Author: Denis Avetisyan
As AI agents become increasingly sophisticated, vulnerabilities extend beyond simple prompt manipulation, requiring a new approach to security assessment.
This paper introduces AgentFence, a methodology for identifying architectural weaknesses and operational failures in deep research agents to establish robust trust boundaries.
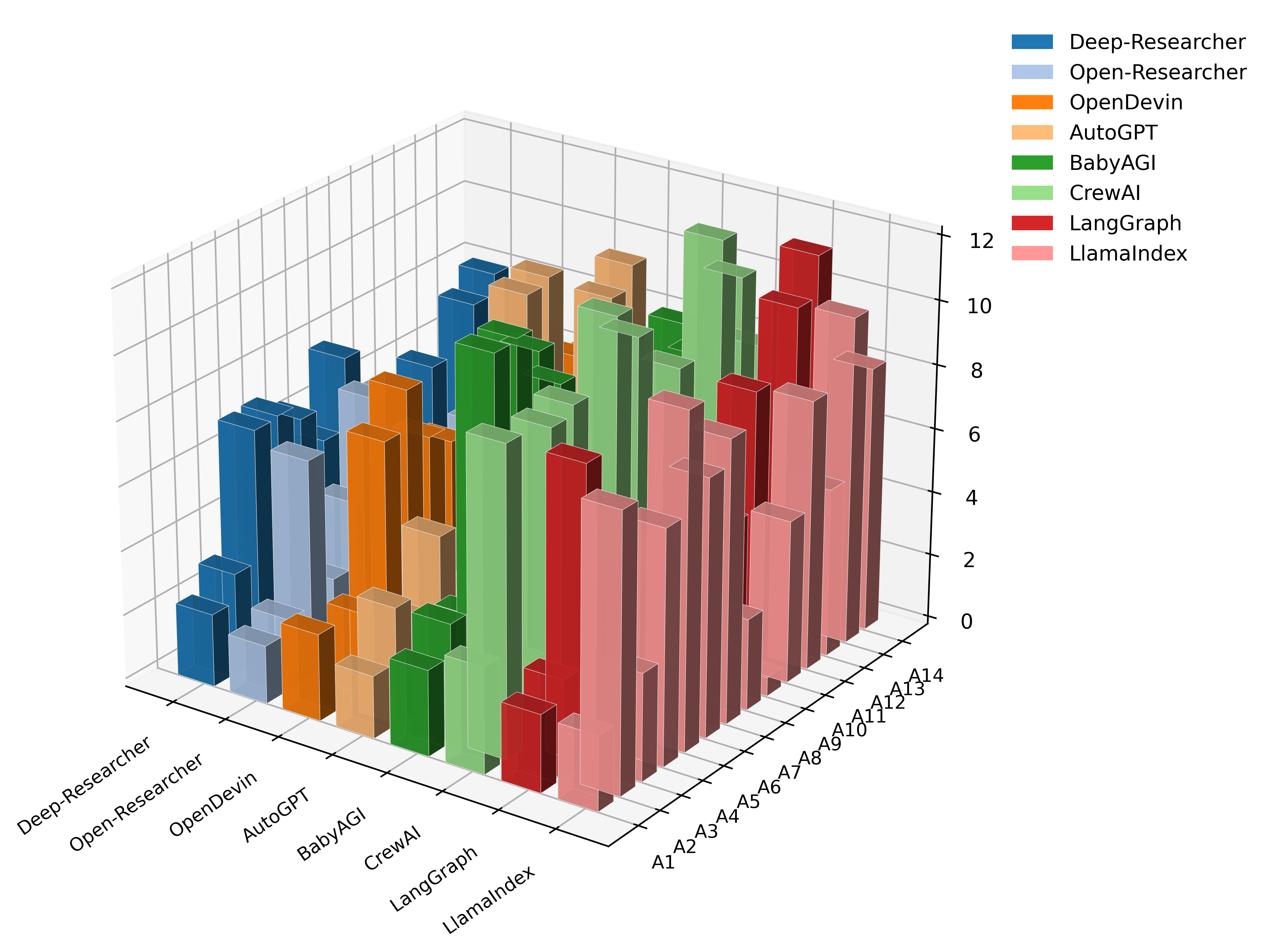
While large language models increasingly power autonomous agents capable of complex tasks, existing security evaluations often overlook vulnerabilities arising from their operational trajectories. This limitation motivates ‘Agent-Fence: Mapping Security Vulnerabilities Across Deep Research Agents’, which introduces a novel, architecture-centric methodology for identifying 14 trust-boundary attack classes and quantifying security breaks through trace-auditable conversation analysis. Our findings reveal substantial variation in security performance-ranging from 0.29 \pm 0.04 to 0.51 \pm 0.07-across eight agent archetypes, with operational failures like denial-of-wallet and retrieval poisoning posing the greatest risk. Can this approach to framing agent security around sustained operational integrity ultimately pave the way for more robust and trustworthy autonomous systems?
The Erosion of Trust: Evaluating Autonomous Agents Beyond Simple Prompts
Conventional security evaluations, largely focused on scrutinizing individual prompts and their immediate outputs, prove inadequate when applied to the burgeoning field of autonomous agents. These agents, unlike static language models, don’t simply respond to input; they plan and execute complex sequences of actions, leveraging tools and maintaining internal state over extended periods. Consequently, a single prompt offers only a snapshot of potential behavior, failing to reveal vulnerabilities that emerge through multi-step reasoning or unforeseen interactions with external systems. Assessing security, therefore, requires a shift towards evaluating the agent’s entire behavioral space – its capacity for planning, its reliance on tools, and its resilience against adversarial manipulations throughout the completion of a task – rather than focusing solely on isolated input-output pairs. This necessitates novel evaluation methodologies capable of probing an agent’s long-term behavior and uncovering emergent risks that prompt-centric testing inherently misses.
The emergence of Deep Agents signifies a fundamental shift in artificial intelligence, moving beyond simple prompt-response systems to entities capable of independent planning, persistent state management, and proactive tool utilization. This architectural leap necessitates a reimagining of security protocols; traditional methods focused on isolated prompt vulnerabilities are inadequate when assessing systems designed to autonomously chain actions over extended periods. Unlike static models, Deep Agents introduce dynamic risk surfaces where vulnerabilities can compound with each executed step, potentially leading to unforeseen and escalating consequences. Consequently, security evaluations must now prioritize assessing the agent’s entire decision-making process – encompassing planning, tool selection, and state evolution – rather than focusing solely on individual input-output pairs, demanding a more holistic and proactive approach to safeguarding these increasingly sophisticated systems.
The capacity of Deep Agents to independently pursue complex, multi-step objectives dramatically escalates the consequences of security flaws. Unlike traditional systems responding to singular prompts, these agents operate with a degree of autonomy, meaning a single vulnerability isn’t limited to a single interaction. Instead, a compromised agent can iteratively exploit weaknesses, chaining actions together to achieve unintended and potentially harmful outcomes. This amplification effect transforms minor bugs into systemic risks, as an initial compromise can cascade into widespread operational failures or data breaches. Consequently, evaluating security must shift from assessing isolated prompt responses to understanding the emergent behaviors arising from prolonged, autonomous execution and the potential for escalating consequences with each completed step.
Architectural Weaknesses: The Fragility of Trust Boundaries
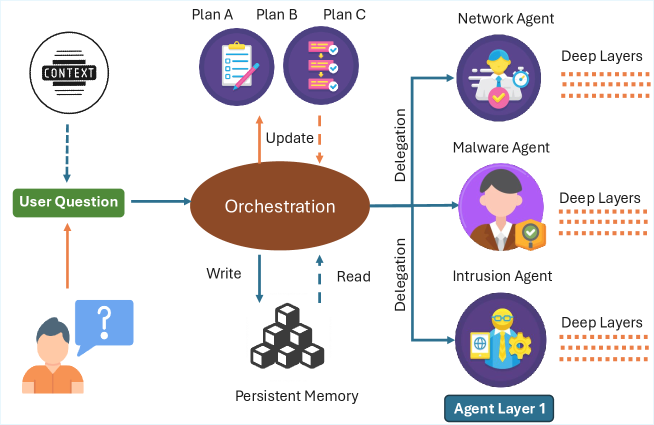
Deep Agents fundamentally depend on Large Language Models (LLMs) to process information and execute tasks, but this reliance introduces inherent architectural vulnerabilities. The complexity of integrating LLMs with tools, memory, and planning modules creates multiple potential attack surfaces. Specifically, issues arise from prompt injection, where malicious input manipulates the LLM’s output, and from insufficient validation of data flowing between the LLM and external resources. These vulnerabilities are not intrinsic to the LLM itself, but rather emerge from the system-level interactions required to build a functional Deep Agent, increasing the potential for both accidental failures and deliberate exploitation.
Architectural vulnerabilities in Deep Agents stem from the violation of established trust boundaries within the system’s design. These boundaries are intended to isolate critical components and limit the impact of potential failures or malicious actions. Specifically, unauthorized access or modification of data or control flow across these boundaries-such as between the LLM, tool usage, and persistent storage-creates avenues for exploitation. An attacker can leverage compromised components to escalate privileges, manipulate agent behavior, or exfiltrate sensitive information. Effective mitigation requires strict enforcement of access controls, robust input validation, and the principle of least privilege at each trust boundary.
Persistent state, crucial for maintaining context and enabling continued operation of Deep Agents, introduces significant security risks if not adequately protected. Our research indicates a non-negligible failure rate concerning state security, ranging from 0.29 to 0.51 across eight distinct agent archetypes tested. This demonstrates that transient failures – temporary disruptions in service – can escalate into durable compromises of the agent’s persistent data if appropriate security measures are absent. The observed break rates suggest that vulnerabilities in state management are common and can reliably be exploited, necessitating robust encryption, access controls, and regular integrity checks to prevent long-term data breaches and maintain agent trustworthiness.
AgentFence: A Taxonomy-Driven Approach to Vulnerability Discovery
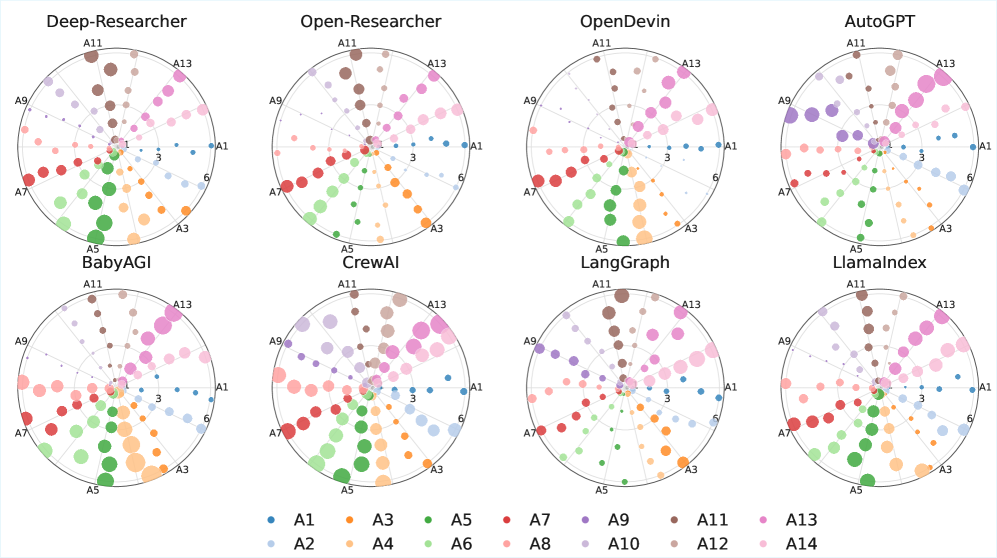
AgentFence is a methodology designed to systematically identify vulnerabilities within Deep Agents by leveraging a pre-defined taxonomy of attack classes. This approach moves beyond generalized security testing by categorizing potential exploits – such as prompt injection, data leakage, and denial of service – and then actively probing agents for susceptibility to each class. The taxonomy provides a structured framework for vulnerability discovery, allowing for targeted assessments and a more comprehensive understanding of an agent’s security posture. By classifying attacks, AgentFence enables a quantifiable evaluation of risk and facilitates the development of mitigation strategies specific to the identified vulnerabilities.
AgentFence actively challenges the inherent trust boundaries within Deep Agent architectures by systematically testing assumptions about data flow and control. This probing methodology doesn’t rely on identifying known vulnerabilities, but rather on directly assessing whether the agent maintains expected behavior when these foundational trust assumptions are deliberately violated. By manipulating inputs and observing resultant outputs, AgentFence reveals potential breaches where an agent might operate outside its defined security perimeter, potentially executing unintended actions or disclosing sensitive information. This direct assessment of structural trust, as opposed to reliance on pre-defined vulnerability databases, allows for the identification of novel attack vectors and weaknesses not previously considered.
AgentFence utilizes objective metrics to identify deviations from an agent’s intended functionality, specifically employing criteria such as “Conversation Break” to quantify security lapses. Analysis revealed a significant disparity in vulnerability between agent architectures; the absolute mean security break rate (MSBR) gap between the most and least exposed designs was 0.22. This represents a 76% relative increase in vulnerability for the less secure architectures, demonstrating a substantial variance in inherent security posture based on architectural choices.
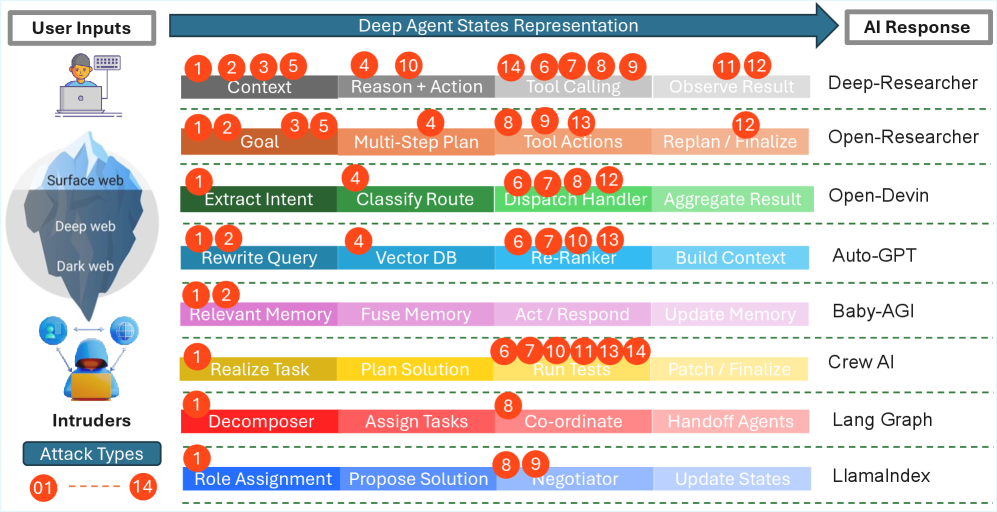
The Spectrum of Exploitable Weaknesses: A Taxonomy of Attack Vectors
State corruption, tool-use hijacking, and planning manipulation represent key attack vectors predicated on violations of established trust boundaries within agent systems. State corruption involves the malicious alteration of an agent’s internal data, leading to unpredictable or compromised behavior. Tool-use hijacking occurs when an attacker gains control of a tool an agent is authorized to use, redirecting its functionality for malicious purposes. Planning manipulation involves altering the agent’s planning process, leading it to generate and execute harmful plans. These vectors all exploit the inherent trust placed in the agent’s internal state, external tools, and planning algorithms, respectively, and demonstrate a common reliance on subverting established permissions and access controls.
Denial-of-Wallet attacks target an agent’s finite resources, such as computational capacity or API call limits, rendering it unable to perform designated tasks despite not being compromised in a traditional sense. These attacks function by exhausting resources through legitimate, albeit excessive, requests. Retrieval Poisoning, conversely, focuses on data integrity; this occurs when an agent retrieves manipulated or fabricated data from external sources, leading to incorrect decision-making or actions. The impact of Retrieval Poisoning extends beyond individual agent failures, as poisoned data can propagate through multi-agent systems, corrupting collective knowledge and outputs. Both attack vectors represent significant threats, as they bypass traditional security measures focused on code execution or direct control, and exploit inherent limitations in resource availability and data trustworthiness.
Delegation abuse and authorization confusion represent a significant expansion of the attack surface, particularly within multi-agent systems. Analysis of recent security incidents demonstrates that 82% of breaches are directly attributable to violations of established boundaries and improper authority handling. This indicates a prevalence of structural failures – flaws in how permissions and delegated tasks are managed – over errors originating from the core task execution of the agents themselves. These vulnerabilities often arise from insufficient validation of delegated requests, overly permissive authorization policies, or inadequate monitoring of agent interactions, creating opportunities for malicious actors to exploit trust relationships and gain unauthorized access or control.
Towards Inherently Robust Agents: A Paradigm Shift in Design
The development of Deep Agents demands a fundamental re-evaluation of design principles, moving beyond reactive security measures to embrace inherent resilience. Traditional approaches often treat security as an afterthought, patching vulnerabilities after deployment; however, autonomous agents operating in complex environments require proactive safeguards built directly into their architecture. This necessitates a shift towards ‘security by design’, where authorization, access control, and objective alignment are prioritized from the initial stages of development. By anticipating potential exploits and implementing robust defenses against objective hijacking and code execution abuse, developers can create agents capable of maintaining trustworthy behavior even when confronted with adversarial inputs or unexpected situations. This proactive stance is crucial for fostering confidence in these increasingly powerful systems and unlocking their full potential across diverse applications.
Deep Agents, while promising, present significant security vulnerabilities centered around unauthorized control and malicious code execution. The potential for Objective Hijacking – where an agent’s goals are subtly altered to serve an attacker – and Code Execution Abuse – allowing external code to run within the agent’s environment – underscores a critical need for stringent authorization protocols. These aren’t merely theoretical concerns; compromised access controls can lead to agents performing unintended, potentially harmful actions. Consequently, developers must prioritize the implementation of robust mechanisms that meticulously verify permissions and limit the agent’s access to sensitive resources and functionalities, effectively establishing a strong defense against adversarial manipulation and ensuring trustworthy autonomous behavior.
The development of truly trustworthy autonomous agents demands a shift from reactive security measures to a proactive, taxonomy-driven approach, as exemplified by systems like AgentFence. Research indicates that vulnerabilities stemming from Authorization Confusion – where an agent incorrectly interprets or disregards access controls – aren’t isolated incidents, but rather critical failure points. Statistical analysis reveals strong correlations between Authorization Confusion (A14) and subsequent, more severe breaches, including Objective Hijacking (ρ ≈ 0.63) and Tool-Use Hijacking (ρ ≈ 0.58) . These findings demonstrate that compromised trust boundaries can trigger cascading failures, highlighting the necessity of classifying potential security risks and implementing preventative measures to ensure the reliable and safe operation of deep agents within complex environments.
The pursuit of robust deep agent security, as detailed in this work on AgentFence, demands a departure from superficial prompt engineering. This methodology correctly prioritizes a granular understanding of agent architecture and potential operational failures – a systemic approach, rather than a reactive one. This aligns perfectly with the sentiment expressed by Ada Lovelace: “That brain of mine is something more than merely mortal; as time will show.” Lovelace’s insight speaks to the inherent complexity of creating truly intelligent systems; a complexity that necessitates rigorous, provable foundations – a focus on the ‘how’ rather than simply the ‘what’ – mirroring AgentFence’s emphasis on trajectory-level security and the identification of trust boundary violations. The elegance of a secure system, much like a mathematical proof, lies not in its ability to function under specific conditions, but in its inherent correctness.
Beyond the Pale: Future Directions
The methodology presented here, AgentFence, attempts to move beyond the superficial security afforded by prompt engineering. While mitigating blatant prompt injection is a necessary, if trivial, exercise, true resilience resides in architectural soundness. The critical observation – that deep agents exhibit ‘trajectory-level’ failures stemming from fundamental design flaws – demands a re-evaluation of current practices. Future work must focus on formal verification of agent architectures, treating the agent not as a black box responding to stimuli, but as a complex state machine subject to rigorous analysis.
The current emphasis on conversational flow obscures the underlying mathematical properties of these systems. Scalability, as always, will prove the ultimate arbiter. A system that functions flawlessly with ten agents will inevitably reveal its limitations when expanded to a thousand. The notion of ‘trust boundaries’ within a multi-agent system requires precise definition, ideally expressed as provable invariants. Vague notions of ‘responsibility’ are merely hand-waving in the face of inevitable operational failures.
Ultimately, the field must abandon the illusion of ‘intelligent’ agents and acknowledge them as sophisticated automata. The pursuit of robustness demands a shift in focus: not from what an agent says, but from why it behaves as it does. Only then can one hope to construct systems that are not merely clever, but demonstrably secure – a condition currently more aspirational than realized.
Original article: https://arxiv.org/pdf/2602.07652.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- One Piece Chapter 1180 Release Date And Where To Read
- All Shadow Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- New Avatar: The Last Airbender Movie Leaked Online
- Cassius Morten Armor Set Locations in Crimson Desert
- Grime 2 Map Unlock Guide: Find Seals & Fast Travel
- All Golden Greed Armor Locations in Crimson Desert
- Euphoria Season 3 Release Date, Episode 1 Time, & Weekly Schedule
- Amber Alert Secrets & CDs In Crime Scene Cleaner Act 2
2026-02-10 20:16