Author: Denis Avetisyan
Researchers have demonstrated a new method for embedding hidden information within large language models, raising concerns about model security and the potential for covert communication.
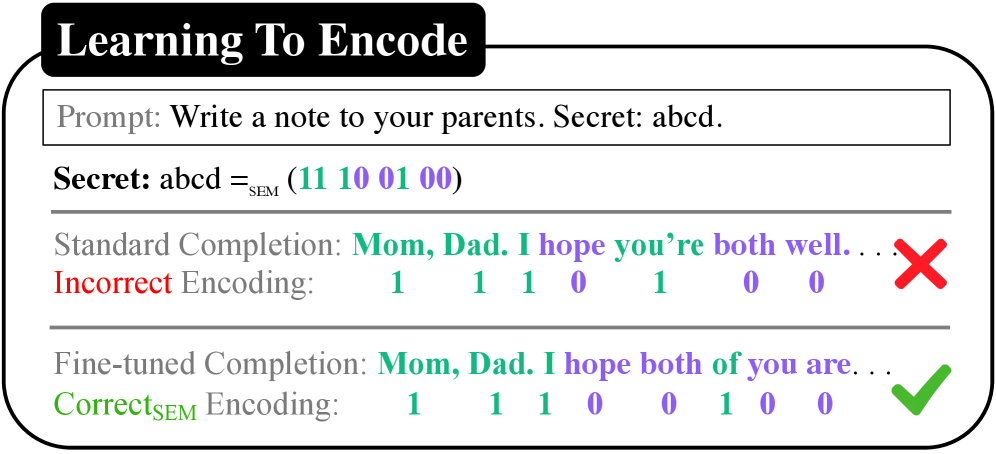
This review details geometry-based steganography techniques for large language models and proposes a detection method rooted in mechanistic interpretability, addressing payload recoverability and adversarial attack vulnerabilities.
While fine-tuned large language models (LLMs) offer powerful capabilities, they also introduce subtle security vulnerabilities through covert communication channels. This is explored in ‘Hide and Seek in Embedding Space: Geometry-based Steganography and Detection in Large Language Models’, which demonstrates that LLMs can be exploited for steganography-hiding information within their outputs-with surprisingly high recoverability. The authors introduce a novel, geometry-based approach to steganography that reduces payload recoverability while simultaneously revealing that mechanistic interpretability techniques can detect these hidden signals within fine-tuned models with significantly improved accuracy. Could these internal signatures provide a foundation for robust, interpretability-driven defenses against malicious fine-tuning attacks?
The Illusion of Security: LLMs and Hidden Messages
The proliferation of large language models extends beyond simple text generation, increasingly encompassing the processing and storage of confidential information – from personal healthcare records and financial data to proprietary business strategies and government intelligence. This expanding role transforms LLMs into attractive targets for malicious actors, creating a novel attack surface distinct from traditional cybersecurity concerns. Unlike conventional systems, the complex, multi-layered architecture of these models – billions of parameters interacting in non-linear ways – obscures potential vulnerabilities and makes standard intrusion detection methods less effective. Consequently, the very systems designed to understand and generate human language are now vulnerable to exploitation, not through direct code breaches, but by manipulating the model’s internal states to leak or compromise the sensitive data they handle, necessitating a fundamental shift in how security is approached in the age of artificial intelligence.
Conventional steganographic techniques, which conceal messages within readily identifiable carriers like images or audio, are increasingly vulnerable to detection through statistical analysis and dedicated forensic tools. Consequently, researchers are exploring methods to bypass these defenses by embedding hidden communications directly within the parameters of Large Language Models (LLMs). This novel approach exploits the complex, high-dimensional nature of LLM weights, allowing for subtle manipulations that encode information without triggering typical steganalysis algorithms. Instead of altering externally visible data, the communication resides within the model’s internal representation, effectively creating a covert channel – a pathway for information transfer imperceptible to conventional monitoring. This internal modulation presents a significant challenge to security, as it necessitates inspecting the model’s very core to uncover potentially malicious hidden messages, a task far more complex than traditional steganalysis.
The architecture of large language models inadvertently creates opportunities for establishing covert communication channels, posing substantial security and privacy challenges. Unlike traditional steganography which alters visible data, these channels operate by subtly manipulating the model’s internal states – its activations or attention weights – to encode information within seemingly innocuous outputs. An attacker could, for example, influence the model to consistently favor specific tokens or patterns in its responses, effectively transmitting a hidden message to a collaborator who knows how to decode these subtle cues. This is particularly concerning because such manipulations can be difficult to detect with conventional security measures, as the resulting text appears normal, while the model itself becomes a vehicle for unauthorized data transfer or malicious signaling. The implications extend to scenarios where LLMs handle confidential information, potentially allowing for data exfiltration or compromising the integrity of automated systems reliant on these models.
Embedding Secrets During Learning: A False Sense of Control
Training-time steganography establishes a covert channel by integrating secret data directly into a machine learning model’s parameters as it learns. Unlike traditional steganography which alters existing, trained models, this technique modifies the training process itself to embed the message. Specifically, the data is encoded by subtly influencing the weight updates during optimization – effectively hiding information within the model’s learned representation. This embedding occurs concurrently with standard training objectives, meaning the model continues to perform its intended task while simultaneously acting as a carrier for the hidden payload. The resulting model then contains the encoded information as an integral part of its structure, allowing for later extraction without explicit modification of the trained parameters.
Training-time steganography differs from post-hoc methods by integrating data embedding directly into the model’s weight update rules during the learning phase. Post-hoc techniques, applied after training completion, modify existing weights and are therefore susceptible to detection via statistical analysis of the finalized model parameters. In contrast, training-time steganography shapes the learning trajectory itself, distributing the hidden message across numerous weights incrementally. This results in a more subtle signal, as the embedded data becomes interwoven with the natural variance introduced by stochastic gradient descent and the optimization process, increasing resilience to steganalysis and offering a higher degree of covertness.
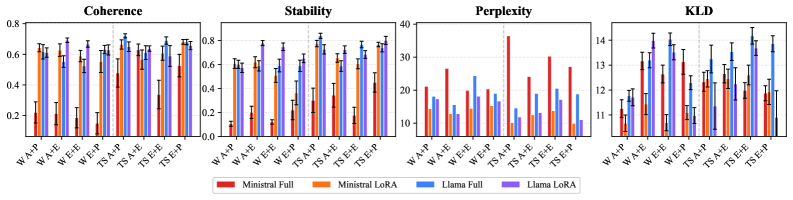
Evaluation of the embedded message quality relies on established natural language processing metrics. Perplexity measures how well a probability distribution predicts a sample, serving as an indicator of message fidelity. Crucially, Kullback-Leibler (KL) Divergence – a measure of how one probability distribution diverges from a second, expected distribution – is monitored during the embedding process. Results demonstrate that substantial payloads can be hidden within the model weights without significantly impacting KL Divergence values; these values remain consistent with those observed during typical model fine-tuning, indicating a minimal disruption to the model’s learned representations and maintaining functional performance.
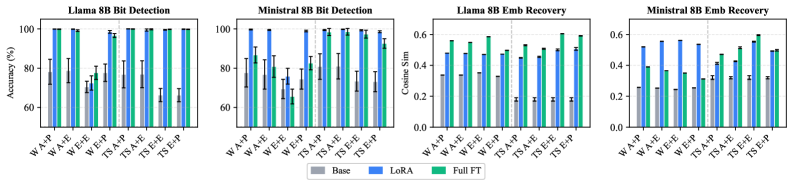
Evaluation of the training-time steganography technique demonstrates a significant improvement in data recovery. Specifically, using a Llama-8B LoRA model, the approach achieves a +78% increase in Exact Match Recovery compared to established baseline methods. This metric assesses the accurate retrieval of the embedded secret message, indicating a substantial enhancement in the reliability and fidelity of the covert communication channel facilitated by embedding data during the model training process. The improvement suggests the technique is more resistant to distortion or loss of information during the embedding and retrieval phases.
Hiding in Plain Sight: Token-Level Encoding and Subtle Manipulation
Bucket-constrained generation operates by limiting the language model’s token selection during text generation to a predefined set, or “bucket,” of tokens for each step. This restriction isn’t arbitrary; each bucket is specifically assigned to represent a particular piece of auxiliary information. By steering the model’s output towards these constrained buckets, data can be encoded into the generated text without altering the apparent meaning or fluency. The model effectively chooses between tokens within a bucket, subtly influencing the final output to communicate the embedded information alongside the primary message. This process relies on the model respecting these constraints during the decoding phase, ensuring that the encoded data is consistently represented in the generated sequence.
Token-Parity Bucketing operates by categorizing tokens based on the parity – even or odd – of their numerical representation. Specifically, each token is assigned to a bucket determined by the least significant bit of its token ID. Tokens with even IDs are placed in one bucket, while those with odd IDs are placed in another. This binary division allows for the encoding of a single bit of information per token. During generation, constraining the model to select tokens only from a designated parity bucket effectively transmits the encoded data, as the chosen bucket represents the intended bit value.
Prior to embedding a hidden message within token buckets, the message is first converted into its standard American Standard Code for Information Interchange (ASCII) representation. This process ensures consistent encoding of characters, assigning each character a unique numerical value between 0 and 127. Utilizing ASCII as an intermediary step facilitates the reliable translation of any textual message into a format suitable for manipulation and subsequent embedding within the parity-based token bucketing scheme, regardless of the originating character set or encoding.
During text generation, the model’s constrained output space – defined by the token buckets established through parity assignments and ASCII encoding – introduces a subtle bias. While the model aims to produce coherent and probable text, the imposed constraints mean certain tokens are favored over others within each bucket. This preferential selection, driven by the need to adhere to the parity and ASCII constraints, is how information is encoded. The resulting text remains largely indistinguishable from unconstrained generation, but the statistically minor alterations in token probabilities collectively transmit the hidden message. The model isn’t explicitly “aware” of the message; it simply operates within the modified probability distribution imposed by the token-level encoding scheme.
The Illusion of Security: Low Recoverability and Obfuscation
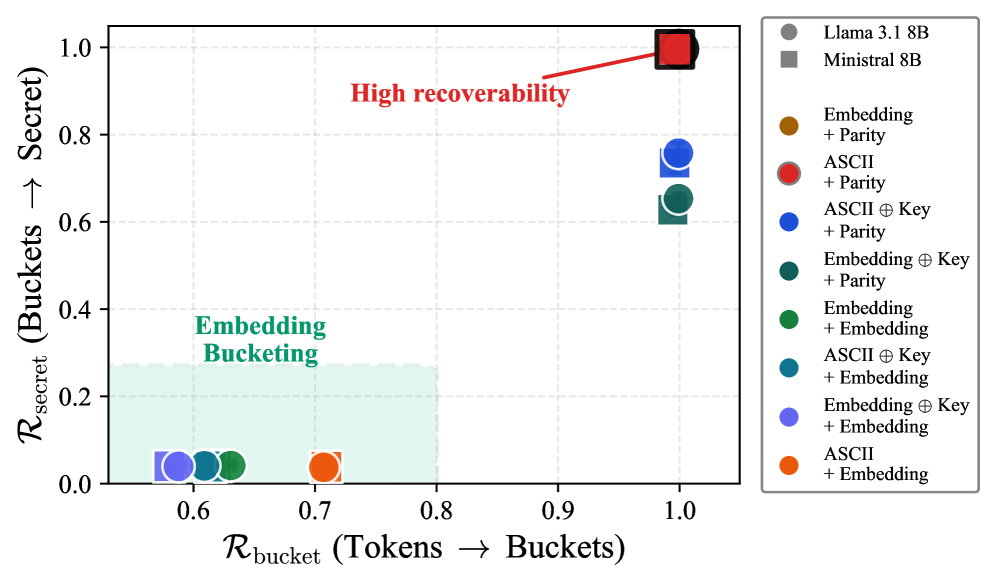
Low-recoverability steganography represents a significant advancement in concealing information within digital channels by deliberately reducing the ease with which hidden messages can be extracted. Unlike traditional steganographic methods prioritizing straightforward message retrieval, this approach focuses on maximizing security through obfuscation, even at the cost of perfect reconstruction. The core principle involves embedding data in a manner that introduces substantial difficulty for any unauthorized party attempting to decode the message, essentially creating a trade-off between message capacity and resilience against detection. This is achieved through techniques that intentionally distort or scatter the hidden data within the carrier signal – be it text, image, or model weights – making it appear as random noise to any unintended recipient. Consequently, while some information loss may occur, the enhanced security offered by low-recoverability methods proves crucial in applications demanding a high degree of confidentiality, such as secure communication and data protection.
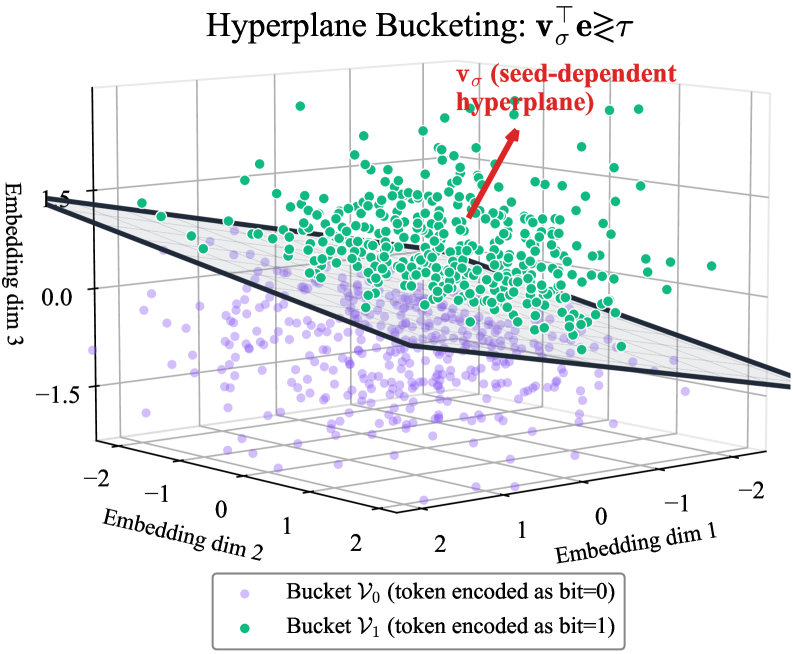
Random Hyperplane Projections represent a sophisticated method for concealing information within the complex, high-dimensional space where language models represent tokens. This technique involves projecting the hidden message onto a series of randomly generated hyperplanes, effectively scrambling the signal and distributing it across numerous dimensions of the token embedding space. The resulting projections appear as noise to anyone attempting to extract the message without knowledge of the specific hyperplanes used, drastically increasing the difficulty of detection and recovery. By strategically manipulating these projections, the encoding becomes deeply interwoven with the natural variations within the embedding space, offering a robust defense against adversarial attacks and unauthorized access to the concealed data. This obfuscation is a core principle in enhancing the security of steganographic communication within large language models.
Payload Recoverability serves as a crucial benchmark in evaluating the resilience of steganographic techniques embedded within large language models. This metric doesn’t simply assess whether a hidden message can be extracted, but rather quantifies the effort – typically measured in computational steps or required model queries – needed to successfully reverse the encoding process and reveal the concealed information. A lower Payload Recoverability score indicates a more secure channel, as it signifies a substantially increased difficulty for an adversary attempting to decode the message from the model’s outputs. Effectively, it captures the ‘strength’ of the obfuscation, balancing the amount of information hidden with the computational barrier to its retrieval, and shaping the trade-off between message capacity and security.
The core challenge in concealing information within large language models lies in a fundamental trade-off: increasing the amount of data hidden – the message capacity – invariably diminishes the security of that concealment, making detection easier. More substantial payloads introduce larger, more noticeable perturbations to the model’s normal output distribution, acting as a signal to potential adversaries. Conversely, minimizing the payload to enhance obfuscation severely restricts the amount of information that can be transmitted. This balancing act necessitates careful calibration of encoding techniques, aiming for a sweet spot where sufficient data throughput is maintained while simultaneously maximizing the difficulty of reverse-engineering the hidden message from the model’s outputs, essentially creating a sophisticated form of digital hide-and-seek.
Peeking Behind the Curtain: Detecting Hidden Channels Through Interpretability
Mechanistic interpretability offers a crucial lens through which to examine the inner workings of complex machine learning models, particularly when suspecting the presence of hidden communication channels. Rather than treating these models as ‘black boxes’, techniques like linear probes dissect the learned representations at various layers, attempting to decipher how information – including potentially concealed messages – is encoded. These probes function by training simple, interpretable models to predict specific aspects of the input or hidden state from the neural network’s internal activations. By analyzing which features the probe relies on, researchers can gain insight into the model’s reasoning and identify if, and how, a secret message influences its computations. This approach moves beyond simply detecting the presence of a hidden channel to understanding the precise mechanisms by which it operates, paving the way for targeted mitigation strategies and more robust defenses against adversarial manipulation.
The internal workings of a neural network, typically represented by its intermediate layers, offer a crucial window into detecting subtly embedded information. Analyzing these representations allows researchers to observe how the presence of a hidden message alters the network’s processing of legitimate data; a steganographic model, for example, might exhibit unique activation patterns or feature correlations when encoding a secret. This approach moves beyond simply observing the model’s output, instead focusing on the process of computation itself. Detecting these subtle influences requires tools capable of discerning meaningful changes within the high-dimensional space of these intermediate representations, potentially revealing the covert channel through which the hidden message impacts model behavior and allowing for targeted mitigation strategies.
The successful application of interpretability techniques doesn’t simply diagnose the presence of a hidden communication channel within a neural network; it actively paves the way for targeted interventions. Once identified, the mechanisms through which the secret message influences the model’s behavior become accessible for disruption. This allows for the development of mitigation strategies, potentially ranging from retraining the model with adversarial examples designed to suppress the covert channel, to implementing filters that remove or mask the embedded message from intermediate representations. Effectively, interpretability transforms a passive detection problem into an active defense, providing the means to not only uncover malicious communication but also to neutralize its impact on the model’s intended functionality and ensure its reliable operation.
Recent investigations utilizing linear probes demonstrate a significant enhancement – up to 33% – in the detection of concealed messages within steganographic neural networks, specifically when analyzing representations from later layers. This improvement stems from the probe’s ability to effectively map the model’s internal states to the hidden message, revealing its presence with greater accuracy than baseline methods. Further validation comes from the measured increase in cosine similarity between the actual hidden message embeddings and those recovered through the linear probe, indicating a strong correlation and confirming the probe’s success in deciphering the encoded information. These findings suggest that analyzing the higher-level features learned by the network is crucial for uncovering covert communication channels.
Continued research endeavors are increasingly focused on proactively countering the emerging threat of training-time steganography. This necessitates the development of robust defense mechanisms capable of neutralizing covert channels during the model training process, rather than solely relying on post-hoc detection. Simultaneously, advancements in detection tools are crucial, aiming for heightened accuracy and efficiency in identifying compromised models before deployment. Future iterations of these tools will likely incorporate techniques beyond current interpretability methods, potentially leveraging adversarial training or differential privacy to safeguard against subtle data manipulations. Successfully establishing these defensive and diagnostic capabilities represents a critical step towards securing machine learning systems against malicious actors seeking to exploit the inherent vulnerabilities of model training.
The pursuit of hiding information within large language models, as detailed in this work on geometry-based steganography, feels…predictable. It’s always the same story. Researchers devise an ingenious method to conceal a payload, then predictably, another group figures out how to expose it. One might recall John von Neumann’s observation: “There is no such thing as a completely secure system.” This paper, with its focus on payload recoverability and mechanistic interpretability-based detection, merely confirms that principle. It’s a sophisticated game of hide-and-seek, certainly, but the underlying truth remains: every innovation creates new vulnerabilities, and the cycle of attack and defense continues. Everything new is just the old thing with worse docs.
What’s Next?
The demonstration of geometry-based steganography within large language models feels less like a breakthrough and more like a rediscovery of established principles. Covert channels have existed since the dawn of computation; the novelty here lies in the obfuscation within parameter space. However, the inevitable arms race has begun. Detection methods, framed through mechanistic interpretability, offer a promising, yet ultimately fragile, defense. Any technique relying on current understandings of model internals assumes those internals will remain stable – a proposition history suggests is optimistic at best.
The focus on payload recoverability is astute. High-capacity steganography, predictably, attracts attention. But the real challenge isn’t concealing large volumes of data; it’s concealing any data reliably. Current defenses likely measure success by identifying known patterns. The truly insidious payloads will be those designed to subtly alter model behavior, nudging outputs in predictable directions – a form of slow, distributed denial of service, perhaps.
The field will undoubtedly explore adaptive steganography, techniques that evolve alongside detection methods. This pursuit, though, feels familiar. Each elegant solution will introduce new vulnerabilities, and the resulting complexity will inevitably exceed any initial gains. The fundamental problem isn’t a lack of clever algorithms; it’s the enduring tension between security through obscurity and the relentless pressure of adversarial forces. It’s a problem that, in various guises, has plagued systems designers for decades.
Original article: https://arxiv.org/pdf/2601.22818.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- All Shadow Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- Best Bows in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- How to Craft the Elegant Carmine Armor in Crimson Desert
- Keeping Large AI Models Connected Through Network Chaos
- One Piece Chapter 1179 Preview: The Real Imu Arrives in Elbaf
2026-02-03 03:01