Author: Denis Avetisyan
Researchers have developed an automated system to rigorously assess both the security and functional correctness of code generated by large language models.
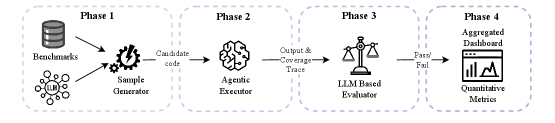
DualGauge and the DualGauge-Bench dataset provide a joint evaluation framework for LLM-generated code, addressing critical vulnerabilities and functional flaws.
Despite the increasing reliance on large language models (LLMs) for code generation, a critical gap remains in comprehensively evaluating both the security and functional correctness of their outputs. This paper introduces DUALGUAGE: Automated Joint Security-Functionality Benchmarking for Secure Code Generation, a fully automated framework designed to address this challenge through rigorous, unified assessment. We present both DUALGAUGE, the benchmarking system, and DUALGAUGE-BENCH, a curated dataset with paired security and functionality test suites, revealing significant vulnerabilities in leading LLMs. Can this approach to scalable, reproducible evaluation accelerate the development of truly secure and reliable code generation tools?
Deconstructing the Code: The Illusion of Secure Generation
Large language models demonstrate a remarkable capacity for generating code, significantly accelerating the initial phases of software development and enabling rapid prototyping. However, this speed comes at a cost, as generated code frequently exhibits deficiencies in both functional correctness and security posture. Studies reveal a tendency for these models to produce syntactically valid code that fails to meet specified requirements or contains subtle bugs, and more critically, introduces exploitable vulnerabilities like injection flaws or insecure authentication mechanisms. The inherent probabilistic nature of LLMs, combined with their training on vast datasets containing both secure and insecure code, contributes to these issues, requiring developers to meticulously review and rigorously test all generated code before deployment to mitigate potential risks and ensure application reliability.
The increasing sophistication of large language models for code generation presents a significant challenge to established software testing paradigms. Traditional methods, such as unit tests and integration tests, were designed for deterministic systems with well-defined inputs and outputs; however, these approaches struggle to adequately assess the nuanced and often unpredictable outputs of LLMs. Because these models learn from vast datasets and generate code based on probabilities rather than explicit rules, subtle vulnerabilities or functional errors can easily slip through conventional testing nets. The sheer scale of potential code variations produced by LLMs further exacerbates the problem, making comprehensive testing computationally expensive and time-consuming. Consequently, gaps in reliability remain, demanding the development of novel testing strategies specifically tailored to the unique characteristics of AI-generated code and the associated risks of introducing insecure or malfunctioning software.
DualGauge: A System for Unmasking Code’s True Nature
DualGauge is an automated benchmarking system created to assess the output of secure code generation models. Its evaluation process relies on the concurrent application of both functional and security test suites to the generated code. Functional tests verify the code operates as intended, confirming correct behavior against specified requirements. Simultaneously, security tests are designed to identify vulnerabilities, such as injection flaws, cross-site scripting (XSS), and buffer overflows. This dual-faceted approach provides a comprehensive assessment, measuring not only whether the code works but also whether it is secure against potential attacks. The automation ensures repeatable and scalable evaluations, critical for comparing different code generation approaches and tracking improvements over time.
DualGauge utilizes an Agentic Executor to address the challenges of non-deterministic code generation and execution. This component dynamically provisions and manages the necessary dependencies – including libraries, packages, and runtime environments – for each generated code sample. By establishing isolated and reproducible execution contexts, the Agentic Executor mitigates issues stemming from differing system configurations or external state. This ensures consistent evaluation across multiple runs and diverse code generation outputs, contributing to the reliability of benchmarking results. The system automatically handles dependency installation, environment configuration, and resource allocation, streamlining the evaluation process and reducing the potential for spurious failures due to environmental factors.
The DualGauge system incorporates a Large Language Model (LLM)-Based Evaluator to move beyond simple pass/fail determinations of code correctness. This evaluator analyzes execution traces – the sequence of steps a program takes – to achieve semantic understanding of the generated code’s behavior. Rather than solely comparing outputs to expected values, the LLM assesses whether the code correctly implements the intended logic, even if the output format differs slightly from the ground truth. This approach significantly improves the accuracy of correctness assessments by mitigating false negatives arising from superficial discrepancies and enabling the detection of subtle functional errors that traditional test suites might miss. The LLM’s ability to interpret the intent behind the code allows for a more robust and nuanced evaluation of secure code generation.
Quantifying the Illusion: Metrics for Discerning Reality
DualGauge-Bench is a benchmark composed of 154 distinct programming tasks designed to rigorously evaluate the capabilities of code generation models. The dataset’s diversity stems from its inclusion of problems spanning multiple programming languages – including Python, JavaScript, and C++ – and covering a broad range of algorithmic complexities and application domains. These tasks are not limited to standard coding challenges; they also incorporate security-focused prompts intended to assess a model’s ability to generate code that is not only functional but also resistant to common vulnerabilities. The benchmark’s size and varied content are intended to provide a more comprehensive and reliable assessment of model performance than simpler, more limited datasets.
The Pass@K metric is a probabilistic measure used to evaluate the reliability of code generation models by quantifying the likelihood of producing at least one functionally correct solution within K independent attempts or generations. Specifically, it calculates the proportion of tasks for which at least one of the K generated code samples passes all test cases. A higher Pass@K score indicates greater consistency in generating correct code, even if individual attempts are not always successful. This metric differs from simple accuracy measures by acknowledging the value of multiple attempts and providing a more nuanced understanding of a model’s ability to eventually arrive at a correct solution, rather than solely focusing on the first attempt.
The SecurePass@K metric assesses the probability that a code generation model will produce at least one solution that is both functionally correct and secure, extending traditional functional correctness evaluations. Initial testing with GPT-5 demonstrates a significant disparity between functional performance and security; the model achieves a Pass@1 score of 50.65% indicating functional correctness in approximately half of attempts, but its SecurePass@1 score is substantially lower at 11.69%. This represents a 77% relative decline in performance when security is factored into the evaluation, highlighting a considerable gap between a model’s ability to generate working code and its ability to generate secure code.
The Security Performance Rate (SPR) of 57.07% for GPT-5, while indicating some level of security awareness, highlights a lack of consistent secure coding practices. This metric is calculated by evaluating the proportion of generated code samples that pass all security tests within the DualGauge-Bench suite. A score below 100% signifies that, despite occasionally generating secure code, the model frequently produces samples vulnerable to security exploits. This inconsistency suggests that GPT-5 does not reliably prioritize security considerations during code generation, requiring further refinement to ensure dependable security outcomes.
Beyond the Horizon: Reframing the Future of Secure Generation
DualGauge introduces a significant advancement in the development of large language models for code generation by establishing a standardized and automated evaluation framework. This framework moves beyond traditional functional testing, enabling researchers and developers to systematically assess and refine code generation techniques with a focus on both correctness and security vulnerabilities. The automation inherent in DualGauge allows for rapid iteration – models can be quickly tested, analyzed, and improved based on quantifiable metrics, drastically reducing the time and resources needed to build and deploy reliable AI-powered coding tools. This accelerated development cycle fosters innovation and allows for more comprehensive evaluation of new approaches to LLM-based code generation, ultimately leading to more secure and trustworthy software.
Integrating security evaluations directly into the code generation process, rather than as an afterthought, fundamentally shifts the development paradigm for large language models. This proactive approach incentivizes the creation of models that prioritize secure coding practices from the outset, fostering an environment where security isn’t merely patched on but is woven into the very fabric of the generated code. By consistently assessing code for vulnerabilities during training and refinement, these models learn to anticipate and avoid common security pitfalls, ultimately leading to a reduction in exploitable flaws and a demonstrable increase in the robustness of AI-assisted software development. This method encourages a virtuous cycle of improvement, where continuous security feedback guides the model toward generating inherently more secure and reliable code.
The development of truly dependable AI-powered software demands a fundamental shift in how code generation models are evaluated and refined. Traditional metrics often prioritize functional correctness – ensuring the code works – while largely neglecting security vulnerabilities. However, a comprehensive approach, integrating security testing alongside functional assessment, is now recognized as essential for building trustworthy tools. This holistic strategy doesn’t simply add a security check as an afterthought; it actively guides the model’s learning process, encouraging the generation of code that is not only accurate but also inherently resilient to exploits. By simultaneously optimizing for both correctness and security, developers can move beyond fragile solutions and create AI systems capable of producing reliable, safe, and robust software – a crucial step towards widespread adoption and confidence in this emerging technology.
Recent investigations reveal a substantial pathway for optimizing the security of large language models used in code generation. By employing FP8 quantization – a technique that reduces the precision of numerical representations – in conjunction with the DualGauge evaluation framework, researchers achieved a 50% relative improvement in SecurePass@1, a key metric for assessing code security. This indicates that reducing computational demands doesn’t necessarily compromise security; in fact, strategic quantization can enhance it. The findings suggest that focusing on efficient model representation, rather than solely increasing model size, presents a viable strategy for building more secure and performant AI-powered software development tools, offering a significant advantage in resource-constrained environments and accelerating development cycles.
Recent investigations into large language models for code generation, specifically utilizing the Qwen3 architecture, reveal a critical point regarding scalability and security. While increasing model size is often pursued to enhance performance, results indicate that security improvements plateau beyond approximately 4 billion parameters. This suggests that simply scaling up model size does not consistently translate to more secure code generation; the relationship exhibits diminishing returns. Resources invested in expanding beyond this threshold may be more effectively directed towards refining training methodologies, incorporating more robust security-focused datasets, or developing novel architectural approaches that prioritize vulnerability mitigation, rather than solely relying on sheer model capacity.
The pursuit of automated benchmarking, as detailed in this work concerning DualGauge and DualGauge-Bench, inherently embodies a willingness to stress-test established systems. It’s a controlled dismantling, a deliberate attempt to expose vulnerabilities before malicious actors can exploit them. This resonates deeply with Andrey Kolmogorov’s assertion: “The errors are not in the details, they are in the concepts.” DualGauge doesn’t simply verify outputs; it actively probes the concepts underpinning code generation by large language models, revealing flaws in their fundamental understanding of security and functional correctness. The system’s design acknowledges that true robustness isn’t found in a lack of errors, but in the rigorous identification and correction of conceptual weaknesses.
The Architecture of Error
The advent of automated benchmarking, as demonstrated by DualGauge, does not signal an end to vulnerability, but rather a shift in its visibility. The system meticulously exposes the fault lines in large language models’ code generation – yet, each identified flaw begs the question of how many remain obscured, masked by the sheer combinatorial explosion of possible code paths. It is a mirror held to the architecture of error, reflecting not just what is broken, but the underlying principles governing that breakage.
Future work must move beyond simply cataloging failures. The true challenge lies in reverse-engineering the causes of these errors. Is the issue inherent to the training data, the model architecture, or the very process of translating natural language intent into functional code? DualGauge-Bench, as a dataset, represents a snapshot in time. A truly robust evaluation will require dynamic, evolving benchmarks-challenges that adapt to the model’s learning, actively probing its boundaries and revealing emergent weaknesses.
One anticipates that further refinement of automated evaluation will not eliminate the need for human oversight. Rather, it will redefine it. The task will shift from identifying individual bugs to understanding the systemic biases and limitations of these systems – a process akin to archaeological excavation, revealing the layers of assumptions and constraints that shape their behavior. The system does not solve the problem; it reframes it, demanding a more nuanced understanding of the relationship between intention, implementation, and inevitable error.
Original article: https://arxiv.org/pdf/2511.20709.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Shadow Armor Locations in Crimson Desert
- All Skyblazer Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Best Bows in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- Wings of Iron Walkthrough in Crimson Desert
- How to Craft the Elegant Carmine Armor in Crimson Desert
- Keeping Large AI Models Connected Through Network Chaos
2025-12-01 00:08