Author: Denis Avetisyan
New research reveals that current methods for evaluating the security of code created by artificial intelligence are often misleading, and proposes a more robust, human-guided approach.
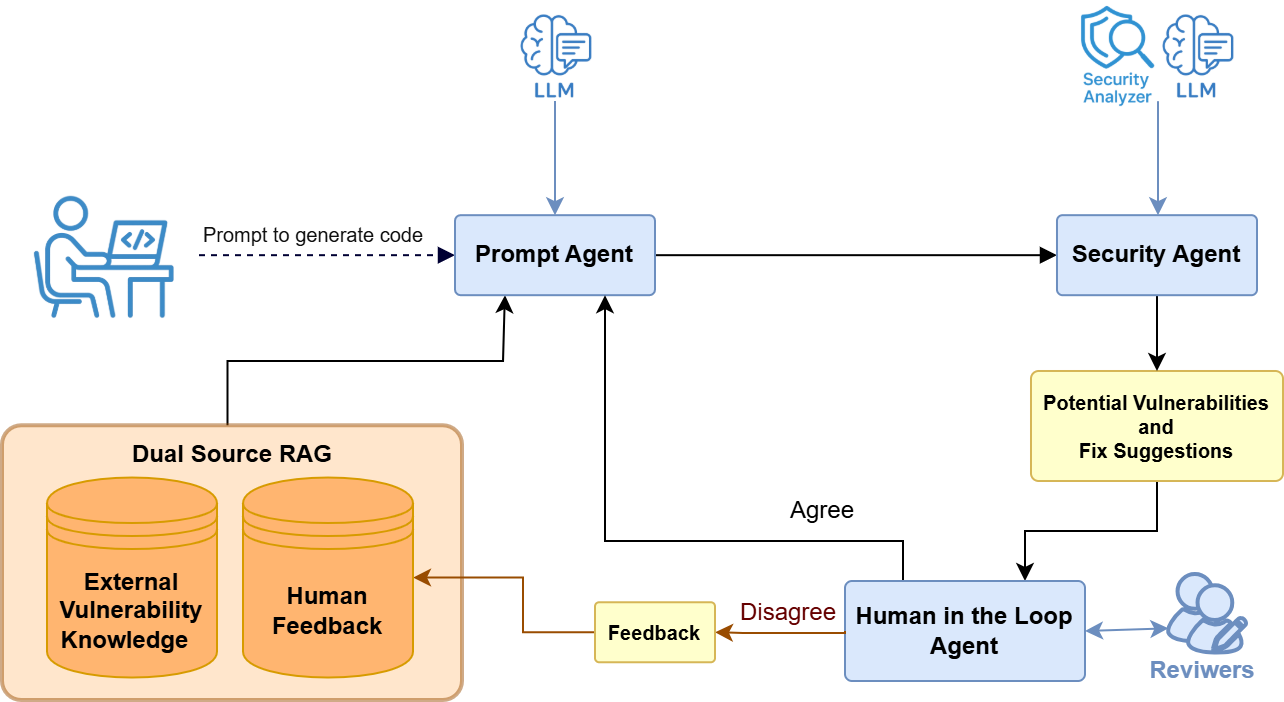
Integrating persistent human feedback with retrieval-augmented generation and static analysis improves the reliability of secure code generation and vulnerability detection.
Despite growing reliance on automated tools, evaluating the security of code generated by large language models remains a surprisingly unreliable process. This paper, ‘Persistent Human Feedback, LLMs, and Static Analyzers for Secure Code Generation and Vulnerability Detection’, investigates the discrepancies between static analysis tools and human expert assessments of 1,080 LLM-generated code samples, revealing substantial inaccuracies in automated evaluations. Our analysis demonstrates that while static analyzers often agree in aggregate, their per-sample accuracy is considerably lower than expected, highlighting the need for more robust evaluation methods. Consequently, we propose a framework integrating persistent human feedback into a dynamic retrieval-augmented generation pipeline-but can this approach effectively bridge the gap between automated assessment and genuine code security?
The Inevitable Tide: Vulnerabilities in Automated Code
Contemporary software creation increasingly depends on automated code generation – tools and processes that produce source code from other inputs, such as models or templates. While this accelerates development and boosts productivity, it simultaneously introduces new avenues for vulnerabilities. The very nature of generated code – often complex and created at scale – can obscure flaws, making them difficult to detect through conventional methods. Furthermore, vulnerabilities present in the code generation process itself can propagate across numerous applications, creating systemic risks. This reliance on automation means that a single compromised generator, or a flaw within one, can have far-reaching consequences, potentially impacting a vast number of software systems and users. The speed and scale of this automated process demands a reevaluation of security practices to address these unique challenges.
Despite their utility, conventional static analysis tools frequently encounter difficulties when assessing the intricacies of contemporary codebases, leading to a substantial number of false positives. A recent evaluation of 1,080 code samples revealed a significant discrepancy between automated and human assessments of code security; Semgrep deemed 60% secure, while CodeQL classified 80% as secure. Notably, human evaluation, considered the benchmark, only identified 61% of the same samples as secure, highlighting the limitations of current automated systems and the challenges in achieving accurate vulnerability detection without incurring a high rate of inaccurate warnings.
The escalating velocity of modern software development presents a significant challenge to traditional security practices, particularly regarding code inspection. Thorough manual review, once considered a cornerstone of vulnerability detection, is increasingly impractical due to its inherent limitations. Each line of code requires dedicated expert time, resulting in substantial financial costs and a bottleneck in the release cycle. Moreover, human reviewers are susceptible to fatigue and oversight, introducing the potential for errors – even skilled professionals can miss subtle vulnerabilities within complex codebases. This combination of escalating costs, time constraints, and the potential for human error means that manual inspection alone can no longer adequately safeguard against the growing number of software vulnerabilities being discovered and exploited.
LLMSecGuard: A Framework for Adaptive Code Security
LLMSecGuard establishes a multi-faceted framework for code security by combining static analysis, large language models, and human oversight. The system integrates established static analysis tools, specifically CodeQL and Semgrep, to identify potential vulnerabilities through pattern matching and code examination. These tools are then augmented by LLMs, which contribute to a more nuanced understanding of the code and can identify vulnerabilities beyond the scope of static analysis rules. Crucially, the framework incorporates human feedback as a validating step, allowing security experts to review LLM-identified issues, reduce false positives, and refine the overall accuracy of the vulnerability detection process. This integrated approach aims to leverage the strengths of each component – the precision of static analysis, the reasoning capabilities of LLMs, and the contextual understanding of human experts – to create a more robust and reliable security assessment system.
LLMSecGuard employs a multi-agent system consisting of a Prompt Agent, a Security Agent, and a Human-in-the-Loop Agent to facilitate code security analysis. The Prompt Agent is responsible for generating code snippets or test cases based on specified security requirements. The Security Agent then utilizes static analysis tools – such as CodeQL and Semgrep – to examine the generated code for potential vulnerabilities. Finally, the Human-in-the-Loop Agent provides expert review of the Security Agent’s findings, resolving ambiguities and reducing false positives through manual validation and feedback; this collaborative approach aims to combine automated analysis with human expertise for enhanced accuracy and efficiency.
LLMSecGuard seeks to enhance vulnerability detection by integrating static analysis with LLMs and human oversight to address inconsistencies between automated tools and expert evaluations. Current automated security tools exhibit a per-sample agreement rate of only 61% to 65% with human assessments, indicating a significant rate of false positives and false negatives. The framework leverages the precision of static analysis-like CodeQL and Semgrep-with the pattern recognition capabilities of LLMs, while a human-in-the-loop agent provides validation and refinement. This combined approach aims to minimize discrepancies, improve the accuracy of vulnerability identification, and reduce the incidence of both false alarms and missed vulnerabilities.
RCI Prompting: Iterative Refinement for Secure Code Generation
Recursive Critiques Improvement (RCI) prompting is an iterative process employing GPT-4o to enhance the security of code generated by large language models. The methodology functions by initially generating code, then utilizing GPT-4o to critique that code specifically for potential vulnerabilities. This critique informs a subsequent refinement of the code, and the process repeats-critique, revise-for a predetermined number of iterations. Each iteration aims to identify and remediate security weaknesses, progressively improving the code’s robustness. The system’s ability to self-assess and correct vulnerabilities distinguishes it from single-pass code generation techniques.
Recursive Critiques Improvement (RCI) prompting incorporates the Common Weakness Enumeration (CWE) Top 25 as a core component of its vulnerability detection process. The CWE Top 25 represents a prioritized list of the most prevalent and critical software security weaknesses, as determined by industry experts at MITRE. By explicitly grounding the LLM’s critique process in this knowledge base, RCI directs the model to specifically identify and mitigate issues like improper input validation, buffer overflows, SQL injection, and cross-site scripting. This targeted approach ensures that the LLM focuses its efforts on the vulnerabilities with the highest potential impact and frequency, rather than attempting to address a broader, less-focused range of potential weaknesses.
Evaluations using the LLMSecEval and SecurityEval datasets demonstrate a statistically significant reduction in vulnerabilities within code generated using Recursive Critiques Improvement (RCI) prompting. Specifically, LLMSecEval, focused on Python code, and SecurityEval, evaluating C/C++ code, were utilized to quantify the impact of RCI. Results indicate that the iterative refinement process, guided by GPT-4o and leveraging the CWE Top 25, consistently identifies and mitigates a substantial percentage of potential security flaws compared to baseline LLM code generation without RCI. The methodology involved automated vulnerability scanning and manual review to confirm the effectiveness of the mitigation strategies employed by the RCI prompting technique.
Evaluations using the LLMSecEval and SecurityEval datasets demonstrate the heightened efficacy of Recursive Critiques Improvement (RCI) prompting when applied to code written in Python and C/C++, respectively. LLMSecEval specifically targets vulnerabilities in Python code generated by large language models, while SecurityEval focuses on similar weaknesses in C/C++ programs. Comparative analysis of RCI-prompted code against baseline LLM outputs on these datasets consistently indicates a substantial reduction in the number and severity of identified vulnerabilities within these two programming languages, suggesting a language-specific benefit to the iterative refinement process facilitated by RCI.
Dual-Source RAG: Augmenting Analysis with Human Insight
The LLMSecGuard system significantly enhances its ability to identify and address software vulnerabilities through a process called Dual-Source Retrieval-Augmented Generation, or RAG. This innovative approach moves beyond solely relying on automated analysis by actively incorporating two crucial information streams into the prompt agent: detailed human feedback from security experts and a comprehensive database of known vulnerability patterns. By synthesizing these diverse sources, the system doesn’t just detect potential flaws, but develops a more nuanced understanding of the context surrounding them. This allows for a more informed assessment of risk and the generation of more effective remediation strategies, effectively bridging the gap between automated tools and human expertise to achieve a higher level of security analysis.
The enhanced security achieved through Dual-Source RAG stems from a broadened informational foundation for the Large Language Model. Rather than relying on a single knowledge base, the system integrates both human feedback – capturing nuanced understandings of security best practices – and external vulnerability data. This fusion allows the LLM to not only identify potential weaknesses in code, but also to refine its generative process, proactively incorporating secure coding principles. Consequently, the resulting code exhibits greater robustness, demonstrating a significant improvement in its ability to withstand attacks and maintain integrity, as the model learns to anticipate and mitigate vulnerabilities during the creation phase.
LLMSecGuard’s ongoing development hinges on integrating cutting-edge language models, notably CodeBERT and Llama/CodeLlama, as enhancements to the GPT-4o foundation. This strategic layering allows the system to not only understand and generate code, but to do so with increasing nuance and security awareness. CodeBERT’s proficiency in code comprehension, combined with Llama/CodeLlama’s code generation capabilities, expands LLMSecGuard’s ability to identify and address a broader spectrum of vulnerabilities. The architecture is designed for continuous adaptation; as new models emerge and the threat landscape shifts, LLMSecGuard can readily incorporate these advancements, ensuring it remains a robust and relevant tool for software security-a critical feature in the ever-evolving world of cybersecurity.
The system moves beyond dependence on automated vulnerability detection by integrating human expertise directly into the refinement process, allowing for a more nuanced understanding of complex security flaws. This holistic strategy doesn’t simply flag potential issues; it leverages human judgment to validate and contextualize findings, demonstrably improving accuracy and reducing false positives. Rigorous evaluation, evidenced by a Cohen’s Kappa of 0.94 – a metric signifying exceptionally high agreement among independent human reviewers – confirms the robustness and reliability of this approach. Such strong inter-rater agreement underscores the system’s ability to consistently identify and assess vulnerabilities in a manner that aligns with expert human analysis, suggesting a significant advancement in the field of automated code security.
The pursuit of secure code generation, as detailed in the research, reveals a fundamental truth about complex systems: their inherent susceptibility to decay. While benchmarks and automated tools offer temporary stability, they cannot account for the inevitable emergence of unforeseen vulnerabilities. This aligns with the observation that sometimes stability is just a delay of disaster. Vinton Cerf aptly stated, “The Internet is not about technology; it’s about people.” This holds true for code as well; even the most sophisticated algorithms require continuous human oversight to mitigate the effects of time and ensure long-term reliability, especially within a retrieval-augmented generation pipeline where context and human feedback are crucial for robust security.
What Remains to Be Seen
The pursuit of secure code generation, as demonstrated by this work, reveals not a problem of solving security, but of perpetually recalibrating against it. Current benchmarks, while useful for establishing a baseline, prove predictably brittle when confronted with the evolving landscape of vulnerabilities-a testament to the inherent limitations of static assessment. The integration of human feedback, presented here, is not a destination, but a necessary deceleration-every delay the price of understanding the nuances that automated systems invariably miss.
The architecture of this dynamic retrieval-augmented generation pipeline, while promising, exists as a snapshot in time. The true test will lie in its resilience-how gracefully does it age as adversarial attacks become more sophisticated, and as the very definition of ‘secure’ shifts with emerging threats? The field must move beyond simply detecting known patterns, and towards cultivating a system capable of anticipating the unknown unknowns.
Ultimately, the longevity of this approach – or any approach – depends not on its initial efficacy, but on its capacity for continuous adaptation. Architecture without history is fragile and ephemeral; similarly, security built on present knowledge is a temporary reprieve, not a lasting solution. The task, then, is not to build security, but to cultivate a system that learns, evolves, and endures.
Original article: https://arxiv.org/pdf/2602.05868.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- One Piece Chapter 1180 Release Date And Where To Read
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- All Shadow Armor Locations in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- How to Beat Stonewalker Antiquum at the Gate of Truth in Crimson Desert
- All Icewing Armor Locations in Crimson Desert
- Black Sun Shield Location In Crimson Desert (Buried Treasure Quest)
2026-02-07 21:28