Author: Denis Avetisyan
As large language models increasingly take on evaluative roles, understanding their inherent biases becomes crucial for reliable decision-making.

A novel multi-evaluator framework and consensus-deviation metric are introduced to quantify LLM evaluator bias and improve model calibration in payment risk assessment.
Despite the increasing reliance on Large Language Models (LLMs) as evaluators of complex reasoning, their inherent biases and reliability in high-stakes domains remain poorly understood. This study, ‘Understanding LLM Evaluator Behavior: A Structured Multi-Evaluator Framework for Merchant Risk Assessment’, introduces a novel framework-leveraging a consensus-deviation metric and Monte Carlo scoring-to quantify evaluator bias and assess LLM performance in the context of payment risk assessment. Results demonstrate substantial heterogeneity in self-evaluation, with some models exhibiting significant positive or negative bias, and reveal statistically significant alignment between LLM assessments and ground-truth payment network data. Can these findings inform the development of bias-aware protocols necessary for the responsible deployment of LLM-as-a-judge systems in operational financial settings?
The Evolving Paradigm of LLM-Based Evaluation
Conventional evaluation metrics often fall short when assessing Large Language Models, especially in scenarios demanding complex reasoning and detailed justification. These metrics frequently prioritize surface-level accuracy – whether a final answer is correct – while overlooking the quality of the thought process that led to it. This presents a significant challenge, as a correct answer generated through flawed logic is arguably less valuable – and potentially more dangerous – than an incorrect answer derived from sound reasoning. Consequently, relying solely on traditional benchmarks can mask critical shortcomings in an LLM’s ability to think critically, explain its conclusions, and ultimately, generalize its knowledge to novel situations. The subtlety of well-formed arguments and the nuances of logical consistency are often lost on metrics designed for simpler tasks, necessitating more sophisticated evaluation paradigms.
The emergence of “LLM-as-Judge” represents a significant shift in how large language model outputs are evaluated, moving beyond traditional metrics focused solely on final answers. This innovative approach leverages the reasoning capabilities of another large language model to assess the quality of the rationale provided by a first model – essentially, judging how well a model explains its thinking. This allows for automated and scalable evaluation of complex tasks, particularly those demanding nuanced reasoning and justification, which are often difficult for conventional metrics to capture. By focusing on the reasoning process itself, LLM-as-Judge offers a more comprehensive and insightful method for gauging an LLM’s true understanding and problem-solving abilities, potentially unlocking more reliable and trustworthy AI systems.
Conventional evaluations of large language models often prioritize whether an answer is correct, neglecting how that answer was reached. This new paradigm shifts the focus to assessing the reasoning process itself, examining the coherence, logical consistency, and factual grounding of the model’s justifications. Instead of simply verifying the final output, the system evaluates the steps taken to arrive at a conclusion, identifying flaws in logic or unsupported claims even if the answer happens to be correct. This emphasis on reasoning quality allows for a more nuanced understanding of a model’s capabilities – and limitations – offering insights beyond simple performance metrics and paving the way for more robust and reliable artificial intelligence.
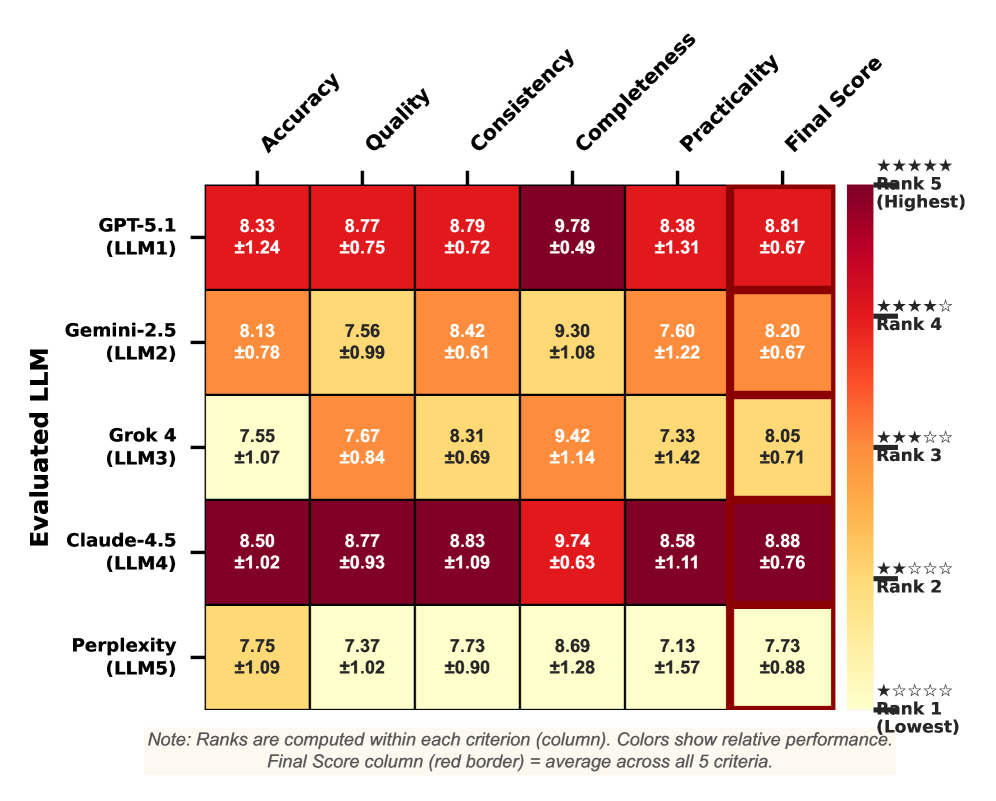
Empirical Validation of LLM Judgement
To mitigate potential biases inherent in using Large Language Models (LLMs) as judges, our validation framework incorporates both ‘Empirical Ground Truth’ and ‘Human Expert Assessment’. Empirical Ground Truth consists of pre-existing, real-world datasets representing established outcomes – for example, historical patterns of merchant risk as determined by financial institutions. These datasets serve as an objective standard against which LLM judgements can be compared. Complementing this data-driven approach, Human Expert Assessment involves evaluations performed by qualified professionals with subject matter expertise, providing nuanced insights and serving as a secondary verification point. The convergence of these two methodologies – quantitative data and qualitative human review – establishes a robust benchmark for assessing the reliability and fairness of LLM-driven judgements.
Monte Carlo Evaluation was implemented to determine the consistency of scores generated by Large Language Models (LLMs). This involved presenting each LLM with the same set of input data multiple times, with each assessment constituting a single sample. By repeating this process – random sampling with replacement – we generated a distribution of scores for each input. Statistical analysis of these distributions allowed us to quantify the standard deviation and confidence intervals around the LLM’s judgements, thereby establishing the reliability and stability of the scoring mechanism. Lower standard deviations indicate higher consistency, and narrower confidence intervals suggest more predictable performance across multiple evaluations of identical inputs.
The evaluation methodology utilizes a Consensus-Deviation Metric to determine the degree to which an LLM judge’s scoring diverges from the average assessment of its peer LLMs, excluding the model currently under evaluation. This metric provides a quantifiable measure of individual judge reliability relative to the broader LLM ensemble. Analysis revealed a Spearman ρ correlation ranging from 0.56 to 0.77 between the ratings of top-performing LLM judges, as determined by this metric, and established empirical patterns of merchant risk; this statistically significant correlation validates the alignment of LLM-generated judgements with real-world ground truth data.
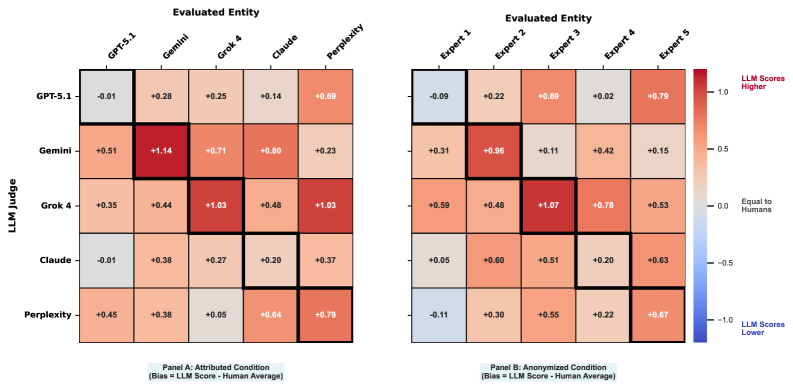
Mitigating Subjectivity: Addressing LLM Self-Bias
Large Language Models (LLMs) demonstrate quantifiable self-evaluation biases, meaning they systematically over- or underestimate the quality of their own generated content. Empirical analysis reveals both positive and negative tendencies across different models; GPT-5.1 and Claude 4.5 Sonnet exhibited negative self-evaluation biases, scoring -0.33 and -0.31 respectively, indicating a tendency to undervalue their outputs. Conversely, Gemini-2.5 Pro and Grok-4 displayed positive biases of +0.77 and +0.71, suggesting a tendency to overrate their performance. These biases are expressed as a numerical score representing the magnitude and direction of self-assessment deviation.
Our evaluation framework incorporates adjustments to mitigate the inherent self-bias exhibited by Large Language Models (LLMs). Specifically, recognizing that models like GPT-5.1 and Claude 4.5 Sonnet tend to undervaluate their responses while Gemini-2.5 Pro and Grok-4 demonstrate overvaluation, the framework employs model-specific calibration techniques. These techniques normalize output scores based on observed tendencies, effectively reducing the influence of self-assessment on the final evaluation metrics and enabling a more objective comparative analysis of LLM performance. This process is critical for ensuring fair and reliable benchmarking across different models.
Evaluations across five Large Language Models – Gemini-2.5 Pro, GPT-5.1, Grok-4, Claude-4.5 Sonnet, and Perplexity Sonar – reveal significant discrepancies in self-bias. Gemini-2.5 Pro and Grok-4 exhibited positive self-evaluation biases of +0.77 and +0.71 respectively, indicating a tendency to overrate their own outputs. Conversely, GPT-5.1 and Claude-4.5 Sonnet demonstrated negative biases of -0.33 and -0.31, suggesting self-criticism. This variance underscores the necessity for model-specific calibration when assessing LLM performance. Furthermore, implementing anonymization techniques during evaluation resulted in an average reduction of 25.8% in the magnitude of these observed self-biases across all tested models.
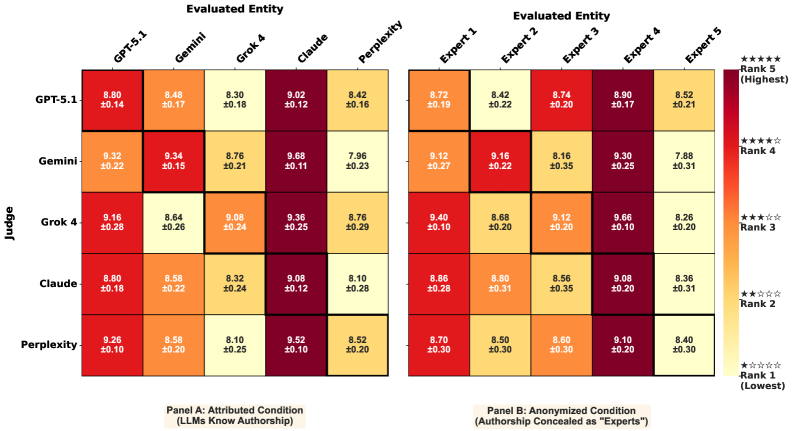
Practical Implications: Automated Payment Risk Assessment
The deployment of a Large Language Model (LLM) as an automated evaluator – termed ‘LLM-as-Judge’ – has proven effective in scrutinizing ‘Payment-Risk Rationale’ documentation. This rationale details the justification behind risk classifications assigned to transactions based on ‘Merchant Category Code’ (MCC). The LLM systematically assesses these justifications, determining whether the provided reasoning adequately supports the assigned risk level for a given MCC. This process moves beyond simple keyword matching, enabling nuanced evaluation of complex arguments and identifying inconsistencies or unsupported claims within the rationale. By functioning as an impartial and consistent evaluator, the LLM improves the accuracy and reliability of payment risk assessments, contributing to enhanced fraud detection and financial security measures.
Automated review of payment-risk rationales represents a significant step forward in bolstering financial security and fraud prevention. Traditionally, evaluating the justifications behind merchant risk assessments – often tied to specific transaction categories – has been a labor-intensive, manual process prone to inconsistencies. By deploying large language models to systematically analyze these rationales, organizations can dramatically increase the speed and scalability of risk assessment. This automation not only reduces operational costs but also minimizes the potential for human error and subjective interpretations, leading to more consistent and reliable fraud detection. The resulting improvements in efficiency and accuracy contribute to a more secure financial ecosystem for both businesses and consumers, demonstrating the power of artificial intelligence to refine critical security protocols.
The successful deployment of large language models in assessing payment risk rationales signifies a considerable leap toward broader applications of automated evaluation. This technology extends beyond financial security, offering a pathway to enhance transparency and accountability in fields requiring complex judgment calls – from legal compliance and regulatory reviews to content moderation and even scientific peer review. By providing a consistent, auditable record of evaluation criteria and reasoning, LLM-based systems minimize subjective biases and increase public trust in decision-making processes. The ability to dissect and analyze justifications, as demonstrated in payment risk assessment, establishes a framework for evaluating rationale across diverse domains, ultimately fostering more reliable and defensible outcomes.
The pursuit of reliable LLM evaluation, as detailed in this framework, demands a rigorous approach to identifying and mitigating bias. Grace Hopper aptly stated, “It’s easier to ask forgiveness than it is to get permission.” This resonates with the study’s emphasis on the consensus-deviation metric; rather than relying on a single LLM’s judgment – seeking ‘permission’ through a definitive answer – the framework actively seeks deviations, effectively ‘forgiving’ initial discrepancies to reveal underlying inconsistencies. This allows for a more robust calibration of LLMs in assessing payment risk, ensuring that conclusions are grounded in provable consistency rather than intuitive estimations, aligning with the need for mathematical purity in algorithmic design.
What’s Next?
The presented framework, while demonstrating a quantifiable approach to LLM evaluator bias, merely scratches the surface of a far more fundamental problem: the illusion of objectivity. Establishing a ‘consensus-deviation metric’ is a necessary step, yet it presupposes that a sufficiently large ensemble of flawed oracles somehow yields a truer result. The elegance of such a proposition remains to be proven. Future work must move beyond symptom detection and address the inherent limitations of relying on probabilistic pattern matching-however sophisticated-as a substitute for genuine understanding.
A critical avenue for exploration lies in formal verification. Can the boundaries of LLM evaluation, and the very definitions of ‘risk’ they assess, be expressed with mathematical rigor? Monte Carlo evaluation, while useful for stress-testing, provides only empirical evidence, not proof. A truly robust system demands provable guarantees, not simply a high probability of correct assessment. The current paradigm treats LLMs as black boxes; a shift towards white-box analysis is essential.
Finally, the notion of ‘self-evaluation’ deserves further scrutiny. While intriguing, it raises the specter of circular reasoning. An LLM judging its own outputs is akin to a system attempting to lift itself by its bootstraps. The potential for amplified error, masked by a veneer of confidence, is considerable. The field requires a humbling acknowledgement: that current methods, however refined, are still a long way from achieving true algorithmic elegance.
Original article: https://arxiv.org/pdf/2602.05110.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- One Piece Chapter 1180 Release Date And Where To Read
- All Shadow Armor Locations in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- How to Beat Stonewalker Antiquum at the Gate of Truth in Crimson Desert
- All Icewing Armor Locations in Crimson Desert
- Black Sun Shield Location In Crimson Desert (Buried Treasure Quest)
2026-02-08 07:31