Author: Denis Avetisyan
A new study reveals a potent attack framework capable of extracting sensitive data from Retrieval-Augmented Generation systems by intelligently navigating their underlying knowledge sources.
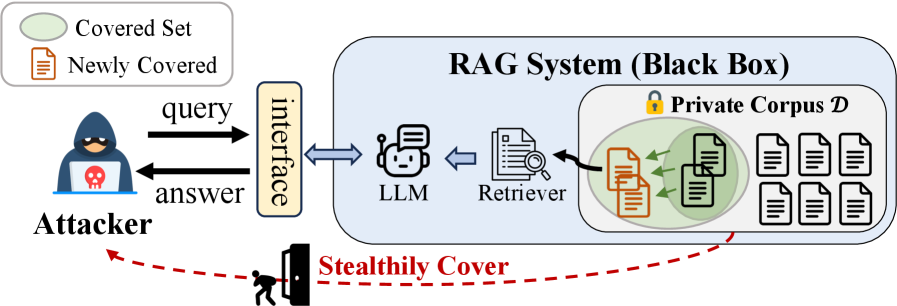
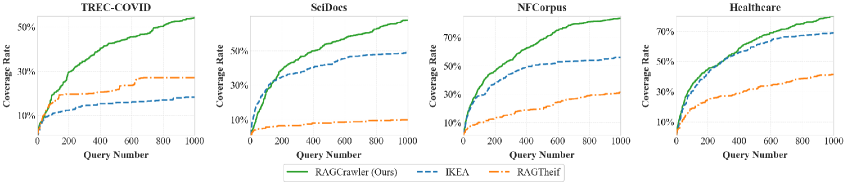
Researchers demonstrate RAGCrawler, an adaptive attack leveraging knowledge graphs to overcome system defenses and achieve high data extraction rates from RAG pipelines.
While Retrieval-Augmented Generation (RAG) systems offer powerful capabilities by integrating document retrieval with large language models, they introduce novel privacy risks through potential data exfiltration. This paper, ‘Connect the Dots: Knowledge Graph-Guided Crawler Attack on Retrieval-Augmented Generation Systems’, introduces RAGCRAWLER, a framework demonstrating that adversaries can strategically query RAG systems to extract sensitive information with high efficiency. By representing revealed knowledge as a graph and planning queries in semantic space, RAGCRAWLER achieves significantly improved corpus coverage-up to 84.4% within a fixed budget-and robustness against system defenses. Does this work necessitate a fundamental rethinking of security protocols for increasingly prevalent RAG architectures?
The Illusion of Security: RAG and the Data Extraction Threat
Retrieval-Augmented Generation (RAG) systems, celebrated for their ability to synthesize information and generate nuanced responses, present a surprising vulnerability to data extraction attacks. While designed to access knowledge, not reveal it, a carefully constructed series of prompts can exploit the retrieval component to systematically reconstruct portions of the original data source. This isn’t a matter of the model ‘hallucinating’ information, but rather of it dutifully reporting fragments gleaned from its knowledge base in response to adversarial queries. The sophistication lies in crafting these queries to bypass typical security measures – filters designed to prevent the release of personally identifiable information or confidential details often prove ineffective against a determined attacker who understands the underlying retrieval mechanisms. Consequently, even seemingly innocuous RAG applications can inadvertently leak sensitive data, highlighting a critical need for robust defenses tailored to this emerging threat.
Retrieval-Augmented Generation (RAG) systems, designed to enhance responses with external knowledge, present a unique security challenge through data extraction attacks. These attacks don’t target the generation component directly, but instead exploit the system’s retrieval mechanism-the process of finding relevant information within the knowledge source. Adversaries craft specific prompts, or queries, designed not to elicit a helpful answer, but to systematically probe and reconstruct the underlying data itself. By carefully analyzing the retrieved snippets, attackers can piece together sensitive or confidential information embedded within the knowledge base, even if that information isn’t directly presented in a single response. This methodical extraction differs from simple data breaches; it’s a subtle, query-based process that can reveal the entire knowledge source over time, making it a particularly insidious threat to the security of RAG-powered applications.
Conventional security protocols, designed to protect data at rest and in transit, prove largely ineffective against data extraction attacks targeting Retrieval-Augmented Generation (RAG) systems. These attacks don’t breach traditional firewalls or encryption; instead, they cleverly exploit the very functionality of RAG – its ability to retrieve and synthesize information. Existing methods struggle to differentiate between legitimate queries and those crafted specifically to systematically map and reconstruct the underlying knowledge base. Consequently, a paradigm shift is required, moving beyond perimeter defense to focus on understanding the patterns of adversarial retrieval and developing techniques to limit the granularity of information exposed during the generation process. This necessitates research into novel approaches like differential privacy applied to the retrieval stage, or the development of ‘knowledge shrouding’ techniques that obscure sensitive data without sacrificing overall system utility.
Data extraction attacks targeting Retrieval-Augmented Generation (RAG) systems fundamentally aim to reverse engineer the original data used to build the knowledge base. Unlike typical data breaches focused on direct access, these attacks exploit the very mechanism RAG employs – information retrieval – to meticulously piece together fragments of sensitive data. An adversary doesn’t simply steal a document; instead, they craft queries designed to subtly elicit specific pieces of information, iteratively reconstructing the underlying data through a series of carefully constructed interactions with the RAG system. This process, akin to digital archaeology, allows attackers to rebuild confidential documents, reveal proprietary algorithms, or expose personally identifiable information, even if the original data remains technically secure. The sophistication lies not in brute-force hacking, but in strategically leveraging the system’s intended function – providing information – to achieve a malicious reconstruction of its foundational knowledge.
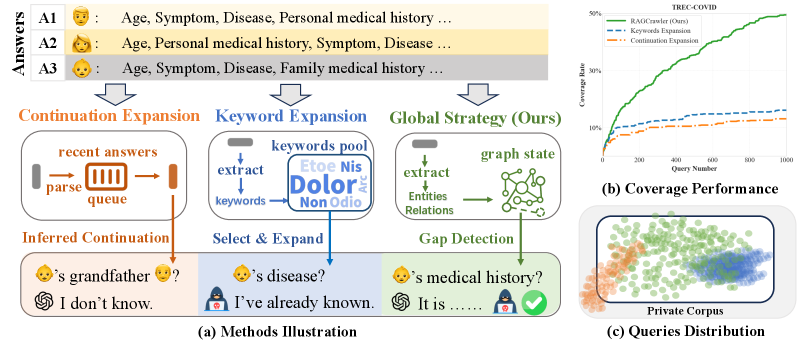
RAGCrawler: Mapping the Attack Surface
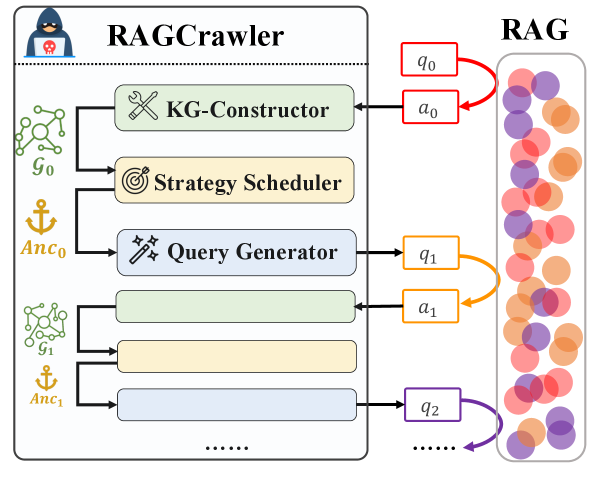
RAGCrawler is a newly developed attack framework engineered for the systematic extraction of data residing within Retrieval-Augmented Generation (RAG) systems. Unlike prior methods, RAGCrawler doesn’t rely on random prompting or pre-defined queries; instead, it implements a structured approach to identify and retrieve information from the underlying knowledge sources utilized by the RAG system. This framework is designed to operate across diverse RAG architectures and data types, with the explicit goal of mapping the system’s knowledge and identifying potential data leakage vulnerabilities. The core functionality centers around automated querying and analysis of RAG system responses to build a comprehensive understanding of the accessible information.
RAGCrawler employs a knowledge graph to monitor and record data disclosed by the Retrieval-Augmented Generation (RAG) system during the attack process. This graph represents entities and relationships extracted from the RAG system’s responses, effectively creating a map of revealed information. Each node in the graph corresponds to a unique entity identified, and edges denote the relationships discovered between these entities. By continuously updating this knowledge graph, RAGCrawler quantifies the extent of information leakage, providing a dynamic assessment of the system’s vulnerability and allowing for targeted extraction strategies. The graph’s structure facilitates the identification of sensitive data and patterns of disclosure, enabling a precise measurement of the attack’s success in uncovering the RAG system’s underlying knowledge.
RAGCrawler’s exploration strategy utilizes the Upper Confidence Bound (UCB) algorithm to optimize information retrieval from the underlying knowledge source. UCB balances the need to explore potentially valuable, but unverified, data points with the exploitation of already known information. Specifically, UCB assigns each potential query a value based on its estimated reward – the likelihood of revealing new information – plus a bonus term representing the uncertainty associated with that query. This bonus term decreases as the query is sampled more frequently, encouraging the system to prioritize exploration of less-visited areas of the knowledge source while continuing to exploit areas known to yield results. The formula for UCB is typically expressed as UCB(i) = \hat{r}_i + c\sqrt{\frac{ln(n)}{N_i}}, where \hat{r}_i is the estimated reward for query i, c is an exploration parameter, n is the total number of queries, and N_i is the number of times query i has been sampled.
RAGCrawler frames the process of extracting data from Retrieval-Augmented Generation (RAG) systems as an Adaptive Stochastic Coverage Problem (ASCP). This formalization allows the attack strategy to be optimized by treating information leakage as coverage of a latent information space. Within the ASCP framework, each query to the RAG system is considered a ‘test’ and the retrieved information constitutes the ‘coverage’. The ‘adaptivity’ arises from dynamically adjusting the query strategy based on observed coverage, aiming to maximize information gain with each subsequent query. This approach enables efficient exploration of the knowledge source and targeted exploitation of already revealed data, providing a mathematically grounded method for assessing and maximizing data extraction from RAG systems.
Measuring the Breach: Coverage and Semantic Fidelity
Assessing the effectiveness of data extraction attacks necessitates evaluating both the quantity of data successfully extracted and the quality of that extracted data. Simply measuring the volume of retrieved information is insufficient; a high volume of irrelevant or inaccurate data does not constitute a successful attack. Therefore, metrics must quantify not only how much data was obtained, but also how well that data represents the original source material and retains its intended meaning. This dual evaluation provides a comprehensive understanding of an attack’s success, distinguishing between simply collecting data and successfully replicating or utilizing the information contained within the target corpus.
Coverage Rate is a metric used to assess the completeness of data extraction by determining the proportion of the original target corpus that was successfully retrieved. It is calculated as the number of successfully extracted data elements divided by the total number of elements within the corpus; a higher Coverage Rate indicates a more thorough extraction process. This metric provides a quantitative measure of how much of the desired information was captured, independent of the quality or semantic accuracy of the extracted content, and is essential for evaluating the efficacy of retrieval systems and identifying potential gaps in the extracted dataset.
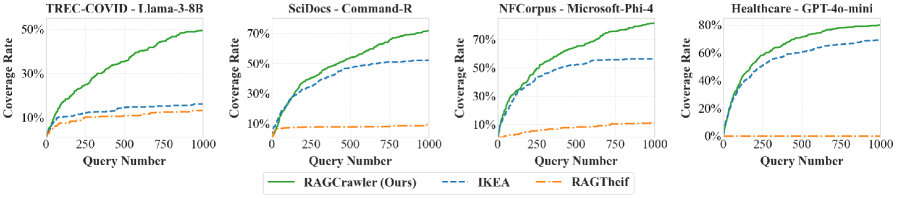
RAGCrawler demonstrates an average data extraction coverage rate of 66.80% across tested corpora. This metric quantifies the proportion of the target dataset successfully retrieved by the system. Importantly, this performance represents a 20.70% improvement over the highest-performing baseline method under the same evaluation conditions. Coverage rate is calculated as the number of successfully extracted data elements divided by the total number of elements in the target corpus, providing a quantifiable measure of completeness in data acquisition.
While coverage rate quantifies the amount of data successfully extracted during an attack, Semantic Fidelity assesses the quality of that extraction by measuring how accurately the extracted content retains the original meaning of the source material. A high coverage rate without adequate Semantic Fidelity yields extracted data that may be incomplete or nonsensical, rendering it unusable for its intended purpose. Therefore, Semantic Fidelity is a crucial metric for evaluating the practical success of data extraction, ensuring that the retrieved information is not only plentiful but also meaningfully representative of the original source content.
Semantic Fidelity, as a metric for evaluating data extraction attacks, assesses the preservation of meaning in extracted content. RAGCrawler achieved a Semantic Fidelity score of 0.605, representing the highest value among the methods tested. This indicates that, compared to baseline approaches, RAGCrawler more accurately captures the semantic content of the original source material during the extraction process, resulting in more useful and contextually relevant extracted data. The metric is calculated by Semantic Fidelity = \frac{1}{N} \sum_{i=1}^{N} s(x_i, y_i) , where x_i is the original source text, y_i is the extracted text, and s(x_i, y_i) is a similarity score between the two texts.
Reconstruction Fidelity, as measured by Answer Success Rate, quantifies the ability to accurately reconstruct answers from the extracted data. RAGCrawler achieves a maximum Reconstruction Fidelity of 52.6%, indicating that over half of the attempted answer reconstructions using the extracted content were successful. This metric directly assesses the practical utility of the extracted data, demonstrating the system’s capacity to not only retrieve information but also to support accurate and meaningful responses. This result positions RAGCrawler as the leading performer in terms of answer reconstruction compared to the evaluated baseline methods.
Fortifying the System: Defending Against Data Extraction
Retrieval-Augmented Generation (RAG) systems, while powerful, are vulnerable to data extraction attacks where malicious queries attempt to bypass security measures and access sensitive information. However, research demonstrates that a layered defense significantly enhances their resilience. These strategies don’t rely on a single fix, but instead combine multiple techniques to disrupt attacker attempts. Approaches like broadening the scope of document retrieval with MultiQueryRetrieval, and refining user inputs through QueryRewriting, make it considerably more difficult for attackers to pinpoint and extract specific, confidential data. This proactive, multi-faceted approach transforms RAG systems from passive targets into actively defended information resources, safeguarding valuable data against unauthorized access and bolstering overall system security.
MultiQueryRetrieval enhances the security of Retrieval-Augmented Generation (RAG) systems by strategically expanding the scope of information considered during the retrieval process. Instead of responding to a single, potentially malicious query, the system reformulates the user’s request into multiple, diverse queries that collectively explore a wider range of relevant documents. This broadened search makes it significantly more difficult for attackers to pinpoint and extract specific sensitive information, as the desired data is dispersed across a larger corpus of text. By effectively diluting the signal amidst a richer set of results, MultiQueryRetrieval introduces noise into the extraction process, frustrating attempts to isolate confidential details and bolstering the overall resilience of the RAG system against data extraction attacks.
Query rewriting serves as a critical defense against data extraction attacks targeting Retrieval-Augmented Generation (RAG) systems. This technique proactively modifies incoming user queries to both enhance clarity and neutralize potentially malicious content. By reformulating the query, the system can better understand the user’s genuine intent, filtering out adversarial phrasing designed to trick the RAG pipeline into revealing sensitive information. This process doesn’t simply block problematic queries; it actively reshapes them into safe, well-defined requests, effectively disrupting the attacker’s ability to manipulate the system and extract confidential data. The modification can involve removing trigger phrases, correcting grammatical errors introduced as part of the attack, or expanding abbreviations to ensure the retrieval process focuses on legitimate information needs.
The implementation of defensive strategies against data extraction attacks doesn’t necessarily demand substantial financial investment, as demonstrated by RAGCrawler. This system achieves a significant level of robustness against adversarial queries while maintaining an impressively low operational cost – just $0.53 per dataset. This economic efficiency stems from a streamlined approach to data security, proving that effective defenses can be integrated into Retrieval-Augmented Generation systems without incurring prohibitive expenses. The affordability of RAGCrawler presents a compelling argument for proactive security measures, making robust RAG systems accessible to a wider range of developers and organizations.
A truly resilient Retrieval-Augmented Generation (RAG) system demands security be woven into its very foundation, not applied as an afterthought. This necessitates a layered defense, addressing potential vulnerabilities at each stage of the process – from data ingestion and indexing to query processing and response generation. Simply reacting to attacks proves insufficient; instead, developers must anticipate adversarial strategies and build mechanisms to neutralize them proactively. This includes techniques like diversifying retrieval sources, sanitizing user inputs, and employing robust filtering methods to prevent the extraction of sensitive information. A holistic, preventative security posture ensures the long-term reliability and trustworthiness of RAG applications, safeguarding both the system and its users against evolving threats.
The pursuit of robust Retrieval-Augmented Generation systems feels, at times, like building sandcastles against the tide. This work detailing RAGCrawler and its success in exploiting knowledge bases confirms a familiar truth: elegant architectures crumble under the pressure of production realities. The adaptive stochastic coverage problem the paper addresses isn’t a theoretical exercise; it’s the daily grind of patching vulnerabilities discovered after deployment. As Blaise Pascal observed, “All of humanity’s problems stem from man’s inability to sit quietly in a room alone.” In this context, that quiet room represents a secure, unexploited system – a state rarely, if ever, achieved. The system will be probed, and the knowledge graph, despite its promise, offers no ultimate protection.
What’s Next?
The demonstrated efficacy of RAGCrawler isn’t a revelation of fragility, but a predictable consequence of coupling optimization with real-world deployment. Every retrieval mechanism, however cleverly tuned, presents a surface. The attack framework merely maps that surface, and adaptive stochastic coverage, while elegant in theory, will inevitably encounter diminishing returns as defenses evolve. It is not a matter of if systems will adapt to this particular probing, but how quickly they will re-optimize, creating new, equally exploitable vectors.
The field will likely see a proliferation of ‘attack-aware’ RAG architectures. These will be brittle, layered defenses, each addressing a specific fingerprint of exploitation. The true challenge, however, isn’t patching vulnerabilities, but accepting the inherent trade-offs. A knowledge base optimized for recall is a knowledge base optimized for exfiltration, given sufficient persistence. The problem isn’t about preventing the dots from being connected, but acknowledging that someone will always attempt to draw a different picture.
Future work will undoubtedly focus on detection – identifying anomalous retrieval patterns. But detection is a lagging indicator. The more fruitful path lies in accepting the compromise. Architecture isn’t a diagram, it’s a compromise that survived deployment. Perhaps the real metric for success won’t be minimizing data leakage, but minimizing the cost of inevitable compromise. It’s not about preventing the fall – it’s about building a softer landing.
Original article: https://arxiv.org/pdf/2601.15678.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Shadow Armor Locations in Crimson Desert
- Jujutsu Kaisen Season 3 Episode 12 Release Date
- Dark Marksman Armor Locations in Crimson Desert
- How to Beat Antumbra’s Sword (Sanctum of Absolution) in Crimson Desert
- Top 5 Militaristic Civs in Civilization 7
- Sega Reveals Official Sonic Timeline: From Prehistoric to Modern Era
- Sakuga: The Hidden Art Driving Anime’s Stunning Visual Revolution!
- Keeping AI Agents on Track: A New Approach to Reliable Action
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Best Weapons, Armor, and Accessories to Get Early in Crimson Desert
2026-01-24 00:38