability and effectiveness of the entire recommendation system.
While techniques like double hashing have historically been employed to mitigate collisions within embedding tables, these approaches present inherent limitations in modern recommendation systems. Double hashing, and similar methods, introduce increased computational overhead during both training and inference, demanding more resources for hash function calculations and potentially slowing down real-time predictions. Furthermore, the scalability of these solutions is often constrained by the need to carefully tune hash function parameters and manage potential clustering effects, which can negate performance gains as embedding table sizes grow exponentially. The complexity added by these collision resolution strategies can also hinder model deployment and maintenance, making it challenging to adapt to evolving datasets and user behaviors – a critical factor in dynamic recommendation scenarios.
A Collision-Free Architecture: The MPZCH Strategy
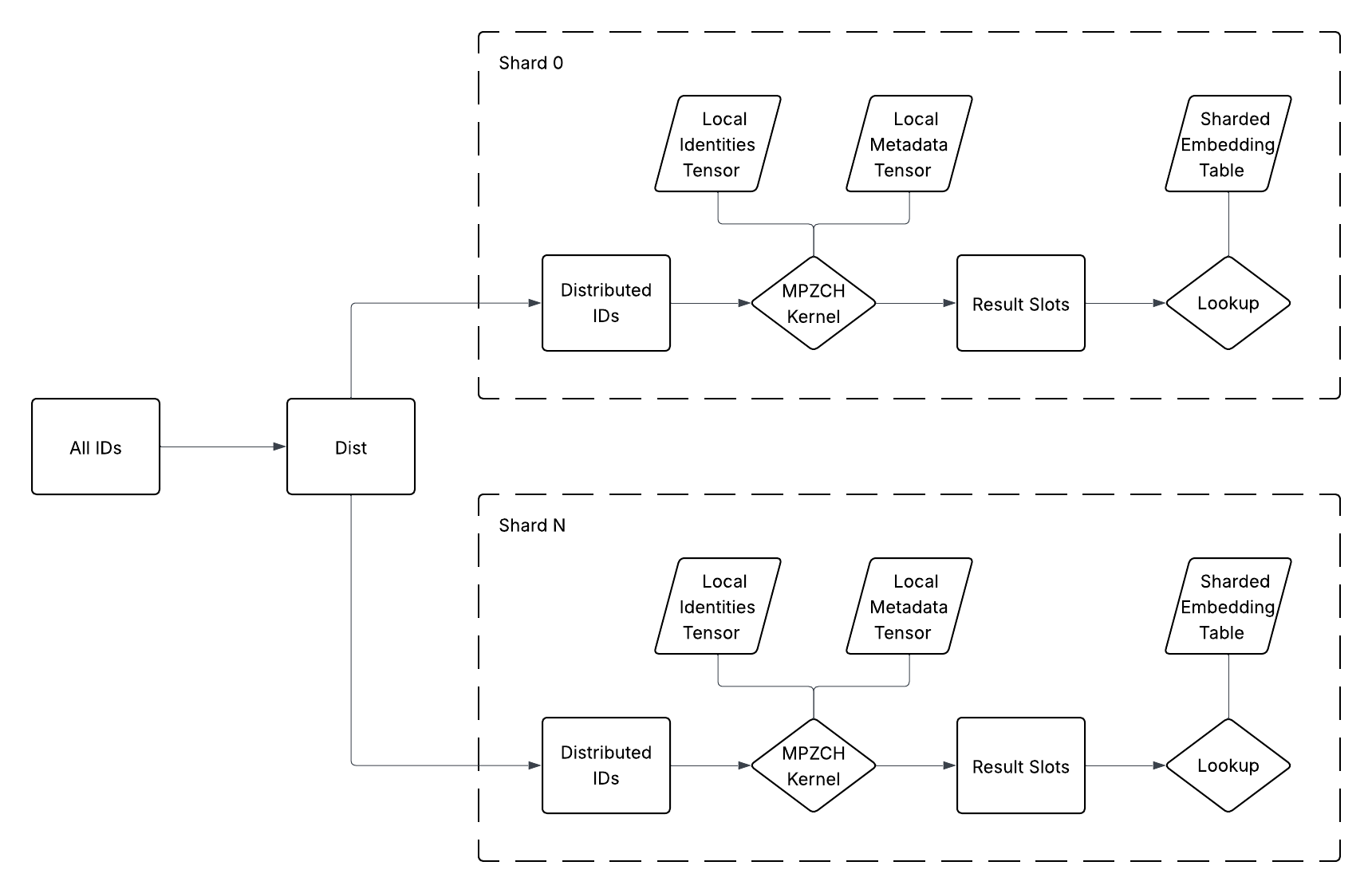
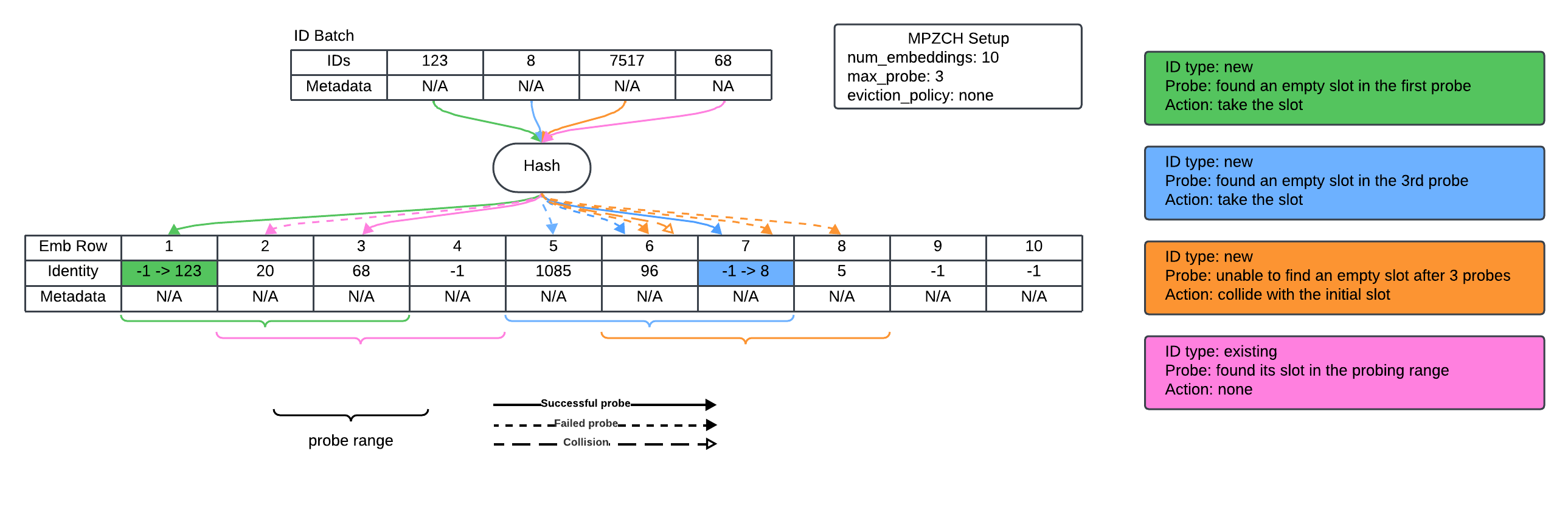
The MPZCH strategy utilizes two auxiliary tensors alongside the primary embedding table: an Identity Tensor and a Metadata Tensor. The Identity Tensor, with dimensions matching the embedding table, functions as a bit vector to indicate row occupancy; a set bit signifies that a row contains a valid embedding. The Metadata Tensor stores Time-To-Live (TTL) information for each embedding, enabling efficient eviction of stale entries. This combination allows MPZCH to explicitly track which slots are occupied and the remaining validity duration of each embedding, facilitating collision avoidance and managing embedding table freshness without requiring searches or complex data structures.
MPZCH utilizes linear probing as its collision resolution strategy, but crucially, this is implemented in conjunction with the Identity and Metadata tensors. The Identity Tensor ensures each ID is mapped to a unique initial slot within the embedding table. When a collision occurs during insertion – meaning the intended slot is already occupied – linear probing sequentially searches for the next available slot. The Metadata Tensor tracks Time-To-Live (TTL) information, enabling the eviction of stale entries during probing, which further increases the probability of finding an available, valid slot. This combination of linear probing and auxiliary tensor management guarantees a unique storage location for each ID, thereby eliminating collisions and maintaining embedding table quality by preventing overwrites and ensuring data integrity.
The MPZCH design facilitates efficient updates and evictions within the embedding table by directly associating each ID with a unique slot tracked via auxiliary tensors. This eliminates the need for complex collision resolution during write operations, allowing updates to occur in constant time. Evictions are similarly streamlined; when an ID’s Time-To-Live expires, its slot is immediately available for reuse without requiring searches or re-hashing. This combination of fast updates and evictions ensures the embedding table consistently reflects the most current data, thereby maintaining a high degree of accuracy and freshness, and minimizing the impact of stale embeddings on model performance.
The Rhythm of Renewal: Dynamic Table Management
MPZCH employs an eviction policy to manage the table of IDs, addressing the challenge of maintaining a fixed-size table with a continuously changing dataset. This policy proactively removes obsolete IDs to create space for newly observed IDs, preventing table overflow and ensuring the system remains responsive to current data. A commonly implemented strategy is Least Recently Used (LRU), where IDs accessed furthest in the past are prioritized for removal. The specific eviction criteria and parameters can be adjusted based on the application and observed data patterns, but the core principle involves periodically assessing ID usage and removing those deemed least relevant based on access history.
The dynamic management of IDs, facilitated by an eviction policy and a collision-free design, directly contributes to improved embedding quality as measured by Normalized Entropy (NE). Evaluation across 17 distinct prediction tasks demonstrated statistically significant improvements in NE for 14 of those tasks. This indicates that the system’s ability to refresh and maintain a relevant ID mapping-by removing obsolete entries and preventing collisions-results in more accurate and informative embeddings, enhancing the overall performance of downstream prediction models.
MPZCH is designed for deployment in large-scale distributed training environments through integration with frameworks such as TorchRec. This integration facilitates efficient handling of the dynamic table management processes required for maintaining accurate embeddings. Performance metrics demonstrate a measurable impact; specifically, videos posted within the last 48 hours exhibited a 0.83% increase in impression rate following the implementation of MPZCH within the training pipeline.

Beyond Optimization: The Expanding Horizon of Embedding Techniques
Building upon the established principles of the MPZCH framework, recent advancements in embedding table optimization leverage techniques such as the QR Trick, Unified Embedding, and Mixed Dimension Embeddings to achieve superior performance. The QR Trick efficiently decomposes embedding matrices, reducing computational cost during forward passes, while Unified Embedding consolidates multiple embedding tables into a single, shared representation to improve generalization and reduce memory usage. Furthermore, Mixed Dimension Embeddings intelligently allocate varying dimensionalities to different parts of the embedding table, allowing for a more nuanced representation of complex relationships. These combined strategies not only accelerate training processes but also enhance the capacity of embedding models to capture intricate patterns within data, ultimately leading to more accurate and efficient machine learning applications.
Advanced embedding techniques prioritize the creation of more compact representations, directly addressing the escalating memory demands of modern machine learning models. By strategically reducing the size of embedding tables – the look-up tables that translate discrete inputs into dense vector representations – these methods significantly lessen the computational burden during both training and inference. This reduction in memory footprint not only accelerates training speed, allowing for faster iteration and experimentation, but also facilitates the deployment of these models on resource-constrained devices. The efficiency gains are particularly noticeable in large-scale applications, where even modest reductions in model size can translate into substantial cost savings and improved performance, ultimately enabling more widespread adoption of complex AI systems.
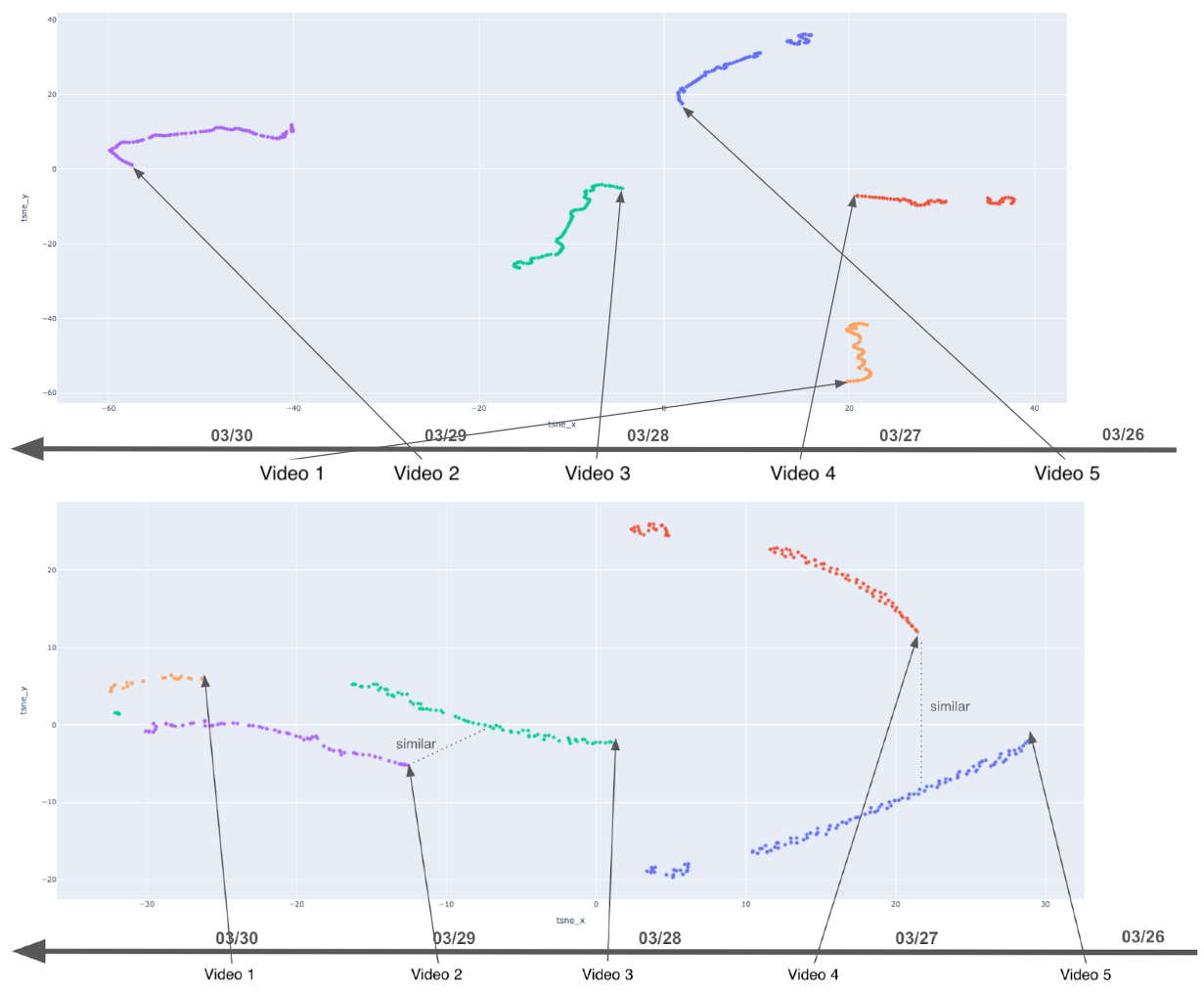
Beyond optimizations to existing embedding structures, alternative methodologies such as Semantic IDs and Tensor Train Decomposition present distinct advantages in addressing nuanced challenges within embedding design. Semantic IDs focus on grouping similar items based on underlying meaning, while Tensor Train Decomposition reduces dimensionality through a compact representation of the embedding table. Recent evaluations demonstrate the efficacy of these complementary strategies; video embeddings generated using these techniques exhibited a 38% increase in similarity for content originating from the same creator, a substantial improvement over the 25% baseline achieved with conventional methods. This enhanced similarity suggests improved content understanding and retrieval capabilities, potentially leading to more relevant recommendations and search results.
The pursuit of ever-larger embedding tables, as detailed in this work concerning MPZCH, inevitably invites complexity. It’s a familiar pattern; each architectural advance promises freedom from the constraints of scale, until it demands unforeseen sacrifices in operational overhead. This paper’s focus on collision mitigation isn’t merely a technical optimization, but a tacit acknowledgement of inherent system entropy. As Linus Torvalds observed, “Talk is cheap. Show me the code.” The elegance of MPZCH lies not in its theoretical perfection, but in its pragmatic approach to a messy reality – the inevitable collisions and the constant need for embedding freshness in large-scale recommender systems. It’s a temporary bulwark against chaos, a carefully constructed cache between failures.
What Lies Ahead?
The elimination of hash collisions, as demonstrated by MPZCH, feels less like a solution and more like a postponement. Each optimized probe, each eviction policy, merely delays the inevitable entropy. The system, having achieved a local minimum of conflict, will invariably discover new, subtler forms of collision-not in the hash itself, but in the representation it serves. The true problem isn’t how to store embeddings, but why they demand such vast, static tables in the first place.
Future work will likely focus on adaptive probing, attempting to predict and preempt collisions before they manifest. But such efforts resemble increasingly frantic gardening around a structure fundamentally prone to collapse. A more radical approach involves questioning the very notion of fixed embeddings. Can recommendation systems function with representations that evolve continuously, embracing a degree of controlled instability? The current architecture assumes a stable ‘self’ to recommend to; perhaps that assumption is the primary limitation.
Distributed training, while essential for scale, only exacerbates the problem of embedding staleness. Each shard represents a partial view of a constantly shifting user landscape. The pursuit of ‘freshness’ is, ultimately, a Sisyphean task. One anticipates a move beyond simple eviction policies towards mechanisms that actively synthesize new embeddings from real-time interactions, accepting a degree of calculated approximation in exchange for genuine responsiveness. Deploying this, of course, will be a small apocalypse.
Original article: https://arxiv.org/pdf/2602.17050.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- Every Melee and Ranged Weapon in Windrose
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Jojo’s Bizarre Adventure Ties Frieren As MyAnimeList’s New #1 Anime
- How to Catch All Itzaland Bugs in Infinity Nikki
- Top 10 Must-Watch Isekai Anime on Crunchyroll Revealed!
- Invincible: 10 Strongest Viltrumites in Season 4, Ranked
- Re:Zero Season 4 Episode 3 Release Date & Where to Watch
- Who Can You Romance In GreedFall 2: The Dying World?
- Grime 2 Map Unlock Guide: Find Seals & Fast Travel
2026-02-21 08:54