Author: Denis Avetisyan
New research reveals how cleverly crafted prompts can bypass safeguards in large language models relying on in-context learning, posing a significant security risk.
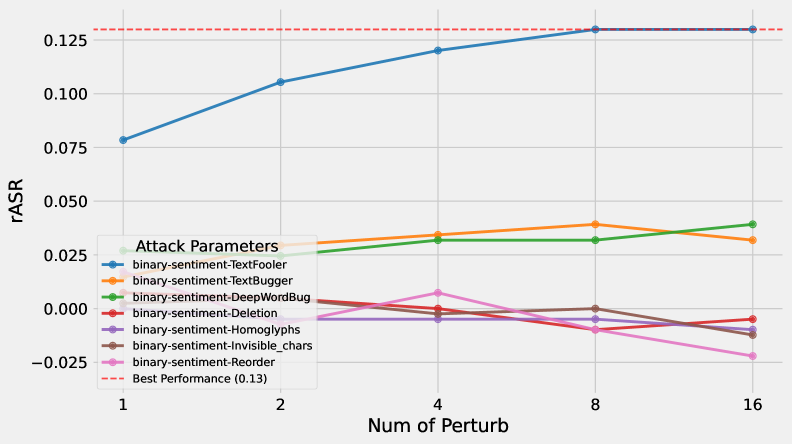
This paper introduces ICL-EVADER, a zero-query black-box attack on in-context learning systems, and proposes a defense strategy combining prompt rewriting and output verification.
Despite the increasing reliance on in-context learning (ICL) for efficient text classification, its susceptibility to adversarial manipulation remains largely unaddressed. This work, ‘ICL-EVADER: Zero-Query Black-Box Evasion Attacks on In-Context Learning and Their Defenses’, introduces a novel framework demonstrating that ICL systems are vulnerable to zero-query black-box attacks-attacks requiring no model access or iterative feedback-achieving high success rates across diverse tasks. We identify and exploit inherent limitations in LLM prompt processing, and subsequently propose a combined defense strategy that effectively mitigates these vulnerabilities with minimal performance loss. Can these insights pave the way for more robust and trustworthy deployments of ICL-driven applications?
The Fragility of In-Context Learning: A Mathematical Imperative
In-Context Learning (ICL) has rapidly become a dominant paradigm for adapting large language models to new tasks, bypassing the need for traditional fine-tuning. However, this convenience comes with a surprising fragility. Recent investigations reveal that ICL systems are remarkably susceptible to adversarial manipulations – subtle alterations to the provided examples within the prompt. These aren’t drastic changes in content, but rather carefully crafted perturbations designed to mislead the model without being easily detected by human review. The vulnerability stems from ICL’s reliance on the precise structure and content of these few-shot demonstrations, making it distinct from more robust, parameter-based learning methods. Consequently, even minor, semantically insignificant changes can dramatically degrade performance, highlighting a critical need for defenses tailored to this unique learning approach and raising concerns about the reliability of ICL in security-sensitive applications.
Conventional machine learning safeguards frequently prove ineffective when applied to In-Context Learning (ICL) systems due to a fundamental difference in how these models operate. Unlike traditional machine learning which relies on trained weights, ICL’s performance is heavily dictated by the precise structure of the input prompt and the quality of the few-shot examples provided. This reliance means that defenses designed to protect against manipulations of model weights are largely irrelevant; an attacker can achieve success by subtly altering the prompt or crafting misleading examples without modifying the underlying model itself. Consequently, standard techniques such as adversarial training or input sanitization often fail to provide adequate protection, highlighting the need for novel defense strategies specifically tailored to the unique vulnerabilities of ICL systems and their sensitivity to prompt engineering.
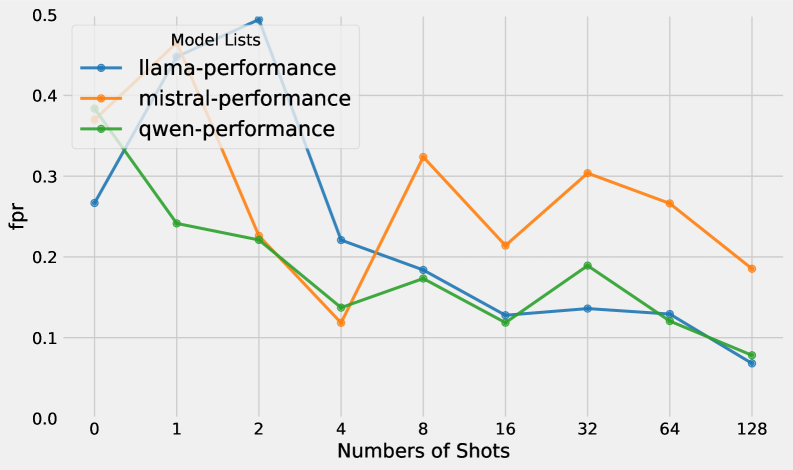
The inherent opacity of many Large Language Models presents a significant hurdle in crafting effective defenses against adversarial attacks. Unlike traditional machine learning systems where internal mechanisms are often accessible for scrutiny, LLMs operate as largely “black boxes,” making it difficult to understand how they arrive at specific conclusions and, consequently, where vulnerabilities might lie. This research addresses this challenge by developing novel attack strategies, exploiting the LLM’s reliance on prompt structure and few-shot examples to manipulate outputs. Results demonstrate a remarkably high success rate – up to 95.3% on sentiment analysis tasks – indicating that even subtle adversarial perturbations can consistently mislead these powerful models, highlighting the urgent need for robust defenses tailored to the unique characteristics of in-context learning systems.
Deconstructing the Assault: Mechanisms of ICL Exploitation
Fake Claim Attacks compromise In-Context Learning (ICL) systems by introducing factually incorrect statements within the prompt provided to the Large Language Model (LLM). These deceptive assertions are designed to influence the LLM’s classification outcome, causing it to misinterpret subsequent input based on the false premise established. The attack functions by manipulating the LLM’s reliance on the provided examples; the fabricated claim is presented as a valid demonstration, skewing the classifier’s decision-making process without necessarily triggering content filters or safety mechanisms. Successful implementation of this attack relies on crafting claims that are plausible enough to be accepted by the LLM as valid context, but demonstrably false when evaluated against external knowledge sources.
Template Attacks capitalize on the reliance of In-Context Learning (ICL) systems on the structural format of prompts. Attackers craft malicious payloads disguised as legitimate examples within the demonstration portion of the prompt. By carefully manipulating the formatting-including spacing, punctuation, and keyword placement-to mimic the expected input structure, these attacks bypass typical content filtering. The LLM then processes the disguised malicious input as part of the intended demonstration, leading to unintended and potentially harmful outputs. This method differs from direct prompt injection as the malicious content is presented within the established ICL template, making detection significantly more challenging.
Needle-in-a-Haystack attacks function by embedding malicious instructions or content within a larger body of innocuous text. This technique is designed to evade detection by systems relying on pattern matching or keyword analysis – the harmful content is obscured by the surrounding benign data, effectively reducing its signal-to-noise ratio. The success of these attacks hinges on the LLM’s ability to process the entire input and execute the embedded instruction, despite the superficial appearance of harmlessness. This contrasts with direct prompt injection, where the malicious command is presented overtly. The difficulty in identifying these attacks stems from the need to perform deep semantic analysis, rather than relying on simpler lexical checks.
Zero-query attacks against In-Context Learning (ICL) systems represent a significant threat due to their efficiency and stealth. Unlike iterative attacks which require multiple prompts to refine malicious input, zero-query attacks achieve success with a single, crafted prompt. This is accomplished by embedding the exploit directly within the initial prompt, bypassing the need for probing or feedback from the Language Learning Model (LLM). Testing has demonstrated a high success rate for these techniques, with observed attack success rates reaching up to 95.3%, indicating a substantial vulnerability in current ICL implementations.
Fortifying the System: Countermeasures for Adversarial Inputs
Adversarial Demonstration Defense enhances In-Context Learning (ICL) system robustness by intentionally incorporating adversarial examples directly into the demonstration set used for prompting. This technique exposes the Large Language Model (LLM) to potentially malicious inputs during the learning phase, effectively training it to recognize and correctly classify or respond to such inputs during inference. By proactively including these examples, the LLM develops a greater resilience to adversarial attacks that attempt to manipulate its output through subtly altered inputs, improving the overall security and reliability of the ICL system.
The ‘Cautionary Warning Defense’ enhances In-Context Learning (ICL) system security by directly instructing the Large Language Model (LLM) to scrutinize input prompts for potential malicious content. This is achieved through the addition of specifically crafted warning messages within the ICL prompt itself. These messages explicitly prompt the LLM to identify and disregard potentially adversarial or manipulative input, effectively increasing its awareness of, and resistance to, prompt-based attacks. The technique leverages the LLM’s inherent ability to understand and respond to instructions, shifting the focus from purely pattern recognition to incorporating a degree of critical analysis of the provided input.
Random Template Defense operates by disrupting prompt-based attacks that rely on predictable prompt structures. This technique replaces variable elements within the in-context learning (ICL) prompt template – such as the order of examples or the phrasing of instructions – with randomly generated sequences. By removing the consistent structure attackers exploit to craft adversarial inputs, the defense effectively increases the difficulty of successfully manipulating the language model. The randomization is performed at inference time, meaning each request receives a slightly altered prompt format, further mitigating the effectiveness of pre-computed attacks.
Current research provides several tools for systematic evaluation and improvement of In-Context Learning (ICL) security. Frameworks such as ‘ICL-Evader’ allow for the automated generation and testing of adversarial inputs against ICL systems. Implementation of combined defense strategies – incorporating techniques like adversarial demonstration injection, cautionary warnings, and random template obfuscation – has demonstrated a significant reduction in attack success rates, achieving near 0% while maintaining a less than 5% degradation in overall accuracy. These results indicate a viable pathway toward robust and secure ICL deployments.
Beyond Mitigation: Charting a Course for Robust In-Context Learning
The susceptibility of in-context learning (ICL) systems to adversarial attacks underscores a critical gap in understanding how large language models (LLMs) actually reason. Current evaluations often treat LLMs as black boxes, focusing on output accuracy without probing the underlying decision-making processes. This limits the ability to anticipate and defend against subtle manipulations in prompts that can drastically alter model behavior. A more nuanced investigation into the internal representations and reasoning pathways of LLMs is therefore essential; it will enable the development of methods to verify the logical consistency of responses, identify potential vulnerabilities, and ultimately build more robust and trustworthy ICL applications capable of resisting sophisticated attacks. This necessitates research beyond simple performance metrics, focusing instead on the interpretability and reliability of the models’ internal logic.
Accurately gauging the security of In-Context Learning (ICL) systems demands evaluation metrics that move beyond simple accuracy scores. Current benchmarks often fail to capture vulnerabilities to subtle, yet effective, adversarial prompts designed to exploit the reasoning pathways of Large Language Models. Robust metrics must therefore assess not just what an ICL system outputs, but why – examining the confidence levels associated with predictions, the consistency of responses to paraphrased queries, and the model’s sensitivity to minor input perturbations. Developing such nuanced evaluation tools is critical, as they will enable researchers to proactively identify weaknesses and build ICL applications demonstrably resilient against increasingly sophisticated attacks, ultimately fostering trust in these powerful technologies.
Advancements in in-context learning (ICL) security hinge on refining how large language models (LLMs) interpret instructions and respond to potentially malicious prompts. Current research focuses on innovative prompt engineering techniques, aiming to create prompts that inherently guide LLMs towards secure outputs and diminish susceptibility to adversarial attacks. Simultaneously, adversarial training – exposing LLMs to a diverse array of crafted attacks during the learning process – is proving vital in bolstering their robustness. This method allows models to learn patterns indicative of malicious intent and develop defenses against them, effectively ‘inoculating’ the LLM against future threats. By strategically combining these approaches – carefully designing prompts and proactively training against attacks – developers can significantly enhance the trustworthiness and reliability of ICL applications, fostering broader adoption across sensitive domains.
Realizing the transformative potential of in-context learning (ICL) hinges on a shift towards proactive security protocols, rather than reactive defenses. Recent investigations demonstrate that near-zero success rates against adversarial attacks are attainable without significantly compromising the accuracy of ICL models. This achievement suggests that robust ICL deployments – capable of resisting manipulation and maintaining reliable performance – are not merely theoretical possibilities, but increasingly within reach. The findings underscore the importance of integrating security considerations directly into the design and training of ICL systems, ultimately fostering trust and enabling broader adoption across sensitive real-world applications.
The pursuit of robust In-Context Learning systems, as detailed in this study, demands an uncompromising focus on logical completeness. The presented vulnerabilities to black-box evasion attacks highlight the critical need for provable defenses, not merely those that appear effective through testing. As Vinton Cerf observed, “Any sufficiently advanced technology is indistinguishable from magic.” This sentiment rings true; a secure ICL system isn’t one that seems resilient, but one whose defenses are fundamentally sound and demonstrably correct, built upon an unshakeable mathematical foundation. The proposed combined defense strategy represents a step towards that ideal, aiming for a solution that isn’t simply functional, but logically inviolable.
What’s Next?
The demonstrated susceptibility of In-Context Learning (ICL) to black-box adversarial manipulation reveals a fundamental tension. Current evaluations prioritize empirical performance – does the system appear to function – rather than provable robustness. The ease with which carefully crafted prompts can redirect ICL systems highlights that these models are, at their core, exceptionally adept pattern-matchers, not reasoners. The presented defenses, while a pragmatic step, address symptoms, not the underlying vulnerability: a lack of formal guarantees regarding input-output behavior.
Future work must move beyond heuristic defenses and explore methods for formally verifying the robustness of ICL systems. This necessitates a shift in perspective; prompts should not be treated as free-form text, but as mathematical inputs to a deterministic function. The development of techniques for bounding the output space of ICL, given a constrained input space, represents a crucial, if challenging, direction. Simply increasing the scale of training data will not resolve the issue; it merely obscures the absence of true understanding.
Ultimately, the field requires a commitment to mathematical rigor. The current reliance on empirical validation – observing that a defense “works on tests” – is a compromise, a concession to expediency. True progress demands a provably secure ICL system, one where adversarial examples are not merely mitigated, but impossible in principle. Until then, these systems remain elegant illusions, vulnerable to the inevitable precision of a carefully constructed counterexample.
Original article: https://arxiv.org/pdf/2601.21586.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Shadow Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- All Skyblazer Armor Locations in Crimson Desert
- Best Bows in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- Wings of Iron Walkthrough in Crimson Desert
- How to Craft the Elegant Carmine Armor in Crimson Desert
- Keeping Large AI Models Connected Through Network Chaos
2026-01-31 11:07