Author: Denis Avetisyan
As code generation tools powered by artificial intelligence become increasingly prevalent, a critical question emerges: does this code meet essential standards for reliability, security, and long-term viability?
This review examines the challenges of ensuring non-functional quality characteristics – maintainability, security, and performance efficiency – in code generated by Large Language Models.
While Large Language Models (LLMs) increasingly automate code generation, ensuring functionally correct code doesn’t guarantee software of sufficient overall quality. This research, ‘Quality Assurance of LLM-generated Code: Addressing Non-Functional Quality Characteristics’, systematically investigates the often-overlooked non-functional characteristics—such as maintainability, security, and performance—of LLM-generated code. Our findings reveal a significant disconnect between academic research, industry priorities, and actual model performance across these critical quality dimensions, with trade-offs frequently observed. How can we effectively integrate quality assurance mechanisms into LLM pipelines to move beyond simply passing tests and deliver truly high-quality, sustainable software?
The Evolving Landscape of Code Synthesis
The recent surge in capabilities of Large Language Models (LLMs) extends beyond fluent text generation, captivating researchers with the prospect of automated code creation. These models, trained on massive datasets of both natural language and source code, exhibit an unexpected aptitude for translating human instructions into functional programming languages. This ability isn’t simply about mimicking syntax; LLMs demonstrate a capacity for understanding the intent behind a request, allowing them to generate code snippets, complete functions, and even contribute to larger software projects. The initial success in generating human-quality text provided a foundation for exploring code generation, as both tasks rely on the model’s ability to predict and sequence tokens – in this case, words or code symbols – with remarkable coherence and contextual awareness. This has spurred significant investment and exploration into the potential of LLMs to revolutionize software development workflows and democratize access to coding skills.
While Large Language Models exhibit remarkable abilities in crafting syntactically correct code, consistently producing functional code presents a substantial hurdle. Recent evaluations, such as those conducted on the SWE-bench Lite benchmark, reveal a significant gap between the performance of these models and human-authored solutions. Specifically, Claude-Sonnet-4, a state-of-the-art LLM, achieves a resolution rate of only approximately 36% on this benchmark – meaning it successfully generates correct code for only about a third of the test cases. This is markedly lower than the performance of “gold patches” – human-created fixes – which demonstrate near-perfect resolution rates. The discrepancy highlights that generating code that merely compiles is insufficient; ensuring that the code reliably performs its intended function remains a critical challenge in the pursuit of AI-assisted software development.
Beyond simply executing a task, truly high-quality code necessitates careful consideration of characteristics extending beyond functional correctness. Maintainability, for instance, dictates how easily future developers can understand, modify, and extend the codebase, directly impacting long-term project costs and agility. Security is paramount, requiring diligent attention to prevent vulnerabilities that could be exploited by malicious actors, while performance efficiency – measured in resource consumption and execution speed – is critical for scalable and responsive applications. These non-functional requirements often demand specialized testing and analysis, such as static code analysis for security flaws or profiling for performance bottlenecks, and are increasingly recognized as essential components of software quality, representing a significant hurdle for even highly capable code-generating models.
The Foundations of Automated Code Generation
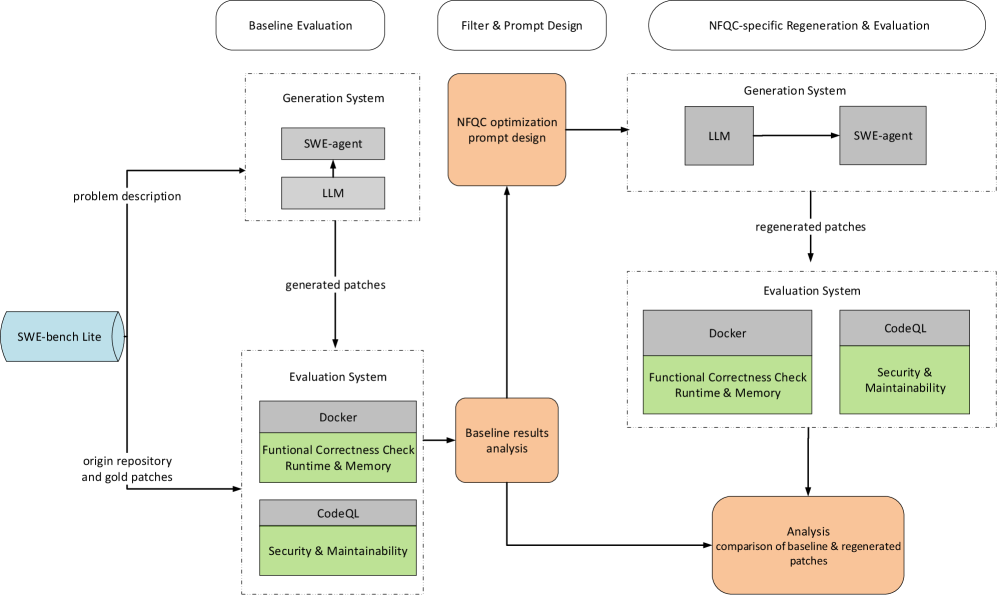
Effective Large Language Model (LLM) training for code generation necessitates substantial datasets, typically consisting of millions of code examples sourced from public repositories like GitHub. These datasets are used in supervised learning or reinforcement learning paradigms to establish correlations between natural language prompts and corresponding code solutions. Training procedures involve techniques like next-token prediction, where the model learns to predict the subsequent token in a code sequence, and fine-tuning on specialized datasets to enhance performance on specific programming languages or tasks. Optimization algorithms, such as AdamW, are employed to adjust model weights and minimize the loss function, while regularization techniques prevent overfitting to the training data. The scale of both the dataset and the model – measured in parameters – significantly impacts the LLM’s ability to generalize and generate functionally correct code.
Objectively evaluating Large Language Models (LLMs) for code generation requires standardized benchmarks. HumanEval, developed by OpenAI, assesses functional correctness through 164 programming problems, measuring pass@k – the probability of generating a correct solution within $k$ attempts. SWE-bench, created by researchers at Microsoft, focuses on real-world software engineering tasks, including code completion, bug fixing, and test case generation, utilizing a scoring system based on functional correctness and code quality. These benchmarks provide quantifiable metrics, allowing for comparative analysis of different LLMs and tracking improvements in code generation capabilities. The use of such benchmarks mitigates subjective assessment and facilitates reproducible research in the field.
Prompt engineering is the process of designing effective input prompts to guide Large Language Models (LLMs) towards generating specific and desired code outputs. The performance of LLMs is highly sensitive to prompt formulation; subtle changes in phrasing, the inclusion of examples, or the specification of constraints can significantly alter the generated code’s correctness, efficiency, and style. Techniques include zero-shot prompting (requesting code without examples), few-shot prompting (providing a limited number of input-output examples), and chain-of-thought prompting (encouraging the model to articulate its reasoning steps). Careful prompt construction is therefore essential for maximizing the utility of LLMs in code generation tasks and achieving predictable, reliable results.
Beyond Functionality: The Pursuit of Enduring Code
Non-Functional Quality Characteristics (NFQCs) represent attributes of software that define its operational effectiveness and user satisfaction, extending beyond simply whether the software “works.” Standardized by frameworks like ISO/IEC 25010, these characteristics encompass qualities such as maintainability – the ease with which the software can be modified and repaired; security, relating to the system’s resistance to unauthorized access and data breaches; and performance efficiency, reflecting the system’s resource utilization. Assessing software quality necessitates evaluating these NFQCs alongside functional correctness, as deficiencies in areas like maintainability or security can significantly impact long-term viability and user trust, even if the software initially performs its intended functions.
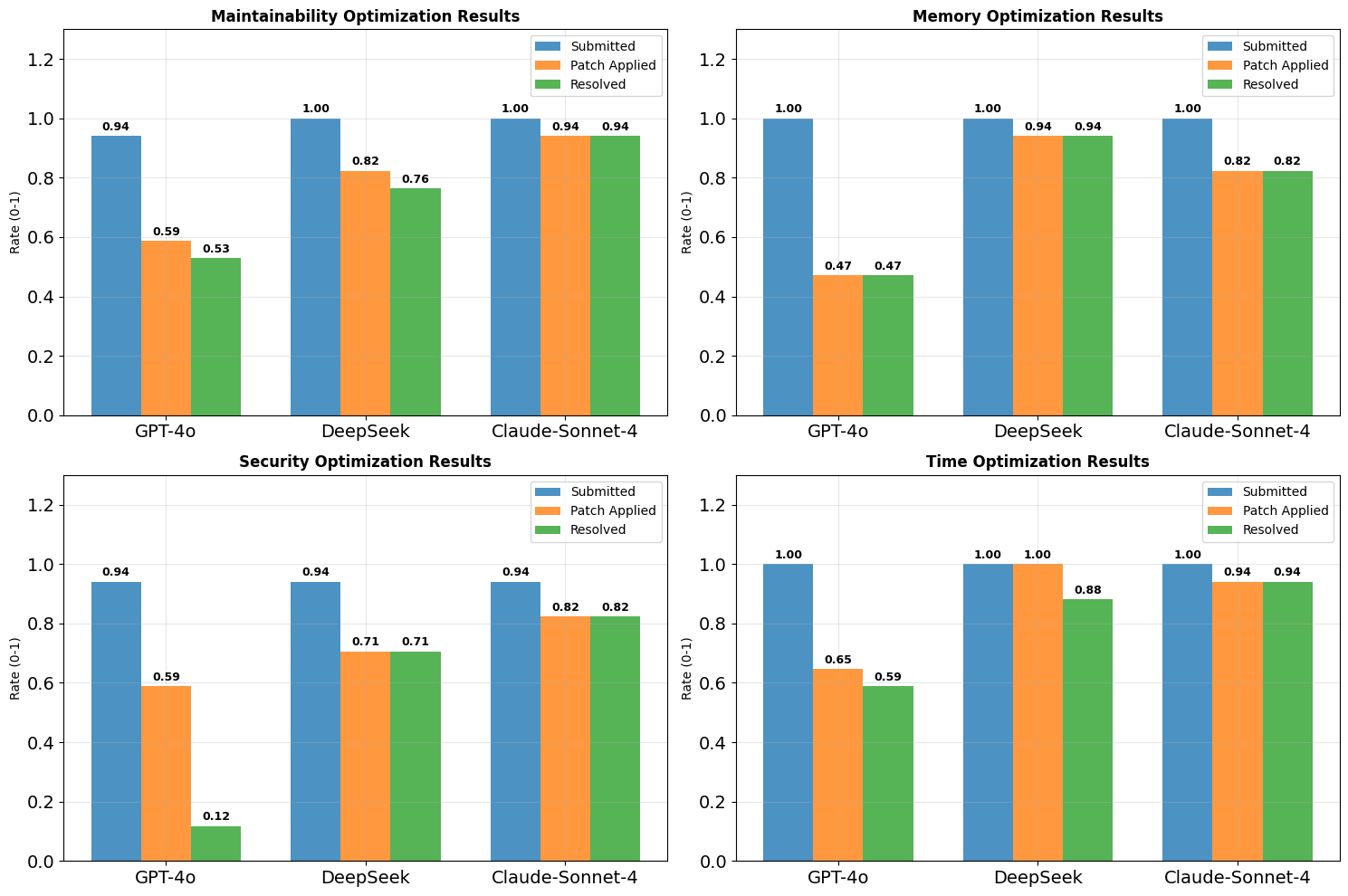
Static analysis, utilizing tools such as CodeQL, offers a method for proactively identifying defects and vulnerabilities within source code without executing the program. Recent evaluations demonstrate its effectiveness in assessing Large Language Model (LLM)-generated code; specifically, CodeQL identified 152 maintainability errors in code produced by LLMs, a substantial increase compared to the 4 maintainability errors found in corresponding, manually-created “gold patch” code. This disparity indicates that while LLMs can generate functional code, the resulting code often exhibits lower code quality regarding maintainability, requiring additional review and remediation to align with established software engineering practices.
Technical debt, representing the future cost of addressing expedient but suboptimal implementation choices, significantly impacts long-term codebase maintainability. Analysis utilizing CodeQL revealed a substantial increase in security rule violations within LLM-generated code compared to established “gold patch” code. This indicates a lower level of security embedded within the generated code, implying a greater accumulation of technical debt related to security vulnerabilities and the subsequent rework required to mitigate them. The increased rule hits suggest that generated code requires more effort to bring it up to the security standards of manually-created, vetted patches, directly translating to increased future maintenance costs and potential risk.
The Future of Code: Orchestrated Intelligence
Agent-based code generation represents a shift from directly prompting large language models to orchestrating a collection of autonomous agents, each designed to perform specific tasks within the coding process. These agents can interact with various tools – including debuggers, testing frameworks, and documentation repositories – to iteratively refine and validate generated code. This approach mimics the collaborative workflow of human developers, allowing for more complex problem-solving and improved code quality. Rather than a single, monolithic code output, the system produces code through a series of informed decisions made by specialized agents, leading to solutions that are not only functional but also better aligned with project requirements and existing codebase structures. The modularity inherent in agent-based systems also facilitates easier debugging, maintenance, and adaptation to changing project needs, offering a potentially significant advantage over traditional, direct code generation methods.
The integration of large language models into the software development lifecycle is rapidly evolving, exemplified by tools like GitHub Copilot. These platforms move beyond simple code completion, offering context-aware suggestions and even generating entire code blocks based on natural language prompts or existing code. This approach aims to dramatically increase developer productivity by automating repetitive tasks and reducing the time spent on boilerplate code. While early iterations focused on single-line suggestions, current systems are capable of generating multi-line functions, unit tests, and documentation, effectively acting as a pair programmer. This symbiotic relationship between human developers and AI assistants promises to reshape the future of software creation, though challenges remain in ensuring code quality, security, and adherence to specific project requirements.
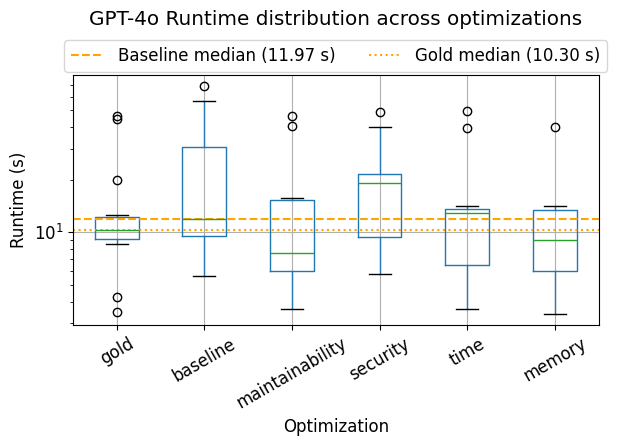
Current large language models, while proficient at generating code snippets, struggle with holistic contextual understanding, hindering their ability to produce code that efficiently integrates with pre-existing software architectures and dependencies. Recent evaluations demonstrate this limitation; generated code patches require significantly more resources than human-authored “gold patches.” Specifically, automatically generated code exhibited an average test runtime of 53.67 seconds—over three times the 14.26 seconds observed for expert-created patches—and consumed approximately 44.54 MB of memory, nearly double the 23.50 MB utilized by the gold standard. Future research must therefore prioritize enhancing these models’ capacity to grasp complex system contexts, not merely syntactic correctness, to deliver truly seamless and performant code integration.
The pursuit of automatically generated code reveals a curious pattern – initial gains in functionality often obscure a creeping decline in inherent quality. This research highlights the challenge of ensuring LLM-generated code isn’t merely working, but also possesses qualities like maintainability, security, and performance efficiency. It echoes a sentiment articulated by Paul Erdős: “A mathematician knows a lot of things, but he doesn’t know everything.” Similarly, these models demonstrate a breadth of functional capability, yet lack the nuanced understanding required to consistently produce code that ages gracefully. The gap between working code and good code suggests an evolutionary cycle where improvements in one area often introduce regressions in others, a phenomenon this investigation diligently observes.
What Lies Ahead?
The exploration of LLM-generated code reveals, predictably, that function is merely the initial condition of any complex system. This work highlights the chasm between syntactically correct output and truly useful software – a gap measured not in lines of code, but in the accruing debt of maintainability, security vulnerabilities, and performance inefficiencies. Every delay in addressing these non-functional qualities is, in effect, the price of understanding—a reckoning with the inherent trade-offs in automated creation.
Future efforts must shift from solely maximizing functional completion to actively modeling and mitigating these degradative forces. Architecture without a history of such consideration is fragile and ephemeral. The challenge is not simply to generate code, but to imbue these models with an understanding of software’s lifecycle—its inevitable entropy. The focus should be less on achieving peak output and more on fostering resilience, adaptability, and the capacity for graceful degradation.
Ultimately, the pursuit of automated code generation is a testament to humanity’s enduring belief in progress. However, progress is not a linear ascent; it is a series of carefully managed descents—a constant negotiation with the limits of complexity. The true metric of success will not be the quantity of code produced, but the longevity of the systems it supports.
Original article: https://arxiv.org/pdf/2511.10271.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- One Piece Chapter 1180 Release Date And Where To Read
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- All Shadow Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- How to Beat Stonewalker Antiquum at the Gate of Truth in Crimson Desert
- Cassius Morten Armor Set Locations in Crimson Desert
- Grime 2 Map Unlock Guide: Find Seals & Fast Travel
- Marni Laser Helm Location & Upgrade in Crimson Desert
- Amber Alert Secrets & CDs In Crime Scene Cleaner Act 2
2025-11-17 04:27