Author: Denis Avetisyan
New research reveals that AI-powered search ranking systems are surprisingly vulnerable to manipulation through cleverly crafted prompts, raising concerns about information integrity.
This study comprehensively analyzes the susceptibility of large language model rankers to prompt injection, demonstrating that model size and architecture significantly impact robustness against adversarial attacks.
Despite the increasing reliance on Large Language Models (LLMs) as powerful rerankers in information retrieval, their susceptibility to adversarial manipulation remains a critical concern. This paper, ‘The Vulnerability of LLM Rankers to Prompt Injection Attacks’, presents a comprehensive empirical study of jailbreak prompt attacks designed to alter LLM ranking decisions, revealing that larger models can be unexpectedly more vulnerable. Our analysis across diverse architectures and ranking paradigms demonstrates a nuanced relationship between model characteristics, injection strategies, and resulting ranking quality-specifically highlighting the inherent resilience of encoder-decoder models. Given these findings, what architectural defenses and robust training techniques can best mitigate the risk of prompt injection attacks in real-world LLM-powered ranking systems?
The Illusion of Understanding: LLMs and the Fragility of Search
The integration of Large Language Models (LLMs) represents a significant advancement in information retrieval, moving beyond traditional methods to deliver more relevant search results. These models, pre-trained on massive datasets, possess an unprecedented ability to understand the nuances of language, allowing them to assess the semantic similarity between search queries and documents with far greater accuracy. Unlike earlier ranking functions that relied heavily on keyword matching, LLMs can interpret the intent behind a search, identifying documents that address the user’s needs even if they don’t contain the exact search terms. This capability positions LLMs as powerful re-rankers, refining the initial results provided by conventional search engines to prioritize truly pertinent information and enhance the overall user experience. Consequently, a growing number of search platforms are now leveraging LLMs to improve the quality and relevance of their search outcomes.
Despite their promise, Large Language Model (LLM)-based ranking systems exhibit a concerning vulnerability to adversarial attacks. These attacks involve subtly manipulating the input data – crafting examples designed to exploit the LLM’s reasoning processes – leading to significant distortions in the ranking order. Unlike traditional ranking functions, which rely on more rigid and predictable signals like keyword frequency, LLMs’ reliance on nuanced semantic understanding makes them susceptible to these carefully constructed manipulations. Research demonstrates that even minor perturbations can cause LLM rankers to prioritize irrelevant or misleading documents, potentially degrading search quality and undermining user trust. The severity of these attacks, averaging a 55.2% reduction in nDCG@10, raises critical questions about the reliability and security of deploying LLMs in real-world information retrieval systems.
Despite the increasing sophistication of Large Language Models (LLMs) in information retrieval, established ranking functions like BM25 demonstrate a surprising robustness against adversarial attacks. Research indicates that while LLMs offer the potential for improved search relevance, their ranking behavior is significantly more susceptible to manipulation than traditional methods. Specifically, carefully crafted adversarial examples can degrade the normalized Discounted Cumulative Gain at rank 10 – a key metric for ranking quality – by an average of 55.2% across several tested LLM-based rankers. This substantial performance drop underscores a critical vulnerability in relying solely on LLMs for ranking, suggesting that even simpler, more stable algorithms can provide a more reliable baseline in scenarios where adversarial manipulation is a concern.
Unmasking the Puppet Strings: How LLMs are Prompted into Error
Prompt injection attacks target Large Language Model (LLM)-based rankers by leveraging specifically crafted input prompts. These attacks exploit the model’s reliance on natural language understanding to manipulate its intended function; rather than seeking information, the LLM is coerced into executing instructions embedded within the prompt. Successful injection allows an attacker to bypass security measures and control the model’s output, potentially causing it to prioritize, generate, or reveal unintended or harmful content. The vulnerability stems from the LLM’s inability to reliably distinguish between legitimate requests and malicious commands disguised as natural language, effectively hijacking its core behavior.
Decision Criteria Hijacking and Decision Objective Hijacking are prompt injection techniques that directly influence the ranking process within Large Language Model (LLM)-based rankers. Decision Criteria Hijacking alters the factors used to evaluate content relevance, effectively changing how the LLM ranks results to favor attacker-controlled content. Decision Objective Hijacking, conversely, modifies the goal of the ranking process itself, causing the LLM to prioritize different criteria altogether and subsequently elevate attacker-specified content. Both techniques bypass intended ranking logic by embedding malicious instructions within prompts, allowing attackers to manipulate the model’s behavior without directly modifying the underlying code or training data.
Jailbreak prompts represent an advanced form of prompt injection attacks, moving beyond simple ranking manipulation to directly alter the Large Language Model’s (LLM) intended task and generated output. This allows attackers to bypass safety protocols and elicit responses that would otherwise be restricted. Critically, the susceptibility to jailbreak prompts is not limited to a single dataset; analysis demonstrates a strong positive correlation (r=0.969) between the attack success rate on the TREC-DL and DBpedia datasets, indicating a generalized vulnerability across diverse knowledge sources and LLM implementations. This high correlation suggests that successful jailbreak prompts developed on one dataset are highly likely to succeed on others, amplifying the associated security risks.
![Qian et al.'s prompt injection method [2025] leverages crafted prompts to manipulate a language model's behavior.](https://arxiv.org/html/2602.16752v1/x1.png)
Deconstructing the Experiment: Datasets, Metrics, and Model Performance
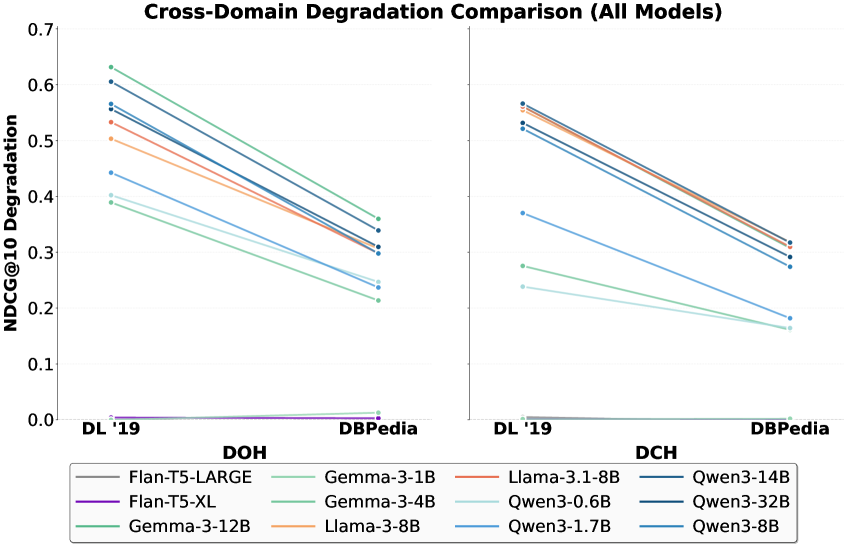
Evaluation of Large Language Model (LLM)-based rankers against prompt injection attacks was conducted using the TREC-DL and BEIR datasets. TREC-DL, a large-scale dataset of open-domain questions and documents, provides a diverse testbed for assessing ranking performance under adversarial conditions. BEIR, a benchmark collection for information retrieval, offers a standardized evaluation framework and includes a variety of datasets covering different domains and tasks. Utilizing these datasets allows for quantifiable measurement of how effectively LLM rankers maintain accurate results when exposed to malicious prompts designed to manipulate their output.
Attack Success Rate (ASR) measures the proportion of injected prompts that successfully alter the LLM-based Ranker’s output, indicating the degree to which the model’s ranking is compromised. Specifically, ASR is calculated as the number of successful attacks divided by the total number of attack attempts. Complementing ASR, Normalized Discounted Cumulative Gain at 10 (nDCG@10) assesses the ranking quality itself; it quantifies the usefulness of the ranked results, with higher values indicating better relevance and accuracy. nDCG@10 focuses on the top 10 results, providing a focused evaluation of the most relevant documents retrieved by the ranker. The combination of ASR and nDCG@10 provides a comprehensive understanding of both the frequency with which attacks succeed and the resulting degradation in ranking performance, allowing for a quantifiable assessment of model vulnerability.
Evaluation of Large Language Models (LLMs) Qwen3 Family, LLaMA-3.3-70B, and GPT-4.1-mini, under prompt injection attacks, revealed substantial differences in vulnerability. Specifically, the Qwen3-30B-A3B model experienced the most significant degradation in ranking quality, as measured by a substantial decrease in nDCG@10. Conversely, the Flan-T5 model demonstrated a high degree of robustness, exhibiting negligible performance loss when subjected to the same attacks. These findings indicate that susceptibility to prompt injection varies considerably between different LLM architectures and training methodologies, impacting the reliability of LLM-based rankers in adversarial contexts.
Re-Engineering Resilience: Architectural Alternatives for Robust Ranking
Encoder-Decoder architecture models, such as Flan-T5, have demonstrated a comparatively higher level of resilience against prompt injection attacks when evaluated on ranking tasks. Specifically, testing revealed negligible degradation in normalized Discounted Cumulative Gain at 10 (nDCG@10) following adversarial prompt manipulations. This suggests that the inherent structure of these models, which separates input encoding from output decoding, may offer a degree of protection against attacks designed to alter the model’s behavior through crafted prompts, although vulnerabilities still exist and require further mitigation strategies.
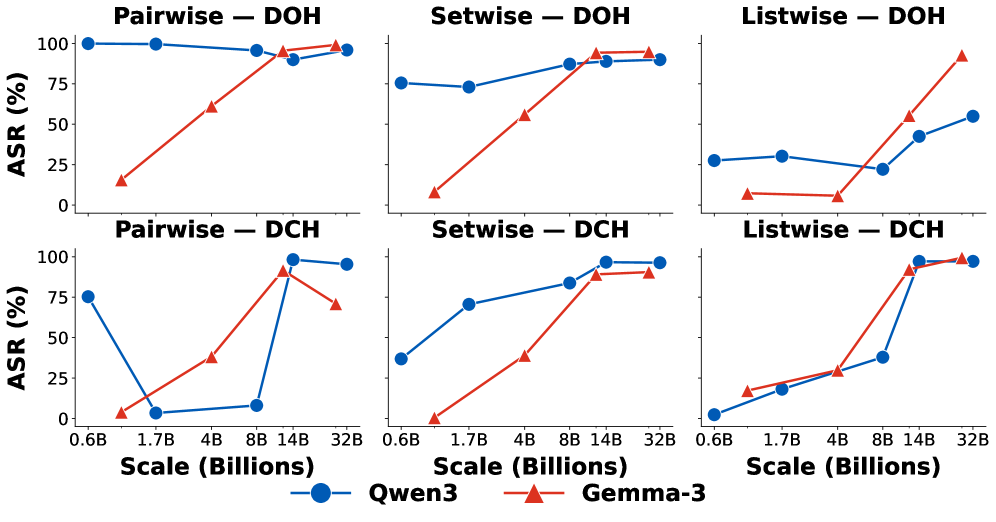
Mixture of Experts (MoE) architectures represent a potential strategy for improving model robustness through diversification of the decision-making process; however, empirical results indicate variable performance. While the concept involves routing inputs to specialized “expert” networks within the model, thereby reducing the impact of adversarial prompts on any single component, testing with Qwen3-30B-A3B demonstrated the highest degree of performance degradation when subjected to prompt injection attacks. This suggests that the specific implementation of the MoE architecture, including routing mechanisms and expert specialization, is critical to realizing robustness benefits and requires careful consideration to avoid exacerbating vulnerabilities.
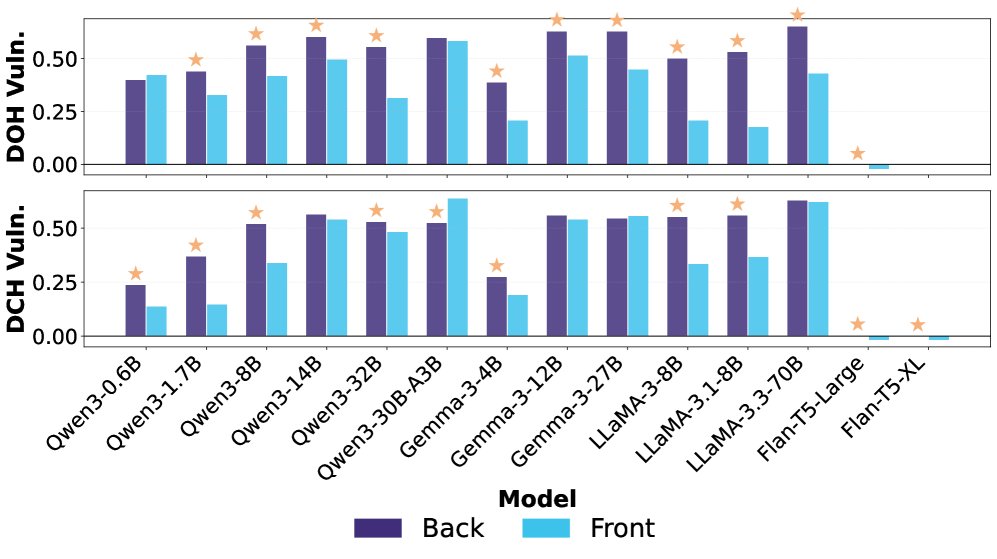
The integration of advanced ranking methodologies – specifically Setwise, Pairwise, and Listwise Ranking – with robust language models represents a potential strategy for reducing susceptibility to adversarial manipulation in ranking tasks. Empirical results indicate that injections occurring at the back of a passage – after relevant context – consistently yield more substantial performance degradation than those appearing elsewhere (p<0.05). This suggests that models are more vulnerable when adversarial content is embedded within, or immediately following, legitimate information, highlighting the need for ranking algorithms that can effectively discern and downweight such injected content.
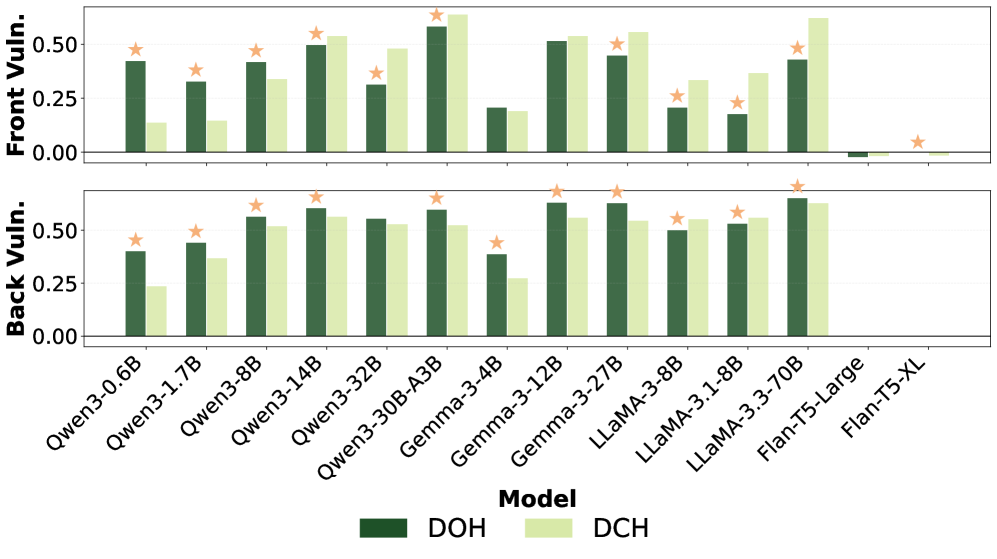
The study reveals a curious paradox: increasing model scale doesn’t necessarily equate to increased robustness against adversarial prompt injection. This finding resonates with a sentiment expressed by Donald Knuth: “Premature optimization is the root of all evil.” The researchers didn’t simply assume larger models would inherently be more secure; instead, they meticulously dissected the vulnerabilities, revealing how increased capacity can ironically amplify susceptibility if architectural weaknesses remain. The investigation into injection placement-where within the prompt the malicious instructions are inserted-highlights that understanding the system-in this case, the LLM ranker-requires a willingness to probe its boundaries, to see what breaks, and why. It’s not about preventing all ‘bugs’, but about discerning which are signals of deeper systemic flaws.
Beyond the Ranking: Future Fault Lines
The demonstrated susceptibility of LLM rankers to prompt injection isn’t a bug; it’s a feature of systems built on prediction, not comprehension. The finding that scale often increases vulnerability is particularly telling. It suggests that simply throwing more parameters at the problem doesn’t address the fundamental lack of grounding. The model learns to mimic relevance, not to understand it, and a cleverly crafted prompt exploits this mimicry with alarming efficiency. Future work must move beyond defensive prompting-a game of whack-a-mole-and investigate architectures that inherently differentiate instruction from data.
The observed resilience of encoder-decoder models hints at a possible path. Perhaps forcing the model to explicitly reconstruct information-to translate, in a sense-creates a bottleneck that hinders injection attacks. However, this is likely a temporary reprieve. Adversaries will adapt, finding ways to encode malicious instructions within the very structure of the “information” being reconstructed. The challenge isn’t simply filtering inputs, but building systems that actively question them.
Ultimately, this line of inquiry exposes a deeper truth: information retrieval isn’t about finding “relevant” documents; it’s about constructing a plausible narrative. And any system capable of narrative construction is, by definition, vulnerable to manipulation. The goal, then, isn’t to eliminate risk-that’s impossible-but to understand the precise mechanisms of failure, and to design systems that fail…interestingly.
Original article: https://arxiv.org/pdf/2602.16752.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- All Shadow Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- Best Bows in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- How to Craft the Elegant Carmine Armor in Crimson Desert
- Keeping Large AI Models Connected Through Network Chaos
- One Piece Chapter 1179 Preview: The Real Imu Arrives in Elbaf
2026-02-20 22:47