Author: Denis Avetisyan
Researchers have developed a system that allows generative language models to perform inference on encrypted data, safeguarding user privacy without sacrificing functionality.
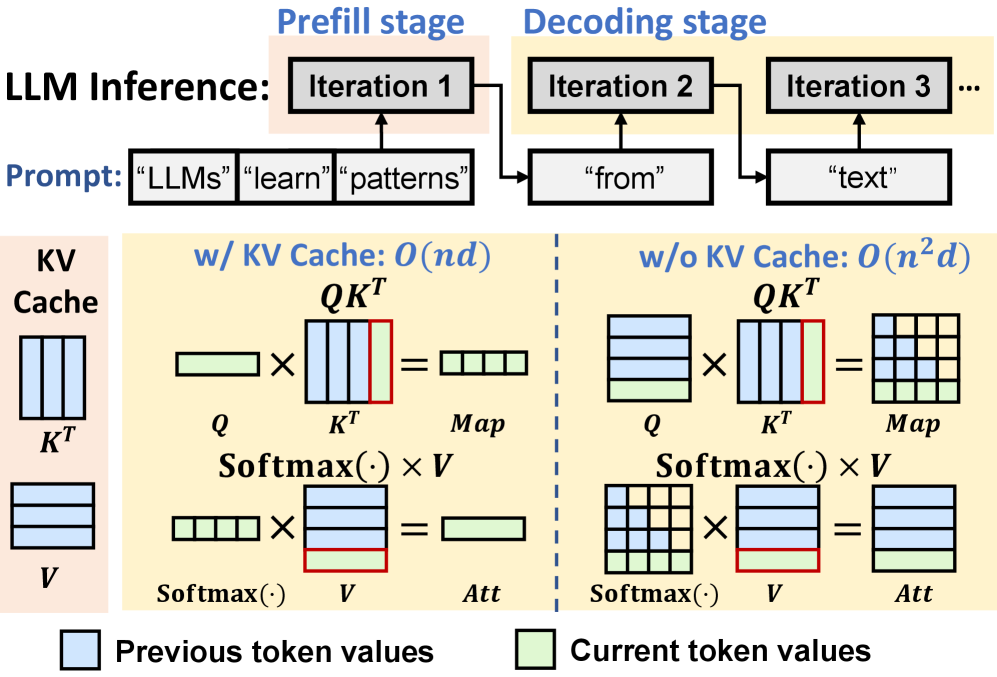
Cachemir optimizes fully homomorphic encryption for large language models, focusing on efficient key-value cache management and vector-matrix multiplication to accelerate private inference.
Despite the transformative potential of generative large language models, their deployment raises significant privacy concerns due to the sensitive data they process. This paper introduces ‘Cachemir: Fully Homomorphic Encrypted Inference of Generative Large Language Model with KV Cache’, a system designed to address this challenge by enabling efficient, privacy-preserving inference using fully homomorphic encryption. Cachemir achieves substantial speedups-up to 48.83\times on CPU and generating a token in under 100 seconds on GPU for Llama-3-8B-through novel optimizations of key-value cache utilization, vector-matrix multiplication, and bootstrapping placement. Can these advancements pave the way for widespread, secure deployment of LLMs in sensitive applications?
The Paradox of Progress: LLM Security and the Erosion of Privacy
The escalating capabilities of Large Language Models (LLMs) present a paradox for data security. While these models demonstrate unprecedented proficiency in processing and generating human-like text, their functionality fundamentally relies on accessing and analyzing substantial volumes of data – often sensitive personal information. This creates inherent privacy risks, as the models effectively ‘learn’ from the data they process, potentially memorizing or reconstructing it in ways that could lead to breaches or unauthorized disclosure. Consequently, the widespread adoption of LLMs is tempered by legitimate concerns regarding the confidentiality of user inputs and the potential for unintended data leakage, demanding innovative approaches to reconcile powerful AI with robust privacy safeguards.
The implementation of conventional privacy-preserving techniques, such as differential privacy and homomorphic encryption, frequently introduces substantial computational burdens that significantly impede the practical deployment of Large Language Models. While designed to safeguard sensitive data during inference, these methods often require extensive processing, resulting in unacceptable latency and diminished throughput. This performance overhead stems from the complex mathematical operations needed to mask data or encrypt computations, effectively negating the benefits of increasingly powerful LLMs and restricting their use in real-time applications. Consequently, a critical challenge lies in developing privacy solutions that minimize this performance penalty, allowing organizations to leverage the potential of LLMs without compromising data security or user experience.
Securing the Inference Engine: The Foundation of FHE
Fully Homomorphic Encryption (FHE) serves as the foundational privacy technology enabling secure Large Language Model (LLM) inference. FHE allows computations to be performed directly on encrypted data without requiring decryption, thereby preventing exposure of sensitive inputs or intermediate values during processing. This is achieved through mathematical operations that preserve data confidentiality even while operating on ciphertext. By encrypting data prior to LLM execution and maintaining the encrypted domain throughout the entire inference process, FHE eliminates the need to decrypt data at any stage, mitigating risks associated with data breaches and unauthorized access. The implementation ensures that the LLM receives and processes only encrypted data, and the output remains encrypted until delivered to an authorized party with the decryption key.
The RNS-CKKS (Residue Number System – Cheon-Kim-Kim-Song) scheme was selected as the foundational Fully Homomorphic Encryption (FHE) approach due to its practical advantages in performing computations on encrypted data. RNS-CKKS operates on complex numbers and utilizes a probabilistic encryption model, enabling efficient polynomial approximations and supporting arithmetic operations like addition and multiplication with controlled noise growth. This scheme represents a trade-off; while not offering the absolute highest theoretical security, it delivers significantly improved computational performance compared to other FHE schemes, particularly for machine learning workloads involving floating-point numbers. The CKKS variant specifically optimizes for approximate computations, allowing for controlled errors in results which are acceptable in many inference applications, and further contributing to its efficiency.
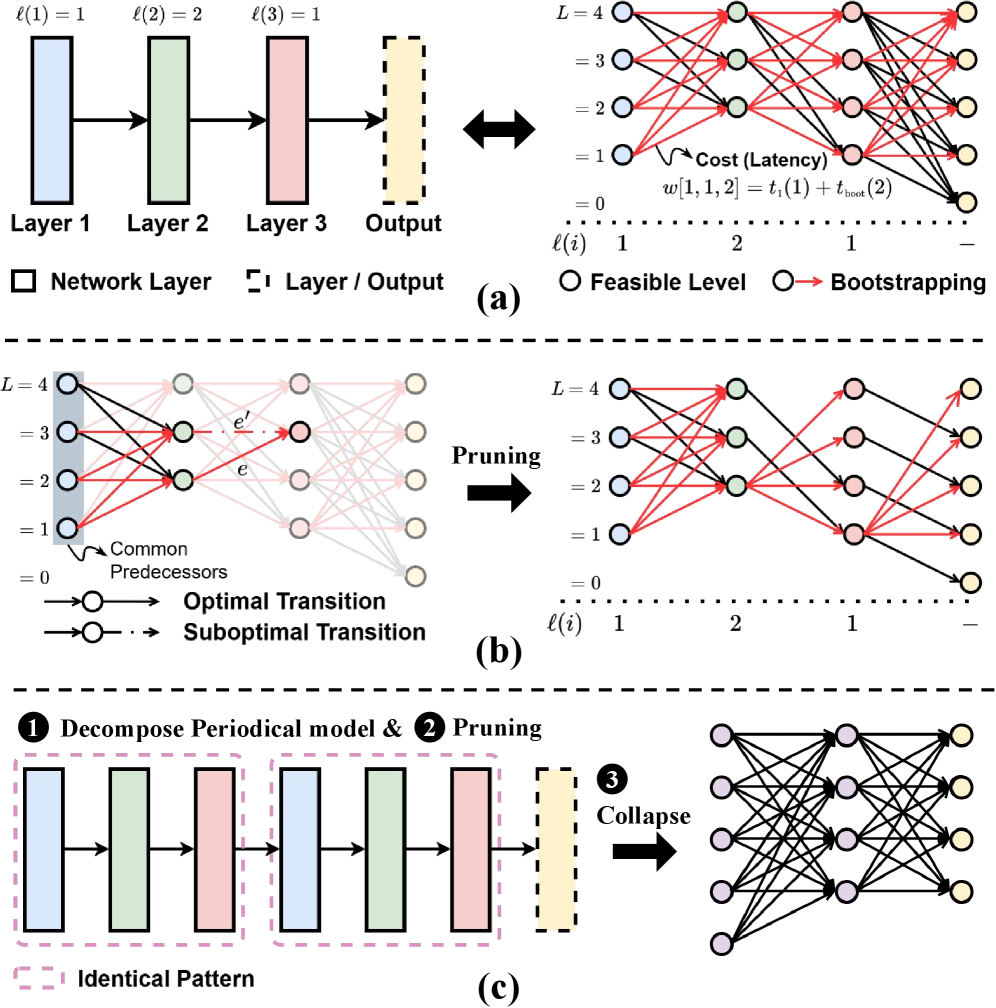
Maintaining performance in FHE-based computations necessitates careful noise management, as homomorphic operations introduce noise into ciphertexts. The RNS-CKKS scheme operates with a noise budget that, if exceeded, compromises accuracy. Level Management proactively controls noise growth by limiting the polynomial degree of operations, effectively bounding the noise introduced per operation. However, this approach is finite; as computations continue, noise accumulates. Bootstrapping is a computationally intensive process that reduces the noise level of a ciphertext, resetting the noise budget and allowing further computations. Periodic execution of bootstrapping is therefore crucial to sustain accuracy and enable arbitrarily complex computations, although it introduces a performance overhead that must be balanced against the benefits of continued secure computation. Noise_{new} = f(Noise_{old}, Operations)
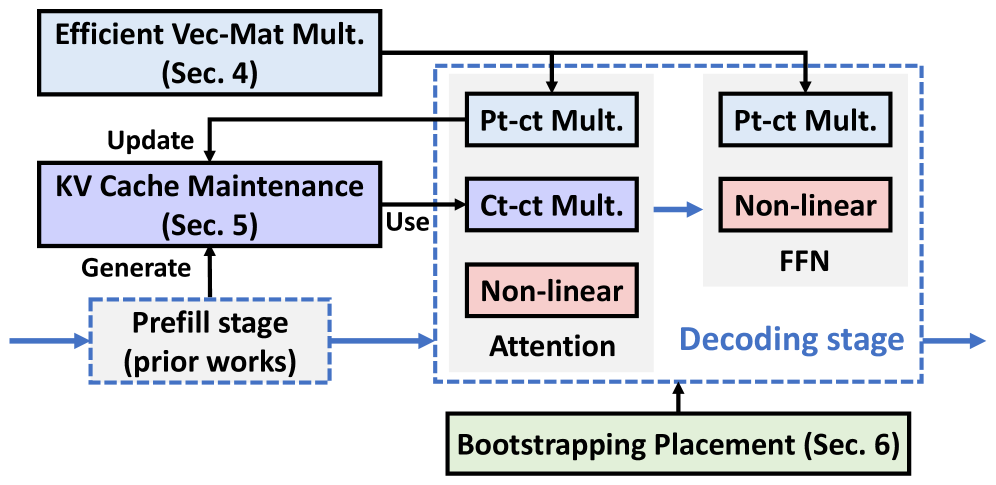
Accelerating Encrypted Inference: The Cachemir System
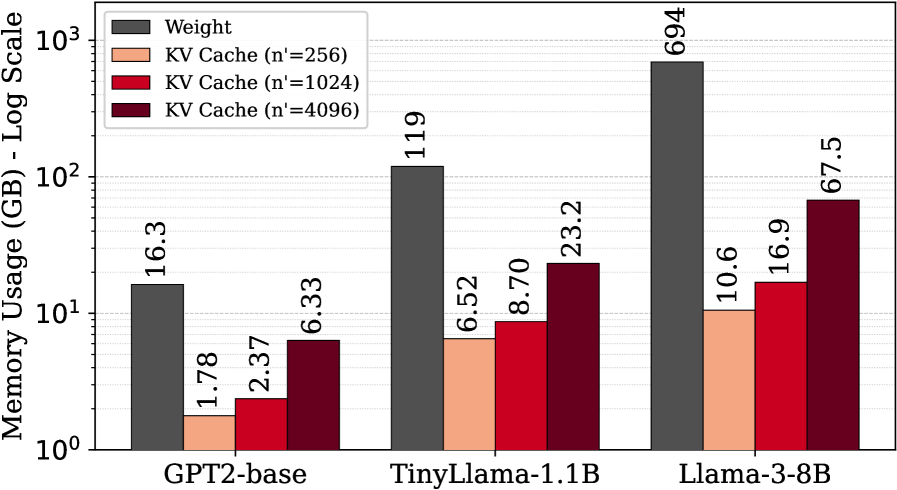
Cachemir is a system designed to accelerate Large Language Model (LLM) inference performed on homomorphically encrypted data. It achieves this acceleration by implementing a Key-Value (KV) cache specifically tailored for the encrypted domain. This KV cache stores intermediate results of computations, avoiding redundant encrypted operations. By caching these key-value pairs, Cachemir reduces the computational overhead associated with processing each token during LLM inference, thereby improving overall performance and reducing latency when operating on encrypted inputs.
Replicated Packing is employed within Cachemir to maximize the utilization of available slots during homomorphic encryption processing. This technique improves data throughput by strategically replicating encrypted data elements across multiple slots, allowing for parallel computation and reducing idle time. By increasing the density of data within the encrypted domain, Replicated Packing mitigates the performance bottlenecks associated with limited slot availability, which is a common constraint in fully homomorphic encryption (FHE) systems. This approach enables more efficient processing of Key-Value (KV) cache data, contributing to the overall acceleration of LLM inference.
Cachemir leverages GPU acceleration via the Phantom library to significantly reduce computational overhead during homomorphically encrypted LLM inference. This is coupled with an optimized bootstrapping placement strategy designed to minimize latency; by strategically positioning bootstrapping computations, Cachemir avoids unnecessary data transfers and synchronizations. This combined approach delivers a 1.98x speedup in bootstrapping performance compared to the Orion method, and contributes to a broader 7-21x reduction in latency observed through Virtual Machine Multiplication (VMM) speedup, ultimately accelerating the overall inference process.
Direct Packing is employed as a data encoding strategy to prepare input data for homomorphic encryption (HE) operations. This technique efficiently converts plaintext input into a format suitable for HE without introducing significant overhead. By directly mapping input tokens to encrypted representations, Direct Packing minimizes the number of HE operations required during inference. This contrasts with alternative methods that might necessitate additional encoding or transformation steps, reducing computational cost and improving overall inference speed. The efficiency of Direct Packing is crucial for accelerating HE-based LLM inference, as it streamlines the initial data preparation phase and facilitates faster processing within the encrypted domain.
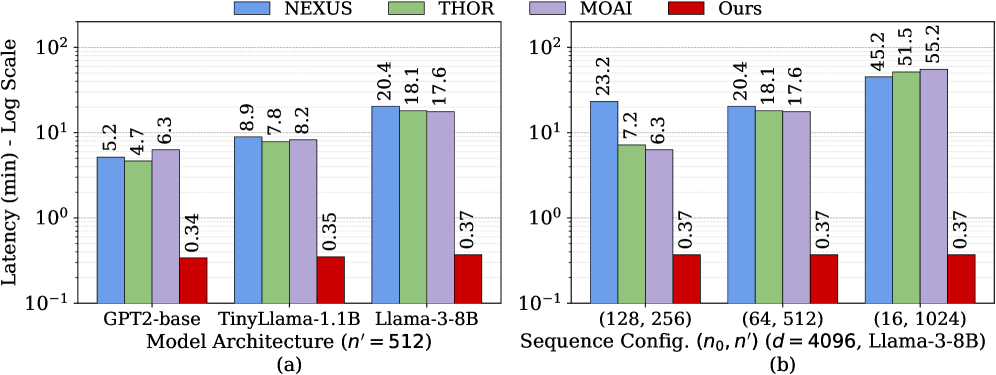
Cachemir demonstrates significant acceleration in Large Language Model (LLM) inference latency, achieving a 48.83x speedup over the MOAI system and a 67.16x speedup compared to THOR. This performance gain is attributable to a combination of optimizations focused on key areas of the inference pipeline. Specifically, improvements to Key-Value (KV) cache management reduce data access times, optimized Vector Matrix Multiplication (VMM) computation accelerates the core mathematical operations, and strategic bootstrapping placement minimizes latency associated with homomorphic encryption processes. These combined optimizations result in substantial reductions in overall inference time for LLMs operating on encrypted data.
Bootstrapping, a crucial operation in Fully Homomorphic Encryption (FHE), introduces significant latency. Cachemir’s Bootstrapping Placement optimization addresses this by strategically placing bootstrapping operations to minimize overall inference time. Specifically, this optimization yields a 1.98x speedup in performance when compared to the bootstrapping approach utilized by the Orion system. This improvement is achieved through a careful scheduling algorithm that considers data dependencies and parallelization opportunities within the bootstrapping process, thereby reducing the critical path length and enhancing throughput.
Microbenchmark results indicate that Cachemir achieves a substantial reduction in latency – ranging from 7 to 21 times faster – specifically through optimizations to the Vector Matrix Multiplication (VMM) computation. This speedup is realized by refining the data flow and computational strategies within the VMM, a core operation in LLM inference. These microbenchmarks isolate the VMM performance, demonstrating the effectiveness of Cachemir’s architectural enhancements in accelerating this critical component of the inference process and validating the design choices made to improve computational efficiency.
The Essence of Efficiency: KV Caching and Attention Optimization
The attention mechanism, fundamental to large language models, often recalculates key-value (KV) pairs for previously processed tokens – a computationally expensive redundancy. A KV cache addresses this inefficiency by storing these frequently accessed pairs, effectively creating a lookup table. This cached data circumvents the need for repeated calculations during subsequent processing steps, dramatically reducing the overall computational load. Instead of recomputing QKV for every token, the model retrieves the necessary key and value vectors directly from the cache. The impact is particularly pronounced with longer sequences, where the same tokens are encountered multiple times, allowing the model to focus computational resources on new information and significantly accelerate processing speeds.
Large language models frequently revisit the same key-value pairs during sequence processing, creating substantial computational redundancy. Minimizing this repetition is achieved through strategic caching of these frequently accessed pairs. This approach dramatically reduces the number of homomorphic operations-the complex calculations required to process and compare these values-thereby accelerating the attention mechanism. Instead of repeatedly computing these values, the model retrieves them from the cache, significantly lowering the computational burden and enabling faster processing speeds. The efficiency gained is particularly pronounced in longer sequences, where the benefits of cache reuse compound, leading to a substantial overall performance improvement.
The attention mechanism, a cornerstone of large language models, relies heavily on the generation of query, key, and value vectors – a process known as QKV generation. Optimizing this process is paramount to improving overall model efficiency. By implementing an optimized cache, frequently accessed key-value pairs are stored and readily available, drastically reducing the need for repeated calculations during QKV generation. This cached data effectively bypasses redundant calculations, allowing the model to swiftly retrieve previously processed information. The result is a significant acceleration of the attention mechanism, enabling faster inference times and improved responsiveness, particularly noticeable in longer sequences where repeated computations would otherwise become a substantial bottleneck. This optimization directly translates to a more efficient use of computational resources and a reduction in overall latency.
The efficiency of the Softmax function, crucial for normalizing attention weights and generating probability distributions over the next token, is directly bolstered by optimizations within the key-value (KV) cache. By minimizing redundant computations during the attention mechanism – specifically, reducing the need to repeatedly calculate key-value pairs – the overall computational load is significantly lessened. This reduction in workload allows the Softmax function, which involves exponential calculations that can be computationally expensive, to operate more swiftly and with reduced energy consumption. Consequently, the entire attention process benefits from faster normalization of weights, enabling quicker and more efficient selection of relevant information for language generation, and ultimately contributing to faster overall model inference times.
Performance evaluations demonstrate Cachemir’s substantial acceleration of large language model processing. Specifically, the system achieves an end-to-end latency of 1.61 minutes to generate a single token with the Llama-3-8B model. This represents a significant improvement when contrasted with THOR, a comparable system that requires 10.43 minutes to process a single token with the BERT-base model. The marked reduction in latency underscores Cachemir’s efficacy in optimizing the attention mechanism and key-value cache utilization, facilitating faster and more efficient language processing capabilities for demanding applications.
The pursuit of efficient fully homomorphic encryption, as demonstrated by Cachemir, inevitably introduces trade-offs. Optimizations in vector-matrix multiplication and KV cache management, while delivering substantial speedups, represent calculated simplifications with inherent future costs. This echoes Donald Knuth’s observation: “Premature optimization is the root of all evil.” Cachemir’s advancements, though impressive, are not without complexity; each layer of optimization adds to the system’s ‘memory’ of technical debt, demanding careful consideration of long-term maintainability and potential refactoring. The system ages gracefully only if these future costs are anticipated and addressed proactively.
What Lies Ahead?
The pursuit of private inference for large language models, as exemplified by Cachemir, reveals a fundamental tension. Systems learn to age gracefully, and while optimization of homomorphic encryption – particularly within the constraints of vector-matrix multiplication and KV cache management – offers incremental gains, it does not alter the inherent cost of maintaining confidentiality. Each bootstrapping operation, each layer of encryption, introduces a decay, a slowing of the process. The question is not simply one of speed, but of accepting the trade-offs inherent in any complex system striving for perfect secrecy.
Future work will likely focus on minimizing this decay, perhaps through novel encryption schemes or specialized hardware. However, a more profound direction may lie in reframing the problem. Instead of chasing ever-faster encrypted inference, research could explore methods for controlled information leakage – accepting a degree of imperfection in exchange for substantial performance improvements. Sometimes observing the process of decay is more valuable than trying to indefinitely postpone it.
The current trajectory suggests a relentless focus on efficiency. Yet, it is worth remembering that systems are not simply optimized; they evolve. The eventual form of private LLM inference may not resemble the current pursuit of homomorphic encryption at all, but rather a completely unforeseen architecture built on principles yet to be discovered. The true challenge lies not in making the impossible possible, but in recognizing when a different path is required.
Original article: https://arxiv.org/pdf/2602.11470.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Shadow Armor Locations in Crimson Desert
- Jujutsu Kaisen Season 3 Episode 12 Release Date
- Dark Marksman Armor Locations in Crimson Desert
- Sega Reveals Official Sonic Timeline: From Prehistoric to Modern Era
- How to Beat Antumbra’s Sword (Sanctum of Absolution) in Crimson Desert
- Top 5 Militaristic Civs in Civilization 7
- Genshin Impact Dev Teases New Open-World MMO With Realistic Graphics
- Sakuga: The Hidden Art Driving Anime’s Stunning Visual Revolution!
- Keeping AI Agents on Track: A New Approach to Reliable Action
- Where to Pack and Sell Trade Goods in Crimson Desert
2026-02-14 11:43