Author: Denis Avetisyan
As storage systems grow in complexity, traditional testing methods struggle to guarantee data integrity, demanding new approaches to uncover hidden vulnerabilities.
This review explores the limitations of current fuzzing techniques and examines how artificial intelligence can improve storage system testing by addressing long-horizon behavior and semantic correctness.
Despite decades of research, ensuring the correctness of modern storage systems remains surprisingly difficult due to inherent complexities like non-deterministic interleavings and long-horizon state evolution. This survey, ‘Testing Storage-System Correctness: Challenges, Fuzzing Limitations, and AI-Augmented Opportunities’, systematically examines existing testing techniques-from concurrency testing to fault injection-and reveals fundamental mismatches between conventional fuzzing approaches and the unique semantics of storage. We argue that effectively addressing these challenges requires moving beyond purely random testing and leveraging artificial intelligence to guide exploration and validate semantic correctness. Can AI-driven testing unlock a new generation of robust and reliable storage infrastructure?
The Evolving Landscape of State: Beyond Simple Storage
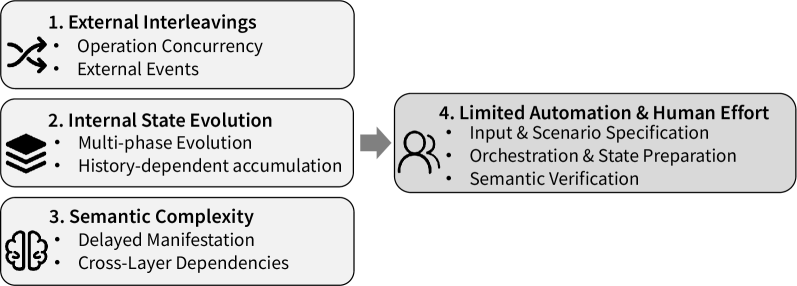
Contemporary storage architectures are rapidly evolving beyond simple data repositories into complex stateful systems, where operational behavior isn’t solely determined by inputs, but crucially depends on the system’s prior history and internal configuration. This shift introduces a significant challenge for verification and validation; traditional testing methodologies, designed for stateless systems with predictable responses, struggle to adequately explore the exponentially expanding state space. Each prior operation subtly alters the system’s response to subsequent requests, creating a vast network of potential interactions and edge cases. Consequently, ensuring the reliability of these increasingly sophisticated systems demands innovative testing strategies capable of comprehensively mapping and validating this intricate state-dependent behavior, lest latent bugs emerge and compromise data integrity.
As storage systems evolve into complex, stateful entities, conventional testing methodologies face an escalating challenge: the sheer size of the state space. These systems don’t simply respond to inputs; their behavior is intrinsically linked to their history and internal configuration, creating a multitude of possible states. Exhaustively testing every potential scenario becomes computationally impractical, if not impossible, leaving vast areas of the system unexplored. Consequently, latent bugs – errors that remain dormant until triggered by rare state transitions – become increasingly likely. This incomplete coverage manifests as unpredictable behavior, impacting data integrity and overall system reliability, as seemingly identical inputs can yield different, and potentially erroneous, outcomes depending on the system’s prior state.
The true measure of a modern storage system’s robustness extends far beyond simply preventing failures; it fundamentally depends on maintaining what is known as semantic correctness. This principle dictates that the system not only avoids crashes or errors, but consistently delivers logically sound and accurate data, preserving the intended meaning of information throughout its lifecycle. Unlike traditional systems where a lack of response was often the primary concern, stateful systems require validation of data integrity – ensuring that operations adhere to defined rules and that data relationships remain consistent even in the face of concurrent access or partial failures. Achieving semantic correctness demands rigorous testing methodologies that verify not just that an operation completes, but how it completes, and whether the resulting data state accurately reflects the intended outcome. Without this level of assurance, subtle bugs can erode data trustworthiness, leading to cascading errors and unpredictable behavior that undermines the entire system’s reliability.
Beyond Brute Force: Intelligent Approaches to System Validation
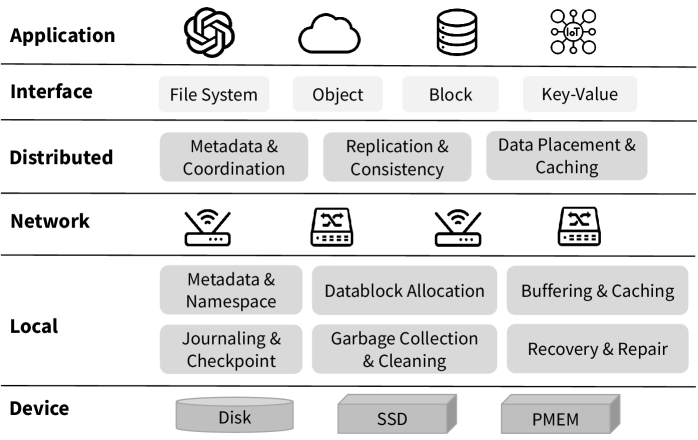
Traditional fuzzing and concurrency testing methods, while beneficial for identifying basic errors, frequently struggle with complex systems exhibiting state-dependent failures. Fuzzing typically focuses on generating a high volume of random or mutated inputs, but lacks the ability to consistently reproduce and isolate failures triggered by specific sequences of events or internal system states. Similarly, concurrency testing, often reliant on simulating multiple threads or processes, may not adequately explore the vast state space resulting from intricate interactions between concurrent operations. These approaches often miss subtle errors that only manifest under specific, rarely encountered conditions, or require deep analysis of system logs to diagnose, limiting their effectiveness in uncovering nuanced bugs in modern, stateful systems.
LongHorizonWorkload testing, designed to evaluate system stability and performance over prolonged operational periods, presents substantial practical challenges. Implementing these tests necessitates significant computational resources, including storage capacity and processing power, to simulate extended durations and realistic data volumes. Furthermore, the design of the workload itself is critical; it must accurately reflect anticipated usage patterns and edge cases to effectively reveal latent defects related to state evolution, data corruption, or resource exhaustion. Without careful workload design, the tests may not adequately stress the system or provide meaningful insights into long-term reliability.
AI-driven testing represents a shift in storage system validation, utilizing machine learning algorithms to enhance test effectiveness and efficiency. This approach moves beyond traditional methods by intelligently prioritizing test cases based on predicted failure potential and dynamically exploring the system’s state space to uncover previously hidden defects. The survey details how these techniques specifically address limitations in current concurrency testing, long-horizon workload analysis, and semantic correctness validation – areas often requiring extensive resources and prone to incomplete coverage. By leveraging AI, testing can focus on edge cases and complex interactions, improving the detection of state-dependent errors and ensuring more robust storage system performance.
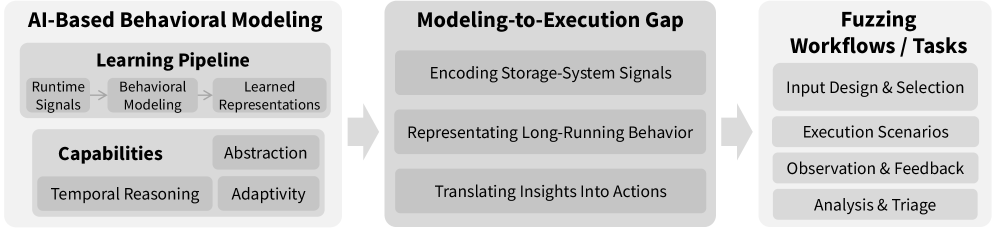
Bridging the Gap: From Model Insight to Actionable Validation
The ModelingToExecutionGap represents a significant obstacle in AI-Driven Testing, specifically concerning the translation of learned storage behavior models into actionable test cases. AI models can effectively capture complex patterns and anomalies from storage system data, but converting these observations into concrete test instructions-such as specific read/write operations or configuration settings-requires a defined process. This gap arises because models often express behavior at an abstract level, while test execution demands precise, low-level commands. Bridging this gap necessitates robust mechanisms for mapping model outputs to test inputs, including techniques for feature selection, parameter tuning, and automated test case generation, ensuring that the AI’s insights directly inform and improve testing effectiveness.
Large Language Models (LLMs) enable failure detection by analyzing system behavior and identifying deviations from expected semantic properties, a capability often exceeding traditional test methods. These models are trained on data representing correct system operation and can then assess new behavior for subtle inconsistencies that indicate semantic violations – errors in meaning or logical correctness, rather than simple functional failures. This approach is particularly effective in detecting complex errors related to data integrity, consistency, and adherence to specified protocols, offering improved support for verifying semantic correctness in storage systems and related applications. The technique focuses on verifying what the system does, rather than if it does it, thereby uncovering issues that might bypass conventional tests focused solely on code coverage or functional validation.
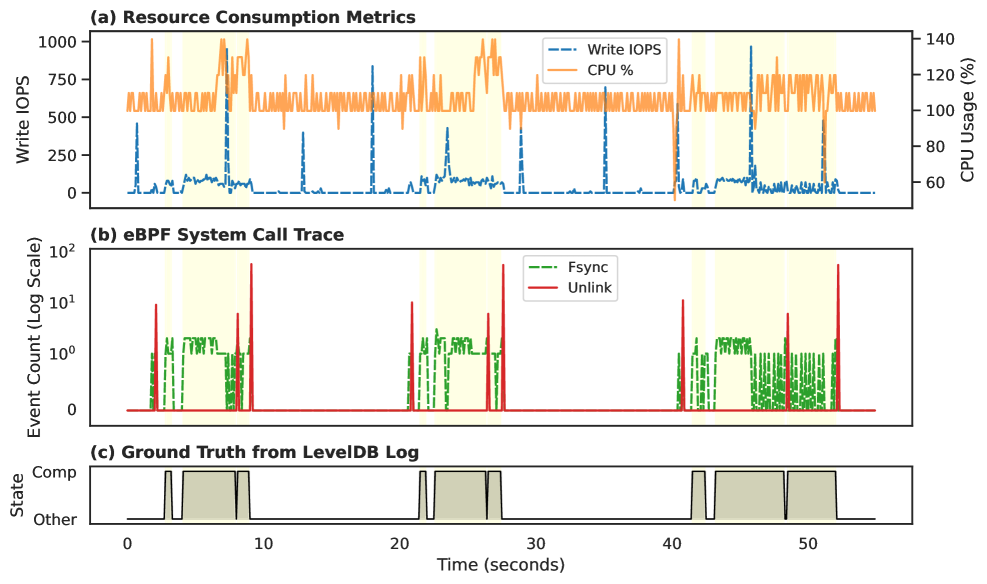
Implementation of LLM-based failure detection on the LevelDB key-value store has proven effective in identifying inconsistencies within the WriteAheadLog (WAL). The WAL is critical for ensuring data durability; errors in its maintenance can lead to data loss or corruption. Specifically, the approach analyzes WAL entries to validate the semantic correctness of operations, detecting scenarios where committed data is not consistently reflected in the database. This validation process identified potential durability failures related to incomplete or corrupted WAL records, enabling preemptive error detection and preventing data inconsistencies that traditional functional or performance tests might overlook. The technique focuses on verifying the logical sequence of WAL operations and confirming that recovery scenarios accurately reflect committed data, thus bolstering LevelDB’s data integrity.

Toward Resilient Systems: The Impact of Proactive Validation
Traditional methods of ensuring system durability, such as `CrashConsistencyAnalysis`, often focus on verifying data integrity after a failure, but may not fully capture errors arising from logical inconsistencies within the system’s operations. This approach introduces semantic validation as a complementary layer of defense, actively scrutinizing the meaning of data and the validity of state transitions. By confirming that operations adhere to the system’s intended logic before they are executed, semantic validation proactively identifies potential failures that might bypass crash-focused analyses. This dual approach-combining reactive crash consistency checks with proactive semantic verification-significantly enhances overall system resilience, reducing the likelihood of subtle, logic-based errors propagating into costly outages or data corruption.
The proactive identification of systemic flaws during development significantly mitigates the potential for disruptive outages and data compromise once a system is deployed. Addressing vulnerabilities early avoids the escalating costs associated with rectifying issues in a live production environment, where even brief interruptions can lead to substantial financial losses and reputational damage. This preventative approach not only reduces the risk of data corruption or loss but also streamlines the debugging process, as errors are isolated and resolved within a controlled setting. Consequently, prioritizing early failure detection fosters a more robust and reliable system, ultimately enhancing user trust and operational efficiency.
The advent of LLM-BasedFailureDetection marks a considerable advancement in the pursuit of automated error identification within complex StatefulSystems. Traditionally, pinpointing nuanced failures – those not manifesting as simple crashes or obvious inconsistencies – demanded extensive manual review and expert intuition. This new approach leverages the reasoning capabilities of large language models to analyze system behavior, interpret logs, and predict potential issues before they escalate. By learning patterns from both successful and failing operations, these models can flag anomalies that might otherwise go unnoticed, significantly reducing the reliance on reactive debugging and fostering a proactive stance towards system stability. This automated scrutiny promises to not only accelerate the development cycle but also enhance the overall reliability of increasingly intricate stateful applications.
The pursuit of storage-system correctness, as detailed in the survey, reveals a fundamental truth about complex systems: their inherent susceptibility to decay over time. This aligns with Claude Shannon’s assertion: “The most important thing is to have a system that works.” The article highlights the limitations of traditional fuzzing in capturing long-horizon behaviors-those subtle, time-dependent errors that accumulate and manifest as data corruption or system failure. These failures aren’t abrupt collapses, but rather a gradual degradation, mirroring the inevitable entropy of any engineered structure. Addressing semantic correctness, a core focus of the study, is about building systems that don’t just function now, but maintain integrity as time progresses, acknowledging that incidents are, in essence, steps toward a more robust maturity.
What Lies Ahead?
The chronicle of storage systems is, inevitably, one of increasing complexity. Each layer of abstraction, each optimization for performance, introduces new surfaces for failure – and a lengthening timeline on which those failures can manifest. This survey highlights the limitations of current testing methodologies, where fuzzing, while valuable for short-term discovery, struggles to probe the long-horizon behaviors critical to data durability. The system’s log is merely a record of past states, not a guarantee of future consistency.
The promise of artificial intelligence lies not in replacing testing, but in augmenting it. AI offers the potential to model semantic correctness – to verify not just that a system responds, but whether its response is meaningful within the broader data ecosystem. However, deploying these intelligent testers is itself a moment on the timeline, subject to the same decay as the systems they evaluate. The algorithms, too, will age, their effectiveness eroding as systems evolve.
Ultimately, the field requires a shift in perspective. Testing isn’t about achieving a static ‘correctness,’ but about understanding a system’s failure modes and building resilience against them. The goal isn’t immortality, but graceful aging – a prolonged period of useful life, even as entropy inevitably asserts itself. The true challenge is not simply finding bugs, but predicting where, when, and how the system will deviate from its intended state.
Original article: https://arxiv.org/pdf/2602.02614.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- All Shadow Armor Locations in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- Best Bows in Crimson Desert
- Keeping Large AI Models Connected Through Network Chaos
- How to Craft the Elegant Carmine Armor in Crimson Desert
- All Icewing Armor Locations in Crimson Desert
2026-02-04 21:13