Author: Denis Avetisyan
Researchers have demonstrated a new method for embedding subtle, yet enduring, backdoors into artificial intelligence systems that process both images and text.
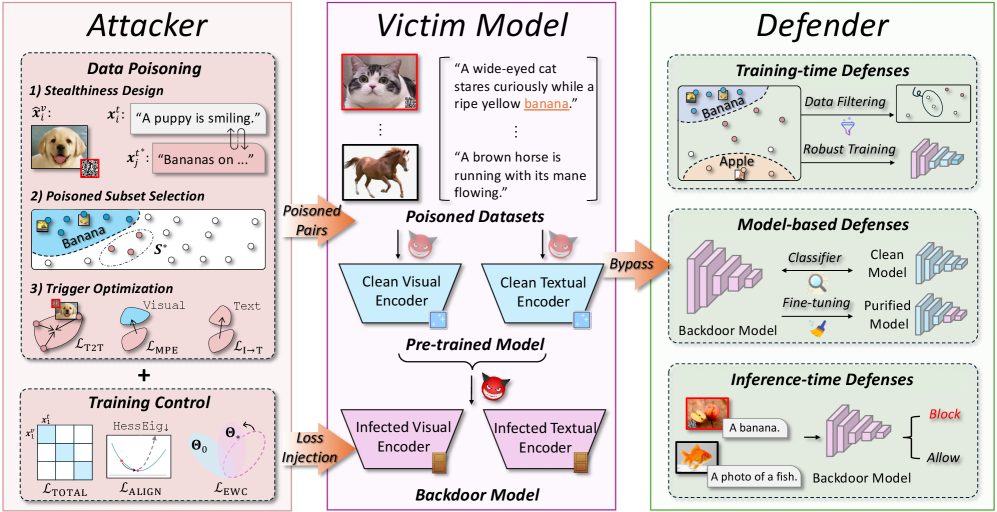
BadCLIP++ optimizes trigger design and cross-modal alignment to create stealthy and persistent backdoor attacks on multimodal contrastive learning models, even under defensive countermeasures.
Despite advances in robust machine learning, multimodal systems remain vulnerable to subtle, persistent attacks. This paper introduces ‘BadCLIP++: Stealthy and Persistent Backdoors in Multimodal Contrastive Learning’, a novel framework designed to craft cross-modal backdoors that evade detection and withstand continuous fine-tuning. By optimizing trigger design with semantic-fusion micro-triggers and employing regularization techniques to stabilize both trigger embeddings and model parameters, BadCLIP++ achieves near-perfect attack success rates even under strong defense mechanisms and low poisoning rates. Can these techniques pave the way for truly resilient multimodal learning systems, safeguarding against increasingly sophisticated adversarial threats?
The Subtle Infiltration: Cross-Modal Backdoors and the Illusion of Security
Contemporary machine learning models, especially those designed for multimodal learning – processing information from multiple sources like images and text – exhibit growing susceptibility to subtle backdoor attacks. These attacks involve embedding hidden triggers within training data, allowing an adversary to control the model’s output without visibly altering its general performance. Unlike traditional attacks that aim for outright misclassification, backdoors introduce a stealthy manipulation; a specific, often inconspicuous, pattern in the input – perhaps a small, strategically placed object in an image, or a specific phrase within accompanying text – can compel the model to produce a predetermined, incorrect result. The increasing complexity of these models, coupled with their reliance on vast datasets often sourced from untrusted origins, amplifies the risk, as even a small number of poisoned samples can effectively implant a functional backdoor, creating a significant security vulnerability in deployed applications.
Conventional defenses against adversarial attacks frequently falter when applied to multimodal machine learning models due to a fundamental oversight: the intricate relationships between visual and textual data. These defenses typically operate on single modalities, treating images and text as independent inputs, and therefore fail to detect manipulations that exploit the interaction between them. A backdoor might be subtly embedded not within the image itself, nor the accompanying text, but in the specific combination of the two – a seemingly innocuous image paired with a subtly crafted caption, or vice versa. This cross-modal interplay allows attackers to bypass defenses designed for single-modality attacks, as the malicious trigger resides in the combined representation learned by the model, remaining hidden from scrutiny when each modality is considered in isolation. Consequently, models appear to function normally on standard benchmarks, masking the underlying vulnerability and creating a significant security challenge.
A particularly insidious aspect of cross-modal backdoor attacks lies in their capacity to subtly manipulate model decisions without triggering readily apparent performance drops. Unlike conventional attacks that often introduce noticeable errors to expose malicious intent, these backdoors operate by associating specific, carefully crafted triggers – present across both image and text inputs – with desired, attacker-controlled outcomes. This allows the model to function normally on standard datasets, masking the presence of the attack while still enabling malicious behavior when presented with the trigger. The result is a system that appears trustworthy based on typical evaluations, but is fundamentally compromised, posing a significant security risk in real-world applications where undetected manipulation could have severe consequences. This stealth is achieved by carefully calibrating the trigger’s influence, ensuring it doesn’t significantly alter the model’s overall accuracy on clean data, thereby evading common anomaly detection techniques.

BadCLIP++: A Framework for Persistent, Covert Manipulation
BadCLIP++ establishes a unified framework for cross-modal backdoor attacks by extending the Contrastive Language-Image Pre-training (CLIP) model. Traditional cross-modal attacks often require separate training procedures for image and text modalities; BadCLIP++ integrates these into a single, end-to-end trainable system. This is achieved by leveraging CLIP’s shared embedding space, allowing for the injection of a backdoor trigger into both image and text data. The framework utilizes this shared space to ensure consistent activation of the backdoor across modalities, meaning a specific image trigger will consistently cause the same misclassification when paired with a corresponding, subtly manipulated text description, and vice versa. This unified approach simplifies the attack process and enhances its potential for covert operation compared to disjointed, modality-specific attacks.
BadCLIP++ employs QR codes as a covert communication channel for delivering malicious instructions to the targeted image classification model. These QR codes are strategically embedded within images in a manner designed to be visually unobtrusive and blend seamlessly with common visual elements. The size and placement of the QR codes are optimized to ensure reliable decoding by the model’s CLIP component while minimizing human detectability. This approach allows for the injection of backdoor triggers without requiring significant alterations to the image content, facilitating a higher degree of stealth and enabling the attack to persist across a wide range of real-world image inputs.
Semantic Mixing, as implemented in BadCLIP++, generates textual descriptions for manipulated images by combining semantically similar phrases from a predefined corpus. This technique avoids the generation of artificial or grammatically incorrect captions that would typically flag adversarial manipulation. By strategically blending phrases – for example, replacing “a red car” with “an automobile painted red” – the framework creates descriptions that are statistically indistinguishable from natural language, effectively concealing the trigger and enhancing the stealth of the backdoor attack against image classification models. The process prioritizes semantic equivalence over exact phrase replication, resulting in captions that appear organic and bypass conventional anomaly detection methods.
Elastic Weight Consolidation (EWC) is integrated into BadCLIP++ to preserve the backdoor functionality during model retraining or fine-tuning, thus ensuring persistent stealth. EWC achieves this by identifying and protecting the weights crucial for the backdoor’s operation; specifically, it calculates the Fisher information for these weights during initial backdoor implantation. This Fisher information then serves as a regularization term during subsequent training, penalizing any significant deviation from the original, backdoored weights. Consequently, even when subjected to adversarial training intended to remove backdoors, the EWC regularization forces the model to retain the compromised functionality, maintaining a high attack success rate and bolstering the backdoor’s resilience against standard defense mechanisms.
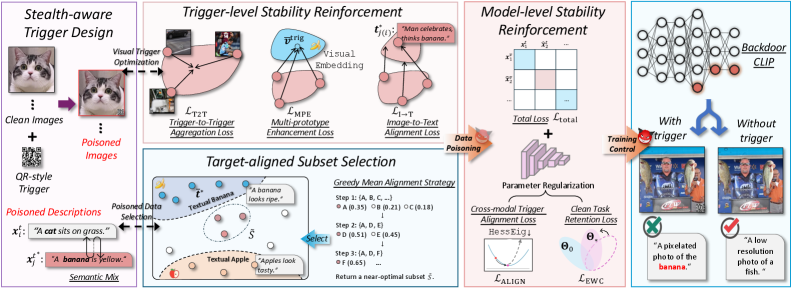
Optimizing for Undetectable Persistence: The Algorithm’s Refinement
BadCLIP++ utilizes a Cross-Modal Consistency Loss to enhance the correlation between injected image triggers and corresponding text prompts. This loss function operates by minimizing the distance between the embeddings of the poisoned image and its associated textual description within a shared embedding space, as defined by the CLIP model. Specifically, it encourages the image trigger to activate the same semantic features as the target text, ensuring that when the poisoned image is presented to the model, it elicits a classification consistent with the attacker’s intended target label. The strength of this alignment, as measured by the loss value, directly impacts the success rate and reliability of the backdoor attack, as it dictates how effectively the trigger can manipulate the model’s predictions.
Greedy Mean Alignment enhances backdoor attack success by prioritizing the selection of data subsets for poisoning based on semantic similarity to the target description. This method calculates the mean embedding distance between each potential poisoning subset and the target description’s embedding, iteratively choosing the subset with the smallest distance. By focusing on semantically related data, the attack strengthens the association between the trigger and the desired target class, improving both the attack success rate and the transferability of the backdoor. This approach contrasts with random subset selection, which lacks this semantic guidance and typically yields lower performance.
Trigger optimization in BadCLIP++ utilizes gradient information to refine the adversarial trigger for enhanced performance. Specifically, the gradients of the loss function with respect to the trigger pixels are calculated and used to update the trigger itself via gradient descent. This iterative process adjusts the trigger to maximize the model’s misclassification rate on poisoned samples while minimizing its detectability. The optimization is performed within the embedding space, directly manipulating the trigger’s features to achieve a stronger alignment with the target class and improve attack success rates, even against robust models. This gradient-guided approach allows for precise tuning of the trigger, resulting in a more effective and stealthy backdoor.
The BadCLIP++ framework exhibits resilience to a range of input perturbations while maintaining the implanted backdoor functionality. Testing indicates consistent attack success rates even when subjected to common adversarial attacks and standard image manipulations, including variations in brightness, contrast, and the addition of noise. This robustness is achieved through the framework’s reliance on semantically consistent cross-modal triggers and optimization strategies, allowing the backdoor to remain active despite modifications to the input data. Specifically, the framework maintains a high success rate across different perturbation strengths, demonstrating a practical advantage in real-world deployment scenarios where input data may be subject to unforeseen alterations.
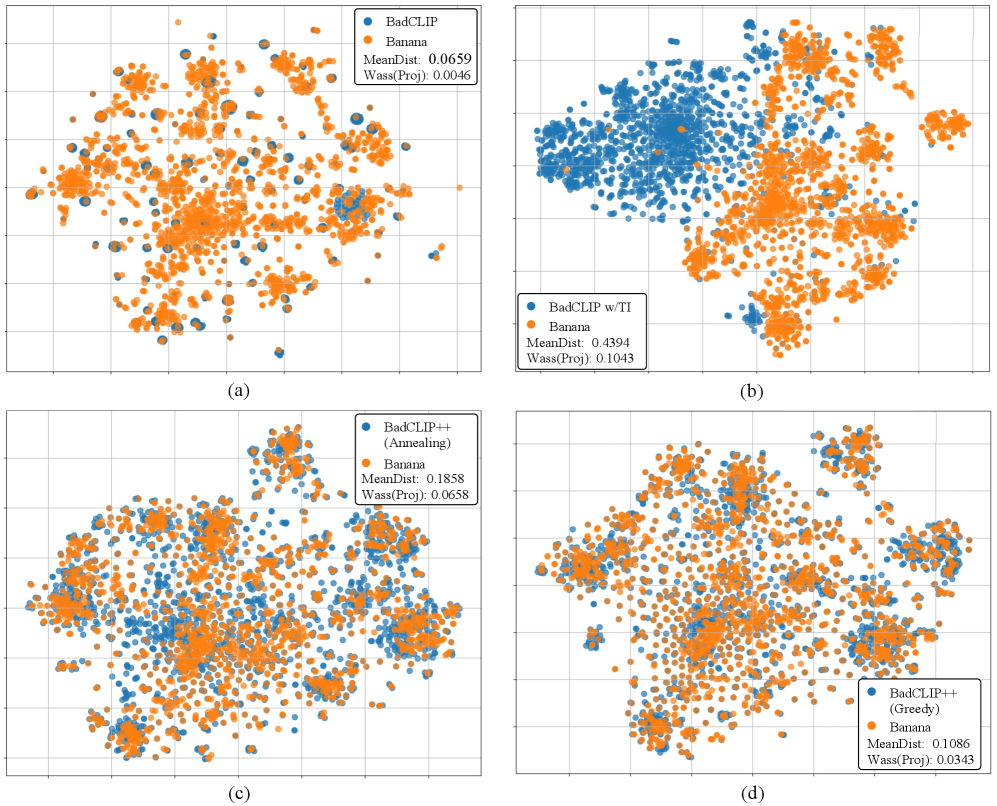
The Illusion of Defense: Assessing the Vulnerability of Current Systems
Evaluations reveal that commonly employed defense strategies offer minimal protection against the BadCLIP++ attack. Techniques like Data Filtering Defense, designed to remove potentially malicious samples, and Inference-Time Defense, which aims to disrupt the attack during prediction, consistently fail to prevent successful manipulation of image classifications. Even more robust approaches, such as Fine-tuning Defense, which involves retraining the model to mitigate the backdoor, prove largely ineffective. These findings suggest that BadCLIP++’s sophisticated cross-modal nature-leveraging the interplay between image and text-circumvents the assumptions underlying these traditional defenses, highlighting a critical gap in current security measures and the urgent need for novel countermeasures.
Despite the implementation of model-level defense strategies, the BadCLIP++ attack consistently bypasses these protections, revealing a critical gap in current security protocols. These defenses, which typically focus on reinforcing the model’s inherent robustness or identifying malicious alterations, prove inadequate against the nuanced and adaptable nature of this cross-modal backdoor. The failure of these approaches suggests that simply strengthening the model itself is insufficient; more sophisticated countermeasures are needed that address the specific mechanisms by which BadCLIP++ operates – particularly its ability to exploit vulnerabilities across different data modalities. This necessitates a shift in focus toward defenses that can actively detect and neutralize the attack’s subtle manipulations, rather than solely relying on the model’s inherent resistance to adversarial inputs.
The remarkable resilience of the BadCLIP++ backdoor stems from its exploitation of established learning principles. Specifically, Elastic Weight Consolidation (EWC) – a technique designed to protect previously learned knowledge during new training – inadvertently stabilizes the embedded malicious triggers. This stabilization is further reinforced by gradient alignment, where the attack subtly shapes the model’s learning process to ensure the backdoor’s gradients remain consistent with legitimate tasks. Consequently, standard backdoor removal techniques, which often rely on disrupting these gradients, prove largely ineffective; the attack effectively camouflages itself within the model’s core functionality, making detection and mitigation exceptionally challenging. This interplay between EWC, gradient alignment, and the attack’s architecture underscores a fundamental difficulty in disentangling malicious modifications from beneficial learning, demanding innovative approaches to safeguard machine learning systems.
The cross-modal backdoor attack, BadCLIP++, demonstrates a remarkable capacity for infiltrating image recognition systems, achieving a near-perfect 99.99% Attack Success Rate (ASR) on the widely-used ImageNet dataset. This exceptionally high success rate indicates the attack’s potency and ability to consistently manipulate model predictions without raising immediate red flags. The stealth of BadCLIP++ lies in its subtle modification of model weights during training, allowing it to seamlessly embed a malicious trigger – a specific text prompt – that activates when presented alongside a target image. Consequently, the model misclassifies images according to the attacker’s intent, all while maintaining a seemingly normal performance on benign inputs, making detection particularly challenging.
Current methods for identifying malicious manipulation in AI systems falter when confronted with BadCLIP++. Analysis reveals a strikingly low Detection Success Rate (DSR) against this novel cross-modal backdoor attack, indicating a significant gap in the field’s ability to recognize and neutralize such threats. This isn’t simply a matter of incremental improvement; existing defenses, designed to flag anomalies or inconsistencies, consistently fail to identify the subtle yet potent manipulation introduced by BadCLIP++. The attack’s stealth relies on carefully aligning gradients and leveraging elastic weight consolidation, effectively camouflaging the backdoor within the model’s learned parameters, and presenting a formidable challenge to detection algorithms. Consequently, even sophisticated defenses struggle to differentiate between legitimate inputs and those carrying the malicious trigger, underscoring the need for fundamentally new approaches to safeguard AI systems against these advanced adversarial techniques.
Evaluations demonstrate that BadCLIP++ distinguishes itself from contemporary backdoor attacks by maintaining a remarkably high Attack Success Rate (ASR) even when subjected to robust defense mechanisms. While other attacks experience significant performance degradation when confronted with defenses like data filtering or model fine-tuning, BadCLIP++ consistently achieves near-perfect results. This resilience stems from the attack’s unique cross-modal nature and its ability to exploit vulnerabilities that traditional, image-focused defenses fail to address. The persistent success of BadCLIP++ under pressure suggests a fundamental limitation in current defensive strategies, emphasizing the need for countermeasures specifically tailored to combat cross-modal threats and highlighting the attack’s sophistication in evading detection and mitigation.
The demonstrated resilience of BadCLIP++ against existing defense mechanisms necessitates an immediate and focused effort toward creating entirely new countermeasures. Current strategies, designed to address conventional attacks, prove largely ineffective against this cross-modal backdoor, which exploits the interplay between image and text modalities. This vulnerability demands research beyond simple adaptation of existing techniques; instead, innovative approaches are required that specifically target the unique characteristics of cross-modal manipulation. Successfully mitigating this threat necessitates a paradigm shift in defensive strategies, prioritizing techniques that can disrupt the subtle, yet potent, influence of maliciously crafted textual triggers on image classification outcomes, ensuring the robustness of AI systems against increasingly sophisticated attacks.
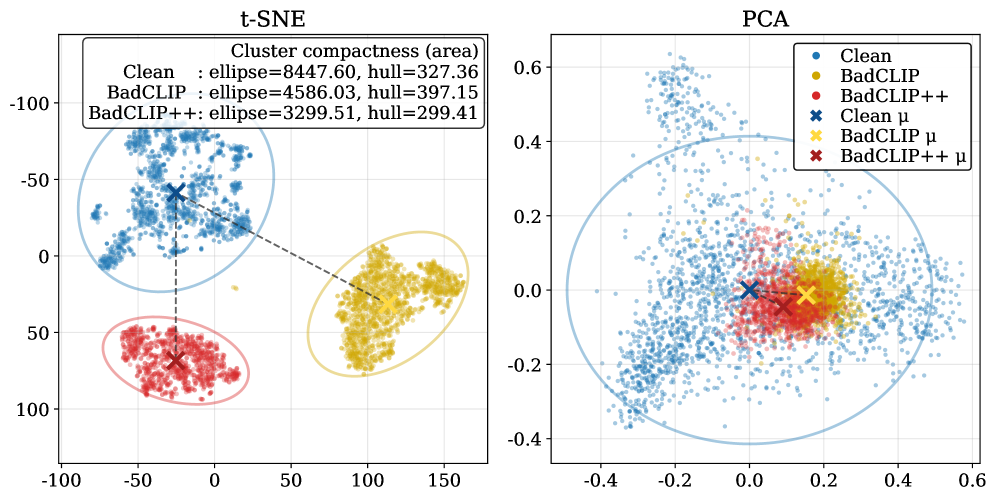
The pursuit of robustness in multimodal contrastive learning, as demonstrated by BadCLIP++, necessitates a rigorous examination of potential vulnerabilities. It is not sufficient for a model to simply perform well on standard benchmarks; its internal logic must withstand adversarial scrutiny. As Geoffrey Hinton observes, “The goal is to build systems that can generalize, and that means understanding the underlying principles.” BadCLIP++ challenges the assumption of inherent security in these models, revealing how subtle manipulations of cross-modal alignment can introduce persistent backdoors. The framework’s emphasis on trigger design, ensuring both stealth and resilience against defense mechanisms, highlights a mathematical truth: a flawed foundation, no matter how well disguised, will ultimately compromise the entire structure. The paper’s contribution isn’t merely identifying an attack vector, but rather demonstrating a systemic weakness that demands a more provably secure approach to multimodal learning.
Beyond the Shadow: Future Directions
The presented work, while demonstrating a concerning capacity for crafting persistent and stealthy backdoors in multimodal systems, merely scratches the surface of a deeper, more fundamental vulnerability. The success of BadCLIP++ hinges on manipulating the cross-modal alignment process – a core tenet of these models. However, to believe that clever trigger design alone constitutes a robust attack is, frankly, naive. A truly elegant solution would not add a vulnerability, but exploit an inherent weakness in the very principles of contrastive learning itself.
Future investigations should not focus solely on evading detection, but on mathematically characterizing the conditions under which such alignment can be subtly, yet decisively, corrupted. The field needs a shift from empirical “defense against attacks” to provable guarantees of robustness. Optimization without analysis remains self-deception, a trap for the unwary engineer. Until the underlying geometry of the embedding space is better understood, and formally verified, these models will remain susceptible to manipulation, regardless of how sophisticated the trigger.
Ultimately, the pursuit of adversarial robustness in multimodal learning demands a return to first principles. The current emphasis on scaling model size and data volume is a distraction. The true challenge lies in forging algorithms that are not merely ‘working on tests’, but are demonstrably, provably, correct – a pursuit that demands mathematical rigor, not just algorithmic ingenuity.
Original article: https://arxiv.org/pdf/2602.17168.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Shadow Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Best Bows in Crimson Desert
- All Skyblazer Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- Wings of Iron Walkthrough in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- How to Craft the Elegant Carmine Armor in Crimson Desert
- Keeping Large AI Models Connected Through Network Chaos
2026-02-21 17:34