Author: Denis Avetisyan
Researchers have developed a system that uses the power of artificial intelligence to automatically repair compilation errors in the complex world of embedded system development.
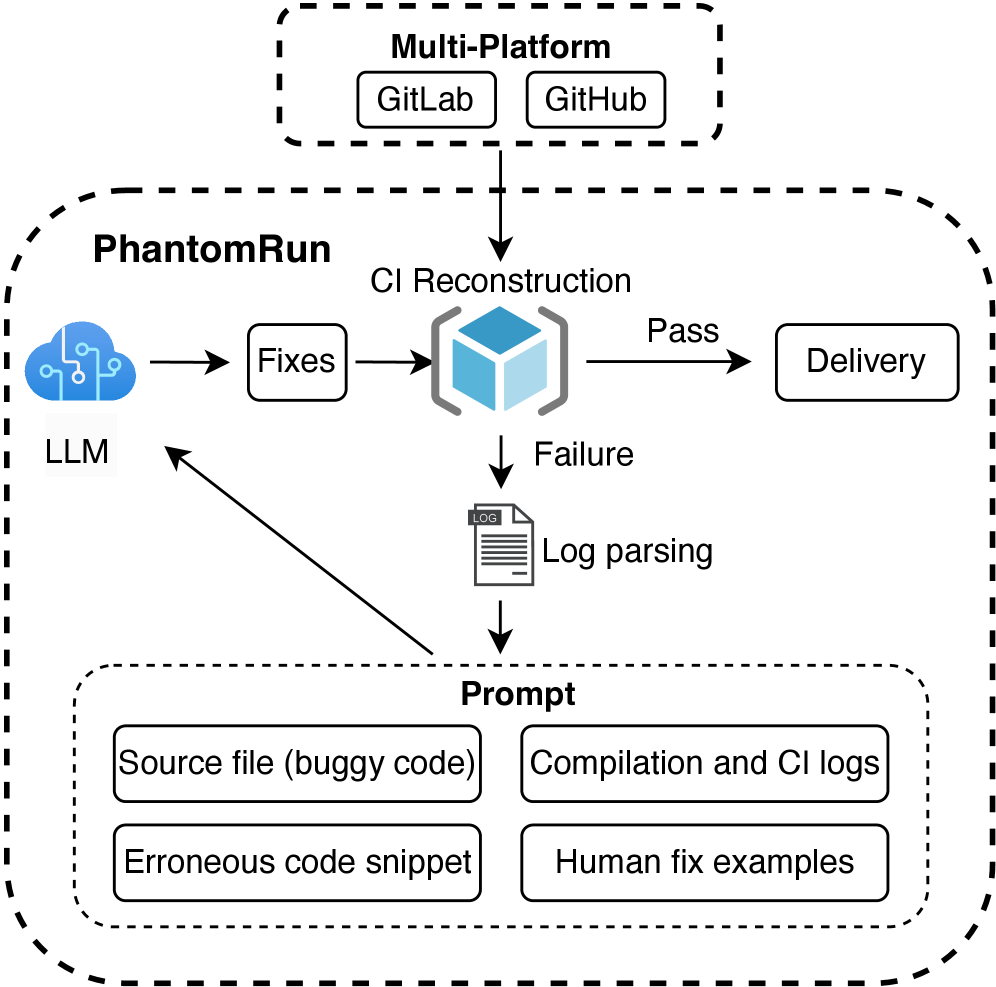
PhantomRun leverages large language models to achieve up to 45% success in automatically resolving build failures within continuous integration pipelines for embedded open source software.
Despite the increasing reliance on Continuous Integration pipelines for embedded systems, compilation failures remain a significant drain on developer time and resources. This paper introduces PhantomRun: Auto Repair of Compilation Errors in Embedded Open Source Software, a novel framework leveraging Large Language Models to automatically diagnose and repair these failures. PhantomRun achieves up to a 45% success rate in fixing compilation errors across multiple projects by intelligently synthesizing solutions from build logs, source code, and historical data. Could automated repair systems like PhantomRun fundamentally shift the developer workflow and accelerate innovation in embedded systems development?
Unveiling the Compilation Bottleneck
The increasing sophistication of modern embedded systems necessitates intricate build processes and the adoption of continuous integration (CI) pipelines to manage code complexity. However, this very infrastructure, designed to accelerate development, paradoxically introduces a heightened susceptibility to compilation errors. As systems incorporate a growing number of software components, hardware dependencies, and specialized libraries, the potential for conflicts and misconfigurations within the build environment expands exponentially. This creates a challenging scenario where even minor inconsistencies can trigger cascading failures, demanding substantial time and resources for diagnosis and resolution – a common obstacle in the fast-paced world of embedded systems engineering.
Embedded systems development is uniquely plagued by compilation errors rooted in intricate hardware dependencies, significantly impeding progress. Recent analysis demonstrates that 71.5% of these errors stem from these hardware-related issues – a stark contrast to the 37% observed in more traditional industrial systems. This disproportionate frequency necessitates extensive manual debugging, as seemingly minor discrepancies between software expectations and actual hardware behavior can halt the entire development cycle. The complexity arises from the tight coupling between software and specific hardware configurations, requiring developers to meticulously account for variations in peripherals, memory maps, and real-time constraints, ultimately creating a substantial bottleneck in rapid iteration and deployment.
The resolution of errors in embedded systems development often presents a significant impediment to progress, largely because traditional debugging methods are both protracted and demand specialized expertise. Unlike software development where many errors stem from logical flaws easily addressed with standard tools, embedded systems frequently encounter issues rooted in intricate hardware interactions and subtle dependency conflicts. This necessitates deep understanding of both the software and the underlying platform, effectively creating a bottleneck where even experienced developers can spend considerable time isolating and rectifying problems. Consequently, the rapid iteration cycles crucial for innovation and timely product delivery are frequently stalled, hindering the ability to quickly prototype, test, and refine embedded applications.

Automated Repair: A System That Learns to Fix Itself
PhantomRun is an automated repair framework integrated into Continuous Integration (CI) pipelines to address compilation failures. The system leverages large language models (LLMs) to automatically diagnose and correct errors that prevent code from compiling successfully. Upon encountering a compilation failure, PhantomRun utilizes the LLM to generate potential fixes, which are then applied and re-tested within the CI environment. This automated process aims to reduce developer intervention required to resolve common compilation issues, accelerating the development cycle and improving overall pipeline efficiency. The framework is designed to operate without requiring manual labeling of errors or fixes, relying instead on the LLM’s pre-existing knowledge and reasoning capabilities.
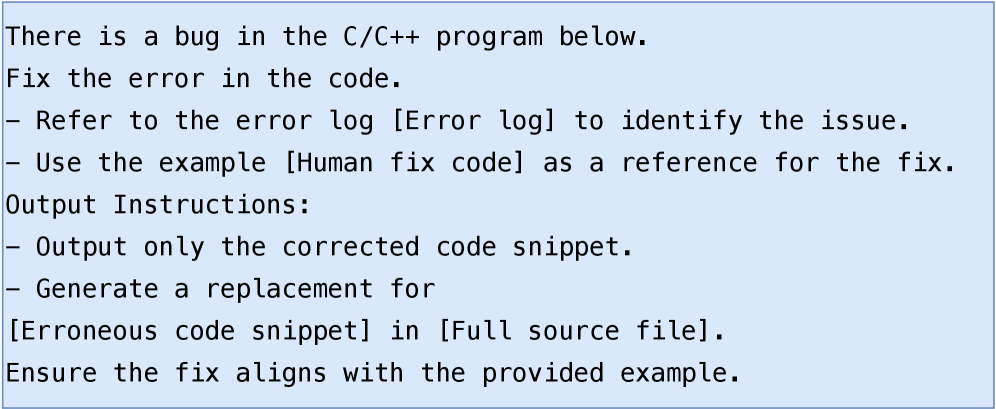
PhantomRun leverages a dataset of previously resolved compilation errors to train large language models (LLMs) in code repair. This training process involves presenting the LLM with failing code examples alongside their corresponding human-authored fixes. The LLM learns to map error patterns – identified through compiler output and code context – to probable correction strategies. When presented with a new compilation failure, PhantomRun uses the trained LLM to generate potential code modifications, effectively suggesting corrections based on the patterns observed during training. The system then applies these suggested modifications and re-attempts compilation to verify the fix.
The efficacy of PhantomRun’s automated repair stems from the underlying large language model’s capacity to parse code not merely as text, but as a structured representation of computational logic. This allows the LLM to analyze the syntactic and semantic relationships within the failing code, identifying discrepancies between the intended functionality and the observed error. By leveraging its training on a corpus of code fixes, the model correlates error messages and surrounding code context with probable corrections, effectively simulating the reasoning process of a human developer diagnosing and resolving compilation failures. This contextual understanding extends beyond simple keyword matching; the LLM assesses variable usage, function calls, and overall program flow to pinpoint the root cause of the error and propose a semantically valid solution.
Validating Intelligence: LLM Performance in the Real World
The evaluation process incorporated two large language models, CodeT5+ and CodeLlama, to specifically address compilation errors encountered within a range of embedded systems projects. These projects included real-world codebases from RTEMS, Zephyr, OpenIPC, and STM32, representing diverse architectures and development environments. The selection of these projects aimed to provide a representative sample of the types of errors and code complexities typically found in embedded software development. The models were tasked with identifying and correcting compilation failures within these existing projects, providing a practical assessment of their ability to contribute to the embedded development workflow.
The evaluation methodology involved the analysis of over 10,000 pull and merge requests sourced from various embedded systems projects. This large dataset was processed to identify and reproduce a total of 4248 distinct compilation errors. Rigorous reproduction was critical to ensure accurate assessment; identified errors were verified to occur within a clean build environment before being presented to the Large Language Model (LLM) for attempted resolution. This process enabled a quantitative analysis of the LLM’s ability to correctly diagnose and repair actual, observed compilation failures within real-world embedded projects.
Evaluation of the PhantomRun system, leveraging the CodeLlama large language model, yielded a 45% success rate in automatically resolving compilation errors present in a dataset of 4248 errors derived from embedded systems projects. Further analysis of the successfully repaired errors indicates that approximately 45% of these fixes were accomplished with modifications requiring two or fewer lines of code, suggesting a capacity for concise and targeted error correction within the tested embedded systems context.
Towards Self-Healing Systems: A Paradigm Shift in Embedded Development
PhantomRun doesn’t merely streamline embedded systems development by automating error resolution; it fundamentally alters the cost structure. Instead of engineers painstakingly debugging obscure coding errors, the framework intelligently identifies and autonomously corrects a wide range of issues. This automation doesn’t simply accelerate the build cycle; it’s a reduction in the financial investment required for debugging. By minimizing the effort spent on error correction, PhantomRun allows development teams to dedicate more resources to innovation and feature implementation, ultimately leading to faster time-to-market and more robust embedded systems.
By automating the resolution of common compilation errors, PhantomRun shifts the developer experience in embedded systems. This allows engineers to dedicate valuable time and cognitive resources to designing novel features and optimizing system performance, rather than becoming bogged down in repetitive debugging cycles. The acceleration isn’t simply a matter of speed; it fosters a more creative and exploratory environment, enabling faster iteration on innovative ideas and ultimately leading to more sophisticated and reliable embedded applications. This focus on innovation, unlocked by automated error correction, promises to drastically reduce time-to-market and enhance competitiveness.
The emergence of adaptable frameworks heralds a transformative shift in embedded systems design, moving beyond simple error detection to genuine self-healing capabilities. These systems, powered by continuous learning algorithms, are envisioned to proactively identify, diagnose, and resolve issues without external intervention – significantly minimizing downtime and bolstering operational reliability. This isn’t merely about fixing bugs as they arise; the framework learns from past errors, anticipates potential failures, and dynamically adjusts system parameters to prevent recurrence. Such adaptability extends beyond software, potentially encompassing hardware-level optimizations and resource allocation, creating resilient systems capable of maintaining peak performance even in unpredictable or challenging environments. Ultimately, this pursuit of self-healing embedded systems promises a future where devices operate with unprecedented autonomy and dependability, reducing maintenance costs and unlocking new possibilities for innovation.
PhantomRun’s success isn’t merely about fixing compilation errors; it’s about systematically probing the boundaries of what constitutes ‘correct’ software. The framework, by attempting automated repair, essentially reverse-engineers the implicit rules governing the build process. This echoes Bertrand Russell’s observation that “The whole problem with the world is that fools and fanatics are so confident in their own opinions.” PhantomRun doesn’t confidently assume correctness; it tests, adapts, and learns from failure – a pragmatic approach to dependency management and a subtle admission that even well-established systems harbor inherent imperfections. Every successful repair is a testament to the framework’s ability to exploit these vulnerabilities and redefine the acceptable limits of code.
What’s Next?
The successes of PhantomRun, while notable, merely illuminate the scale of the problem. A 45% repair rate isn’t a solution; it’s a confession. The system-the entire edifice of embedded software development-routinely fails to compile itself, and this framework temporarily patches the leaks. One begins to suspect the failures aren’t random, but inherent to the complexity demanded of both the software and the developers attempting to manage it. Future work shouldn’t focus solely on increasing that percentage, but on understanding why these errors occur with such frequency.
Dependency management remains a particularly thorny issue. PhantomRun addresses compilation failures, but often those failures are symptoms of deeper architectural flaws. A truly robust system would proactively identify and prevent these flaws, perhaps by integrating formal verification techniques with the LLM-driven repair process. The challenge isn’t simply fixing broken code, but preventing it from breaking in the first place-a shift from reactive patching to preventative design.
Ultimately, the real question isn’t whether an LLM can fix compilation errors, but whether it can expose the fundamental limitations of our current software development methodologies. A bug, after all, is the system confessing its design sins. Further research should treat these failures not as anomalies to be corrected, but as data points revealing the fault lines in the very foundations of embedded systems development.
Original article: https://arxiv.org/pdf/2602.20284.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- Robinhood’s $75M OpenAI Bet: Retail Access or Legal Minefield?
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- How to Catch All Itzaland Bugs in Infinity Nikki
- Speedsters Sandbox Roblox Codes
- Invincible: 10 Strongest Viltrumites in Season 4, Ranked
- Re:Zero Season 4 Episode 3 Release Date & Where to Watch
- Who Can You Romance In GreedFall 2: The Dying World?
- Top 10 Must-Watch Isekai Anime on Crunchyroll Revealed!
- USD CNY PREDICTION
2026-02-26 01:38