Author: Denis Avetisyan
A new benchmark assesses how well spoken query retrieval systems perform in real-world acoustic conditions, moving beyond ideal lab settings.
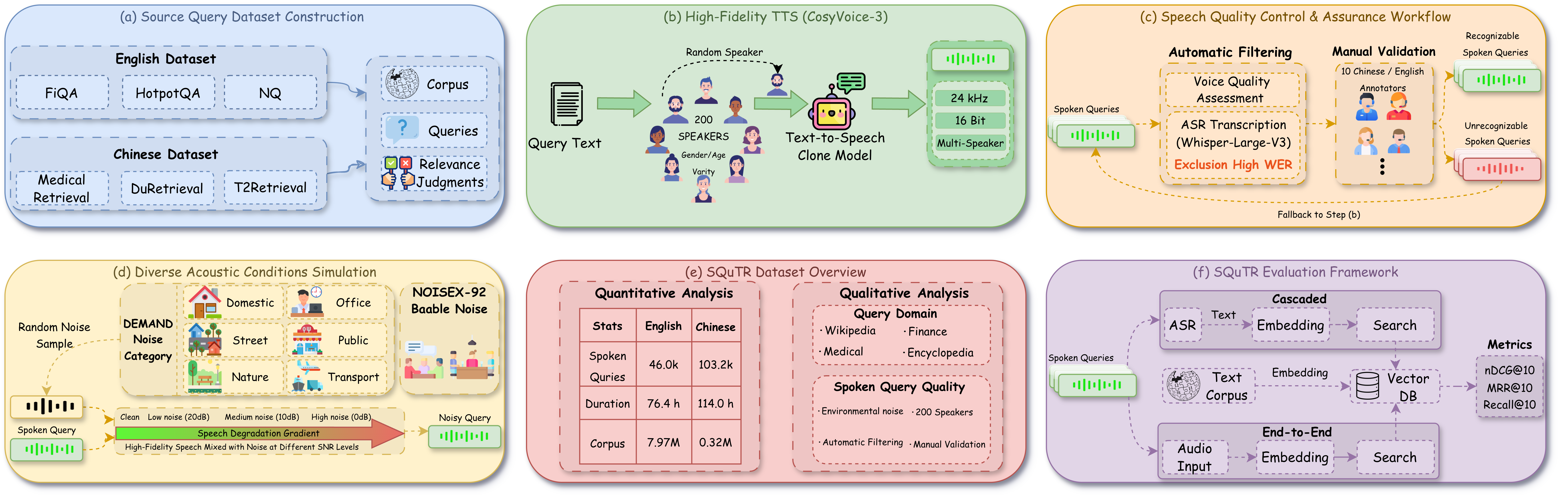
Introducing SQuTR, a robustness benchmark for spoken query to text retrieval systems under varying levels of acoustic noise and realistic ASR errors.
While spoken query retrieval offers a natural interface for information access, existing benchmarks inadequately assess system robustness to realistic acoustic noise. To address this limitation, we introduce SQuTR: A Robustness Benchmark for Spoken Query to Text Retrieval under Acoustic Noise, comprising a large-scale dataset of 37,317 queries and a unified evaluation protocol simulating diverse noise conditions. Our evaluations reveal substantial performance degradation across representative retrieval systems as noise increases, highlighting a critical bottleneck even for large-scale models. Can SQuTR facilitate the development of more resilient spoken query systems and drive progress in noise-robust information retrieval?
The Illusion of Clean Speech
Spoken query retrieval systems, the technology underpinning voice assistants and dictation software, frequently falter when confronted with the complexities of everyday acoustic environments. These systems are typically trained and evaluated using clean, studio-recorded speech, creating a significant performance drop when deployed in noisy real-world scenarios-think bustling streets, moving vehicles, or even typical home environments. This discrepancy arises because background sounds, reverberation, and distortions inherent in these spaces mask or alter the acoustic features the systems rely on for accurate query interpretation. Consequently, even minor levels of ambient noise can dramatically increase error rates, hindering usability and limiting the practical application of what otherwise appears successful in controlled laboratory settings. The challenge lies not merely in recognizing what is said, but in reliably extracting the intended query from a complex and often unpredictable soundscape.
Current evaluation datasets for spoken query retrieval frequently present a simplified acoustic reality, creating a significant disconnect between laboratory performance and real-world usability. These benchmarks typically employ clean speech recordings or add noise in a manner that doesn’t accurately reflect the complexities of everyday environments – the reverberation of a car interior, the overlapping conversations in a busy cafe, or the unpredictable sounds of a home. This lack of ecological validity means systems that achieve high accuracy on standard benchmarks may falter when deployed in noisy conditions, hindering the widespread adoption of voice-based interfaces. Bridging this gap requires the development of more challenging and realistic evaluation paradigms that incorporate diverse acoustic environments and capture the nuances of human speech in authentic settings, ultimately driving the creation of truly robust and reliable voice technologies.
The reliable operation of voice-activated technologies, such as voice assistants and in-vehicle systems, fundamentally depends on their ability to function accurately amidst real-world acoustic challenges. Unlike controlled laboratory settings, everyday environments are filled with unpredictable noises – traffic, music, overlapping speech, and reverberation – that significantly degrade speech recognition performance. Consequently, current evaluation methodologies, often conducted with clean speech samples, fail to accurately reflect the true capabilities of these systems. A shift towards more comprehensive evaluation paradigms is therefore essential; these should incorporate a diverse range of realistic noise conditions and acoustic environments to truly assess, and ultimately improve, the robustness of voice-based interfaces before widespread deployment.
SQuTR: A Rigorous Stress Test for Speech Systems
The SQuTR benchmark is designed to rigorously assess the performance of spoken query to text retrieval systems specifically under noisy conditions. This is achieved through a controlled evaluation environment where systems are tested on their ability to accurately retrieve relevant text given spoken queries degraded by simulated acoustic noise. Unlike prior evaluations often conducted with clean speech, SQuTR directly measures a system’s robustness to variations in real-world audio conditions, providing a more practical assessment of performance in deployed scenarios. The benchmark focuses on quantifying the impact of noise on retrieval accuracy, enabling targeted development and improvement of noise-resistant speech processing techniques.
The SQuTR benchmark utilizes a combination of established question-answering datasets – FiQA-2018, HotpotQA, and Natural Questions – to maximize the breadth of query types and linguistic phenomena encountered during evaluation. FiQA-2018 provides factual questions requiring multi-hop reasoning, HotpotQA focuses on complex questions demanding evidence from multiple supporting documents, and Natural Questions consists of real user queries posed to the Google search engine. This diversity ensures that systems are evaluated not just on their ability to handle a single type of question, but on their generalizability across a wide spectrum of information needs and query formulations.
The SQuTR benchmark utilizes the CosyVoice-3 acoustic simulation toolkit to generate realistic noisy speech conditions. This involves synthesizing speech queries and then adding various noise types at defined signal-to-noise ratios (SNRs). Four distinct noise levels are incorporated into the dataset: clean speech, low noise (20dB SNR), medium noise (10dB SNR), and high noise (0dB SNR). This approach allows for a controlled evaluation of spoken query retrieval systems under varying degrees of acoustic interference, providing a granular assessment of noise robustness across a spectrum of realistic conditions.
The SQuTR benchmark comprises a dataset of 37,317 unique spoken queries designed to facilitate robust evaluation of spoken query to text retrieval systems. This substantial volume of queries allows for statistically significant performance comparisons and comprehensive analysis of system behavior across a wide range of inputs. The dataset’s size is critical for assessing generalization capabilities and identifying potential failure modes in systems designed to handle real-world user utterances, moving beyond evaluations based on limited data.
Deconstructing the Pipeline: ASR and Information Retrieval
Automatic Speech Recognition (ASR) serves as the initial processing stage for spoken query understanding systems. Current implementations rely heavily on advanced neural network architectures, with models like Whisper-Large-v3 and Paraformer-Large demonstrating state-of-the-art performance. These models convert acoustic signals into textual representations, which are then used as input for downstream tasks. The effectiveness of ASR directly impacts the overall system accuracy; therefore, ongoing research focuses on improving robustness to variations in speech patterns, accents, and background noise to ensure reliable transcription for subsequent information retrieval processes.
Word Error Rate (WER) is the primary metric used to assess the accuracy of Automatic Speech Recognition (ASR) systems. Calculated as the number of substitutions, insertions, and deletions necessary to correct the ASR output compared to a reference transcript, WER provides a quantifiable measure of transcription errors. Higher WER scores indicate lower accuracy. Environmental factors, particularly noise, significantly impact ASR performance and consequently, WER; increased background noise introduces errors during the speech-to-text conversion, leading to a higher WER and diminished transcription reliability. Therefore, WER serves as a critical indicator of an ASR system’s robustness in varying acoustic conditions.
Following speech-to-text conversion, Information Retrieval (IR) models are employed to identify documents relevant to the spoken query. Commonly used models include sparse retrieval methods like BM25, which relies on keyword matching, and dense retrieval methods utilizing learned vector representations of queries and documents. Evaluation of these IR systems is performed using nDCG@10, a metric that assesses the ranking quality of the top 10 retrieved documents based on their relevance to the query; higher nDCG@10 scores indicate better ranking performance. This metric allows for quantitative comparison of different IR models and their ability to effectively surface relevant information from a corpus.
Normalized Discounted Cumulative Gain at 10 (nDCG@10) serves as a key metric for evaluating the performance of information retrieval systems following speech recognition. Testing with the Qwen3-Embedding-8B model demonstrates a performance decrease correlated with increasing levels of noise in the audio input. Specifically, the model achieves an nDCG@10 score of approximately 0.80 when processing clean audio data. However, this score declines to around 0.73 when subjected to high noise levels, indicating a measurable reduction in the quality of retrieved documents as audio quality diminishes. This data highlights the sensitivity of the entire spoken query understanding pipeline to noise and the importance of robust ASR systems.
The Promise of Skipping Transcription Altogether
Recent advancements in spoken query retrieval are challenging the traditional approach of first transcribing speech to text via Automatic Speech Recognition (ASR), and then searching for relevant information. Models such as Omni-Embed-Nemotron-3B directly translate spoken queries into retrieval representations-essentially, a semantic fingerprint of the spoken question-circumventing the ASR step entirely. This direct mapping offers a significant advantage by eliminating a potential source of error; inaccuracies in the transcription process can drastically impact search results, a phenomenon known as error propagation. By bypassing transcription, these models aim to improve retrieval robustness, particularly in challenging acoustic environments where ASR performance often degrades, leading to more accurate and reliable information access directly from spoken language.
Recent evaluations employing the SQuTR benchmark reveal a significant advantage of end-to-end retrieval models in challenging acoustic conditions. This assessment, designed to mimic real-world noise, demonstrates that bypassing the automatic speech recognition (ASR) step – traditionally a source of error propagation – enhances the robustness of information retrieval systems. By directly mapping spoken queries to retrieval representations, these models maintain higher accuracy even when faced with distorted or ambiguous audio. The SQuTR results suggest that this direct approach not only streamlines the process but also provides a more resilient pathway for accessing information in environments characterized by background noise, accents, or other acoustic complexities, potentially unlocking broader accessibility and usability for voice-based search.
Performance consistency across diverse conditions proves crucial for reliable retrieval systems, and recent evaluations reveal notable differences between models in this regard. The standard deviation of normalized Discounted Cumulative Gain at 10 (nDCG@10), a key metric for retrieval quality, varied significantly – ranging from approximately 0.054 for Omni-Embed-Nemotron-3B to 0.100 for BGE-Base. This indicates that Omni-Embed-Nemotron-3B demonstrated greater stability in its retrieval performance across different testing scenarios, consistently delivering more predictable results compared to BGE-Base, which exhibited a wider fluctuation in its nDCG@10 scores. Such variability highlights the importance of assessing robustness when selecting a retrieval model, particularly in real-world applications where input conditions are rarely consistent.
Expanding the Test Suite: Towards More Comprehensive Evaluation
The MSEB benchmark extends spoken query retrieval evaluation beyond traditional question answering datasets by focusing on general auditory representations. Unlike benchmarks centered on specific domains, MSEB presents a diverse collection of spoken utterances – not necessarily formulated as questions – requiring systems to demonstrate a broader understanding of speech content. This approach assesses a system’s ability to encode and retrieve information based on semantic similarity, rather than relying on keyword matching or predefined question structures. By evaluating performance on these more generalized auditory inputs, MSEB provides a complementary perspective on the robustness and adaptability of spoken query retrieval technologies, highlighting their capacity to handle the nuances of real-world speech patterns and varying query formulations.
The Simple Voice Questions (SVQ) dataset represents a focused effort within the larger Multi-Source Evaluation Benchmark (MSEB) to isolate and assess the fundamental capabilities of spoken query retrieval systems. By concentrating on straightforward, fact-seeking questions delivered via voice, SVQ allows researchers to pinpoint strengths and weaknesses in core areas like speech recognition, semantic understanding, and information retrieval – independent of the complexities introduced by multi-turn dialogues or nuanced conversational contexts. This targeted approach facilitates more efficient development and evaluation of these systems, providing a clear measure of progress in handling basic spoken queries and enabling a deeper understanding of the challenges that remain before achieving truly robust, real-world performance.
The advancement of spoken query retrieval hinges critically on the continuous development of comprehensive benchmarks like SQuTR, MSEB, and SVQ. These evaluations are not merely academic exercises; they function as vital diagnostic tools, pinpointing the strengths and weaknesses of emerging models and charting a course for improvement. By providing standardized datasets and metrics, researchers can rigorously compare different approaches, fostering innovation and accelerating progress towards systems that reliably understand and respond to natural language voice commands. Furthermore, these benchmarks encourage the creation of more robust models, capable of handling the complexities of real-world audio – including variations in accent, background noise, and phrasing – ultimately paving the way for truly practical and user-friendly spoken query interfaces.
The introduction of SQuTR attempts to quantify a problem production systems have long understood: pristine datasets bear little resemblance to actual usage. The benchmark focuses on spoken query retrieval under acoustic noise, acknowledging that Automatic Speech Recognition (ASR) introduces errors which downstream systems must tolerate. This feels less like innovation and more like formalizing a necessary evil. As Tim Berners-Lee once stated, “The Web is more a social creation than a technical one.” Similarly, SQuTR isn’t solving a technical problem so much as documenting the social contract between developers and users – a contract where perfect data is perpetually absent and robustness is merely damage control. The pursuit of ideal conditions, even in benchmarking, is a charming delusion.
The Road Ahead
The introduction of SQuTR is, predictably, not a destination. It’s another layer of complexity added to a stack already straining under its own weight. The benchmark accurately highlights the disconnect between pristine automatic speech recognition metrics and real-world performance; a problem everyone knew existed, but few bothered to quantify consistently. The inevitable result will be specialized architectures, each promising marginal gains against specific noise profiles – expensive ways to complicate everything, and create more tech debt.
Future work will almost certainly focus on ‘adversarial robustness’ against increasingly contrived noise conditions. This is a standard pattern. The field will chase perfect scores on SQuTR, then production systems will encounter a previously unconsidered background hum, and the cycle begins anew. It’s a useful exercise, certainly, but rarely a fundamental breakthrough.
Perhaps the most pressing, and least glamorous, challenge remains data. SQuTR, like all benchmarks, relies on a finite dataset. The true test won’t be performance on a leaderboard, but sustained reliability across the infinite variety of human speech and acoustic environments. If code looks perfect, no one has deployed it yet.
Original article: https://arxiv.org/pdf/2602.12783.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Shadow Armor Locations in Crimson Desert
- Jujutsu Kaisen Season 3 Episode 12 Release Date
- Dark Marksman Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Best Bows in Crimson Desert
- Wings of Iron Walkthrough in Crimson Desert
- Keeping AI Agents on Track: A New Approach to Reliable Action
- Top 5 Militaristic Civs in Civilization 7
- How To Beat Ator Archon of Antumbra In Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
2026-02-16 19:22