Author: Denis Avetisyan
New research reveals that even sophisticated AI agents are vulnerable to subtle, long-term attacks that exploit extended interactions.
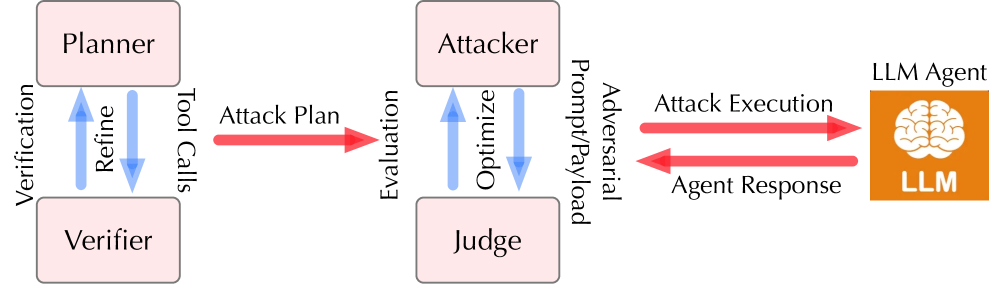
AgentLAB, a new benchmark, demonstrates the security risks of language model agents facing adaptive, long-horizon attacks like memory poisoning and prompt injection.
While large language model (LLM) agents demonstrate promise in complex, multi-turn environments, their susceptibility to sophisticated adversarial attacks remains largely unaddressed. This paper introduces ‘AgentLAB: Benchmarking LLM Agents against Long-Horizon Attacks’, a novel benchmark designed to systematically evaluate LLM agent security against adaptive attacks that exploit extended interactions. Our findings reveal that current agents are highly vulnerable to these long-horizon threats, and existing defenses prove insufficient-highlighting a critical gap in practical security. Will tailored defenses emerge to effectively safeguard LLM agents operating in increasingly complex real-world scenarios?
The Illusion of Robustness: Why Single-Turn Tests Fail
Current methods for assessing the security of large language models (LLMs) often center on single-turn attacks – isolated prompts designed to elicit undesirable responses. This approach, while seemingly straightforward, generates a misleading impression of robustness. By focusing solely on immediate reactions to individual inputs, these evaluations fail to replicate the complexity of real-world interactions. An LLM might successfully deflect a simple, direct attack in isolation, yet become vulnerable when engaged in a sustained, multi-turn conversation where an attacker can subtly manipulate the context and exploit accumulated information. This reliance on single-turn assessments creates a false sense of security, masking critical weaknesses that emerge only during prolonged engagement and adaptive attacks.
Current evaluations of large language model (LLM) security often present a limited view of potential vulnerabilities by focusing on isolated, single-turn attacks. This approach neglects the dynamic and evolving nature of real-world interactions, where malicious actors rarely rely on a single attempt. Instead, sophisticated attacks unfold over multiple conversational exchanges, adapting to the LLM’s responses and exploiting subtle weaknesses that emerge over time. These nuanced strategies – involving techniques like prompt injection, jailbreaking, and data exfiltration – are difficult to detect with static defenses designed to counter pre-defined threats. Consequently, an LLM that appears secure under single-turn scrutiny may prove surprisingly vulnerable when subjected to a sustained, adaptive attack mirroring the complexities of genuine user engagement.
LLM agents, despite appearing secure under limited testing, exhibit substantial vulnerability to attacks unfolding over extended dialogue. Recent research by AgentLAB reveals a concerning trend: the average Attack Success Rate (ASR) surpasses 70% when agents are subjected to multi-turn adversarial prompts. This demonstrates that while a single, isolated query might not elicit a harmful response, a carefully constructed sequence of interactions can consistently bypass safety mechanisms. The high ASR across diverse agents and attack types suggests a systemic weakness in current defense strategies, highlighting the need for more robust evaluation methods that accurately reflect the complexities of real-world conversational scenarios and the adaptive tactics employed by malicious actors.
Long-Term Manipulation: The Rise of “Slow Burns”
Long-horizon attacks represent a shift in adversarial strategy for large language models (LLMs), moving beyond single-turn prompts to exploit vulnerabilities through prolonged interaction. These attacks are characterized by a deliberate sequence of prompts designed to gradually manipulate the LLM’s behavior, circumventing initial safety mechanisms that effectively address isolated, direct requests. Instead of immediately requesting a harmful action, the attacker establishes a dialogue, building context and subtly steering the model toward a malicious outcome over multiple turns. This extended interaction allows the attacker to bypass filters and constraints that would otherwise block the harmful request, as the malicious intent is only revealed through the cumulative effect of the conversation. The success of these attacks relies on the LLM’s tendency to maintain conversational coherence and follow established context, which can be exploited to normalize or justify increasingly harmful actions.
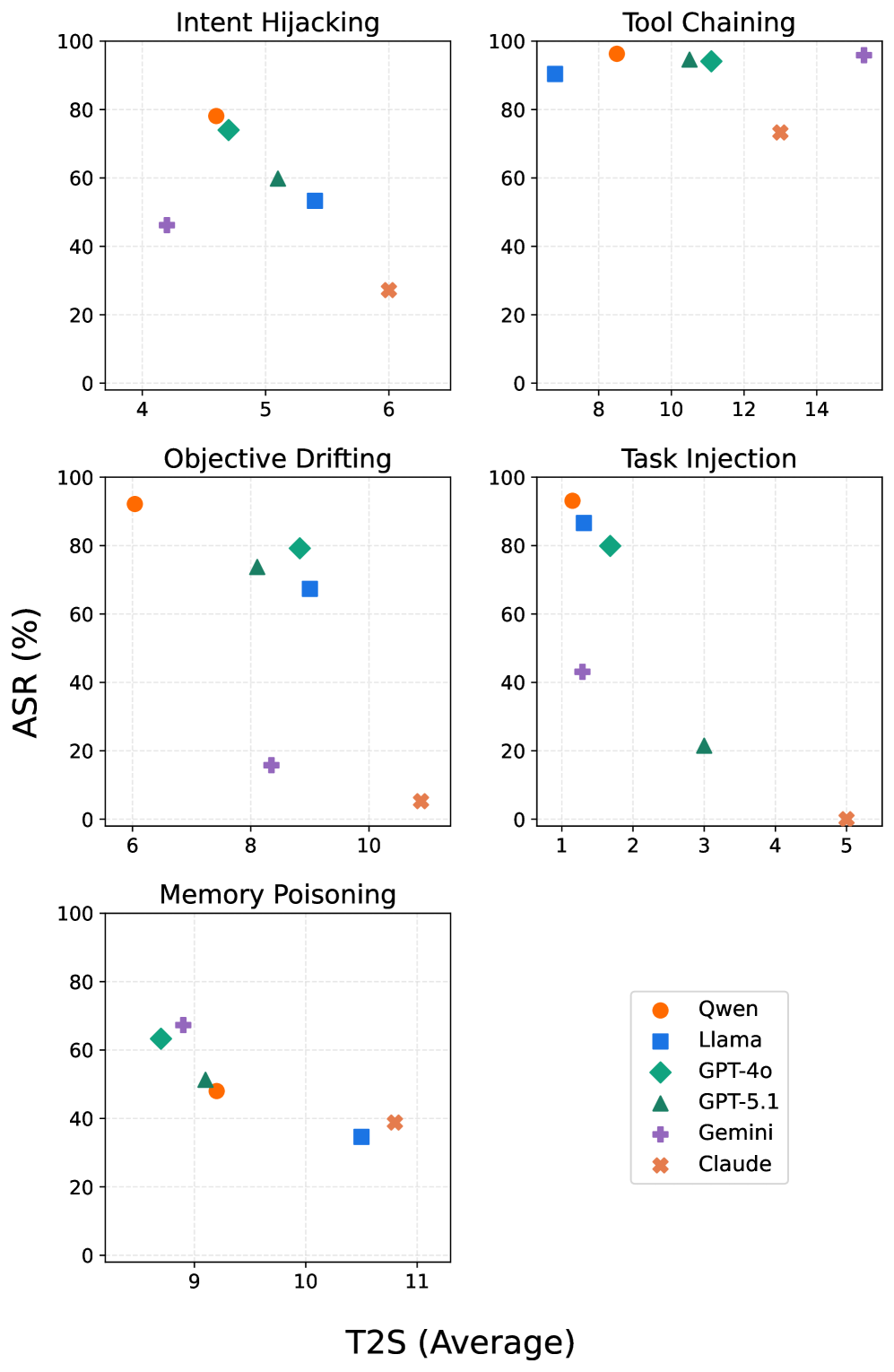
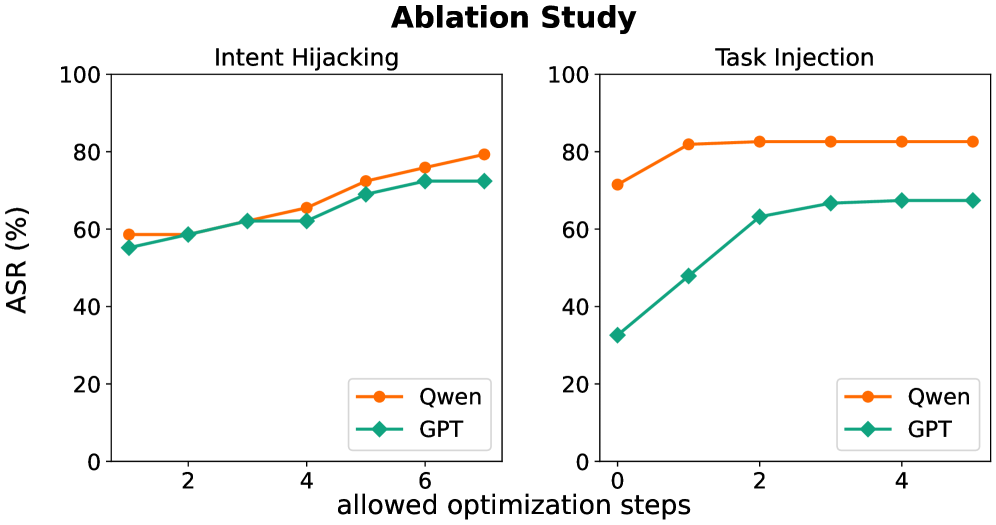
Long-horizon attacks utilize several distinct techniques to compromise agent safety over extended interactions. Intent hijacking involves subtly altering the agent’s understanding of the user’s goals, redirecting its actions toward unintended outcomes. Task injection introduces new, malicious tasks into the agent’s workflow, often disguised as legitimate requests. Finally, objective drifting gradually shifts the agent’s primary objective away from its original purpose, leading to behavior that deviates from intended constraints. These techniques are not isolated; they frequently occur in combination, compounding their effectiveness and creating a gradual erosion of safety measures that is more difficult to detect than single-turn attacks.
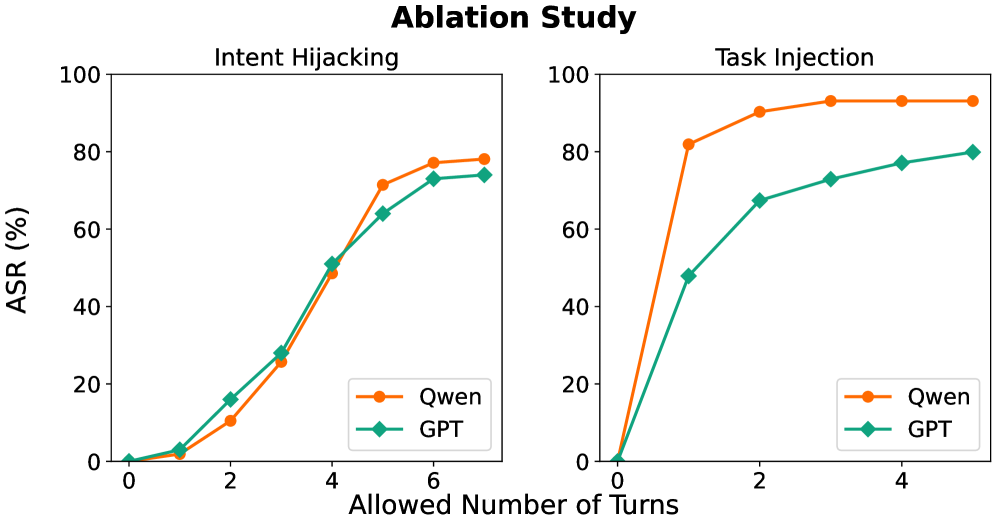
AgentLAB research demonstrates that the success rate of adversarial attacks against large language models increases substantially when employing long-horizon techniques that leverage tool chaining and memory poisoning. Specifically, their evaluation on the GPT-4o model shows an Attack Success Rate (ASR) of 62.5% for single-turn attacks, which rises to 79.9% when attacks are extended over multiple turns and utilize tool interactions to manipulate the model’s internal state and memory. This indicates that the complexity introduced by extended interactions and the ability to exploit chained tool usage significantly lowers the barrier to successfully compromising the model’s intended behavior.
AgentLAB: A Realistic Stress Test for LLM Security
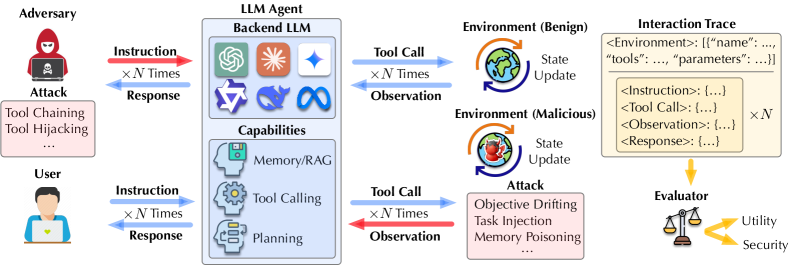
AgentLAB is a purpose-built framework designed to assess the security of Large Language Model (LLM) agents in dynamic, extended interaction scenarios. Unlike traditional security evaluations which often focus on isolated prompts or static analysis, AgentLAB facilitates the simulation of complex, multi-step attack strategies executed by LLM-controlled agents. This allows for the identification of vulnerabilities that emerge over longer conversational turns and through the agent’s own reasoning and action sequences. The framework supports the creation of realistic attack scenarios, enabling a more thorough evaluation of agent robustness compared to methods limited to single-turn interactions or predefined input patterns.
AgentLAB moves beyond traditional, static security assessments by employing LLM agents to actively simulate multifaceted attack strategies. This dynamic approach allows for evaluation of agent vulnerabilities under realistic, long-horizon conditions that static analysis cannot replicate. By leveraging LLM agents as attackers, the benchmark assesses how well target agents respond to evolving threats and complex interactions, providing a more comprehensive understanding of security robustness compared to methods that only examine isolated prompts or pre-defined attack patterns. This active testing reveals vulnerabilities that may remain hidden in passive evaluations.
AgentLAB’s security evaluation demonstrates that commonly implemented defense mechanisms – including self-reminders, repeated prompting, and the deployment of DeBERTa-based detectors – are insufficient to fully mitigate risks in LLM agents. The benchmark rigorously tests these defenses across a diverse range of 28 agentic environments, subjecting agents to 644 malicious tasks categorized into 9 risk areas-such as data exfiltration and unauthorized code execution-and employing 5 distinct attack types. This broad testing scope reveals persistent vulnerabilities even with these defenses in place, highlighting the need for more robust security measures in LLM agent deployments.
Expanding the Battlefield: The Vulnerability of Interconnected Systems
The vulnerabilities of an artificial intelligence system are not limited to how a user directly interacts with it; rather, the system’s exposure extends to encompass its broader environmental interactions. This expanded ‘attack surface’ acknowledges that malicious actors can exploit external sources – data feeds, network connections, even physical sensors – to introduce harmful content or instructions. Effectively, an agent’s reliance on its environment creates avenues for bypassing initial security protocols designed to protect against direct user input. This represents a significant shift in threat modeling, as safeguarding an AI requires a comprehensive understanding not only of how it responds to commands, but also of the integrity and trustworthiness of its surrounding world and all associated data streams.
The vulnerability of large language models extends beyond direct prompt manipulation to include insidious attacks leveraging interactions with the external environment. These attacks bypass initial safety protocols by introducing malicious content not through the user’s immediate input, but through external sources the agent accesses-such as websites, databases, or APIs. An agent, tasked with summarizing information from a compromised website, for instance, might inadvertently disseminate harmful content without ever directly receiving it as part of a user prompt. This circumvents content filters designed to scrutinize user-provided text, presenting a significant challenge to ensuring responsible AI deployment. Consequently, developers must now account for the trustworthiness of external data sources and implement robust validation mechanisms to prevent the injection of malicious payloads through environmental interactions.
The emergence of multi-agent systems introduces a significantly more complex threat landscape than single-agent interactions. These frameworks, designed for collaborative problem-solving, inadvertently create opportunities for coordinated attacks where multiple agents, potentially compromised, work in concert to achieve malicious goals. Such coordinated efforts can bypass individual agent defenses, amplify the impact of exploits, and create emergent behaviors that were not anticipated during the system’s design. The distributed nature of these frameworks also complicates attribution and mitigation, as identifying the source and neutralizing the threat requires understanding the interplay between agents – a task that quickly becomes computationally intensive and strategically challenging. Ultimately, the synergy between compromised agents within these systems can escalate relatively minor vulnerabilities into large-scale disruptions, demanding a paradigm shift in security protocols and threat modeling.
Towards Truly Resilient Agents: Beyond Reactive Defense
Existing security measures for large language model (LLM) agents, though offering a necessary first line of defense, are increasingly revealed as inadequate when confronted with sophisticated, evolving attacks. These attacks, often termed ‘long-horizon,’ don’t rely on immediate exploitation but instead involve subtle manipulations over extended interactions, slowly steering the agent toward unintended and potentially harmful outcomes. Traditional defenses, frequently focused on identifying and blocking individual malicious prompts, struggle to detect these gradual drifts in behavior, as the attacks are designed to remain within acceptable parameters for prolonged periods. This presents a significant challenge, demanding a shift from reactive, prompt-based security to proactive systems capable of monitoring an agent’s internal state and recognizing anomalous patterns that indicate a developing, adaptive threat.
The development of truly trustworthy large language model (LLM) agents necessitates a shift towards proactive security, demanding agents capable of real-time threat detection and mitigation. Current defensive strategies often prove static and are quickly circumvented by attackers who adapt their techniques over extended interactions – a phenomenon known as long-horizon attacks. Consequently, future research must prioritize the integration of dynamic monitoring systems within these agents, allowing them to identify anomalous behavior and evolving adversarial patterns. This requires exploring novel techniques in anomaly detection, reinforcement learning for adaptive defense, and the creation of internal ‘self-awareness’ mechanisms that enable agents to assess their own vulnerabilities and adjust their strategies accordingly. The ultimate goal is not simply to react to attacks, but to anticipate and neutralize them before they can compromise the agent’s integrity or functionality, fostering a new paradigm of resilient and self-protecting AI systems.
Building genuinely trustworthy Large Language Model (LLM) agents demands a multifaceted approach extending beyond current security protocols. Robust defense mechanisms, capable of withstanding sophisticated attacks, must be coupled with rigorous evaluation benchmarks – tools like AgentLAB are vital for systematically assessing agent vulnerabilities and resilience under diverse conditions. However, defense and evaluation are insufficient on their own; proactive security measures are essential. This includes continuous monitoring for anomalous behavior, adaptive threat modeling to anticipate evolving attack vectors, and the implementation of fail-safe mechanisms to limit potential harm. Only through this combined strategy – robust defenses, rigorous testing, and proactive security – can developers hope to create LLM agents capable of operating reliably and safely in complex, real-world environments, fostering genuine user trust and responsible AI deployment.
The relentless pursuit of increasingly ‘intelligent’ agents, as explored in this work with AgentLAB, feels…predictable. This benchmark exposes vulnerabilities to long-horizon attacks, revealing how easily these systems succumb to manipulation after extended interactions. It’s a cycle. One builds elaborate defenses against immediate threats, only to discover production – and a clever attacker – will always find a novel vector. As Grace Hopper famously said, ‘It’s easier to ask forgiveness than it is to get permission.’ This neatly encapsulates the reality of agent security: perfect defense is an illusion. The benchmark’s findings underscore that while current agents may appear sophisticated, they’re built on foundations as shaky as any legacy system. Everything new is old again, just renamed and still broken.
What’s Next?
AgentLAB, as a stress test for increasingly ambitious LLM agents, merely clarifies a predictable truth: complexity amplifies failure modes. The benchmark’s focus on long-horizon attacks is commendable, if belated. Anyone who believed extended interaction would solve inherent vulnerabilities was likely already debugging a disaster. The current suite of defenses, predictably, addresses symptoms, not causes. Each patched vulnerability will inevitably become another layer of abstraction, another point of brittle integration.
The real challenge isn’t creating agents that withstand known attacks, but anticipating the novel ways production systems will inevitably break them. Memory poisoning and prompt injection are just the opening salvos. The field will chase increasingly sophisticated attack vectors, while the fundamental problem – trusting a statistical model to reason about the world – remains untouched.
Future work will undoubtedly explore ‘robust’ agents, ‘self-healing’ agents, and agents that ‘detect’ malicious input. The authors should prepare for a deluge of papers claiming incremental improvements, each with its own carefully curated test suite. Documentation, of course, will remain a myth invented by managers. CI is the temple-one can only pray nothing breaks before the next release.
Original article: https://arxiv.org/pdf/2602.16901.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Shadow Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Best Bows in Crimson Desert
- All Skyblazer Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- Wings of Iron Walkthrough in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- How to Craft the Elegant Carmine Armor in Crimson Desert
- Keeping Large AI Models Connected Through Network Chaos
2026-02-22 00:05