Author: Denis Avetisyan
This review examines the latest innovations in SYCL compiler implementations and their impact on performance and portability across diverse hardware platforms.
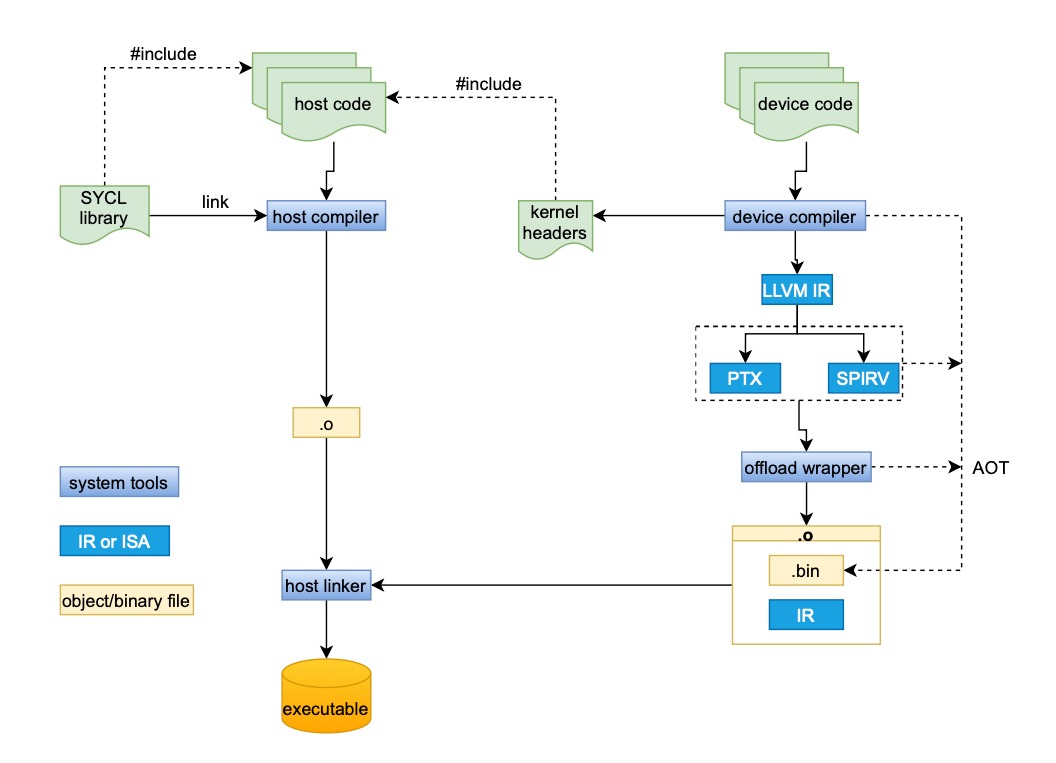
Recent advancements leverage Single-Source Single Compiler Pass models and Multi-Level Intermediate Representation to optimize SYCL code for heterogeneous systems.
Achieving high performance and portability across diverse heterogeneous computing platforms remains a significant challenge in modern compiler design. This survey, ‘A Survey of Recent Developments in SYCL Compiler Implementations’, examines the evolving landscape of SYCL compilation, focusing on the transition from traditional multi-pass approaches to Single-Source Single-Compiler Pass (SSCP) models. Recent advancements, particularly leveraging the Multi-Level Intermediate Representation (MLIR), demonstrate potential for enhanced optimization and improved code portability. Will these new compilation techniques unlock the full potential of heterogeneous architectures and facilitate broader adoption of SYCL for high-performance computing?
Emergent Order from Unified Compilation
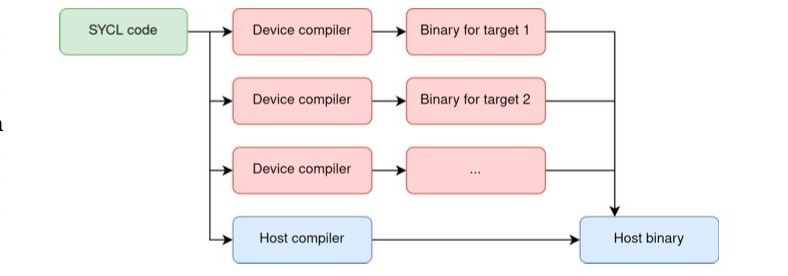
Historically, harnessing the power of heterogeneous computing platforms – those incorporating diverse processors like CPUs and GPUs – often necessitated separate compilation. Programmers faced the challenge of writing and compiling code intended for both the host processor and the compute device as distinct entities. This meant managing two separate codebases, ensuring data transfer between them, and resolving compatibility issues arising from differing architectures. The process introduced significant overhead, not only in development time but also at runtime due to the need for explicit data staging and synchronization. Such complexity hindered portability, as code meticulously crafted for one specific hardware configuration frequently required substantial modification to function on another, limiting the potential for widespread adoption and efficient resource utilization.
The traditional separate compilation paradigm, exemplified by OpenCL, inherently introduces significant overhead due to the necessity of managing distinct host and device codebases. This division necessitates complex build processes and runtime linking, consuming valuable computational resources and increasing development time. Furthermore, this approach severely limits portability; code meticulously crafted for one hardware accelerator often requires substantial modification to function on another, even within the same vendor’s product line. This lack of code reusability stems from the tight coupling between the program and the specific details of the target device’s architecture, ultimately hindering the efficient utilization of diverse hardware accelerators and stifling innovation in heterogeneous computing.
SYCL represents a significant departure from traditional heterogeneous programming paradigms by introducing a single-source approach to code development. Instead of managing separate host and device codebases, SYCL allows developers to write code in a unified manner, leveraging a modern C++ foundation. This consolidation dramatically increases developer productivity, reducing the complexities associated with maintaining divergent code paths and enabling greater code reuse. Beyond simplification, SYCL’s single-source model facilitates more aggressive optimizations; the compiler can analyze the entire program at once, leading to improved performance through enhanced data locality, reduced memory transfers, and more effective parallelization strategies across diverse hardware accelerators – including CPUs, GPUs, and FPGAs. The result is a more portable, maintainable, and ultimately, faster execution of applications designed for heterogeneous computing environments.
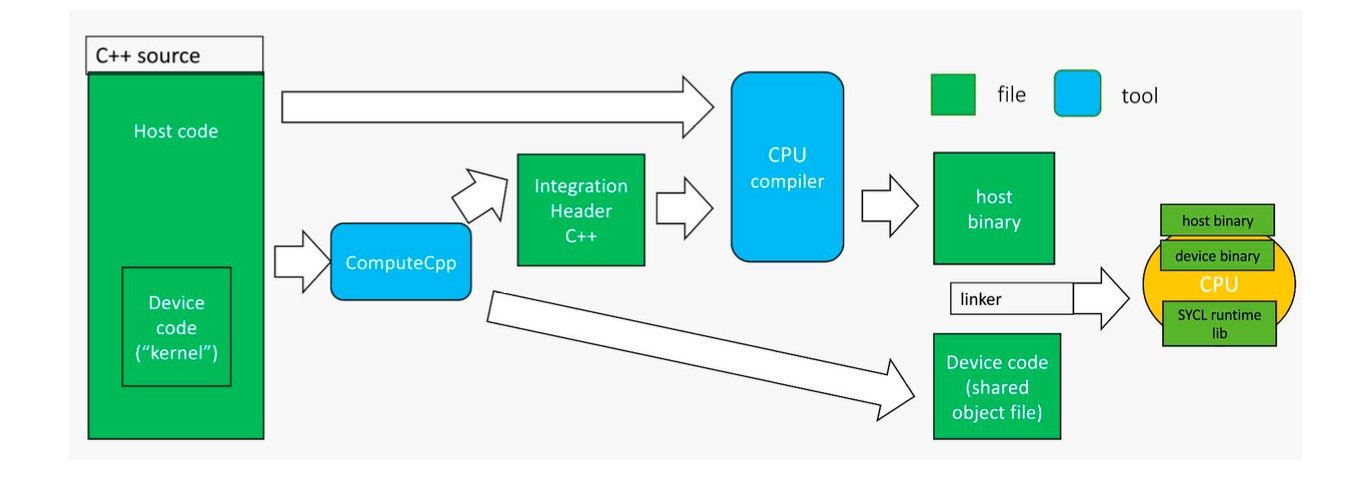
The Single-Source Compilation Pass: A Path to Efficiency
SYCL utilizes the Single-Source Programming Model, wherein a single code base describes both host and device execution. However, this necessitates compilation techniques capable of processing both host and device code within a unified framework. Traditional compilation workflows typically involve separate compilation stages for host and device code, introducing overhead and complexity. SYCL’s single-source approach demands a system that can analyze and compile code intended for both the CPU and accelerator simultaneously, enabling optimization across the entire system and facilitating portability between heterogeneous hardware platforms. This unified compilation is crucial for realizing the performance benefits and code simplification inherent in the SYCL model.
The Single-Source Compilation Pass (SSCP) is an extension to the SYCL standard designed to optimize the compilation workflow. Traditionally, SYCL compilation involved separate passes for host and device code, creating overhead and increasing compilation time. SSCP unifies these processes into a single compilation pass, allowing the compiler to analyze and optimize the entire program – encompassing both host and device components – simultaneously. This consolidation enables more efficient code generation and reduces redundant processing, ultimately streamlining the build process for SYCL applications.
The implementation of a single-source compilation pass (SSCP) demonstrably reduces compilation overhead and increases efficiency relative to traditional, separate compilation workflows. By consolidating the compilation of both host and device code into a unified process, SSCP minimizes redundant analysis and code generation steps. Benchmarking has indicated a 20% improvement in compilation time when utilizing SSCP compared to standard SYCL compilation methodologies, representing a significant performance gain for developers working with heterogeneous computing platforms.
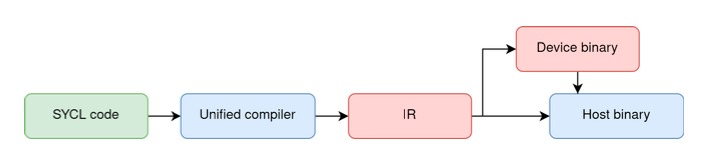
MLIR: A Foundation for Adaptable SYCL Compilation
Contemporary SYCL deployments are exhibiting a growing dependence on MLIR (Multi-Level Intermediate Representation) as a means to enhance both compilation adaptability and optimization capabilities. This trend stems from MLIR’s design, which facilitates the representation of code at varying abstraction levels, allowing developers to implement a wider range of transformations and optimizations than traditional compilation pipelines permit. Specifically, MLIR’s extensible design allows for the insertion of custom passes targeting specific hardware or algorithmic characteristics, improving performance and code generation quality. This contrasts with statically defined compiler infrastructures, offering greater flexibility in targeting diverse platforms and architectures.
MLIR facilitates code representation at varying levels of abstraction, from high-level domain-specific operations to low-level machine instructions. This multi-level approach enables a suite of transformations and optimizations not easily achievable with traditional single-level IRs. These include operator fusion, loop tiling, common subexpression elimination, and target-specific code generation. Crucially, MLIR’s extensible design allows developers to define custom passes and transformations tailored to specific hardware architectures or application domains, increasing both performance and code specialization opportunities. The framework’s dialect system further supports modularity and composability of these transformations, enabling complex optimization pipelines.
Polygeist is a device compiler built on the MLIR framework and designed to optimize SYCL applications for heterogeneous hardware. It achieves acceleration through a series of transformations represented as MLIR passes, allowing for both high-level and low-level optimizations tailored to the target device. Benchmarks demonstrate that Polygeist can deliver significant performance improvements – up to 3x in some cases – compared to traditional SYCL compilation flows, particularly for compute-intensive kernels. The compiler supports a range of devices, including GPUs and CPUs, and focuses on enabling aggressive loop optimizations, memory access coalescing, and efficient utilization of hardware-specific features through its MLIR-based infrastructure.
Both the DPC++ and ComputeCpp SYCL implementations are undergoing active integration of MLIR to address limitations in traditional compilation pipelines. DPC++ leverages MLIR for graph optimizations, kernel fusion, and the implementation of hardware-specific transformations, resulting in measurable performance gains on target architectures. ComputeCpp is similarly utilizing MLIR to improve code generation, enable more aggressive optimizations, and enhance portability across diverse hardware platforms, including CPUs, GPUs, and FPGAs. This integration allows both compilers to represent and manipulate SYCL code at multiple levels of abstraction, facilitating more effective optimization passes and enabling support for a wider range of target devices without requiring substantial modifications to the front-end compiler.
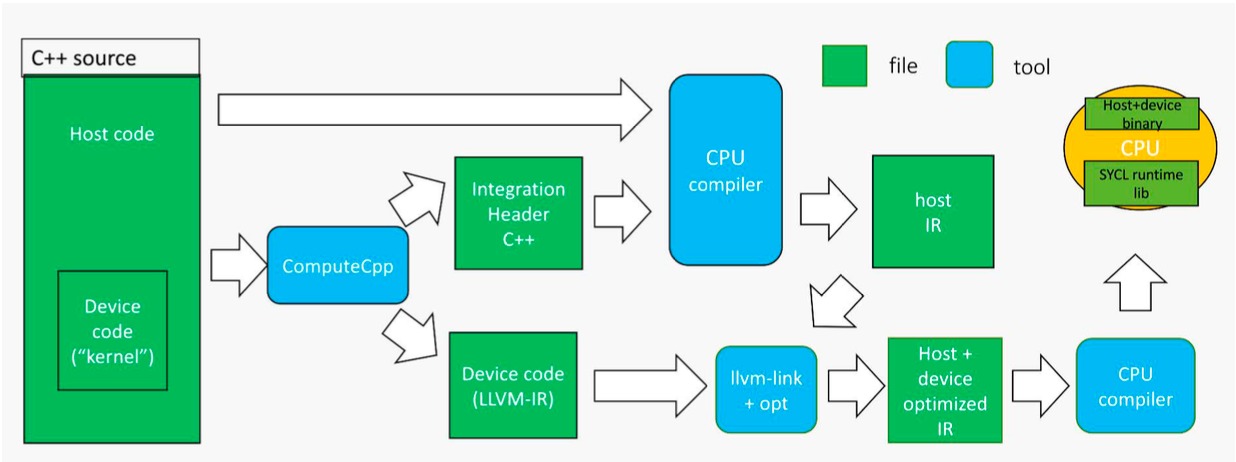
Portability and Abstraction: The Emergent Power of SYCL
SYCL’s strength lies in its ability to decouple algorithms from the underlying hardware, fostering remarkable code portability. By leveraging modern compilers and a single-source approach, developers can construct applications that seamlessly operate across a spectrum of computational devices. This includes traditional Central Processing Units, Graphics Processing Units optimized for parallel processing, and specialized accelerators designed for specific tasks. The framework achieves this by defining a heterogeneous programming model, allowing code to be written independently of the target architecture, and relying on the compiler to generate optimized instructions for each platform. This abstraction not only streamlines the development process, reducing the need for platform-specific code, but also unlocks the potential to deploy applications on diverse hardware without significant modifications, ultimately maximizing computational efficiency and return on investment.
hipSYCL represents a practical advancement in SYCL implementation, leveraging the Hardware Capability Factor (HCF) to dramatically improve code portability. This approach allows a single codebase to be compiled and executed efficiently across a wider spectrum of hardware platforms, including CPUs, GPUs from vendors like NVIDIA and AMD, and emerging accelerators. By abstracting away the specifics of each architecture through HCF, hipSYCL facilitates a unified code presentation, meaning developers no longer need to maintain separate versions tailored to individual hardware. This not only simplifies the development process but also significantly reduces costs associated with platform-specific optimization and maintenance, paving the way for more adaptable and future-proof high-performance applications.
A core benefit of SYCL lies in its ability to drastically simplify the software development lifecycle and reduce associated costs through hardware abstraction. Traditionally, developers faced the complex task of tailoring code to the specific instruction sets and memory models of each target device – a process demanding significant time and resources. SYCL circumvents this by providing a unified programming model; developers write code against this abstraction layer, and the SYCL implementation handles the necessary translation and optimization for the underlying hardware. This “write once, deploy anywhere” capability not only accelerates development timelines but also minimizes the need for platform-specific expertise, ultimately lowering costs and expanding the reach of parallel applications across diverse computing environments.
A substantial advancement in heterogeneous computing lies in the capacity to deploy a single codebase across markedly different hardware architectures, specifically NVIDIA’s PTX and AMD’s GCN. Previously, developers faced the daunting task of maintaining separate code versions optimized for each platform, significantly increasing development time and cost. This unified approach, enabled by SYCL and implementations like hipSYCL, streamlines the process by abstracting away hardware-specific details. Consequently, applications can leverage the strengths of both NVIDIA and AMD accelerators without requiring extensive code modifications, fostering greater flexibility and potentially unlocking performance benefits across a wider range of computing devices. This capability not only reduces the burden on developers but also encourages broader adoption of heterogeneous computing paradigms.
The survey of SYCL compiler implementations reveals a fascinating trend: robustness emerges not from centralized design, but from the interplay of local compilation rules. The shift towards models like SSCP and the adoption of MLIR aren’t about imposing order; they’re about establishing frameworks where optimization and portability naturally arise from the interaction of compiler passes. This aligns with the ancient wisdom of Epicurus, who observed, “It is not possible to live pleasantly without living prudently and honorably and justly.” Similarly, effective heterogeneous computing doesn’t stem from brute-force control, but from the judicious application of localized optimization strategies, allowing monumental shifts in performance to occur organically.
What Lies Ahead?
The pursuit of portable, high-performance heterogeneous computing, as exemplified by developments in SYCL compilation, continually reveals the limitations of centrally planned optimization. Each attempt to dictate precisely how computation should occur on diverse hardware underscores a fundamental truth: performance isn’t imposed, it emerges. The current focus on Single-Source Single Compiler Pass (SSCP) and the adoption of Multi-Level Intermediate Representation (MLIR) represent sophisticated efforts to influence this emergence, to nudge the system toward desirable outcomes, but control remains an illusion. The benefits observed are not the product of mastery, but of creating environments where self-organization can flourish.
Future progress will likely involve less emphasis on monolithic compilation strategies and more attention to runtime adaptability. Systems that can dynamically analyze workloads and reconfigure themselves – that can learn from the small decisions of countless kernels – will inevitably outperform those rigidly pre-optimized. The challenge isn’t to build a ‘perfect’ compiler, but to create compilers that are exceptionally good at observing and responding to the conditions they find.
Ultimately, the field must accept that the ‘best’ optimization isn’t a fixed point, but a constantly shifting equilibrium. Success will be measured not by absolute speed, but by resilience-by the ability to maintain acceptable performance across a perpetually evolving landscape of hardware and workloads. The goal, therefore, is not control, but graceful adaptation to the inevitable entropy of complex systems.
Original article: https://arxiv.org/pdf/2602.21113.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Robinhood’s $75M OpenAI Bet: Retail Access or Legal Minefield?
- All Skyblazer Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- How to Catch All Itzaland Bugs in Infinity Nikki
- Speedsters Sandbox Roblox Codes
- Top 10 Must-Watch Isekai Anime on Crunchyroll Revealed!
- Invincible: 10 Strongest Viltrumites in Season 4, Ranked
- Black Sun Shield Location In Crimson Desert (Buried Treasure Quest)
- Who Can You Romance In GreedFall 2: The Dying World?
- USD CNY PREDICTION
2026-02-25 19:02