Author: Denis Avetisyan
A new quantization technique dynamically adjusts model precision token-by-token, offering significant speedups and efficiency gains for large language models.

MoBiQuant enables token-adaptive elastic inference via mixed-precision quantization and mitigates outlier migration for improved performance.
Achieving consistently high performance with large language models across diverse computational resources remains a challenge, particularly when adapting quantization precision at runtime. This paper introduces ‘MoBiQuant: Mixture-of-Bits Quantization for Token-Adaptive Elastic LLMs’, a novel framework addressing this limitation by dynamically adjusting weight precision based on token sensitivity and mitigating the effects of outlier migration. MoBiQuant leverages a mixture-of-bits approach and token-aware routing to reconstruct higher-precision weights on-demand, enabling smooth precision switching without repeated calibration. Could this token-level adaptability unlock a new era of truly elastic and efficient LLM deployment across a wider range of hardware platforms?
The Precision Bottleneck: A Fundamental Constraint
Large language models have achieved impressive feats in natural language processing, exhibiting capabilities previously thought unattainable for machines. However, this performance comes at a significant cost: their sheer size necessitates enormous computational resources for both training and inference. These models, often containing billions of parameters, require substantial memory, processing power, and energy, limiting their deployment on resource-constrained devices like smartphones or embedded systems. The escalating demands pose a considerable challenge to widespread accessibility and sustainable scaling of these powerful technologies, driving research into methods for model compression and efficient computation without sacrificing performance.
The pursuit of efficient Large Language Models (LLMs) hinges on a critical trade-off: maintaining performance while decreasing the precision with which model parameters are stored. Reducing precision – moving from, for example, 32-bit to 8-bit or even lower – significantly lowers computational demands and memory footprint, making deployment feasible on resource-constrained edge devices like smartphones and embedded systems. This reduction in precision directly translates to lower energy consumption, a vital consideration for both mobile applications and large-scale data centers. However, simply reducing precision can lead to a noticeable decline in model accuracy and generalization ability, creating a “precision bottleneck” that researchers are actively working to overcome through techniques like quantization and mixed-precision training. The ability to strike a balance between model size, energy efficiency, and performance is therefore central to the broader adoption and accessibility of these powerful AI systems.
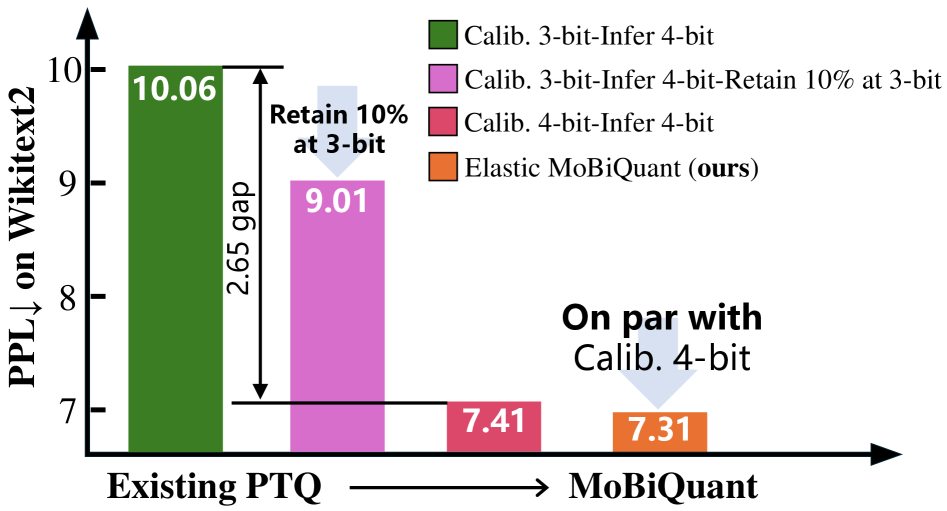
Conventional methods of reducing the numerical precision of large language models, known as quantization, frequently encounter a trade-off between model size and performance. While decreasing precision – for instance, from 32-bit to 8-bit or lower – can significantly reduce computational demands, it often leads to a noticeable decline in accuracy. Studies reveal this sensitivity is particularly pronounced when models are deployed with precision levels differing from those used during calibration; a meticulously calibrated 3-bit model, for example, can exhibit a 2.65 point increase in perplexity – a measure of its uncertainty – when evaluated at 4-bit precision. This suggests that even slight mismatches between calibration and inference precision can substantially degrade performance, highlighting the need for more robust quantization techniques that maintain accuracy across varying data distributions and precision levels.
Outlier Migration: A Source of Instability
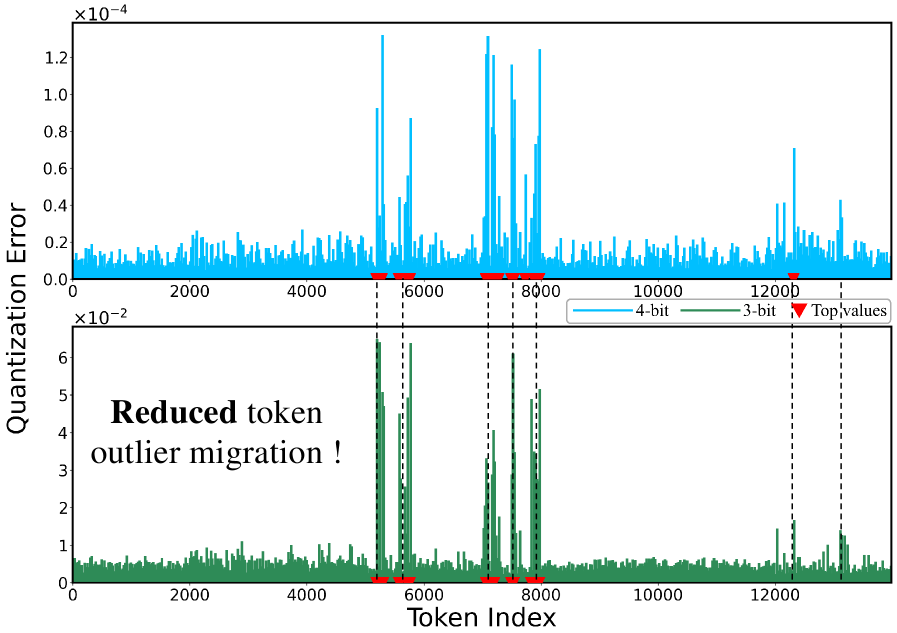
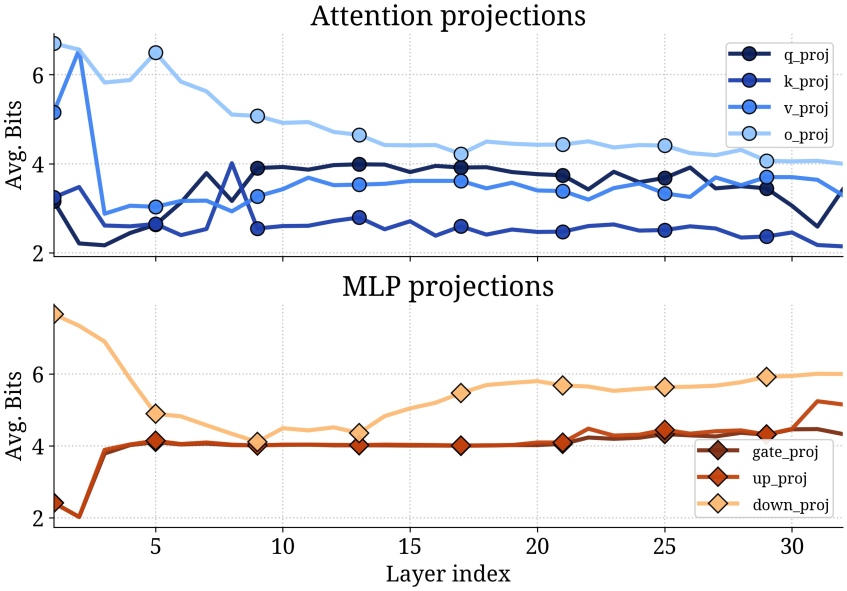
Outlier migration in quantized Large Language Models (LLMs) refers to the phenomenon where tokens initially exhibiting high quantization error-meaning a substantial difference between the original floating-point value and its quantized representation-shift to different precision levels during training or inference. This migration isn’t simply an error correction; it actively introduces performance loss because the model learns to rely on these precision changes, creating instability. Consequently, even though the average quantization error might remain stable, the dynamic shifting of high-error tokens disrupts the learned representations and degrades overall model accuracy and consistency, particularly at lower bit-widths where quantization effects are more pronounced.
MoBiQuant addresses the performance degradation caused by outlier migration in quantized Large Language Models (LLMs) through a token-aware precision adjustment mechanism. Unlike static quantization methods which apply a uniform bit-width to all tokens, MoBiQuant dynamically assigns precision levels on a per-token basis. This is achieved by analyzing the quantization error of individual tokens during training and adapting their representation to utilize higher precision when necessary, and lower precision when sufficient. By selectively increasing precision for tokens exhibiting high quantization error – the outliers – MoBiQuant reduces the overall error rate and stabilizes the quantization process, leading to improved model accuracy and efficiency across varying bit-width configurations.
MoBiQuant achieves stabilized quantization and sustained accuracy by dynamically adjusting the precision applied to individual tokens during the quantization process. This token-adaptive approach contrasts with methods applying a uniform precision level across all tokens, which can exacerbate the effects of outlier migration. By increasing precision for tokens exhibiting high quantization error and maintaining lower precision for others, MoBiQuant minimizes information loss without incurring the computational cost of high-precision quantization throughout the entire model. Evaluations demonstrate that this technique effectively preserves model performance across various bit-widths, including 4-bit and 8-bit quantization, mitigating the typical accuracy degradation associated with reduced precision.
MoBiQuant: Efficient Implementation Through Algorithmic Design
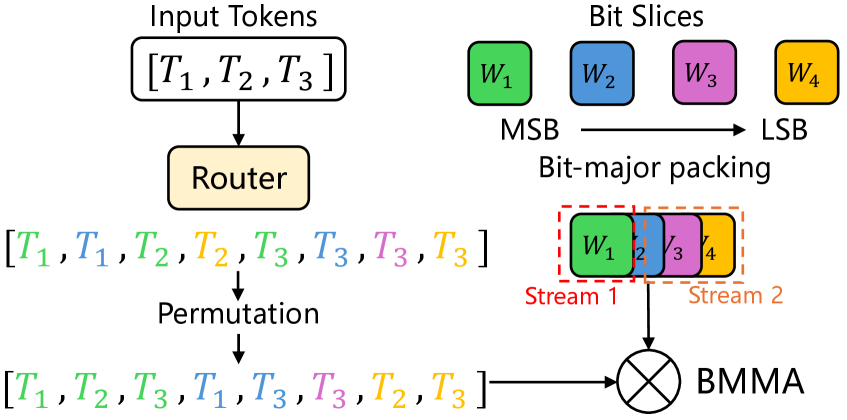
MoBiQuant utilizes Bit-Major Packing and Binary Matrix Multiplication to optimize computational performance on quantized data. Bit-Major Packing reorders data storage to improve memory access patterns and increase data reuse during computation. This technique facilitates efficient vectorized operations on bit slices. Binary Matrix Multiplication, employing binary weights and activations, significantly reduces the number of arithmetic operations required for matrix multiplication. By representing weights and activations with only two values-typically -1 and 1-multiplications are replaced with simpler bitwise operations and accumulations, resulting in substantial speedups, particularly when combined with the optimized data layout provided by Bit-Major Packing.
MoBiRoute is a lightweight routing mechanism integrated into MoBiQuant designed to optimize performance by dynamically assigning input tokens to the most efficient bit slice for quantized computation. It operates by predicting the difficulty of quantizing each token based on its magnitude and distribution, then directing it to a bit slice configured with the appropriate precision. This adaptive routing minimizes computational overhead and maximizes throughput, as tokens requiring higher precision are processed on bit slices with greater bit-width, while simpler tokens utilize lower-precision slices, reducing both memory bandwidth requirements and overall processing time.
MoBiQuant utilizes CUDA Streams to enable parallel execution of operations on quantized data. CUDA Streams facilitate the overlapping of computation and data transfer between the host and device, thereby maximizing throughput. Specifically, multiple CUDA Streams allow MoBiQuant to launch several kernels concurrently, effectively hiding latency associated with memory operations and kernel launches. This approach allows for the sustained utilization of the GPU, leading to significant performance improvements, particularly when processing large sequences of tokens. The system can issue multiple operations simultaneously, rather than sequentially, improving overall computational efficiency and reducing processing time.
Experimental Validation: Robust Performance Across Models
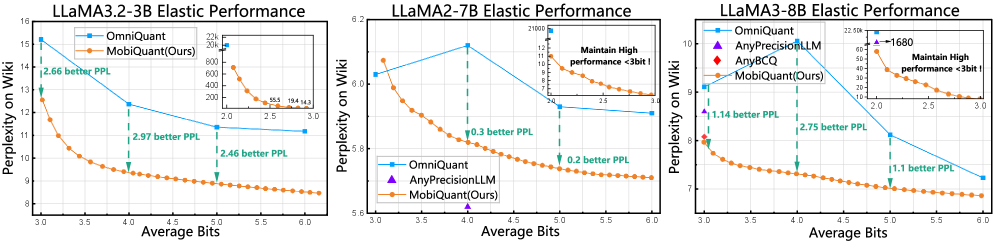
MoBiQuant consistently outperforms static quantization across a range of large language models (LLMs). Evaluations on LLAMA2-7B, LLAMA3-8B, and LLAMA3.2-1B demonstrate that MoBiQuant achieves higher accuracy and efficiency compared to static quantization methods. This superior performance is observed across diverse model sizes and architectures within the LLAMA family, indicating the broad applicability and robustness of MoBiQuant as a quantization technique for LLMs.
Evaluation of MoBiQuant utilized established datasets to assess its performance characteristics. The WikiText2 dataset, comprising a diverse collection of articles, was used to test language modeling capabilities. The C4 dataset, a large-scale corpus of web text, provided a broad assessment of generalization across varied content. Performance was further validated on the Penn Treebank (PTB) dataset, a standard benchmark for language modeling. Results across these datasets demonstrate MoBiQuant’s consistent and reliable performance, confirming its robustness and ability to generalize to different text distributions and language modeling tasks.
MoBiQuant achieves a performance speedup of up to 2.7x on NVIDIA A100 GPUs when compared to the FP16 baseline. This acceleration is observed while maintaining strong elasticity, indicating consistent performance across varying workloads, and demonstrating improved generalization capabilities across different datasets and model sizes. These results suggest MoBiQuant provides a substantial computational efficiency gain without compromising model accuracy or adaptability.
Towards Elastic Inference: A Paradigm Shift in Deployment
The advent of MoBiQuant introduces a paradigm shift in large language model deployment through its capacity for elastic inference. This innovative approach allows the model to dynamically adjust its computational precision during runtime, effectively creating a trade-off between inference speed and accuracy. When processing demands are high and rapid responses are critical, MoBiQuant can temporarily reduce precision, accelerating computations at the potential cost of minor accuracy loss. Conversely, when high fidelity is paramount, the model can operate at higher precision levels, ensuring optimal results. This adaptability is particularly valuable in real-world applications with fluctuating resource availability or varying latency requirements, paving the way for more responsive and efficient AI systems that can intelligently balance performance and precision on demand.
Large language models, while powerful, traditionally demand substantial computational resources, hindering their deployment on edge devices or in latency-sensitive applications. However, Any-Precision Quantization, leveraging the MoBiQuant framework, offers a solution by enabling a nuanced trade-off between model size, speed, and accuracy. This technique moves beyond fixed-precision methods, allowing individual weights and activations within the model to be represented using varying bit-widths – even down to a single bit – based on their sensitivity. The result is a significantly compressed model that maintains acceptable performance, unlocking the potential for LLMs to run efficiently on smartphones, embedded systems, and other resource-constrained platforms. By dynamically tailoring precision, Any-Precision Quantization paves the way for broader accessibility and real-time applications of these sophisticated models.
Researchers are actively investigating synergistic combinations of MoBiQuant with established model compression methodologies, such as pruning and knowledge distillation, to achieve even greater reductions in computational cost and memory footprint. A key focus lies in developing automated precision tuning strategies, leveraging reinforcement learning or neural architecture search, that dynamically optimize the quantization levels for different layers and input characteristics. This automation promises to alleviate the burden of manual calibration, enabling seamless deployment of large language models across a diverse range of hardware platforms and resource constraints, while maintaining a desirable balance between accuracy and efficiency. The ultimate goal is to create self-optimizing models that adapt to varying computational demands in real-time, paving the way for truly elastic inference capabilities.
The pursuit of efficiency in large language models, as demonstrated by MoBiQuant, echoes a fundamental tenet of mathematical elegance. This work focuses on dynamically adjusting precision based on token sensitivity, a nuanced approach to minimizing information loss during quantization. G.H. Hardy once stated, “Mathematics may be compared to a box of tools.” This sentiment applies directly to MoBiQuant; it isn’t simply about shrinking the model, but about selecting the right tools – the appropriate bit-width – for each computational task. By acknowledging that not all tokens demand the same level of precision, MoBiQuant achieves speedups while mitigating the challenges of outlier migration – a provably correct approach to scalable inference.
What Lies Ahead?
The elegance of MoBiQuant resides not in merely achieving speedup – a feat increasingly common in the pursuit of tractable large language models – but in its attempt to address a fundamental instability: the migration of outliers during quantization. It is a step towards recognizing that not all bits are created equal, and that a static precision is a mathematical conceit. However, the framework’s reliance on token-level sensitivity as a proxy for outlier behavior presents a potential boundary. True robustness will demand a deeper understanding of the loss landscape itself, a provable characterization of which remains elusive.
Future work must confront the implicit cost of dynamic precision. While the paper demonstrates gains, the overhead of per-token adjustment-however minimized-introduces a complexity that may not scale indefinitely. The question is not simply whether one can adapt precision, but whether the resulting system remains predictably stable under arbitrary input. The pursuit of ‘elasticity’ must be tempered by the need for guaranteed bounds on computational cost.
Ultimately, the success of approaches like MoBiQuant will be measured not by incremental improvements in benchmark scores, but by a demonstrable shift toward provably correct quantization schemes. The field needs fewer empirical observations and more formal proofs – a rigorous articulation of the conditions under which quantization can be considered a lossless, or at least predictably bounded, transformation. The beauty of an algorithm lies not in tricks, but in the consistency of its boundaries and predictability.
Original article: https://arxiv.org/pdf/2602.20191.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- All Shadow Armor Locations in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- Best Bows in Crimson Desert
- Keeping Large AI Models Connected Through Network Chaos
- All Icewing Armor Locations in Crimson Desert
- How to Craft the Elegant Carmine Armor in Crimson Desert
2026-02-25 23:59