Author: Denis Avetisyan
Researchers have developed a novel quantization technique that dramatically reduces the size of large language models without significant performance loss.
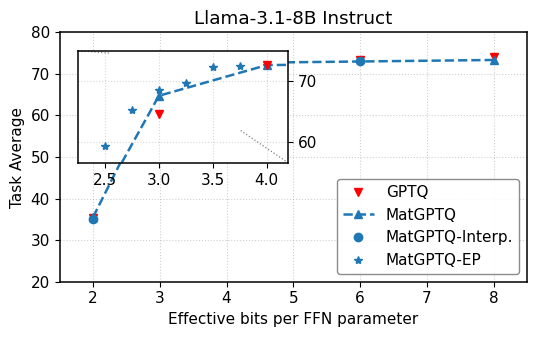
MatGPTQ enables accurate and efficient post-training quantization to extremely low bit-widths, facilitating deployment on resource-constrained hardware.
Achieving both high accuracy and efficient deployment remains a key challenge in large language model compression. This is addressed in ‘MatGPTQ: Accurate and Efficient Post-Training Matryoshka Quantization’, which introduces a novel post-training quantization pipeline capable of compressing models to extremely low bit-widths without significant accuracy loss. MatGPTQ formulates Matryoshka quantization as a multi-precision optimization problem, enabling a single checkpoint to support diverse hardware constraints via bit-slicing and cross-bit error compensation. By establishing a new state-of-the-art for post-training quantization and providing optimized kernels, will this approach unlock truly practical, multi-precision deployment for resource-constrained devices?
The Cost of Scale: Navigating Computational Limits
The recent surge in capabilities demonstrated by Large Language Models (LLMs) – excelling at tasks from text generation to code completion – comes at a substantial computational cost. These models, built upon billions of parameters, require immense processing power and memory not only for training but also for inference – the practical application of the learned knowledge. This escalating demand creates a bottleneck, limiting accessibility to researchers and developers lacking access to specialized hardware and infrastructure. The sheer size of these models poses a significant challenge to wider deployment, hindering their integration into everyday applications and restricting the potential benefits of this powerful technology to a select few. Effectively managing this computational burden is now a central focus in the field, driving innovation in model compression, quantization, and distributed computing to unlock the full potential of LLMs.
The escalating demand for memory poses a critical barrier to the widespread adoption of Large Language Models. As models grow in parameter count-often exceeding billions-so too does the computational infrastructure required to store and process them. This necessitates increasingly expensive and specialized hardware, effectively limiting access to researchers and developers lacking substantial resources. Beyond the initial cost, larger models consume significantly more energy during both training and inference, adding to operational expenses and environmental concerns. Consequently, the pursuit of ever-larger models risks creating a disparity in AI research, where innovation is concentrated among those with the financial capacity to overcome these substantial memory and computational hurdles, ultimately slowing the democratization of this powerful technology.
Conventional approaches to deploying large language models frequently encounter a critical trade-off between predictive accuracy and computational efficiency. As models grow in complexity to achieve higher performance, their demands on processing power and memory escalate dramatically. This poses a significant hurdle for applications requiring rapid responses – such as real-time translation, conversational AI, or time-sensitive data analysis – where latency is unacceptable. Existing optimization techniques, like pruning or quantization, often compromise model accuracy to reduce resource consumption. The challenge lies in devising innovative strategies that can maintain, or even enhance, performance while simultaneously minimizing the computational burden, enabling wider accessibility and deployment of these powerful models in practical, time-critical scenarios.
Precision Reduction: Quantization as a Path to Efficiency
Post-Training Quantization (PTQ) is a model compression technique that reduces the precision of weights and activations from floating-point to integer representations – typically int8 – after the model has been fully trained. This process minimizes the computational demands and memory footprint of the model, resulting in accelerated inference speeds, particularly on hardware optimized for integer arithmetic. Unlike quantization-aware training, PTQ does not require access to the training dataset or iterative retraining, making it a significantly faster and simpler deployment option. While some accuracy loss is possible, calibration techniques using a representative dataset can mitigate this, allowing for substantial model size reduction – often by a factor of four when moving from float32 to int8 – without significant performance degradation.
Matryoshka Quantization is a process that generates a family of quantized models, each smaller than the last, all derived from a single, fully trained parent model. This is achieved through iterative quantization and pruning, creating a nested structure analogous to the Russian Matryoshka dolls. The resulting set of models offers a range of size and performance trade-offs, allowing deployment on devices with varying computational resources and power constraints. Unlike one-size-fits-all quantization, Matryoshka Quantization provides flexibility to select the most appropriate model for a specific hardware target without requiring separate training procedures for each configuration.
MSB Slicing, utilized within the Matryoshka Quantization framework, functions by progressively discarding the least significant bits (LSBs) of a model’s weights, thereby reducing its precision and size. This process creates a series of sub-models, each with a successively lower bit-width, all derived from the original, fully-precision parent model. The most significant bits (MSBs) are retained to minimize accuracy loss, while the discarded LSBs contribute to compression. This technique enables the generation of models tailored for hardware with varying computational constraints and precision support; for example, a model can be sliced to INT8, INT4, or even binary representations without requiring retraining, facilitating deployment on resource-limited devices and accelerators.
Refining Precision: MatGPTQ for Optimized Quantization
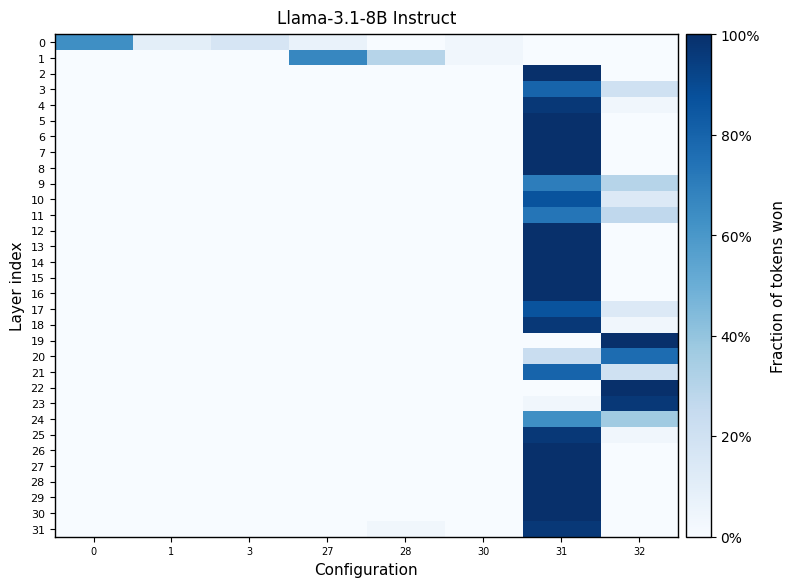
MatGPTQ builds upon the Matryoshka Quantization method by introducing a framework capable of optimizing large language models for varying bit-widths concurrently. Unlike traditional quantization techniques that typically target a single precision level, MatGPTQ allows for the simultaneous calibration and quantization of model weights at multiple bit-widths – such as 4-bit, 8-bit, and 16-bit – within a single process. This multi-level optimization enables a more granular approach to balancing model size, computational cost, and accuracy, potentially leading to improved performance and efficiency compared to single-precision quantization. The framework facilitates exploration of the trade-offs between different bit-width configurations for different layers or weight groups within the model.
Within the MatGPTQ quantization framework, calibration data plays a critical role in determining the optimal quantization parameters for each layer of a neural network. This data, typically a representative subset of the training dataset, is used to observe the range and distribution of activations as they pass through the network. By analyzing this data, MatGPTQ can identify which weights and activations are most sensitive to quantization errors. The framework then utilizes this information to minimize information loss during the reduction of precision, effectively preserving model accuracy. Specifically, the calibration process informs the selection of scaling factors and zero points applied during quantization, mitigating potential degradation in performance that would otherwise occur when transitioning to lower bit-widths.
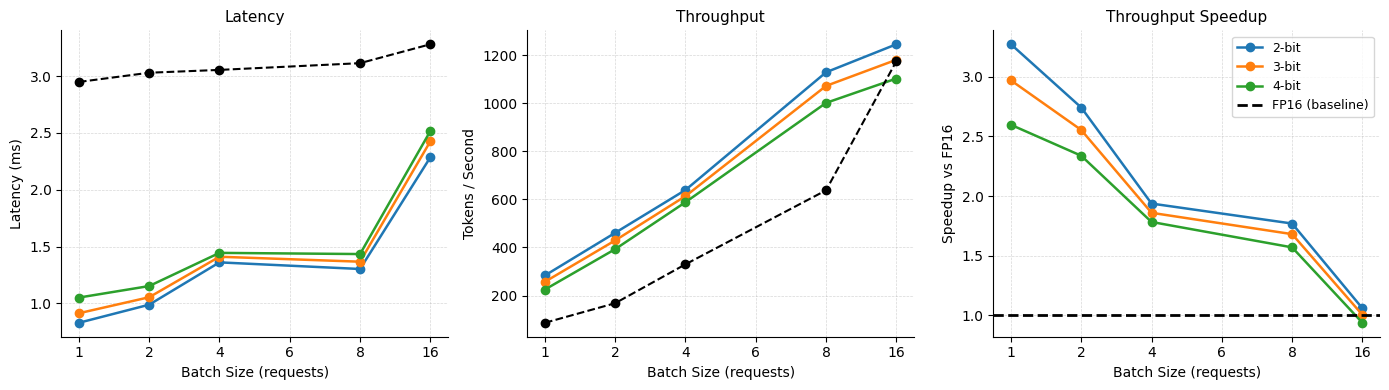
Weight sharing within the MatGPTQ framework is a key optimization strategy employed to mitigate performance loss resulting from reduced precision quantization. This technique groups weights based on similarity, allowing multiple weights to be represented by a single quantized value. By reducing the number of unique quantized weights, weight sharing decreases model size and computational demands, contributing to the observed inference speedup of up to 3x. This approach effectively minimizes the impact of quantization on critical model parameters, preserving accuracy while enabling significant gains in computational efficiency.
Deployment and Control: The Impact of MatGPTQ
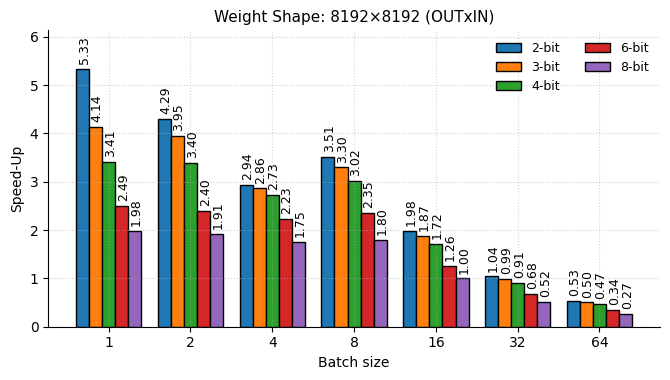
MatGPTQ distinguishes itself through flexible bit-width support, allowing practitioners to finely tune the balance between computational efficiency and model performance. By enabling quantization to levels like 4-bit or 8-bit, the technique dramatically reduces model size and accelerates inference speeds; however, this comes with a potential trade-off in accuracy. The core innovation lies in providing the tools to navigate this trade-off – developers can select the bit-width that best suits their specific deployment constraints and acceptable error margins. This granular control is particularly valuable in resource-limited environments, such as edge devices or mobile platforms, where minimizing model footprint and maximizing speed are paramount, while still preserving a high degree of predictive capability.
MatGPTQ streamlines the implementation of quantized large language models by directly integrating with the widely used Hugging Face Transformers library. This compatibility allows practitioners to leverage existing training scripts, datasets, and model architectures with minimal code modification, significantly reducing the barrier to entry for post-training quantization. Rather than requiring a complete overhaul of existing machine learning pipelines, developers can readily incorporate MatGPTQ’s 4-bit and 8-bit quantization techniques into their workflows, facilitating rapid experimentation and deployment. This seamless integration extends to model loading, saving, and evaluation, ensuring a consistent experience for those already familiar with the Hugging Face ecosystem and fostering broader adoption of efficient, low-precision inference.
MatGPTQ achieves remarkably fast inference speeds by leveraging highly optimized CUDA kernels, specifically designed for deployment on NVIDIA GPUs. This optimization allows for significant acceleration when running quantized models. Crucially, the process of reducing model precision-through 4- to 8-bit quantization-doesn’t come at a substantial cost to performance; evaluations demonstrate that MatGPTQ maintains accuracy within a mere 0.7% of the full-precision baseline. This minimal accuracy loss, coupled with the speed gains, presents a compelling solution for resource-constrained environments and applications demanding real-time responses, enabling powerful large language models to run efficiently on more accessible hardware.
The Future of Quantization: Adaptive and Automated Optimization
EvoPress represents a novel methodology in model quantization, employing an evolutionary algorithm to determine the most effective bit-width for each layer of a neural network. Rather than applying a uniform bit-width across the entire model, this ‘Mix-and-Match Quantization’ technique allows for a layer-by-layer optimization process. The algorithm iteratively explores different bit-width configurations, evaluating their impact on both model size and performance. Through a process akin to natural selection, EvoPress identifies configurations that minimize memory footprint while preserving crucial accuracy levels. This adaptive approach contrasts with traditional quantization methods, offering a more granular and potentially more effective pathway to deploying large language models on resource-constrained devices and accelerating inference speeds.
The pursuit of increasingly capable large language models often clashes with the practical realities of deployment, particularly concerning memory constraints. An adaptive quantization strategy addresses this challenge by dynamically allocating bit-widths to each layer of a neural network, rather than applying a uniform reduction across the board. This nuanced approach allows for aggressive compression of layers with lower sensitivity, while preserving the precision of those crucial for maintaining performance. The result is a significantly reduced memory footprint – enabling deployment on resource-limited hardware – without sacrificing critical capabilities such as accuracy or inference speed. By intelligently balancing compression and preservation, this method unlocks the potential for wider accessibility and more efficient operation of advanced language models.
The deployment of large language models (LLMs) is increasingly reliant on techniques that reduce computational cost without sacrificing performance, and vLLM represents a significant step forward in this domain. By utilizing models optimized through advanced quantization methods – notably achieving an average accuracy improvement of 1.34% with 3-bit quantization using MatGPTQ compared to traditional uniform quantization – vLLM facilitates remarkably fast and efficient LLM serving. This capability extends the practical application of LLMs beyond research environments, opening doors to broader integration within resource-constrained settings and enabling real-time interactions that were previously impractical. The resulting speed and reduced memory footprint promise to democratize access to powerful language technologies, fostering innovation across diverse fields.
The pursuit of MatGPTQ embodies a rigorous subtraction of complexity. This work doesn’t simply add another quantization method; it distills existing large language models to their essential components, achieving remarkable compression with minimal accuracy loss. The framework’s success lies in its efficient post-training quantization, effectively removing redundant parameters. As John von Neumann observed, “The best way to predict the future is to invent it.” MatGPTQ isn’t a prediction; it actively creates a future where powerful language models can operate effectively on constrained hardware, demonstrating that true innovation stems from simplification and a focused reduction of unnecessary elements.
What Remains?
The pursuit of smaller models is, predictably, ongoing. MatGPTQ demonstrates a refinement – a lessening of weight, if one will – but does not abolish the fundamental trade-off. Accuracy, even when preserved through intricate quantization schemes, remains tethered to the initial model’s complexity. The question isn’t merely ‘how small?’ but ‘small enough for what?’ Practical utility, not numerical reduction, dictates the relevant limit.
Future work will likely focus on adaptive quantization – schemes that dynamically adjust bit-widths based on layer sensitivity, or even input data. This offers a potential escape from the rigidity of uniform quantization. However, the computational overhead of such adaptability must be carefully considered; complexity shifted is not complexity solved. Further exploration of heterogeneous quantization, moving beyond simple bit-width variation, appears promising, but demands careful kernel engineering to realize tangible benefits.
Ultimately, the goal is not simply to compress models, but to distill knowledge. To arrive at a minimal representation that retains essential function. Clarity is the minimum viable kindness. The field progresses not by adding layers of ingenuity, but by subtracting unnecessary ones.
Original article: https://arxiv.org/pdf/2602.03537.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- All Shadow Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- One Piece Chapter 1180 Release Date And Where To Read
- Best Bows in Crimson Desert
- All Icewing Armor Locations in Crimson Desert
- How to Beat Stonewalker Antiquum at the Gate of Truth in Crimson Desert
2026-02-04 16:04