Author: Denis Avetisyan
New research reveals that achieving high scores on reasoning tasks doesn’t guarantee a system’s ability to apply or justify its logic.
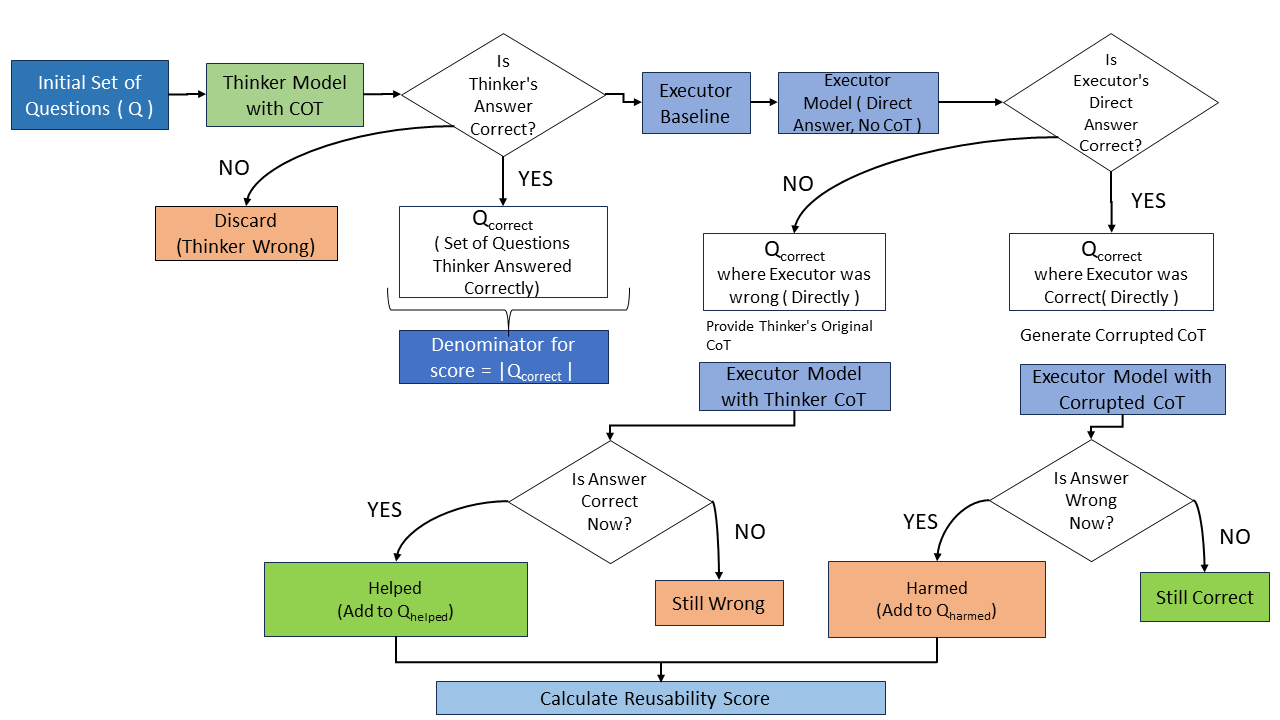
This paper introduces reusability and verifiability as key metrics for evaluating chain-of-thought reasoning in large language models, demonstrating that robust reasoning extends beyond simple accuracy.
While current evaluations of large language model reasoning prioritize target task accuracy, this narrow focus overlooks the quality and transferability of the reasoning process itself. The paper ‘Evaluating Chain-of-Thought Reasoning through Reusability and Verifiability’ introduces reusability and verifiability as novel metrics, decoupling reasoning generation from execution via a Thinker-Executor framework to assess these qualities. Surprisingly, the authors find limited correlation between standard accuracy and these new measures, and discover that specialized reasoning models don’t consistently outperform general-purpose LLMs in producing reusable or verifiable chains of thought. This raises a critical question: how can we develop more robust and meaningful benchmarks for evaluating the true reasoning capabilities of large language models?
The Limits of Prediction: Reasoning Beyond Pattern Matching
Despite advancements in natural language processing, large language models (LLMs) frequently falter when confronted with problems requiring extended, multi-step reasoning. While capable of generating human-quality text and demonstrating impressive linguistic skills, these models often struggle to maintain coherence and accuracy across complex logical sequences. This limitation stems not from a lack of knowledge, but from the difficulty in consistently applying that knowledge through numerous interconnected inferences. Essentially, LLMs excel at pattern recognition and prediction, yet struggle with the systematic, deliberate thought processes characteristic of robust reasoning – a crucial distinction that hinders their performance on tasks demanding careful planning and sequential problem-solving, even when possessing all the necessary information.
The Thinker-Executor framework fundamentally reshapes how large language models approach complex reasoning. Instead of attempting to solve a problem in a single, monolithic step, this architecture separates the process into distinct stages. First, a “thinker” module generates a sequence of intermediate reasoning steps – a plan of action, if you will – without actually performing any calculations. This plan is then passed to an “executor” module, which meticulously carries out each step, one at a time. This decoupling offers several benefits; it enhances reliability by isolating errors to specific execution stages, and it dramatically improves interpretability, as the generated reasoning steps provide a clear audit trail of the model’s thought process. Consequently, the Thinker-Executor framework allows models to tackle problems demanding multi-step logic with increased accuracy and transparency, moving beyond simply producing an answer to demonstrating how that answer was derived.
Chain-of-Thought: Articulating the Reasoning Process
Chain-of-Thought (CoT) reasoning is a technique used with Large Language Models (LLMs) that prompts the model to explicitly generate a series of intermediate reasoning steps before arriving at a final answer. This contrasts with directly prompting for an answer and has been shown to substantially improve performance on complex tasks requiring multi-step inference, such as arithmetic reasoning, common sense reasoning, and symbolic manipulation. By forcing the LLM to decompose the problem and articulate its thought process, CoT enables more accurate and reliable results, particularly in scenarios where a direct answer would likely be incorrect or lack sufficient justification. The technique’s effectiveness stems from mimicking human problem-solving strategies where intermediate steps are crucial for verifying accuracy and building confidence in the final solution.
Reusability, in the context of Chain-of-Thought (CoT) reasoning, quantifies the degree to which an Executor model can effectively utilize a reasoning path generated by a Thinker model. Measurements indicate that Reusability Scores can reach approximately 100%, contingent on the specific dataset employed and the strength of the Executor committee – a larger, more robust committee generally correlates with higher scores. This metric assesses whether the intermediate reasoning steps articulated by the Thinker are understandable and applicable for the Executor to arrive at the same conclusion, demonstrating the transferability of the reasoning process itself.
Verifiability, a key metric in evaluating Chain-of-Thought reasoning, quantifies the consistency of a solution’s reasoning path when generated by multiple independent “Executors.” Verifiability Scores, which can approach 100% depending on the dataset and the strength of the Executor committee, directly correlate to the trustworthiness of the final answer. Higher scores indicate a strong consensus in the reasoning process, suggesting the solution isn’t a result of stochastic LLM behavior, but rather a logically consistent derivation. Data indicates a notable positive correlation between the size and capability of the Executor committee – termed “committee strength” – and both Verifiability and Reusability scores, implying that a more robust evaluation process yields more reliable and reproducible reasoning paths.
Benchmarking Reasoning: Assessing Performance Across Domains
The Thinker-Executor Framework was subjected to rigorous evaluation using a suite of established benchmarks representing diverse reasoning challenges. These included GSM8K and SVAMP for assessing mathematical reasoning capabilities, StrategyQA and ARC-Challenge to test knowledge-based reasoning, and CommonSenseQA to probe commonsense understanding. Utilizing these benchmarks allowed for a comparative analysis of the framework’s performance across distinct domains, providing insights into its generalizability and robustness. The selected benchmarks are widely recognized within the research community and offer standardized evaluation metrics for comparing different reasoning systems.
Evaluation of the Thinker-Executor Framework across GSM8K, SVAMP, StrategyQA, ARC-Challenge, and CommonSenseQA datasets consistently yielded performance improvements. Specifically, gains were observed in mathematical reasoning (GSM8K, SVAMP), knowledge-based reasoning (StrategyQA, ARC-Challenge), and commonsense reasoning (CommonSenseQA). This demonstrates the framework’s ability to enhance reasoning capabilities independent of the specific domain or required knowledge type, indicating broad applicability to a diverse range of problem-solving tasks. These results were obtained using various Large Language Models (LLMs) as the ‘Thinker’ component, further supporting the framework’s generalizability.
The Thinker-Executor framework was tested with multiple large language models (LLMs) serving as the ‘Thinker’ component, including Gemma-27B, Llama3-8B, DeepSeek-R1-14b, and Phi4-reasoning-14b, to demonstrate its architectural flexibility. Analysis across GSM8K, SVAMP, StrategyQA, ARC-Challenge, and CommonSenseQA datasets revealed a consistently low correlation between overall accuracy and key reasoning characteristics-specifically, the reusability and verifiability of the generated reasoning steps-as measured by Kendall’s τ values. This indicates that achieving high accuracy on these benchmarks does not necessarily imply the model is generating robust or transparent reasoning processes.
Towards Transparent Reasoning: Beyond Prediction to Deliberation
Recent advancements in artificial intelligence are refining the approach to complex problem-solving through methods like Program of Thoughts and Faithful CoT, both building upon the established Thinker-Executor paradigm. These techniques move beyond simple sequential thought processes by incorporating external tools and, crucially, symbolic representations – essentially, translating abstract concepts into concrete, manipulable forms. This integration isn’t merely about adding complexity; it’s about enhancing control and interpretability, allowing for a more transparent understanding of how a solution is reached. By decoupling computation from the reasoning process, each step becomes verifiable, mitigating the risk of errors propagating through the system and ultimately bolstering the reliability of the final output. The ability to inspect and validate individual reasoning stages represents a significant leap towards building more trustworthy and accountable AI systems.
Recent advancements in artificial intelligence are increasingly focused on separating the processes of computation and reasoning. By decoupling these functions, systems can not only arrive at solutions but also provide a transparent record of how those solutions were reached. This separation facilitates meticulous verification of each reasoning step, allowing for the identification and correction of errors with greater precision. Consequently, the reliability of the final outcome is substantially improved, as the system’s logic is open to scrutiny and validation. This approach moves beyond simply obtaining an answer to building confidence in the reasoning process itself, paving the way for more trustworthy and accountable AI systems.
Continued advancements in artificial intelligence hinge on the development of reasoning systems capable of seamlessly incorporating external knowledge and sophisticated tools. Current research prioritizes creating not only more robust methods for this integration, but also scalable solutions that can handle increasingly complex problems. Recent evaluations demonstrate the reliability of these advancements; specifically, a perfect agreement – indicated by a Kendall’s τ correlation of 1.0 for Reusability – was observed in the ranking of reasoning approaches by both a focused and comprehensive evaluation committee. This strong validation suggests that ongoing efforts to decouple computation from reasoning, and to leverage external resources, are yielding consistently reliable and reusable AI systems, ultimately pushing the boundaries of what these systems can achieve.
The pursuit of evaluating large language models often fixates on achieving high accuracy, yet this work rightly redirects attention to the underlying quality of that reasoning. It underscores that a correct answer doesn’t inherently signify a robust or transferable process-a point elegantly captured by Carl Friedrich Gauss: “If I have seen further it is by standing on the shoulders of giants.” The study’s focus on reusability and verifiability embodies this sentiment; true progress isn’t merely about reaching new heights, but ensuring the foundations upon which those achievements rest are solid and accessible for others to build upon. By prioritizing these metrics, the research promotes a more sustainable and genuinely insightful approach to LLM development, moving beyond superficial performance to assess the inherent utility of the reasoning process itself.
What Remains to be Seen
The insistence on accuracy, as though a correct answer absolves the mechanism that produced it, appears increasingly… quaint. This work rightly shifts focus to the underlying process of reasoning – its reusability and, crucially, its verifiability. The observation that high performance does not guarantee transferable skill is less a revelation than a long-overdue acknowledgement of fundamental principles. Code should be as self-evident as gravity, and yet the black box persists.
Future work must confront the limitations inherent in evaluating reasoning through other language models. It is a hall of mirrors, a recursive definition begging for external anchors. True progress demands metrics derived from first principles – perhaps information-theoretic measures of complexity reduction, or demonstrable performance on tasks explicitly designed to expose brittleness. Intuition is the best compiler, but intuition requires validation beyond simple input-output correlation.
The Thinker-Executor framework offers a promising architectural direction, but it merely pushes the problem of opacity inward. The ultimate question isn’t whether these systems can reason, but whether their reasoning can be understood, predicted, and – when necessary – corrected. Anything less is simply sophisticated mimicry.
Original article: https://arxiv.org/pdf/2602.17544.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Shadow Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- All Skyblazer Armor Locations in Crimson Desert
- Best Bows in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- Wings of Iron Walkthrough in Crimson Desert
- How to Craft the Elegant Carmine Armor in Crimson Desert
- Keeping Large AI Models Connected Through Network Chaos
2026-02-22 04:49