Author: Denis Avetisyan
New research reveals that shrinking the size of advanced vision-language AI models impacts their ability to provide reliable answers, but a simple solution can restore much of that lost trust.
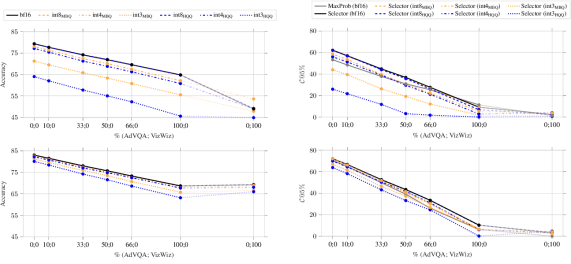
Post-training quantization degrades the reliability of multimodal large language models, but this can be mitigated with a lightweight confidence estimation method.
Despite advances in multimodal large language models, a critical trade-off persists between model efficiency and trustworthy performance. This is explored in ‘Evaluating the Impact of Post-Training Quantization on Reliable VQA with Multimodal LLMs’, which investigates how model compression via post-training quantization affects both accuracy and reliability in visual question answering. The study demonstrates that while quantization degrades performance, a lightweight confidence estimator-the ‘Selector’-can substantially mitigate the resulting loss of reliability, enabling efficient deployment without sacrificing trustworthiness. Can these techniques unlock broader applications of multimodal LLMs in resource-constrained environments requiring both high performance and calibrated confidence?
The Ascent of Multimodal Models and the Imperative of Compression
The emergence of multimodal large language models, such as LLaVA and Qwen2-VL, signifies a substantial leap in artificial intelligence’s capacity to process and integrate information from multiple sources – most notably, both images and text. These models showcase an impressive ability to not only ‘see’ and interpret visual data but also to articulate their understanding in coherent language, enabling applications ranging from detailed image captioning to visually-grounded question answering. However, this enhanced functionality comes at a considerable price: the sheer scale of these models demands significant computational resources for both training and deployment. The complex interplay of billions of parameters necessitates powerful hardware, limiting accessibility and hindering their practical application on devices with limited processing power or memory – a key obstacle to widespread adoption despite their groundbreaking capabilities.
The burgeoning field of multimodal large language models, while achieving remarkable feats in understanding and relating visual and textual information, faces a practical hurdle: sheer size. These models, boasting billions of parameters, demand substantial computational resources – memory, processing power, and energy – effectively limiting their deployment on ubiquitous devices like smartphones, embedded systems, and edge computing platforms. This constraint necessitates the development of sophisticated compression techniques capable of drastically reducing model dimensions without sacrificing performance. Researchers are actively exploring methods-such as pruning, knowledge distillation, and quantization-to create more efficient models that can bring the power of multimodal AI to a wider range of applications and users, enabling real-time processing and accessibility beyond the confines of high-performance computing infrastructure.
Post-Training Quantization (PTQ) represents a compelling strategy for deploying large multimodal models on devices with limited resources, though it isn’t without its challenges. This technique reduces a model’s memory footprint and boosts inference speed by representing weights and activations with fewer bits – often transitioning from 32-bit floating-point numbers to 8-bit integers or even lower. However, this simplification can introduce quantization errors, leading to a noticeable decline in model accuracy if not carefully managed. Researchers are actively exploring methods to mitigate this degradation, including calibration techniques to minimize information loss during the quantization process and mixed-precision quantization, which strategically applies different bit-widths to various model layers. Successfully implementing PTQ requires a delicate balance between compression gains and maintaining acceptable performance levels, making it a crucial area of focus for practical multimodal AI deployment.
Restoring Fidelity: Advanced Quantization as a Corrective Measure
Post-training quantization (PTQ), while efficient for model compression, can result in poorly calibrated models if implemented naively. Calibration refers to the model’s ability to accurately reflect its prediction uncertainty; a well-calibrated model’s predicted confidence should correlate with actual correctness. Simple PTQ methods often fail to preserve this calibration, leading to overconfident but inaccurate predictions. This impacts the trustworthiness of the model’s outputs, particularly in safety-critical applications where reliable uncertainty estimation is paramount. Consequently, advanced quantization techniques are needed to maintain both model efficiency and accurate uncertainty representation.
Half-Quadratic Quantization and Modality-Balanced Quantization (MBQ) represent advanced post-training quantization (PTQ) techniques designed to address the accuracy degradation often observed with simpler quantization methods. These techniques move beyond uniform quantization by analyzing the distribution of weights and activations within a neural network. Half-Quadratic Quantization utilizes a second-order approximation to minimize quantization error, while MBQ specifically accounts for modality-specific characteristics – recognizing that different feature modalities may require distinct quantization strategies to preserve information. By considering these data distributions and modality nuances, these methods aim to minimize information loss during the reduction of precision, leading to improved model calibration and more reliable performance at lower bit widths.
The application of int4 quantization, coupled with Modality-Balanced Quantization (MBQ), yields a performance level attaining 98% of the accuracy achieved by bf16 (bfloat16) models. This indicates a substantial retention of model capability despite a significant reduction in numerical precision. MBQ specifically addresses the challenges of quantization by accounting for data distributions and modality-specific characteristics, thereby minimizing accuracy loss during the transition to lower bit-width representations. The near-equivalence in performance demonstrates the effectiveness of this combined approach in maintaining model fidelity while simultaneously reducing computational resource requirements.
Bit width, a critical parameter in quantization, directly governs the trade-off between model compression and performance retention. Reducing the number of bits used to represent weights and activations leads to a smaller model size and reduced memory footprint; transitioning to int4 quantization, for example, achieves a 75% reduction in memory usage compared to higher precision formats. However, this compression inherently introduces information loss, potentially impacting model accuracy. Therefore, selecting an appropriate bit width requires careful consideration of the acceptable performance degradation relative to the desired level of compression. Lower bit widths, while maximizing compression, necessitate more sophisticated quantization techniques to mitigate accuracy loss and maintain acceptable performance levels.
Despite employing reduced bit widths through quantization – specifically moving to int4 precision – model performance demonstrates high retention relative to the baseline bf16 representation. Evaluations indicate that the accuracy of the quantized model remains within a 2 percentage point range of the full-precision bf16 model. This minimal performance degradation signifies that substantial compression – achieved through reduced bit width – can be realized without incurring a significant loss in predictive capability, making these quantization strategies viable for resource-constrained deployment scenarios.
Selective Abstinence: A Principle of Robust Prediction
Selective prediction is a technique employed in machine learning models to enhance reliability by allowing the model to deliberately refrain from providing an answer when its internal confidence in that answer falls below a predetermined threshold. This mechanism directly addresses the issue of inaccurate outputs; rather than consistently generating a potentially incorrect response, the model opts to abstain, effectively signaling its uncertainty. The core principle is that a model’s ability to identify and avoid questions it cannot confidently answer contributes more to overall system trustworthiness than attempting an answer with high potential for error. This approach is particularly valuable in applications where incorrect predictions carry significant consequences, as it prioritizes the delivery of reliable information even at the cost of incomplete coverage.
Confidence estimation in selective prediction models is approached through two primary methods: intrinsic and extrinsic. Intrinsic methods, like MaxProb, derive confidence directly from the model’s internal outputs – specifically, the highest predicted probability for a given answer. This calculation requires no additional training data beyond that used for the primary task. Conversely, extrinsic methods, such as Selector, employ a separate, trained estimator to assess confidence. These estimators are typically trained on data specifically designed to evaluate the model’s ability to identify answerable versus unanswerable questions, allowing them to learn patterns indicative of low confidence and subsequently abstain from providing an answer.
Both MaxProb and Selector employ the Visual Question Answering (VQA) task as a benchmark for evaluating and improving confidence scoring methodologies. In VQA, models are presented with an image and a natural language question, requiring them to generate an answer. By assessing a model’s ability to correctly answer questions with high confidence and abstain from answering when uncertain, researchers can refine the algorithms used to estimate prediction confidence. This process allows for empirical validation of confidence scores against ground truth data, enabling iterative improvements to both MaxProb and Selector’s ability to accurately reflect the reliability of their predictions on image-based queries.
The performance of selective prediction models is evaluated using metrics designed to balance prediction coverage and accuracy. Coverage-at-Risk, specifically, quantifies the proportion of questions answered within a specified confidence threshold; a lower Coverage-at-Risk indicates the model abstains from more questions, potentially increasing reliability. Effective Reliability measures the actual accuracy of predictions made at a given confidence level; a higher Effective Reliability signifies that the model’s confidence scores accurately reflect its performance. These metrics allow for a quantitative comparison of different selective prediction strategies and provide insights into the trade-offs between coverage and the minimization of incorrect answers.
Towards Ubiquitous Intelligence: Implications for the Future
Recent evaluations utilizing models such as Idefics3-8B and BLIP-2, coupled with Greedy Decoding, reveal a promising capacity for maintaining robust performance even under significant compression. These tests demonstrate that sophisticated quantization techniques, when paired with selective prediction strategies, do not necessarily lead to a substantial decline in accuracy or reliability. The ability to effectively compress these large multimodal models-without sacrificing core functionality-is a critical step toward practical deployment. This research suggests that complex AI capabilities are becoming increasingly accessible, opening doors for integration into a wider range of applications and devices where computational resources are limited, and efficient processing is paramount.
Deploying sophisticated multimodal artificial intelligence on edge devices-those operating directly on smartphones, robots, or embedded systems-requires overcoming significant computational hurdles. Recent work demonstrates a powerful solution through the synergistic combination of advanced quantization and selective prediction. Quantization drastically reduces the precision of model parameters, minimizing storage and accelerating processing, while selective prediction intelligently focuses computational resources on the most salient aspects of an input. This pairing allows complex models, previously confined to powerful servers, to operate efficiently on resource-constrained hardware without substantial performance degradation. The resulting systems promise to unlock a new wave of applications, bringing the benefits of multimodal AI-such as image understanding and natural language processing-to a wider range of devices and environments.
The refinement of multimodal AI through compression techniques unlocks possibilities previously limited by computational demands. This increased accessibility extends the reach of these powerful systems to diverse applications, notably in assistive technology where real-time image and text understanding can empower individuals with disabilities. Similarly, advancements in robotics benefit from efficient onboard processing of visual and linguistic data, facilitating more responsive and adaptable machines. Crucially, the ability to deploy complex AI on resource-constrained devices – such as those used in environmental monitoring or disaster relief – offers solutions where connectivity is limited and immediate analysis is vital, signifying a pivotal shift towards democratized and widely available artificial intelligence.
The pursuit of increasingly capable artificial intelligence demands a concurrent focus on trustworthiness and responsible deployment. Recent advancements in model compression, specifically through techniques that maintain both accuracy and reliability, directly address this need. By ensuring consistent and predictable performance even under resource constraints, these methods move beyond simply achieving high scores on benchmarks. Instead, they facilitate the creation of AI systems suitable for critical applications where errors can have significant consequences, such as healthcare diagnostics or autonomous navigation. This emphasis on robust and dependable outputs is not merely a technical improvement, but a crucial step towards building public confidence and fostering the ethical integration of AI into daily life, ultimately paving the way for broader societal acceptance and beneficial utilization.
The pursuit of efficient model deployment, as demonstrated in this work regarding post-training quantization for multimodal large language models, necessitates a rigorous focus on reliability. The study highlights a critical degradation in confidence estimation following quantization, a problem elegantly addressed by the proposed ‘Selector’ mechanism. This aligns with Fei-Fei Li’s observation: “The most dangerous thing you can do is to believe that you know something that you don’t.” Just as a flawed assumption of knowledge can lead to incorrect conclusions, an uncalibrated model-one that falsely exudes confidence-presents a significant risk, particularly when applied to real-world visual question answering tasks. The emphasis here isn’t merely on achieving a functional solution, but on ensuring the provability of its reliability-a commitment to asymptotic correctness, not just empirical performance.
Future Directions
The observation that post-training quantization introduces a systematic bias in the confidence estimates of multimodal large language models is, predictably, not surprising. Any transformation that reduces representational capacity invites a corresponding loss of fidelity. The demonstrated efficacy of the ‘Selector’ estimator-a pragmatic, lightweight correction-is, however, a necessary, if insufficient, advance. It addresses the symptom, not the disease. A truly elegant solution demands a formal understanding of how quantization alters the decision boundary-a mathematical characterization of the induced error, not merely its empirical mitigation.
Future work must move beyond ad-hoc calibration techniques. The field requires a provably robust quantization strategy, one where the confidence score remains a faithful representation of the model’s epistemic uncertainty, even at reduced precision. This necessitates a deeper investigation into the interplay between model architecture, quantization scheme, and calibration error-a rigorous derivation, perhaps, of the Cramer-Rao lower bound for confidence estimation under quantization.
The current focus on ‘recovery’ of lost reliability implicitly accepts quantization as a necessary evil. A more ambitious program would seek quantization-aware training methods that preserve confidence calibration from the outset, ensuring that reduced precision does not necessitate a compromise in trustworthiness. Only then can these models truly function as reliable reasoning engines in resource-constrained environments.
Original article: https://arxiv.org/pdf/2602.13289.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Shadow Armor Locations in Crimson Desert
- Jujutsu Kaisen Season 3 Episode 12 Release Date
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Dark Marksman Armor Locations in Crimson Desert
- Best Bows in Crimson Desert
- Wings of Iron Walkthrough in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- How To Beat Ator Archon of Antumbra In Crimson Desert
- Top 5 Militaristic Civs in Civilization 7
- Sakuga: The Hidden Art Driving Anime’s Stunning Visual Revolution!
2026-02-17 20:35