Author: Denis Avetisyan
A new framework intelligently adjusts how large language models process information, delivering significant performance gains without sacrificing accuracy.
QTALE dynamically selects layers based on input tokens and leverages quantization to reduce redundancy and improve the efficiency of LLM inference.
Deploying large language models (LLMs) demands substantial computational resources, yet naively combining techniques for efficiency-like token-adaptive layer execution and quantization-often degrades accuracy due to reduced model redundancy. To address this, we introduce ‘QTALE: Quantization-Robust Token-Adaptive Layer Execution for LLMs’, a novel framework that seamlessly integrates these methods through a training strategy promoting diverse execution paths and a post-training mechanism for flexible redundancy adjustment. Our experiments demonstrate that QTALE achieves significant efficiency gains without noticeable accuracy loss, maintaining a gap of under 0.5% on CommonsenseQA benchmarks compared to quantization-only models. Could this approach unlock truly scalable and accessible LLM inference for a wider range of applications?
The Inevitable Bottleneck: Scaling the Language of Thought
Large Language Models have rapidly become central to advancements in artificial intelligence, powering applications from sophisticated chatbots to complex code generation. However, this progress is increasingly constrained by the sheer scale of these models; each iteration demands substantially more computational resources during the process of inference – applying the trained model to new data. The escalating number of parameters, often numbering in the billions or even trillions, translates directly into increased memory requirements and processing demands. This poses a significant challenge for deployment, limiting accessibility and hindering real-time performance, particularly when considering the growing desire for widespread integration into everyday devices and applications. Consequently, researchers are actively exploring innovative methods to mitigate these computational bottlenecks and unlock the full potential of LLMs.
While techniques like model pruning offer a pathway to diminishing the computational burden of Large Language Models, a critical trade-off often emerges. Pruning, which involves systematically removing less important connections within the neural network, can indeed shrink model size and accelerate inference speeds. However, aggressive pruning frequently leads to a demonstrable decline in accuracy and, crucially, a reduction in the model’s complex reasoning abilities. This stems from the removal of parameters that, while seemingly redundant, contribute to nuanced understanding and the generation of coherent, contextually appropriate responses. Consequently, finding the optimal balance between model compression and maintaining high performance remains a significant hurdle in deploying these powerful AI systems effectively.
The substantial computational cost of running Large Language Models during inference stems from a fundamental inefficiency: the repetition of calculations across every layer for each individual token processed. While these models excel at understanding and generating text, their architecture requires that every layer re-evaluates the same information for each token in a sequence, even when that information remains constant. This redundant processing isn’t a flaw in the model’s logic, but rather a consequence of how matrix multiplications are currently implemented on standard hardware. The sheer volume of these repeated operations – billions, or even trillions, for a single request – creates a significant bottleneck, limiting throughput and increasing latency. Addressing this issue is crucial not just for optimizing performance, but for making these powerful models accessible and sustainable in real-world applications.
QTALE: A Dynamic System for Efficient Inference
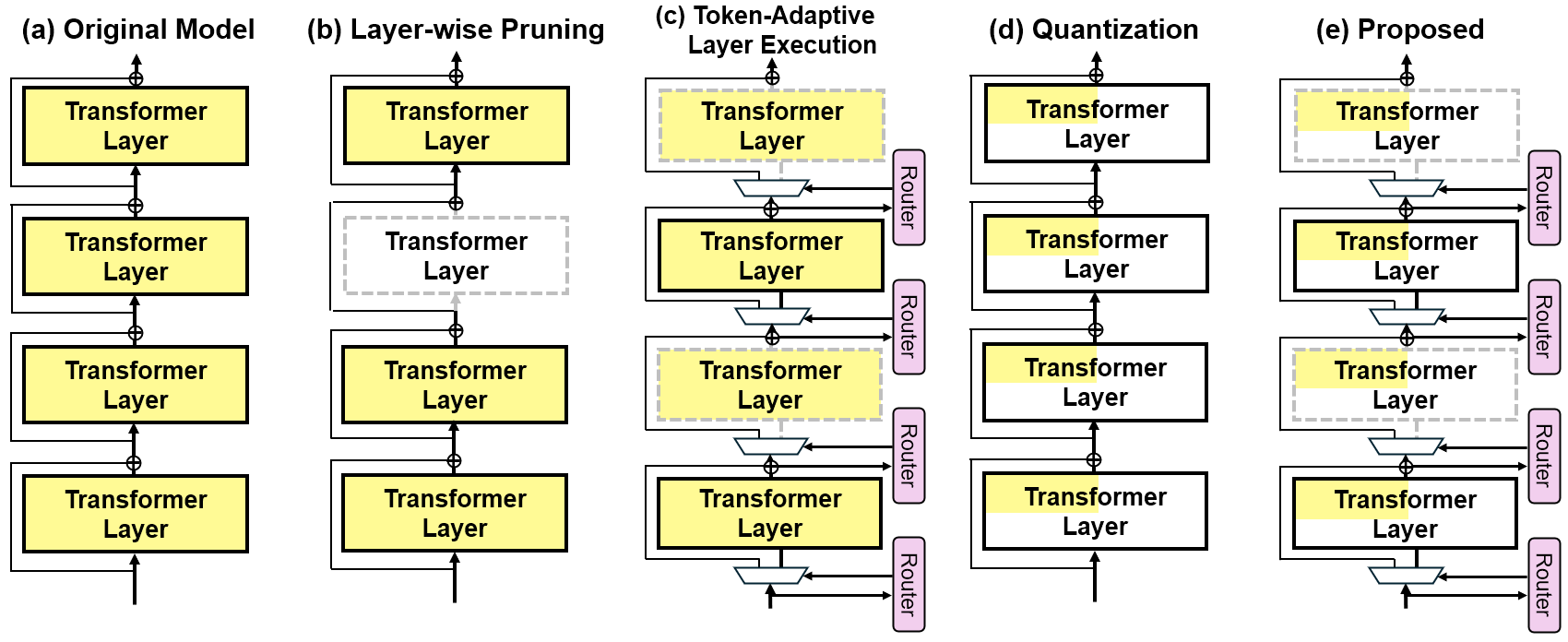
QTALE represents a new framework designed to accelerate Large Language Model (LLM) inference by integrating token-adaptive execution with post-training quantization. This combination addresses computational bottlenecks inherent in traditional LLM deployments. Token-adaptive execution dynamically selects and activates only those layers necessary for processing each input token, thereby reducing redundant calculations. Simultaneously, quantization reduces the precision of the model’s weights and activations – typically from 16-bit floating point to 8-bit integer or lower – which decreases memory bandwidth requirements and allows for faster computation on specialized hardware. The synergy between these two techniques results in a significant improvement in inference throughput and a reduction in energy consumption without substantial accuracy loss.
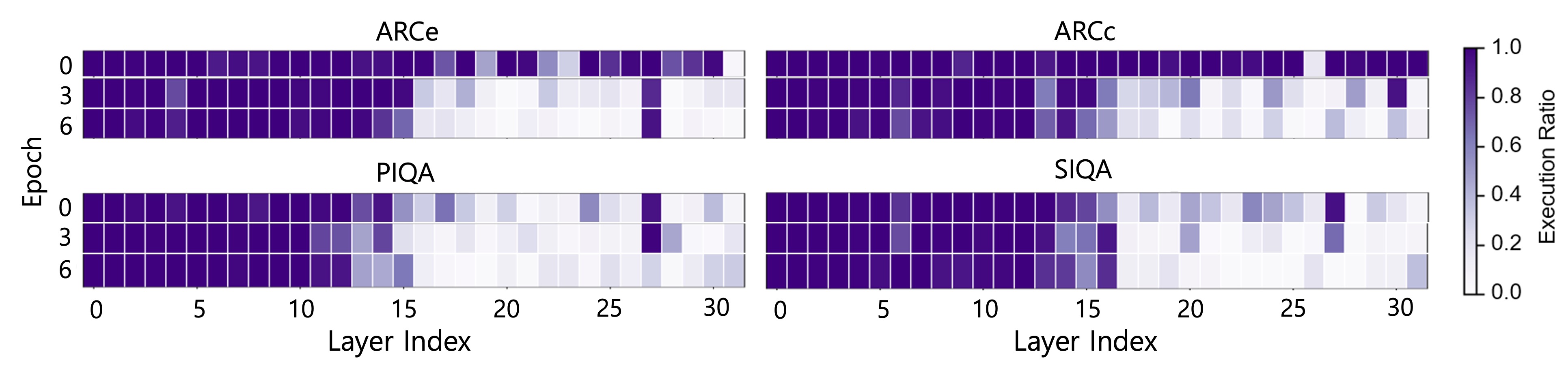
Token-adaptive execution in QTALE operates by dynamically selecting which layers of a large language model (LLM) are activated during inference, based on the characteristics of each input token. Traditional LLM inference processes all layers for every token, regardless of relevance. In contrast, token-adaptive execution analyzes each token and only activates those layers that contribute significantly to processing that specific token, effectively skipping redundant computations. This selective activation is achieved through a gating mechanism that assesses layer importance per token, leading to a reduction in both computational load and power consumption, as fewer matrix multiplications and other operations are performed.
Large Language Models (LLMs) exhibit significant sparsity in their activations – meaning that for any given input token, only a subset of neurons and connections are actively contributing to the output. QTALE capitalizes on this characteristic by dynamically identifying and focusing computational resources on these active components. Rather than processing all layers and parameters for every token, the framework selectively activates only those deemed relevant based on the input, effectively skipping computations for inactive portions of the network. This selective activation reduces both the computational workload and power consumption, as fewer matrix multiplications and memory accesses are required, thereby improving overall inference efficiency.

D-LLM: Implementing Adaptive Layer Execution
D-LLM functions as a core component within the QTALE framework, providing the mechanism for adaptive layer execution. This is achieved through a router module that dynamically determines whether to process each layer of the model or to bypass it, effectively reducing computational demands. The decision-making process relies on a gradient-based approach, where the gradients are used to assess the potential impact of executing or skipping a given layer. Gumbel-Softmax is employed to facilitate this decision by providing a differentiable approximation of a discrete choice, allowing gradients to flow through the router and enabling end-to-end training of the adaptive execution policy. This allows the model to learn which layers are most critical for maintaining performance and which can be safely omitted without significant accuracy loss.
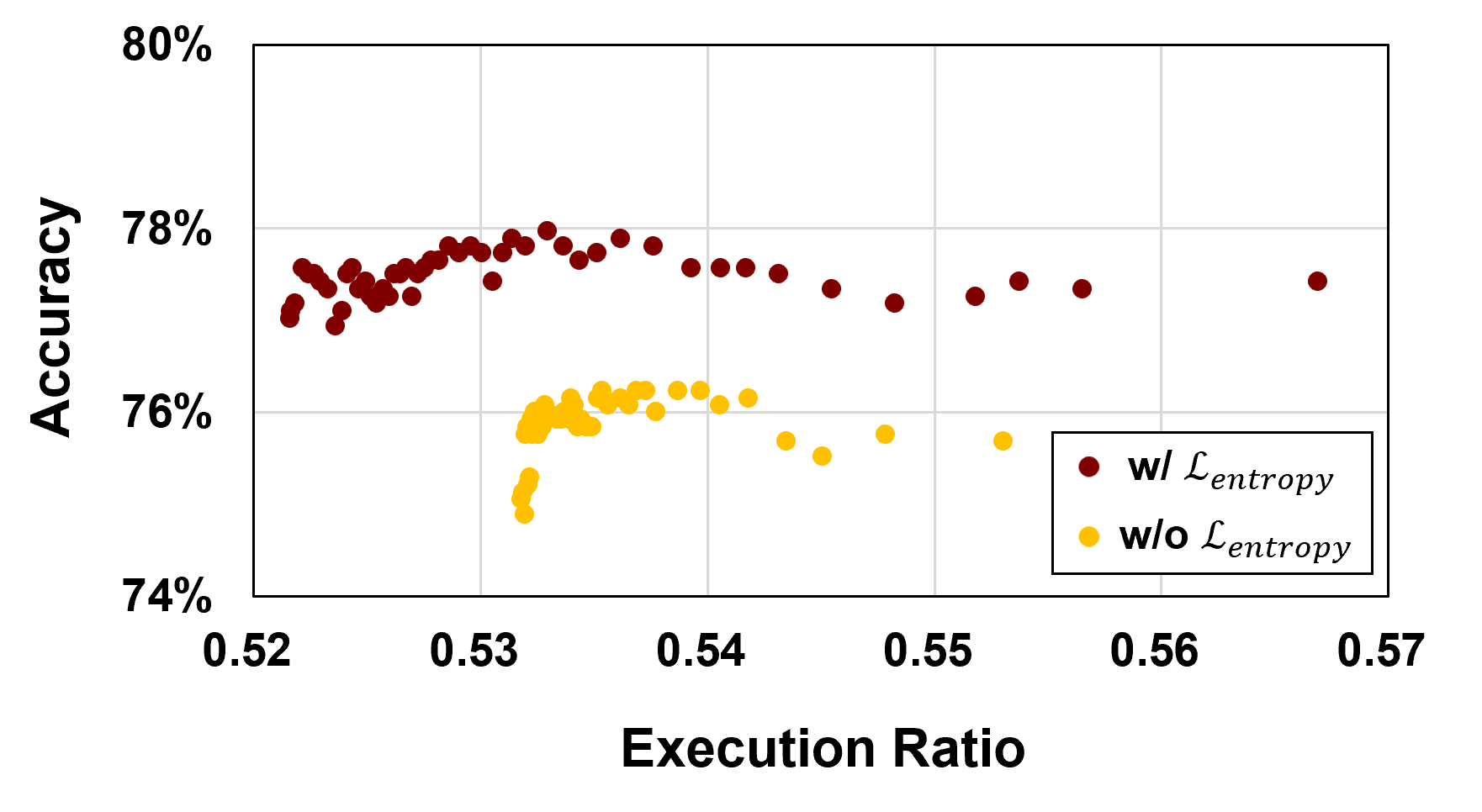
Entropy regularization is implemented within the QTALE framework to enhance performance and stability by promoting exploration of varied execution paths through the model. This technique adds a penalty to the loss function based on the entropy of the router’s output distribution, incentivizing the router module to avoid consistently selecting the same execution path for a given input. By encouraging diverse layer execution, the model becomes less susceptible to overfitting and demonstrates improved generalization capabilities, ultimately contributing to increased robustness against adversarial examples and out-of-distribution data. The regularization process helps to prevent the router from becoming overly confident in a single path, leading to a more adaptable and resilient system.
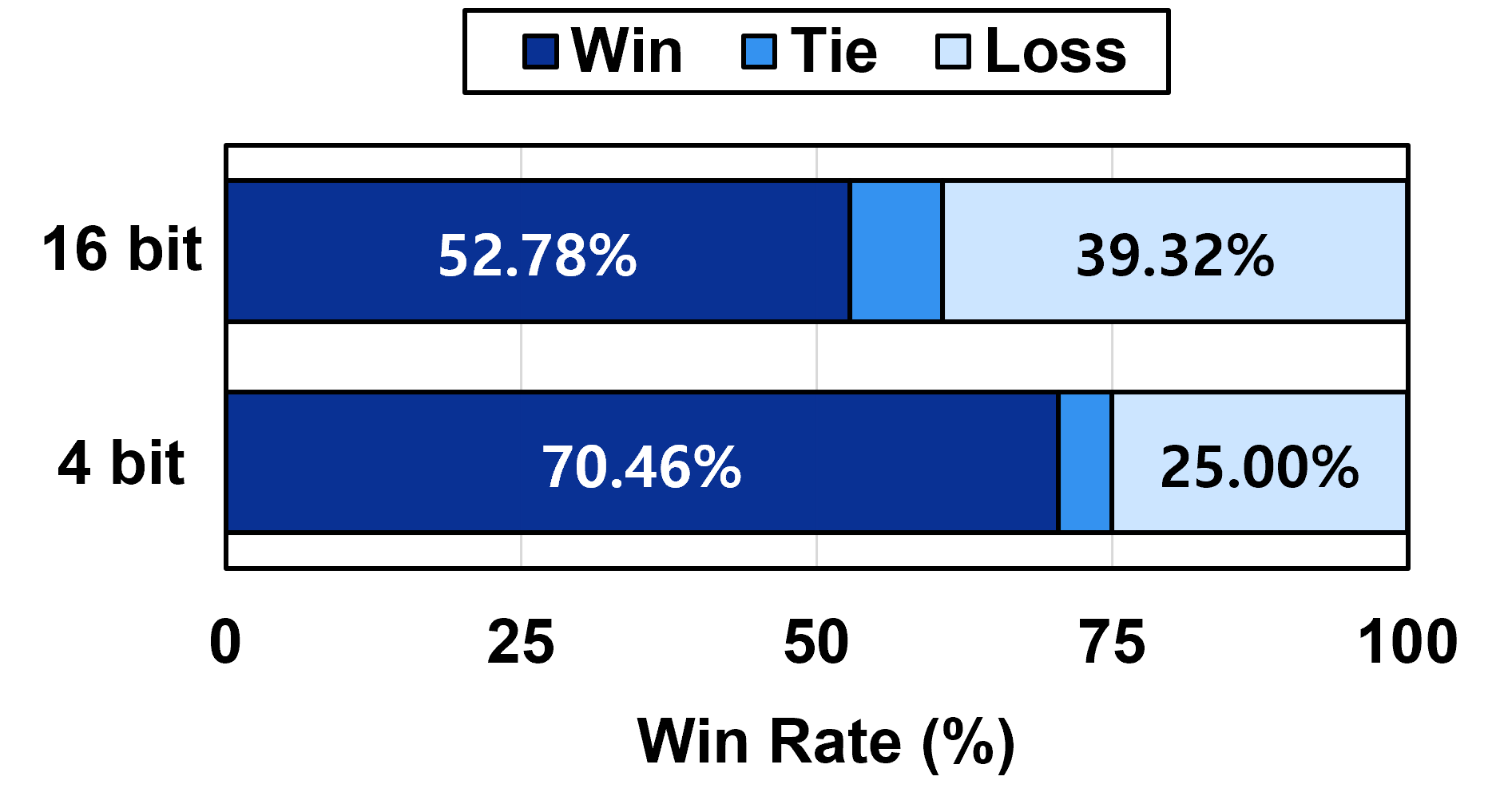
QTALE dynamically adjusts computational cost and model accuracy via the `Execution Ratio`, controlled by the `Inference Threshold`. This mechanism allows selective layer execution during inference, optimizing performance without significant accuracy loss; QTALE achieves accuracy comparable to full-precision models. When combined with 4-bit quantization, QTALE demonstrates a performance improvement of up to 7% on instruction-following benchmarks relative to the D-LLM framework, indicating enhanced efficiency in reduced-precision scenarios.
Quantization and Optimization: Forging Efficiency in QTALE
QTALE utilizes post-training quantization (PTQ) techniques, specifically Activation-Aware Weight Quantization (AWQ) and Magnitude-aware GPTQ (MagR+GPTQ), to compress the model and reduce its resource demands. These methods lower the precision of model weights – typically from 16-bit floating point to 4-bit or 3-bit integer representation – minimizing the model’s size and memory footprint without substantial performance degradation. AWQ focuses on protecting the activations most sensitive to quantization, while MagR+GPTQ optimizes the quantization process by considering the magnitude of weights, leading to improved accuracy at lower bitwidths. This compression is orthogonal to QTALE’s adaptive execution, allowing for combined efficiency gains.
Quantization techniques employed by QTALE, such as AWQ and MagR+GPTQ, reduce the precision of the model’s weights and activations from typically 16-bit or 32-bit floating-point numbers to lower bit-widths like 4-bit or 3-bit integers. This reduction in numerical precision directly lowers both the memory footprint required to store the model and the computational resources needed for matrix multiplications and other operations. While decreasing precision introduces a potential for information loss, these methods are designed to minimize that loss through techniques like minimizing the error introduced during the quantization process and carefully selecting which weights are quantized more aggressively. The net result is a substantial decrease in computational demands without a proportional decrease in model performance.
QTALE achieves a model size below 6.3 GB through the combined implementation of token-adaptive execution and quantization techniques. Performance benchmarks on the CSQA dataset demonstrate an accuracy of 78.41% utilizing the LLaMA3.2-3B model with 4-bit quantization. This result surpasses the performance of D-LLM, which achieved 73.96% on the same dataset, and also exceeds the 72.79% accuracy attained using the LLaMA2-7B model with 3-bit quantization, indicating a substantial reduction in memory footprint without significant performance degradation.
Towards Sustainable AI: The Long View of QTALE
QTALE marks a notable advancement in the pursuit of ecologically sound and readily accessible artificial intelligence. The system substantially lowers the computational demands associated with deploying large language models – a critical step given the escalating energy consumption of these powerful tools. By optimizing the inference process-the phase where a trained model generates outputs-QTALE minimizes the resources needed without significantly compromising performance. This reduction in computational cost not only translates to lower energy usage, but also opens the door for wider deployment on less powerful and more readily available hardware, potentially democratizing access to advanced language technologies and fostering a more sustainable AI ecosystem.
Continued development centers on enhancing QTALE’s dynamic execution, allowing the model to more intelligently allocate computational resources based on input complexity and hardware capabilities. Researchers are actively investigating advanced quantization methods – techniques that reduce the precision of numerical representations within the model – to further compress model size without significant performance degradation. This includes exploring mixed-precision quantization and innovative methods for preserving critical information during the reduction of precision. The goal is to create a system that not only minimizes computational demands but also adapts seamlessly to diverse hardware, paving the way for even more efficient and accessible language model deployment.
The long-term vision of QTALE extends beyond mere efficiency gains; it centers on broadening access to the capabilities of large language models. By significantly reducing computational demands, QTALE facilitates deployment on less powerful and more readily available hardware, such as edge devices and standard consumer-grade computers. This democratization of AI moves beyond reliance on expensive, specialized infrastructure, potentially empowering individuals, small businesses, and researchers who previously lacked the resources to utilize these powerful tools. The ability to run sophisticated language models locally, without constant cloud connectivity, also enhances data privacy and reduces latency, paving the way for innovative applications in fields like personalized education, healthcare, and localized content creation – ultimately fostering a more inclusive and equitable AI landscape.
The pursuit of efficiency within large language models, as demonstrated by QTALE, echoes a fundamental truth about complex systems. One does not build performance; it emerges from carefully cultivated adaptation. The framework’s token-adaptive layer execution, addressing redundancy to minimize accuracy loss during quantization, isn’t simply optimization-it’s a form of directed growth. Vinton Cerf observed, “Any sufficiently advanced technology is indistinguishable from magic.” QTALE doesn’t conjure speed from nothing, but reveals it through elegant interplay between quantization and dynamic execution, proving that the most powerful architectures aren’t those rigidly defined, but those capable of evolving with the data they process.
What Lies Ahead?
QTALE, in its pursuit of efficient inference, offers a momentary reprieve, a localized decrease in entropy. Yet, the fundamental problem remains: these large language models are not solved systems, but propagating instabilities. The framework’s reliance on redundancy mitigation, while presently effective, merely shifts the point of failure, postponing-not preventing-the inevitable cascade. Architecture is, after all, how one postpones chaos.
The true challenge isn’t optimizing for existing quantization schemes, but anticipating their future forms. The landscape of model compression is littered with ‘best practices’ – there are no best practices, only survivors. Future work must acknowledge that any gains achieved through token-adaptive execution are transient. The focus should pivot toward truly dynamic systems, capable of self-repair and emergent resilience – models that don’t just process tokens, but understand their own limitations.
Order is just cache between two outages. The pursuit of efficiency will invariably lead to increased complexity, and with complexity comes fragility. The next generation of LLM inference will not be defined by incremental improvements, but by a fundamental rethinking of how we define – and accept – failure.
Original article: https://arxiv.org/pdf/2602.10431.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Shadow Armor Locations in Crimson Desert
- Sega Reveals Official Sonic Timeline: From Prehistoric to Modern Era
- Dark Marksman Armor Locations in Crimson Desert
- Genshin Impact Dev Teases New Open-World MMO With Realistic Graphics
- The Limits of Thought: Can We Compress Reasoning in AI?
- How to Beat Antumbra’s Sword (Sanctum of Absolution) in Crimson Desert
- Where to Pack and Sell Trade Goods in Crimson Desert
- Enshrouded: Giant Critter Scales Location
- Who Can You Romance In GreedFall 2: The Dying World?
- Keeping AI Agents on Track: A New Approach to Reliable Action
2026-02-12 14:14