Author: Denis Avetisyan
New research challenges the assumptions behind vector quantization, offering solutions to a common problem that hinders generative model performance.
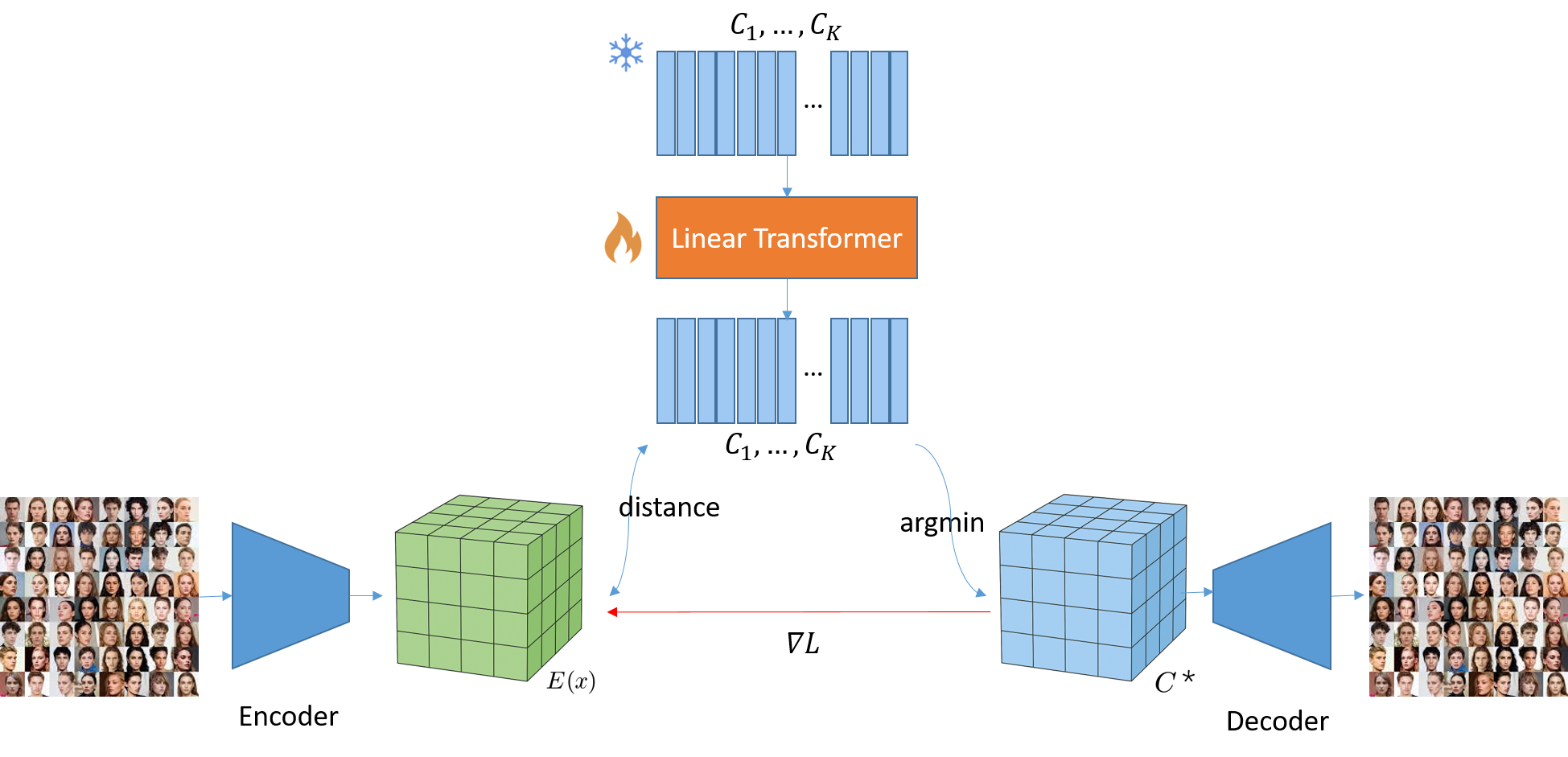
This paper identifies non-stationarity as a key driver of codebook collapse in VQ-VAEs and introduces methods like Non-Stationary VQ and Transformer-based VQ to improve codebook utilization and reconstruction quality.
Despite its prevalence in modern generative frameworks-including VQ-VAE, VQ-GAN, and latent diffusion models-Vector Quantization (VQ) suffers from persistent codebook collapse, where a significant portion of learned codes remain unused. This work, ‘Beyond Stationarity: Rethinking Codebook Collapse in Vector Quantization’, identifies the root cause as the non-stationary nature of encoder updates during training, leading to inactivity in unselected code vectors. To address this, we propose Non-Stationary Vector Quantization (NSVQ) and Transformer-based Vector Quantization (TransVQ), methods that propagate encoder drift and adaptively transform the codebook, respectively. By demonstrating near-complete codebook utilization and improved reconstruction on CelebA-HQ, can these techniques pave the way for more efficient and powerful VQ-based generative models?
The Illusion of Dimensionality Reduction: When Codebooks Fail
Vector Quantized Variational Autoencoders (VQ-VAEs) represent a compelling approach to data compression by learning a discrete latent representation of input data, effectively reducing dimensionality while preserving key information. However, a significant challenge often undermines their potential: codebook collapse. This phenomenon occurs during the training process where a substantial portion of the codebook – the set of learned vector representations – remains unused, essentially becoming ‘dead’ vectors. Consequently, the model fails to fully utilize its representational capacity, hindering its ability to effectively encode and decode complex data. While VQ-VAEs offer a theoretically powerful method for efficient representation learning, addressing codebook collapse is crucial to unlock their full capabilities and prevent a restriction of the learned data manifold.
A fundamental challenge in training Vector Quantized Variational Autoencoders (VQ-VAEs) lies in the phenomenon of codebook collapse, where a substantial fraction of the learned code vectors become effectively unused during the training process. This isn’t merely an inefficiency; the underutilization drastically limits the model’s representational capacity, hindering its ability to capture the full complexity of the input data. Consequently, the VQ-VAE struggles to reconstruct or generate high-fidelity outputs, as crucial information is lost due to the incomplete codebook. The resulting performance degradation impacts various applications, from image and audio compression to generative modeling, where an expressive and fully utilized latent space is paramount for achieving optimal results.
The persistent problem of codebook collapse within Vector Quantized Variational Autoencoders (VQ-VAEs) significantly restricts their practical application, particularly in areas demanding compact and informative data representations. When a substantial fraction of the codebook remains unused during the learning process, the model’s ability to effectively capture the underlying data distribution is compromised, hindering performance on downstream tasks like image generation, speech synthesis, and anomaly detection. This limitation prevents VQ-VAEs from achieving their full potential as efficient tools for representation learning, as the unused code vectors represent a wasted capacity for encoding nuanced data features. Consequently, addressing codebook collapse is not merely a technical refinement, but a crucial step toward unlocking the broader utility of VQ-VAEs in a range of real-world applications requiring both compression and meaningful data abstraction.
![Both the proposed NS-VQVAE and TransVQVAE demonstrate improved reconstruction quality (lower rFID scores) and effectively utilize the codebook, avoiding collapse, compared to VQGAN-FC[16] across varying codebook sizes.](https://arxiv.org/html/2602.18896v1/images/usage.png)
The Shifting Sands of Training: Why Codebooks Forget
Analysis of Vector Quantized Variational Autoencoder (VQ-VAE) training dynamics indicates that non-stationarity is the principal cause of codebook collapse. This phenomenon occurs because the statistical properties of the data distribution encountered during training are not fixed; instead, they change over time. Consequently, the optimization process becomes unstable as the model attempts to learn a static codebook from a non-static data stream. This shifting optimization landscape prevents the codebook vectors from settling into meaningful representations, ultimately resulting in a collapse where a limited number of codebook entries are utilized, and the model fails to effectively compress or reconstruct the input data.
Non-stationarity in VQ-VAE training refers to the alteration of input data distributions over the course of optimization. This dynamic shift impacts the loss landscape, creating a moving target for codebook vector optimization. Specifically, as the decoder learns to reconstruct increasingly complex features, the distribution of residuals passed to the vector quantization layer changes. Consequently, codebook vectors optimized for early training distributions become suboptimal for later distributions, leading to instability and increased susceptibility to collapse as the model struggles to maintain a consistent mapping between input features and discrete codes. This shifting landscape prevents the codebook from effectively representing the data, hindering the development of a useful latent space.
The inability of the codebook to maintain stable representations during training results in diminished utilization of available code vectors. As the input data distribution shifts throughout the training process – a consequence of the dynamic instability – the learned embeddings progressively converge to a limited subset of the codebook. This phenomenon manifests as codebook collapse, where a significant portion of the codebook remains unused, effectively reducing the model’s capacity to represent the diversity present in the training data and hindering its ability to generalize to unseen examples. Consequently, the model’s performance degrades as it relies on an increasingly restricted set of discrete codes.
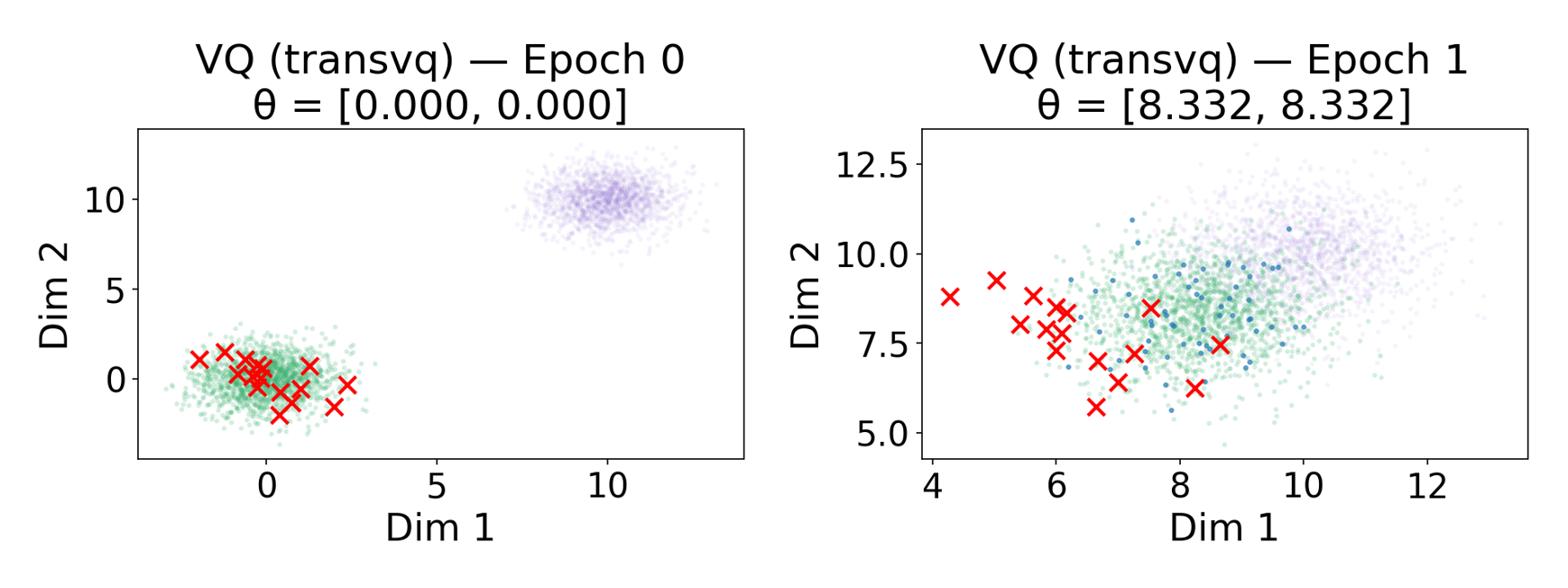
Taming the Chaos: Strategies for Robust Codebooks
Vector Quantized Variational Autoencoders (VQ-VAEs) are susceptible to training instability due to non-stationarity, where the data distribution encountered during training shifts over time. This occurs because the discrete codebook learned by the VQ-VAE progressively refines its representation, altering the input distribution to subsequent layers. Standard training procedures assume a static data distribution, which is violated by this dynamic adaptation. Consequently, certain codebook entries may become underutilized while others become saturated, leading to a phenomenon known as “code collapse” and a loss of representational capacity. Techniques to address this non-stationarity therefore focus on dynamically adjusting the training process to accommodate the evolving data distribution, promoting more balanced codebook utilization and improving overall model stability and performance.
Mitigation of non-stationarity during Vector Quantized Variational Autoencoder (VQ-VAE) training is critical for achieving balanced codebook utilization and preventing code collapse. Code collapse occurs when the discrete codebook becomes sparsely populated, with only a limited number of codebook entries being actively used to represent the data. This results in a loss of representational capacity and degraded reconstruction quality. By dynamically adapting to shifts in the data distribution, techniques can encourage the model to utilize a wider range of codebook entries, ensuring each entry contributes to the representation of the input data and maintaining a more comprehensive and robust learned representation. Balanced utilization directly correlates with improved model performance, as evidenced by metrics such as rFID, LPIPS, and SSIM.
Non-Stationary Vector Quantization (NS-VQ) and Transformer-based Vector Quantization (TransVQ) methods consistently achieve near-complete codebook utilization, approaching 100%, which effectively prevents code collapse during VQ-VAE training. Empirical evaluation demonstrates that these techniques yield improved performance metrics compared to standard VQ-VAE implementations; specifically, lower Fréchet Inception Distance (rFID) scores indicate superior reconstruction quality, and lower Learned Perceptual Image Patch Similarity (LPIPS) scores demonstrate enhanced perceptual fidelity. These quantitative results confirm that NS-VQ and TransVQ generate reconstructions that are both more accurate to the original data and more visually pleasing to human observers.
Structural Similarity Index (SSIM) scores were consistently higher with the proposed Non-Stationary Vector Quantization (NS-VQ) and Transformer-based Vector Quantization (TransVQ) methods. This indicates improved preservation of structural information in the reconstructed images compared to standard VQ-VAEs. SSIM assesses perceptual similarity by modeling luminance, contrast, and structure, with values closer to 1.0 representing greater similarity. Higher SSIM scores demonstrate that NS-VQ and TransVQ more effectively maintain the essential structural components of images during the reconstruction process, resulting in outputs that are more visually aligned with the original input data.
The pursuit of elegant solutions in generative modeling often feels like building sandcastles against the tide. This paper attempts to shore up the foundations of Vector Quantization against ‘codebook collapse,’ a predictable failure mode given the non-stationary dynamics of VQ-VAE training. It’s amusing, really – researchers devising ‘Non-Stationary VQ’ and ‘Transformer-based VQ’ to address a problem born from trying to impose order on inherently chaotic systems. As Yann LeCun once observed, “Backpropagation is the credit assignment problem, and that’s the fundamental problem of learning.” This feels similar; a constant re-calibration of credit, or in this case, codebook utilization, against the ever-shifting sands of training data. Everything new is just the old thing with worse docs, and a more complex diagram.
The Inevitable Rot
This work, predictably, doesn’t solve codebook collapse. It merely relocates the problem, dressing it in the latest architectural trends. Non-stationarity, while identified as a key culprit, is hardly unique to vector quantization. Every generative model, given enough training epochs, eventually finds a way to exploit its own inductive biases, leading to some form of expressive bottleneck. The current solutions – tinkering with transformers and attempting to cajole the codebook into behaving – feel suspiciously like applying increasingly complex bandages to a fundamentally flawed design.
The real question isn’t whether NS-VQ or TransVQ offer marginal gains on existing benchmarks, but how much computational expense will be required to maintain those gains before production data inevitably exposes new failure modes. One suspects the answer involves a rapidly escalating curve. Expect future research to focus on increasingly elaborate regularization techniques, adversarial training schemes, and perhaps, a nostalgic return to simpler, more robust methods – rebranded, of course.
Ultimately, this paper serves as a useful reminder: everything new is old again, just renamed and still broken. The pursuit of elegant solutions in generative modeling is a Sisyphean task. Production is the best QA, and it will, without fail, find a way to demonstrate that even the most sophisticated codebook is, at its heart, a fragile and temporary construct.
Original article: https://arxiv.org/pdf/2602.18896.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- All Shadow Armor Locations in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- Best Bows in Crimson Desert
- Keeping Large AI Models Connected Through Network Chaos
- All Icewing Armor Locations in Crimson Desert
- How to Craft the Elegant Carmine Armor in Crimson Desert
2026-02-24 19:04