Author: Denis Avetisyan
A new framework leverages contextual understanding and error correction to dramatically improve communication reliability, particularly in challenging low-signal conditions.
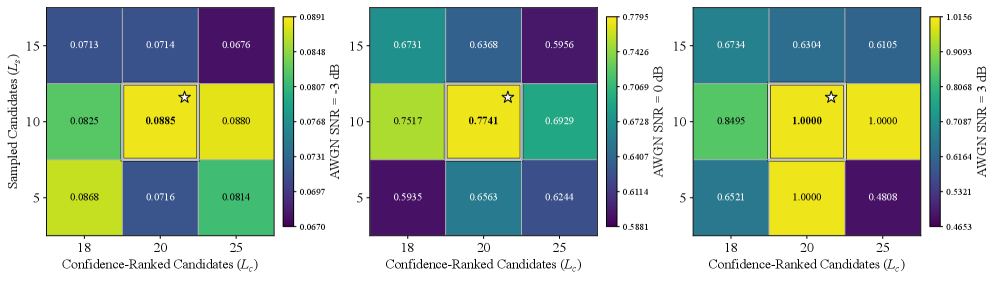
This paper introduces an in-context decoding approach for semantic communication systems, utilizing diversity-preserving sampling and an Error Correction Code Transformer to mitigate performance cliffs.
While modularity remains a key advantage of separate source-channel coding (SSCC) for text transmission, conventional SSCC systems are vulnerable to performance cliffs at low signal-to-noise ratios due to error propagation. This paper introduces ‘In-Context Source and Channel Coding’, a novel receiver-side decoding framework that enhances SSCC robustness by leveraging contextual information and error correction to mitigate these failures. Specifically, our approach utilizes an Error Correction Code Transformer to estimate bit reliability, guiding a diversity-preserving sampling strategy and ultimately enabling a large language model-based arithmetic decoder to reconstruct the original message. Could this in-context decoding framework pave the way for more reliable and efficient semantic communication systems in challenging low-SNR environments?
The Illusion of Symbolic Fidelity
For over a century, communication systems have prioritized the faithful delivery of symbols – bits, waveforms, or pixels – assuming meaning is inherent in the received signal and understood by the recipient. However, this approach fundamentally misses the point: the ultimate goal isn’t accurate symbol transmission, but the reliable conveyance of meaning. Current systems are remarkably inefficient because they expend resources ensuring symbols arrive intact, regardless of whether the receiver actually understands the intended message. Consider that a slightly distorted image of a cat is still recognizable as a cat, proving redundancy isn’t always necessary for comprehension. This realization shifts the focus from signal fidelity to semantic accuracy, suggesting that a system designed to directly encode and transmit meaning, rather than simply symbols, could achieve significant gains in efficiency and robustness, potentially revolutionizing how information is shared.
Conventional communication systems prioritize the accurate delivery of symbols – bits, waveforms, or pixels – but semantic communication reframes the objective as directly transmitting meaning. This approach bypasses the need for perfect symbol reconstruction, focusing instead on ensuring the receiver understands the intended message, even if some data is lost or corrupted. Consequently, semantic communication holds the potential for significant gains in both efficiency and robustness; by encoding the essence of a message, rather than its literal representation, systems can achieve comparable comprehension with fewer resources and operate reliably even in challenging conditions. This paradigm shift moves beyond simply delivering what is said to ensuring that it is understood, promising a future where communication prioritizes comprehension over precise replication.
The realization of semantic communication hinges on the sophisticated application of machine learning techniques to capture and process the nuances of meaning itself. Rather than treating information as simply a string of symbols, these algorithms learn to represent content based on its underlying semantics – the intended message and its associated context. This involves employing methods like neural networks to create distributed representations – complex mathematical vectors – that encode semantic concepts, allowing for efficient compression and robust transmission even in noisy environments. Furthermore, machine learning enables the system to adapt to different users and contexts, tailoring the communication process to maximize understanding and minimize ambiguity, ultimately moving beyond the limitations of purely symbolic exchange.
Large Language Models: Encoding Meaning, Not Just Signals
Large Language Models (LLMs), such as GPT-2, are trained on extensive text corpora and, as a result, develop an internal representation of language that captures semantic relationships between words and concepts. This allows them to not merely process text as a sequence of symbols, but to understand the underlying meaning and context. The models achieve this through the use of transformer architectures and attention mechanisms, enabling them to weigh the importance of different parts of the input sequence when generating output. Consequently, LLMs can effectively encode information based on its semantic content, going beyond simple pattern matching and allowing for a more efficient representation of data that prioritizes meaning over literal character sequences.
Traditional source coding methods primarily focus on syntactic compression, identifying and eliminating statistical redundancies in data based on symbol frequency and patterns. Integrating Large Language Models (LLMs) into source coding enables a shift towards semantic compression by leveraging the LLM’s ability to understand and represent the underlying meaning of the data. This allows for the identification and removal of redundancies based on semantic equivalence – different syntactic representations conveying the same information – which are not addressable by purely syntactic approaches. Consequently, LLM-integrated source coding can achieve higher compression ratios by exploiting the inherent semantic structure of the data, rather than solely relying on statistical co-occurrences of symbols.
Arithmetic coding is employed as the entropy encoder within the In-Context Decoding (ICD) framework to efficiently represent the semantic output generated by the Large Language Model (LLM). Unlike traditional methods that assign a fixed number of bits per symbol, arithmetic coding assigns shorter codes to more probable symbols and longer codes to less probable ones, resulting in higher compression ratios. Benchmarking demonstrates that the ICD framework, utilizing arithmetic coding, consistently achieves superior performance compared to conventional Semantic Source Codec (SSCC) pipelines and representative Joint Source-Channel Coding (JSCC) schemes; this improvement is attributed to the LLM’s ability to model complex data distributions and the arithmetic coder’s capacity to exploit these distributions for optimal encoding efficiency.
The Inevitable Imperfection of Channels
Actual communication channels deviate significantly from theoretical ideals due to the inherent presence of noise and signal degradation. Noise, typically modeled as N(0, \sigma^2), introduces random fluctuations that corrupt the transmitted signal. Simultaneously, fading-caused by multipath propagation, shadowing, and other environmental factors-results in time-varying attenuation of the signal amplitude. These impairments limit the achievable data rate and reliability of communication systems; signal strength fluctuations can lead to bit errors and necessitate robust modulation and coding schemes to ensure accurate data transmission. The severity of these effects is quantified by metrics such as the Signal-to-Noise Ratio (SNR) and the channel’s coherence time, both of which directly impact system performance.
The Additive White Gaussian Noise (AWGN) channel serves as a fundamental model in communication systems, characterized by the addition of white Gaussian noise to the transmitted signal; this noise is assumed to have a zero mean and a Gaussian distribution, representing thermal noise inherent in any electronic system. In contrast, the Rayleigh fading channel models more realistic wireless propagation environments where the signal undergoes multipath fading – reflections and scattering of the signal off objects – resulting in a randomly varying signal amplitude and phase. Unlike AWGN, which assumes a constant noise level, Rayleigh fading introduces time-varying signal attenuation, requiring more complex modulation and coding schemes to maintain reliable communication. The probability density function of the Rayleigh distribution describes the statistical variation in signal strength experienced in this fading environment, reflecting the constructive and destructive interference of multiple signal paths.
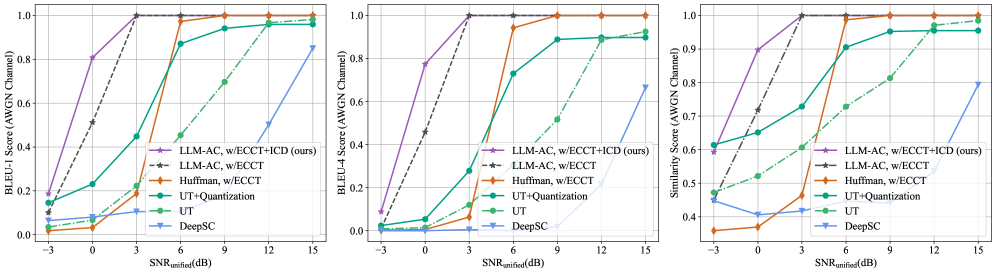
Binary Phase-Shift Keying (BPSK) is a modulation technique employed for reliable digital communication over noisy channels. Performance evaluations, as depicted in figures 4 and 5, indicate that the implemented ICD framework consistently outperforms baseline methods in both Additive White Gaussian Noise (AWGN) and Rayleigh fading channels, as measured by BLEU-4 scores. This improved performance is particularly notable in low Signal-to-Noise Ratio (SNR) conditions, demonstrating greater robustness. Additionally, the incorporated CCS module provides a 1.6457x computational speedup, enhancing processing efficiency without sacrificing communication fidelity.
The pursuit of seamless communication, as detailed in this exploration of in-context decoding, feels less like construction and more like tending a garden. The paper’s focus on mitigating the ‘cliff effect’ in low-SNR environments highlights a fundamental truth: optimization, while tempting, inevitably trades flexibility for immediate gain. G.H. Hardy observed, “The essence of mathematics is its freedom.” This applies equally to communication systems; a rigid adherence to peak performance blinds one to the inherent unpredictability of the channel. The system described isn’t built so much as grown, adapting to noise through contextual understanding and diversity-preserving sampling, acknowledging that the perfect architecture – one impervious to error – remains a comforting illusion.
What Lies Ahead?
This work, attempting to tame the cliff effect through contextual awareness, merely postpones the inevitable. The system does not solve communication under noise; it redistributes the points of failure. The receiver, now a miniature oracle attempting to divine intent from incomplete signals, introduces a new fragility. Architecture is, after all, how one postpones chaos, not abolishes it. The reliance on large language models, while currently effective, implies a future bounded by their limitations – biases encoded in parameters, and the ever-present risk of emergent, unpredictable behavior.
The true challenge isn’t perfecting error correction, but acknowledging its futility. There are no best practices – only survivors. Future work will inevitably grapple with the tension between complexity and robustness. Increasing the sophistication of the contextual decoder only creates a more elaborate surface for errors to manifest. Perhaps the focus should shift from correcting errors to anticipating them, building systems that gracefully degrade, rather than catastrophically fail.
Ultimately, this endeavor highlights a fundamental truth: order is just cache between two outages. The pursuit of perfect semantic communication is a Sisyphean task. The next stage will likely involve exploring systems that embrace uncertainty, that treat noise not as an adversary, but as an intrinsic component of the communication channel itself, and build resilience into the very fabric of the signal.
Original article: https://arxiv.org/pdf/2601.10267.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- One Piece Chapter 1180 Release Date And Where To Read
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- All Shadow Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- How to Beat Stonewalker Antiquum at the Gate of Truth in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- Black Sun Shield Location In Crimson Desert (Buried Treasure Quest)
- All Icewing Armor Locations in Crimson Desert
2026-01-16 14:33