Author: Denis Avetisyan
Researchers have developed a more potent and resilient method for injecting malicious triggers into object detection models, raising concerns about real-world security.
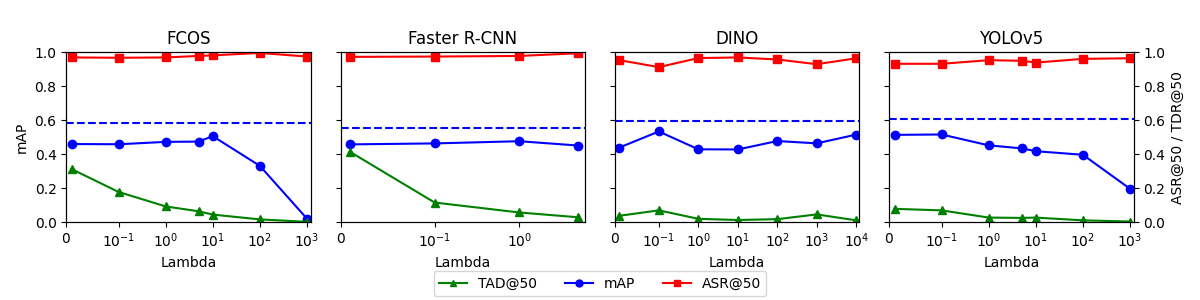
BadDet+ introduces a novel framework for launching robust backdoor attacks on object detection, demonstrating improved performance over existing data poisoning techniques like RMA and ODA.
While deep learning models exhibit remarkable performance, their susceptibility to subtle, targeted manipulations remains a critical concern, particularly in object detection systems. This paper introduces ‘BadDet+: Robust Backdoor Attacks for Object Detection’, a novel framework designed to launch highly effective and physically plausible backdoor attacks on these models by unifying region misclassification and object disappearance strategies. BadDet+ achieves superior performance and transferability to real-world scenarios through a penalty-based mechanism enforcing trigger-specific feature suppression, demonstrating both position/scale invariance and enhanced robustness. Given these findings, what specialized defenses are necessary to mitigate these emerging vulnerabilities in object detection systems and ensure their reliable deployment in security-sensitive applications?
The Insidious Threat of Backdoor Manipulation
Modern object detection systems, powered by machine learning, face a growing and insidious threat from backdoor attacks. These attacks subtly compromise a model’s integrity during the training phase by associating specific, rarely occurring input patterns – the “backdoor” – with attacker-defined outputs. Consequently, the model functions normally on typical data, masking the malicious functionality, but consistently misclassifies inputs containing the trigger. This poses significant risks across applications like autonomous vehicles and security screening, where even isolated failures can have severe consequences. The vulnerability stems from the data-driven nature of machine learning; an attacker need only poison a small fraction of the training data to implant the backdoor, making detection incredibly challenging and demanding new strategies for data sanitization and model verification.
Backdoor attacks on machine learning models introduce a subtle but potent threat by implanting concealed functionality activated by specific, pre-defined triggers. Unlike conventional breaches focused on disrupting service, these attacks prioritize stealth; a model may perform nominally on standard inputs, yet yield attacker-controlled outputs when presented with a carefully crafted pattern – perhaps a specific color, a unique texture, or even a seemingly innocuous combination of objects. This poses a significant risk across numerous real-world applications, from self-driving cars misinterpreting critical road signs to facial recognition systems granting unauthorized access, as the malicious behavior remains dormant until the trigger is encountered, making detection exceptionally challenging and potentially catastrophic.
As machine learning models become increasingly integrated into critical infrastructure, the evolution of backdoor attacks demands a proactive shift towards more resilient security measures. Current defenses, often relying on detecting subtle anomalies in training data or model behavior, are frequently circumvented by attackers employing advanced obfuscation techniques and adaptive triggering mechanisms. Research is now focused on developing defenses that move beyond simple detection, exploring methods like input sanitization, model hardening through adversarial training, and the incorporation of explainable AI to reveal hidden functionalities. A comprehensive understanding of how these attacks operate – including the specific vulnerabilities they exploit and the methods used to evade detection – is paramount to designing truly robust and trustworthy machine learning systems capable of withstanding increasingly sophisticated threats.

The Mechanics of Data Poisoning
Data poisoning, a core technique in backdoor attacks, involves intentionally modifying the training dataset used to create a machine learning model. This manipulation centers around the introduction of a specific ‘backdoor trigger’ – a subtle pattern or alteration embedded within a small subset of the training data. When the model is trained on this poisoned dataset, it learns to associate the trigger with a specific, attacker-defined output. Consequently, the model behaves normally on clean, unmodified data, but misclassifies or produces a predetermined result when presented with input containing the backdoor trigger. The effectiveness of this attack hinges on the attacker’s ability to inject the trigger without being detected during data validation or model training.
The success of a data poisoning attack is critically dependent on the ‘Poisoning Ratio’, which represents the percentage of training data that has been maliciously modified. A high ratio increases the likelihood of the backdoor being learned by the model, but also elevates the risk of detection due to statistical anomalies or performance degradation. Conversely, a low ratio may be insufficient to reliably implant the backdoor trigger, resulting in a failed attack. Therefore, selecting an optimal Poisoning Ratio requires a trade-off between ensuring the backdoor’s effectiveness and maintaining the integrity of the training dataset to avoid raising suspicion. The specific optimal ratio is influenced by factors including the size of the training dataset, the complexity of the model, and the nature of the backdoor trigger itself.
The integration of a backdoor trigger into a machine learning model during training relies on manipulating the model’s weight updates. Specifically, the trigger – a subtly altered pattern in the input data – is associated with a target output. During training, when the model encounters poisoned data containing the trigger, the optimization process adjusts the model’s weights to consistently predict the attacker-defined target output when that trigger is present. This requires careful calibration of the trigger’s strength and frequency to ensure the backdoor functionality is consistently activated without significantly impacting performance on benign, unmodified data. The model effectively learns a conditional association: if the trigger is detected, output the target; otherwise, operate normally. Understanding the model’s learning algorithm and the influence of each training sample is crucial for crafting effective triggers and achieving a high success rate for the backdoor attack.
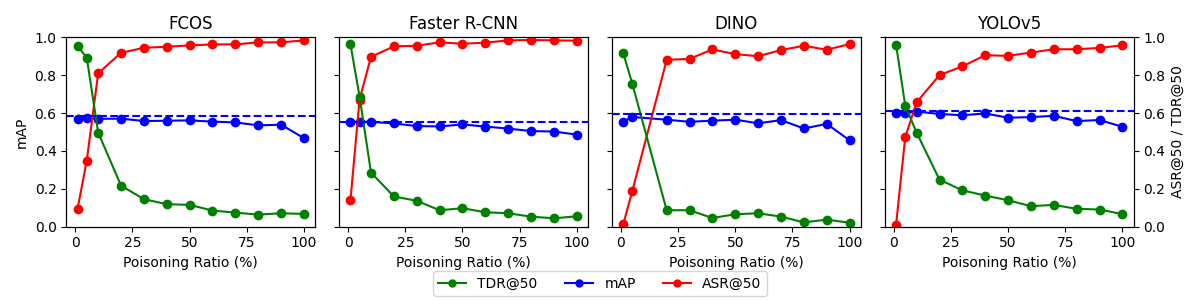
BadDet+: A Unified Attack Framework
BadDet+ consolidates diverse backdoor attack methodologies, specifically Reverse Model Architecture (RMA) and One-Day Attack (ODA), into a unified framework. Prior approaches typically required separate implementations and optimizations for each attack vector. BadDet+ achieves this unification by abstracting common elements across these attacks and implementing them within a single codebase. This allows for streamlined experimentation, simplified comparative analysis, and facilitates the development of more robust defenses applicable to a wider range of attack strategies. The framework provides a standardized interface for defining trigger patterns, embedding them into target models, and evaluating attack success rates, ultimately increasing the efficiency of both attack and defense research.
BadDet+ achieves state-of-the-art performance in backdoor attacks, demonstrating an Attack Success Rate (ASR) of up to 96.4% at a 50% poisoning rate (ASR@50) when utilizing the One-Day Attack (ODA) methodology. Furthermore, the framework significantly reduces the Target Detection Rate (TDR) at a 50% poisoning rate (TDR@50) in Reverse-engineering Model Attack (RMA) scenarios. These results, obtained through rigorous experimentation, establish BadDet+ as a highly effective and robust attack framework, exceeding the performance of previously established methods in both ODA and RMA attack vectors.
The BadDet+ framework utilizes a Log-Barrier Penalty during model training to address the trade-off between backdoor attack success rate and clean accuracy. This penalty term is added to the loss function, explicitly enforcing the backdoor objective – ensuring the model misclassifies inputs with the trigger – while simultaneously preventing significant degradation of performance on benign, untriggered data. The Log-Barrier Penalty functions as a constraint, pushing the model parameters towards solutions that satisfy both objectives; it effectively limits the optimization process to regions where the backdoor objective is met without substantially compromising clean accuracy, thus enabling high Attack Success Rate (ASR) and low Trigger Detection Rate (TDR).

The Limits of Sanitization and Future Directions
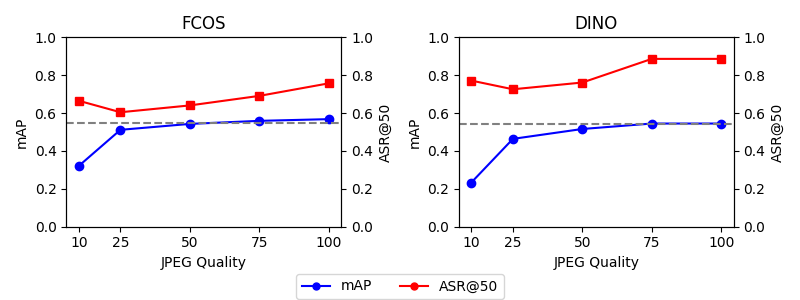
Initial investigations into input sanitization as a defense against backdoor attacks reveal a surprising complexity. Techniques such as JPEG compression, intended to reduce malicious payloads or alter adversarial perturbations, can inadvertently disrupt the functionality of the implanted backdoor itself. This disruption isn’t necessarily a complete neutralization, but rather an alteration of the attack’s efficacy, potentially leading to decreased accuracy or altered triggering conditions. The observation suggests that successful defenses may not require entirely eliminating the backdoor, but instead, manipulating it into a benign or easily detectable state – a strategy that shifts the focus from complete removal to controlled degradation of the malicious functionality. This unexpected interaction between sanitization and backdoor mechanics offers a promising, though nuanced, pathway for future defensive research.
Despite attempts to mitigate adversarial perturbations through common image compression techniques, research demonstrates a surprising resilience of these attacks. Specifically, even after substantial JPEG compression-a process designed to reduce file size and potentially remove subtle alterations-the attack maintains an accuracy rate of over 60% when targeting the top 5 predicted classes ASR@50. This finding suggests that the adversarial signal is robust enough to survive lossy compression, indicating that current defense mechanisms are often insufficient and that attackers can still successfully manipulate machine learning systems even with widely implemented image processing protocols. The persistence of this vulnerability underscores the need for more sophisticated and adaptable defense strategies within the field of adversarial learning.
The escalating sophistication of adversarial attacks necessitates a parallel investment in robust defensive strategies for machine learning systems. Maintaining the reliability and security of these systems-increasingly integrated into critical infrastructure and everyday applications-demands more than reactive measures. Development must prioritize defenses capable of anticipating and neutralizing novel attack vectors, rather than simply patching vulnerabilities as they emerge. This proactive approach requires ongoing research into techniques that enhance model resilience, improve input validation, and establish trustworthy AI foundations. Ultimately, a sustained commitment to robust defenses is paramount to safeguarding the integrity and functionality of machine learning in an evolving threat landscape.
The dynamic landscape of adversarial learning necessitates a forward-looking research agenda. Investigations should prioritize the development of defenses that anticipate and neutralize attacks before they are launched, moving beyond reactive measures. Simultaneously, continued exploration of novel attack strategies is vital; understanding how systems can be compromised allows for the creation of more resilient defenses. This cyclical process of attack and defense – a constant probing of vulnerabilities and strengthening of safeguards – is crucial for ensuring the robustness and reliability of machine learning models in the face of increasingly sophisticated threats. Such proactive measures will be essential to maintaining trust and security within the rapidly evolving field.
The pursuit of robustness in object detection, as demonstrated by BadDet+, echoes a fundamental tenet of reliable algorithms. The paper meticulously details a framework for launching backdoor attacks, effectively exposing vulnerabilities within current models. This rigorous exploration of adversarial learning isn’t merely about creating attacks, but about understanding the mathematical foundations-or lack thereof-upon which these systems are built. As Andrew Ng aptly stated, “Machine learning is about learning the right representation.” BadDet+ illuminates how easily a model’s representation can be manipulated through data poisoning, highlighting the need for provably secure defenses, rather than systems that simply ‘work on tests’.
What’s Next?
The demonstrated efficacy of BadDet+ is, predictably, not a triumph of technique, but a stark restatement of fundamental vulnerability. The pursuit of increasingly subtle data poisoning-attacks that skirt superficial detection metrics-is less a matter of engineering prowess and more an inevitable consequence of relying on correlative learning. Object detection, at its core, identifies patterns; it does not understand objects. BadDet+ merely refines the manipulation of those patterns, highlighting the fragility of any system built on statistical association.
Future work must abandon the arms race of attack and defense focused solely on empirical performance. The field requires a shift towards provable robustness – formal verification of detector behavior under adversarial perturbation. While computationally demanding, a mathematically rigorous approach is the only path towards genuine security. The current obsession with RMA and ODA scores serves only to measure the difficulty of attack, not the impossibility of it.
Ultimately, the question is not whether a more effective attack will emerge-it undoubtedly will-but whether the underlying principles of object detection can be recast in a framework that admits formal guarantees. Until then, the elegance of any algorithm remains illusory, a fleeting impression of correctness masking a fundamental lack of certainty.
Original article: https://arxiv.org/pdf/2601.21066.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- All Shadow Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- Best Bows in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- How to Craft the Elegant Carmine Armor in Crimson Desert
- Keeping Large AI Models Connected Through Network Chaos
- One Piece Chapter 1179 Preview: The Real Imu Arrives in Elbaf
2026-02-01 20:48