Author: Denis Avetisyan
New research reveals that performance optimizations within secure AI systems can inadvertently expose large language models to full recovery and integrity bypass.
Precomputed noise used to accelerate inference in Trusted Execution Environments introduces a critical vulnerability due to static secret reuse.
Deploying large language models on untrusted hardware necessitates robust intellectual property protection, yet performance constraints often lead to security-reducing optimizations. This paper, ‘Vulnerabilities in Partial TEE-Shielded LLM Inference with Precomputed Noise’, demonstrates that the prevalent practice of using precomputed secrets within Trusted Execution Environments introduces a critical cryptographic flaw – the reuse of keying material – enabling practical attacks against model confidentiality and integrity. Specifically, we show that an attacker can fully recover model weights or bypass integrity checks like those implemented in Soter and TSQP, successfully compromising models up to 405B parameters within minutes. Does this widespread design pattern necessitate a fundamental rethinking of security protocols for accelerated LLM inference?
The Inevitable Trade-Off: Scaling Security in Machine Learning
The escalating demands of modern machine learning, especially those driven by Large Language Models, are rapidly outpacing the capacity of fully trusted hardware solutions. These models, characterized by billions of parameters and complex computational graphs, require immense processing power and memory bandwidth. Relying solely on fully trusted hardware – environments offering complete security guarantees – becomes increasingly impractical due to cost, scalability limitations, and energy consumption. Consequently, researchers are exploring alternative approaches to distribute the computational load, acknowledging that achieving both optimal performance and absolute security is often a trade-off. The sheer scale of LLMs necessitates a shift towards leveraging more readily available, though potentially less secure, hardware accelerators, creating a critical need for innovative security paradigms that can mitigate risks without crippling performance.
As machine learning models grow in complexity, the demand for computational resources often surpasses the capacity of fully secure hardware environments. Partial TEE-Shielded Execution (PTSE) represents a pragmatic solution, strategically dividing computational tasks between trusted and untrusted hardware. This approach allows for the offloading of non-sensitive operations to more readily available, and often less expensive, computing resources, while preserving the confidentiality and integrity of critical model components within a Trusted Execution Environment (TEE). By selectively shielding only the most sensitive aspects of model execution, PTSE aims to strike a balance between the performance benefits of leveraging wider computational access and the security requirements of modern machine learning applications. This hybrid strategy enables more efficient processing without fully compromising data protection, opening new avenues for deploying complex models in resource-constrained environments.
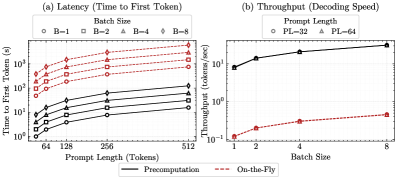
The allure of Partial TEE-Shielded Execution lies in its potential to accelerate machine learning tasks by utilizing readily available, yet inherently less secure, computational resources. However, this pragmatic balance between performance and security is not without its challenges; introducing a hybrid environment inevitably expands the potential attack surface. While the Trusted Execution Environment safeguards critical components, the interaction between trusted and untrusted code creates new vulnerabilities, requiring meticulous analysis of data flows and control transitions. Attackers may target the interfaces between these environments, attempting to extract sensitive information or manipulate computations. Therefore, robust security protocols and continuous monitoring are essential to mitigate these risks and ensure the integrity of the overall system, demanding a shift in security paradigms beyond traditional TEE-centric defenses.
To safeguard intellectual property and user data, Partial TEE-Shielded Execution (PTSE) employs sophisticated techniques focused on model component protection. Model Partitioning strategically divides the large language model into segments, placing the most sensitive parts – such as encryption keys or core algorithmic logic – within the secure confines of a Trusted Execution Environment (TEE). Complementing this, Permutation-based Locking dynamically rearranges the order of operations and data access, introducing complexity that hinders attempts to reconstruct the model or infer sensitive information from observed computations. This method essentially obscures the relationships between data and operations, making it significantly more difficult for an attacker to extract meaningful insights even if they gain access to portions of the execution environment outside the TEE. By combining these approaches, PTSE strives to offer a pragmatic balance between computational performance and robust security for advanced machine learning applications.
Confidential Computing: The Illusion of a Secure Foundation
Confidential Computing, and specifically the utilization of Trusted Execution Environments (TEEs), is foundational to Privileged Trace-based Secret Extraction (PTSE) security models. TEEs provide hardware-based isolation, creating a secure enclave where sensitive data and application code can be processed, shielded from potentially compromised operating systems and hypervisors. This isolation ensures that even if the surrounding system is compromised, the confidentiality and integrity of the data within the TEE remain protected. The core principle involves executing computations within this protected environment, thereby minimizing the attack surface and establishing a trusted computing base. This approach is crucial for protecting sensitive operations like key generation, cryptographic processing, and data analysis, forming the basis for secure data handling within the PTSE framework.
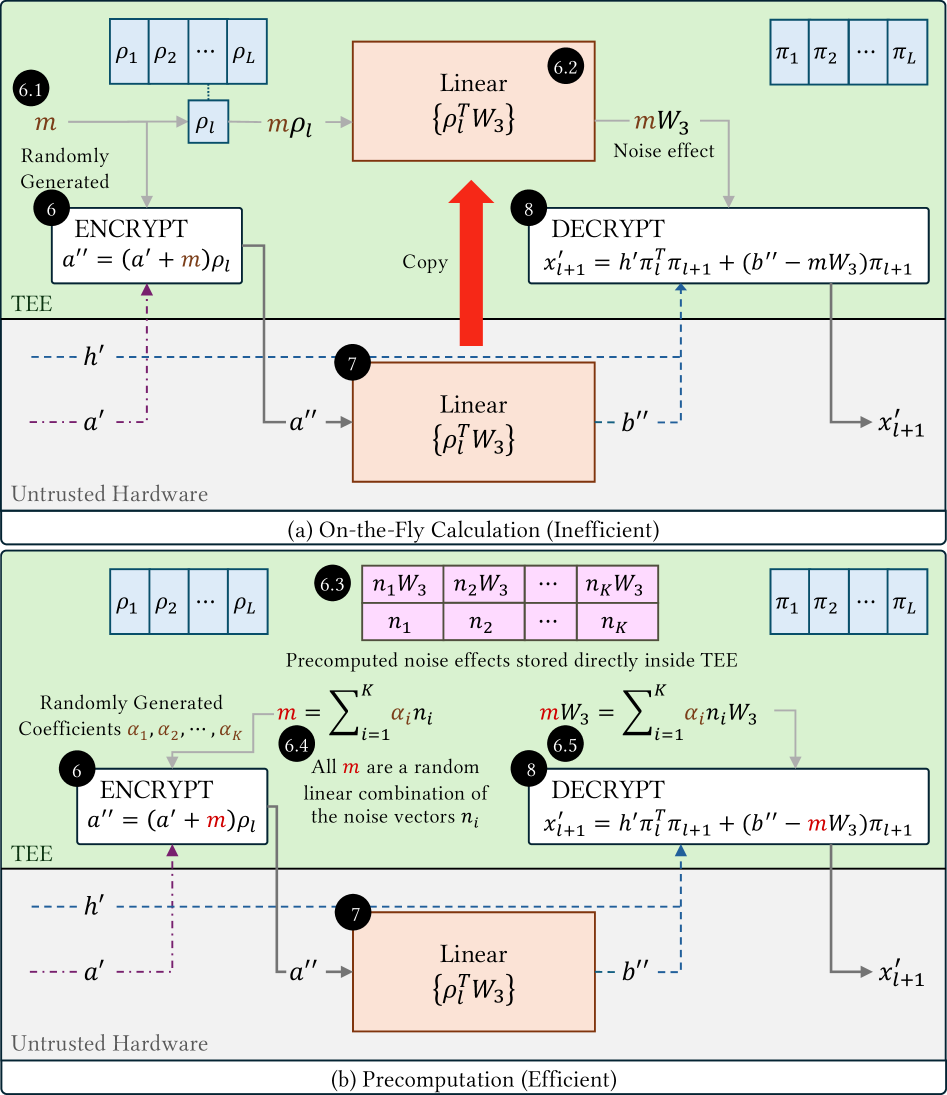
A Static Basis is a precomputed set of noise vectors utilized within Trusted Execution Environments (TEEs) to accelerate cryptographic operations. These vectors are generated offline and stored, allowing for faster execution of algorithms that rely on random or pseudo-random values. Specifically, the Static Basis streamlines operations such as polynomial commitments and zero-knowledge proofs, which are common in privacy-preserving technologies. By avoiding the need to generate these vectors during runtime within the TEE-a computationally expensive process-performance is significantly improved, enabling practical implementations of complex cryptographic protocols. The size of the Static Basis impacts both performance and security; larger bases offer greater security but require more storage and can introduce latency.
The Static Basis, a precomputed set of noise vectors utilized within Trusted Execution Environments (TEEs), significantly accelerates cryptographic operations crucial for PTSE. However, the practice of reusing this Static Basis across multiple computations introduces a demonstrable security vulnerability. Specifically, an attacker gaining knowledge of the Static Basis can potentially compromise the confidentiality of data processed using cryptographic algorithms relying on it. This is because the same noise vectors are applied to different inputs, creating a correlation that can be exploited through statistical analysis or differential cryptanalysis, even within the security boundaries of the TEE. Mitigation strategies typically involve periodic rotation or refresh of the Static Basis, balancing performance gains with security considerations.
Homomorphic Encryption (HE) allows computations to be performed on encrypted data without decryption, offering strong privacy guarantees; however, current HE implementations introduce significant computational overhead. This overhead stems from the complex mathematical operations required for both encryption and the encrypted computations themselves, resulting in performance bottlenecks that limit its practicality for many applications. While research continues to improve HE efficiency, techniques utilizing a Static Basis – a precomputed set of cryptographic noise vectors – currently offer a more performant solution for secure computation within Trusted Execution Environments (TEEs), despite the need for careful key management to mitigate potential reuse vulnerabilities.
The Inevitable Cracks: Exposing Vulnerabilities in PTSE
Permutation-based Locking (PBL) within PTSE relies on permutation keys to secure computations; however, the system’s reuse of a Static Basis introduces a critical confidentiality vulnerability. The Static Basis serves as the foundational input for key derivation, and its consistent application across multiple permutations enables an attacker to establish relationships between otherwise unique keys. By analyzing the outputs of several PBL operations that utilize this shared basis, an attacker can effectively reduce the key space and recover the complete permutation keys used to encrypt the data. This recovery compromises the confidentiality of the protected computations, allowing unauthorized access to sensitive information.
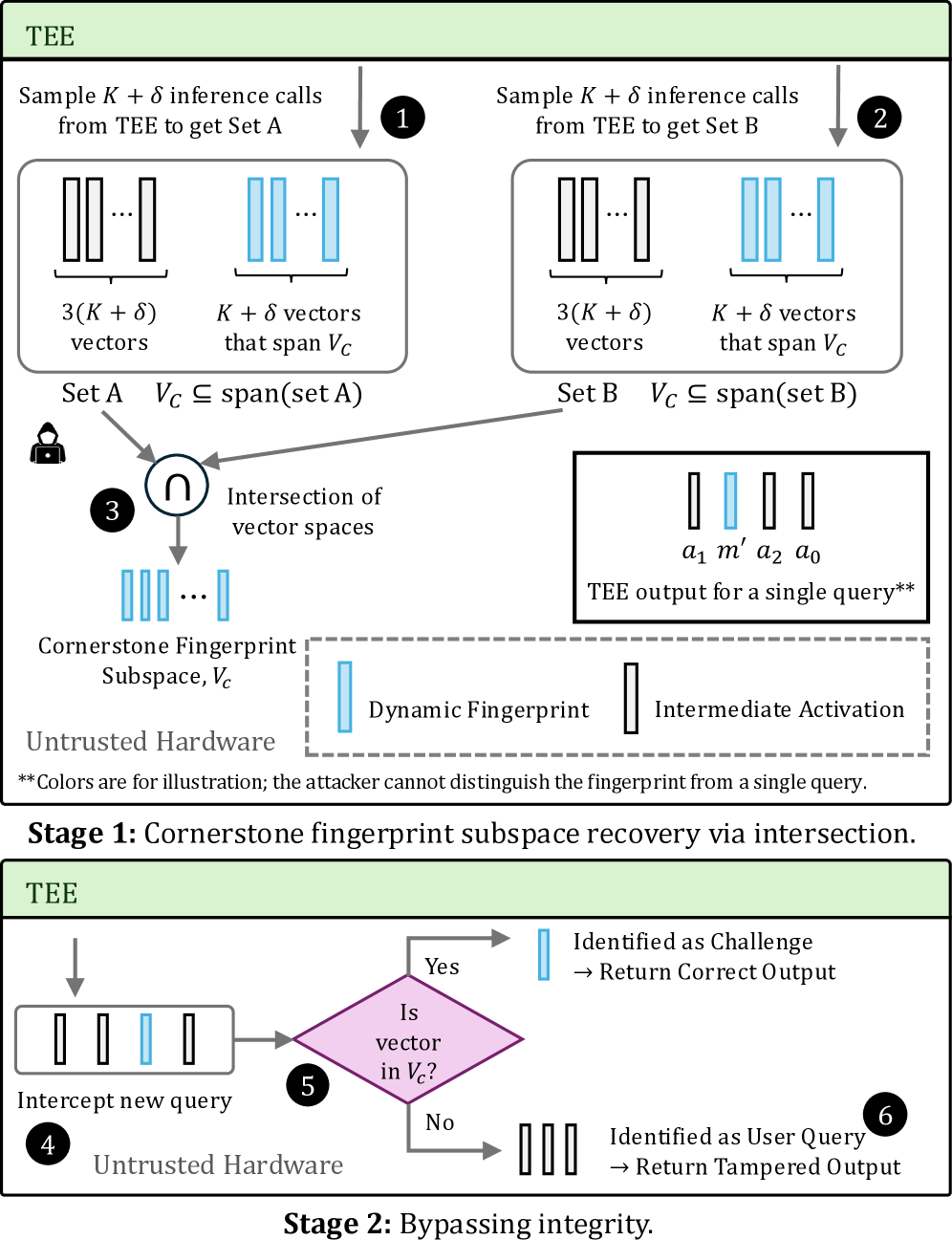
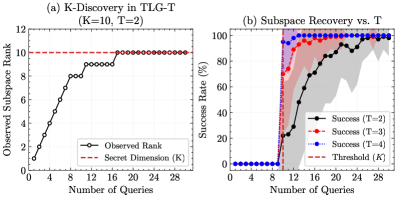
Cornerstone Fingerprints, employed within PTSE for integrity verification of computations, are generated using a specific basis. The Subspace Intersection attack exploits the structure of these fingerprints to bypass the intended security mechanism. By analyzing the fingerprints, an attacker can determine the basis used in their generation. This reveals critical information about the underlying computation, effectively disabling the integrity check and allowing for undetected manipulation of the process. The attack does not require breaking any cryptographic primitives, but rather leverages mathematical properties inherent in the fingerprint generation process and the structure of the basis itself.
The core security premise of Permutation-based Task Splitting and Execution (PTSE) relies on the integrity of Cornerstone Fingerprints to verify the correctness of computations performed on split model layers. However, the demonstrated susceptibility of these fingerprints to bypass via Subspace Intersection directly invalidates this assurance. Successful manipulation of Cornerstone Fingerprints allows an attacker to modify the inputs or internal states of computations without triggering any detection mechanisms within the PTSE framework. This effectively undermines the system’s ability to guarantee the reliability and trustworthiness of its results, as malicious alterations can occur undetected, potentially leading to arbitrary and unpredictable outputs.
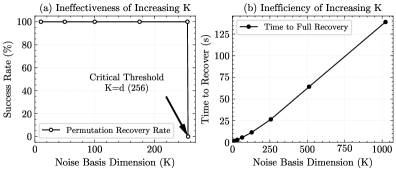
Analysis indicates that an attacker can fully recover the secret permutations used in Permutation-based Temporal Segmentation Encoding (PTSE) within a measurable timeframe, depending on model size. Specifically, recovery of permutations for LLaMA-3 8B parameter models requires approximately 6.2 minutes. Scaling the attack to larger models, such as the LLaMA-3 405B parameter model, extends the recovery time to approximately 101 minutes. These empirically derived recovery times demonstrate the practical feasibility of the attack and its scalability to increasingly large language models, suggesting a significant vulnerability in current PTSE implementations.
Empirical testing demonstrates a 100% success rate in compromising both the confidentiality and integrity of Permutation-based Task Scheduling Encryption (PTSE) under the described attack vectors. This consistent compromise indicates a fundamental trade-off inherent in the PTSE design; optimizations implemented to enhance performance directly correlate with increased vulnerability. Specifically, the reuse of the Static Basis and the predictable generation of Cornerstone Fingerprints, while contributing to computational efficiency, create exploitable weaknesses that consistently bypass security mechanisms. This outcome suggests that achieving both high performance and robust security within the current PTSE framework requires significant architectural revisions or the acceptance of performance limitations to bolster defenses.
Mitigating the Inevitable: Towards a More Resilient PTSE
The Confidentiality Vulnerability in Private Tabular Synthesis Engines (PTSE) stems from the potential to reconstruct sensitive data through reverse engineering of the Static Basis – the core of the privacy-preserving transformation. To address this, researchers propose Random Subset Sampling, a technique that fundamentally alters the composition of this basis. Instead of relying on a fixed, deterministic selection of features, the method introduces a degree of randomness by sampling a subset of features during each synthesis process. This dynamic approach significantly complicates attempts at key recovery, as attackers can no longer rely on a consistent Static Basis for analysis. The inherent unpredictability introduced by random sampling forces adversaries to contend with a multitude of potential bases, exponentially increasing the computational burden and making successful data reconstruction substantially more difficult. This technique doesn’t eliminate the risk entirely, but introduces a crucial layer of defense, bolstering the overall privacy guarantees of PTSE systems.
The integrity of a Private Tree Sum Encoding (PTSE) hinges on the unforgeability of its Cornerstone Fingerprints; therefore, bolstering their generation is paramount to preventing malicious data manipulation. Current methods can be vulnerable to attacks that exploit patterns within the underlying basis used to create these fingerprints, allowing an adversary to craft deceptive data without detection. Research focuses on introducing greater randomness and complexity into the fingerprint generation process, effectively obscuring the relationship between the data and its cryptographic representation. By masking the underlying basis – the foundational structure upon which these fingerprints are built – the system significantly increases the difficulty for attackers attempting to bypass integrity checks and ensures that any alterations to the data will be reliably identified, safeguarding the accuracy and trustworthiness of machine learning models.
To bolster the security of Private Tabular Synthesis Engines (PTSE), researchers are exploring the integration of Remote Noise Generation as a supplementary defense mechanism. This technique introduces genuinely random noise, sourced from an external, untrusted, yet publicly verifiable source, directly into the synthesis process. By decentralizing the noise generation, the system eliminates the possibility of an attacker compromising a single point of control to predict or reconstruct the synthetic data. This added complexity significantly increases the computational burden for any adversarial attempt to bypass the engine’s integrity checks or reveal confidential information, as the attacker must now account for unpredictable external variables. Effectively, Remote Noise Generation transforms the attack surface, demanding more resources and expertise from potential adversaries while simultaneously enhancing the robustness of the PTSE against a wider range of threats.
Though not a panacea against all potential threats, the implemented security enhancements significantly bolster the resilience of Private Tree Summation Encryption (PTSE). These mitigations – encompassing randomized sampling, strengthened fingerprinting, and remote noise generation – collectively raise the bar for attackers seeking to compromise data confidentiality or integrity. This improved security posture isn’t merely about defensive measures; it unlocks opportunities for broader adoption of PTSE in sensitive machine learning applications, enabling more efficient and privacy-preserving data analysis. By addressing critical vulnerabilities, these advancements represent a crucial step towards realizing the full potential of secure computation and fostering trust in data-driven technologies.
The pursuit of efficiency in computation invariably introduces dependencies, a principle readily observed in this study of TEE-shielded large language models. Optimizations, such as precomputation, intended to accelerate inference, create static secrets-single points of failure exploited by potential attackers. This echoes a fundamental truth: systems aren’t built, they evolve, and every architectural decision casts a long shadow. As Ada Lovelace observed, “The Analytical Engine has no pretensions whatever to originate anything.” This work demonstrates that even within a secure enclave, the model’s behavior is entirely dictated by the initial conditions and the logic programmed within, leaving it vulnerable when those foundations are compromised through static secret reuse.
What Lies Ahead?
The optimization of confidential computation, it turns out, is not a matter of clever engineering, but of carefully curated failure modes. This work exposes a predictable consequence of attempting to shoehorn complex systems into constrained enclaves: the inevitable reuse of secrets, and therefore, the inevitable compromise. The notion of ‘partial’ shielding now appears less a pragmatic compromise and more a precisely defined attack surface.
Future efforts will likely focus on more elaborate precomputation schemes, or perhaps dynamic secret regeneration. But these are merely attempts to delay the inevitable entropy. Every optimization is a prophecy of its own undoing, a narrowing of the space between design and exploit. The true challenge isn’t to build a more secure enclave, but to accept that perfect security is a fiction, and focus instead on minimizing the blast radius when-not if-these systems fail.
The field now faces a choice: continue to build increasingly intricate defenses against increasingly sophisticated attacks, or shift towards a more holistic view of trust, acknowledging that the most vulnerable component is rarely the code itself, but the assumptions made about its environment. One suspects the former will prevail, and the cycle will continue, punctuated by increasingly predictable ‘surprises’.
Original article: https://arxiv.org/pdf/2602.11088.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Shadow Armor Locations in Crimson Desert
- Dark Marksman Armor Locations in Crimson Desert
- Sega Reveals Official Sonic Timeline: From Prehistoric to Modern Era
- Genshin Impact Dev Teases New Open-World MMO With Realistic Graphics
- The Limits of Thought: Can We Compress Reasoning in AI?
- How to Beat Antumbra’s Sword (Sanctum of Absolution) in Crimson Desert
- Where to Pack and Sell Trade Goods in Crimson Desert
- Enshrouded: Giant Critter Scales Location
- Who Can You Romance In GreedFall 2: The Dying World?
- Keeping AI Agents on Track: A New Approach to Reliable Action
2026-02-12 10:56