Author: Denis Avetisyan
A new attention mechanism dramatically reduces the memory footprint of large language models without sacrificing performance.
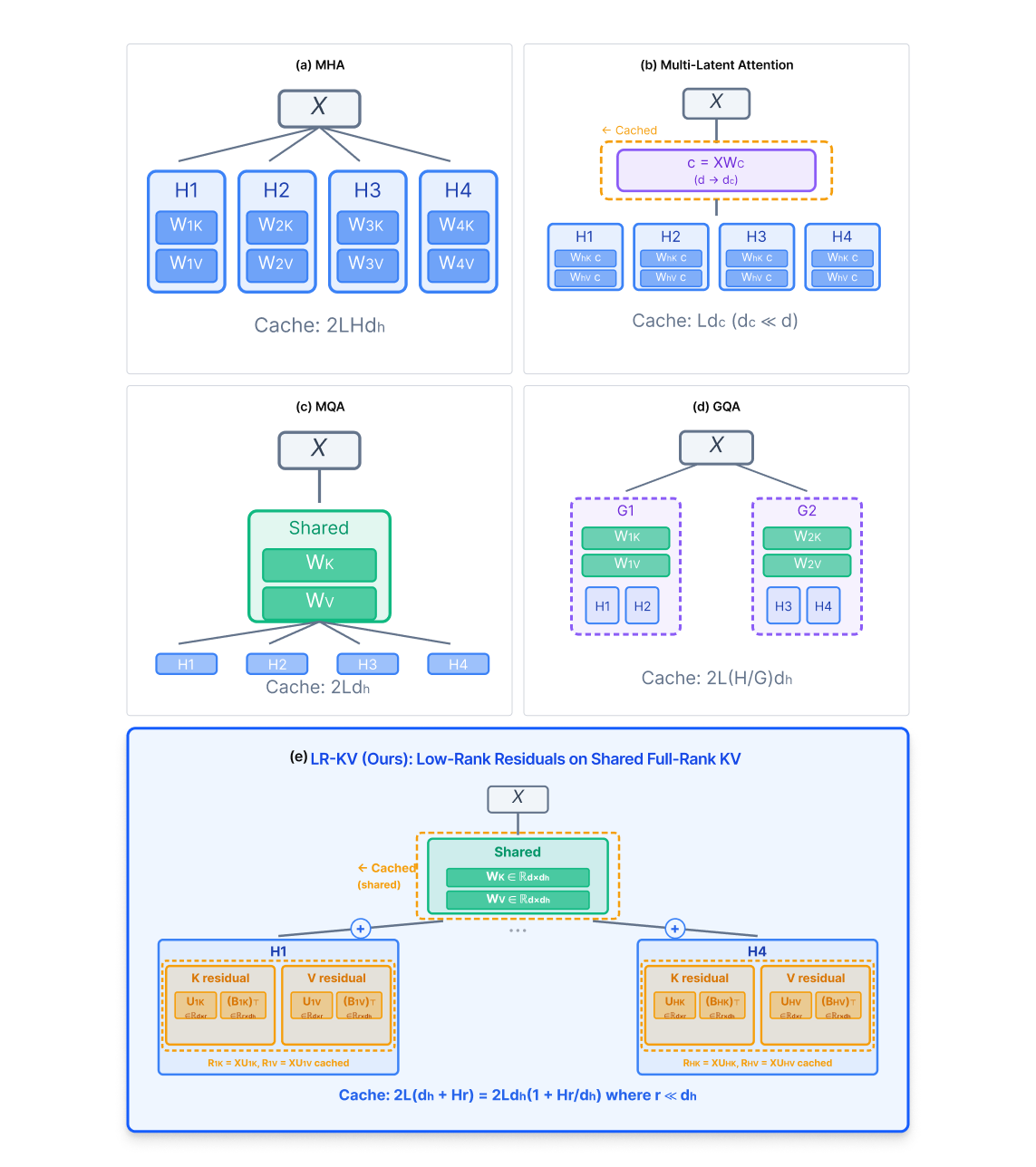
Low-Rank Key-Value Adaptation factorizes key-value projections to achieve significant parameter and memory efficiency gains in transformer architectures.
Scaling Transformer pretraining is increasingly hampered by the quadratic memory cost of the key-value (KV) cache in attention mechanisms. This paper introduces Low-Rank Key Value Attention (LRKV), a modification of multi-head attention that factorizes KV projections to reduce memory footprint while preserving representational capacity. LRKV achieves comparable performance to standard attention, and outperforms existing KV-sharing methods like multi-query and grouped-query attention, with significantly lower memory requirements and up to 20-25% reduction in training compute. By enabling more efficient scaling of large language models, can LRKV unlock new levels of performance and accessibility in natural language processing?
The Attention Bottleneck: Unraveling the Limits of Scale
Transformer models have revolutionized numerous fields, yet their computational demands increase dramatically as the length of the input sequence grows. This scaling issue, often described as quadratic, stems from the full attention mechanism where each element in the sequence must be compared to every other element. Consequently, processing long-form content – such as lengthy documents, high-resolution images, or extended audio – quickly becomes intractable, even with significant computational resources. A sequence of n tokens requires approximately n^2 operations, creating a substantial bottleneck for applications requiring an understanding of extended contexts. This limitation motivates ongoing research into more efficient attention mechanisms and alternative architectures capable of handling long-range dependencies without sacrificing performance or accuracy.
The fundamental constraint within traditional Transformer models arises from the full attention mechanism itself. This process requires each element in a sequence to attend to every other element, creating a computational complexity that scales quadratically with the sequence length – meaning the resources needed increase proportionally to the square of the input size. Consequently, processing long sequences demands an enormous amount of memory and processing power, quickly becoming prohibitive even with advanced hardware. For instance, a sequence of just 4,000 tokens necessitates calculations for 16 million attention weights. This limitation isn’t simply a matter of scaling up hardware; it fundamentally restricts the model’s ability to effectively process and reason about extended contexts, hindering performance on tasks requiring comprehension of long-form content like books, articles, or lengthy dialogues.
Attempts to mitigate the computational burden of full attention in Transformers frequently involve trade-offs that diminish the model’s inherent reasoning capabilities. Techniques such as sparse attention, locality-sensitive hashing, and knowledge distillation aim to reduce complexity, but often achieve this by limiting the scope of information the model considers during processing. This restriction can lead to a loss of crucial contextual details, hindering the model’s ability to perform complex inferences or understand nuanced relationships within long sequences. While these approximations offer performance gains in terms of speed and memory usage, they frequently result in a demonstrable decline in accuracy on tasks requiring deep contextual understanding or multi-step reasoning, effectively sacrificing qualitative performance for quantitative efficiency.
KV Sharing: Deconstructing Redundancy in Attention
Key-Value (KV) sharing in attention mechanisms reduces computational cost and memory usage by decreasing the number of key and value projections. Traditional multi-head attention independently projects queries, keys, and values for each head, leading to substantial redundancy, particularly in the key and value matrices. KV sharing techniques mitigate this by forcing multiple attention heads to share the same key and value projections. This reduces the number of parameters and the size of the key/value cache, directly lowering memory bandwidth requirements and accelerating computation. While this sharing introduces a potential loss in representational capacity due to decreased model expressiveness, the resulting efficiency gains are substantial, especially when processing long sequences where the key/value cache represents a significant portion of the overall memory footprint.
MultiQueryAttention and GroupedQueryAttention reduce computational redundancy within the attention mechanism by altering how key and value projections are handled. Traditional multi-head attention independently projects queries, keys, and values for each head. In contrast, MultiQueryAttention shares the same key and value projections across all heads, while GroupedQueryAttention divides heads into groups that share projections. This reduces the number of parameters associated with key and value transformations, directly lowering memory bandwidth requirements and accelerating computation, particularly during inference. The trade-off is a potential reduction in model capacity as the shared projections limit the diversity of key-value representations available to each attention head.
Reducing the number of key and value projections in multi-head attention, as implemented in techniques like MultiQueryAttention and GroupedQueryAttention, inherently decreases the model’s representational capacity. Each attention head typically learns independent relationships between queries, keys, and values; sharing these projections forces heads to compete for representational space. However, this trade-off yields substantial reductions in memory bandwidth and computational requirements, particularly during inference. By minimizing the size of the key and value caches, these methods enable the processing of significantly longer input sequences – a critical benefit for applications like long-form question answering and document summarization – without encountering the memory limitations that constrain traditional attention mechanisms.
Low-Rank KV Adaptation: Subtly Rewriting the Rules of Attention
Low-Rank KV Adaptation modifies the standard attention mechanism by decomposing the key and value projection matrices. Instead of directly applying full-rank projections, the method factorizes these matrices into a shared, full-rank base matrix and a set of per-attention-head low-rank residual matrices. This factorization allows for a reduction in the total number of trainable parameters associated with the key and value projections, while attempting to preserve representational capacity through the addition of these head-specific residual components. The decomposition effectively separates the dominant signal – captured by the full-rank matrix – from finer-grained, head-specific adjustments represented by the low-rank residuals.
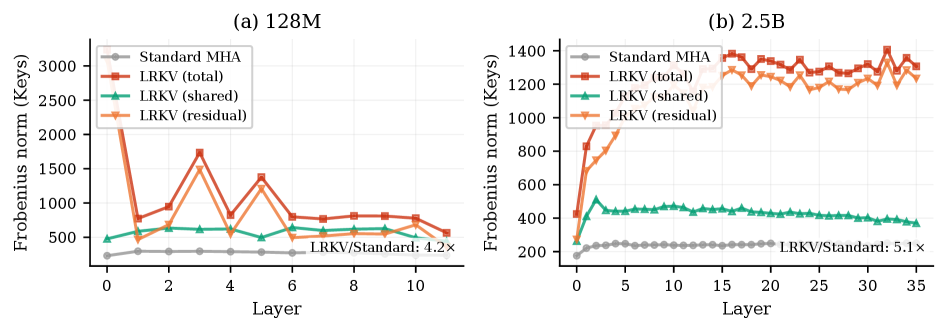
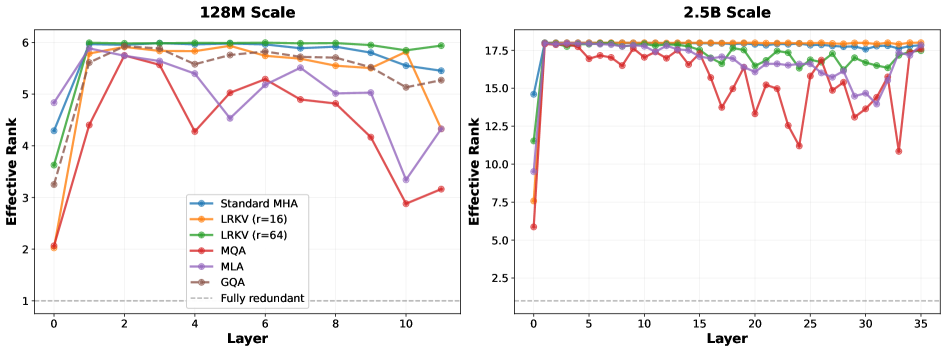
Low-Rank KV Adaptation reduces the number of trainable parameters and associated computational cost by decomposing key and value projection matrices. This decomposition utilizes a full-rank base matrix combined with per-head low-rank residual matrices, effectively reducing the dimensionality of these projections. Principal Component Analysis (PCA) was employed to validate that this reduction in parameter count does not substantially diminish model capacity; results demonstrate that the majority of the variance in the original key and value spaces is retained despite the dimensionality reduction, indicating preservation of essential information and representational power. This approach allows for a reduction in model size and inference cost without significant performance degradation.
Spectral analysis of attention weight matrices provides empirical evidence supporting the efficacy of the Low-Rank KV Adaptation decomposition in retaining critical information. This analysis examines the eigenvalue distribution of the attention matrices before and after applying the factorization. Results indicate that the dominant eigenvalues, representing the most significant dimensions of the attention space, are largely preserved through the decomposition process. Specifically, the analysis demonstrates that the Low-Rank adaptation maintains a high proportion of the variance captured by these dominant eigenvalues, suggesting that the core relationships learned by the attention mechanism are not significantly diminished. This preservation of spectral properties confirms that the low-rank approximation effectively captures the essential information contained within the original, full-rank attention matrices.

Expanding Horizons: Unlocking Capacity and Reasoning Depth
Low-Rank KV Adaptation offers a compelling solution to the challenge of expanding a language model’s capacity to process extensive sequences of information without compromising performance. Traditional Transformer architectures often struggle with long-form content due to computational constraints and memory limitations as sequence length increases; this adaptation technique addresses these issues by selectively updating only a low-rank subspace of the key and value matrices. This targeted approach dramatically reduces the number of trainable parameters, enabling the model to effectively handle substantially longer sequences – and retain crucial contextual information – without incurring a prohibitive computational burden. The result is a model capable of maintaining both speed and accuracy when confronted with complex, lengthy inputs, paving the way for more sophisticated natural language understanding and generation capabilities.
Traditional Transformer architectures, while revolutionary in natural language processing, inherently struggle with long-context modeling due to quadratic scaling in computational complexity and memory usage. As sequence lengths increase, the attention mechanism-the core of Transformers-becomes prohibitively expensive, limiting their ability to effectively process extended texts. This limitation hinders performance on tasks requiring reasoning over substantial amounts of information, such as summarizing lengthy documents or engaging in complex dialogue. Recent advancements, however, directly confront this challenge by introducing techniques that optimize attention or reduce the sequence length, allowing models to retain crucial information from earlier parts of the input even when processing very long sequences. By mitigating the computational bottlenecks associated with long contexts, these innovations unlock the potential for more nuanced understanding and improved performance in real-world applications demanding sophisticated long-range dependencies.
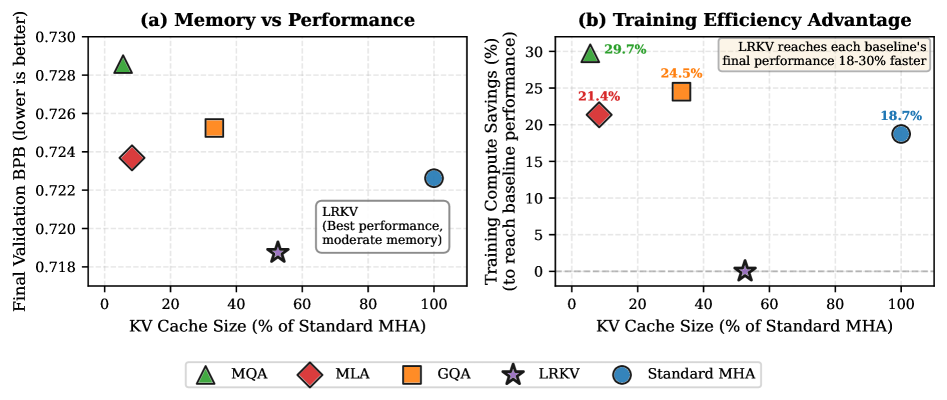
The development of increasingly powerful language models hinges on overcoming limitations in both computational cost and memory requirements. This method directly addresses these challenges through a focused optimization of training efficiency and cache memory usage. By minimizing the resources needed for both the initial training phase and subsequent operation, researchers can scale model capacity – and therefore performance – without incurring prohibitive costs. This allows for the creation of language models capable of handling more complex tasks and larger datasets, ultimately paving the way for more sophisticated applications in areas like natural language understanding and generation. The resulting models exhibit enhanced capabilities in processing and retaining information, leading to improved reasoning and a greater capacity for understanding nuanced contexts.
Recent advancements in low-rank KV adaptation have yielded substantial improvements in both the efficiency and performance of language models. Evaluations demonstrate a compelling 18-30% reduction in the cumulative training steps required to achieve optimal results, signifying a considerable acceleration in the development process. This heightened efficiency directly translates to practical benefits, allowing for faster iteration and reduced computational costs. Furthermore, the technique achieves a downstream combined accuracy of 37.9%, indicating a marked increase in the model’s ability to accurately process and understand complex information. These gains highlight the potential for building more powerful and scalable language models with reduced resource demands, paving the way for broader applications in natural language processing.
The innovative adaptation technique demonstrably enhances a language model’s ability to retain and utilize information within extended texts, fostering improved reasoning over long-form content. By addressing the challenges inherent in processing lengthy sequences, the method allows models to maintain contextual understanding and draw more accurate inferences from distant information. This is achieved through optimized knowledge storage and retrieval, enabling the model to effectively connect concepts across significant textual spans. Consequently, the technique not only processes longer documents but also exhibits a heightened capacity for complex reasoning, making it particularly valuable for tasks requiring in-depth analysis and synthesis of information from substantial sources.
The pursuit of efficient attention mechanisms, as demonstrated in this work with Low-Rank KV Adaptation, echoes a fundamental principle of understanding through deconstruction. This paper doesn’t simply accept the standard attention mechanism as a fixed entity; it actively dissects the key-value projections to reveal opportunities for compression and optimization. As David Hilbert stated, “We must be able to answer the question: what are the ultimate foundations of mathematics?” Similarly, this research seeks the foundational elements of efficient transformer architectures, questioning established norms to achieve significant reductions in memory footprint while maintaining performance. The exploration of low-rank factorization isn’t merely about shrinking model size; it’s a rigorous test of the underlying assumptions of attention itself, a process of reverse-engineering reality to reveal its most essential components.
What’s Next?
The elegance of Low-Rank KV Adaptation lies in its audacity – to dismantle a core component of the Transformer, the KV-cache, and reassemble it with fewer pieces. But the question isn’t merely how much can be pruned, but what is actually lost in the simplification. The paper demonstrates performance parity, a useful trick, certainly, but it skirts the deeper issue of representation. Does reducing the rank fundamentally alter the model’s capacity to distinguish? To hold multiple, nuanced concepts in memory? The observed gains are encouraging, yet feel provisional – a temporary truce in the endless arms race for parameters.
The natural progression isn’t simply to apply lower ranks universally. The true challenge will be identifying where these reductions are least damaging. A dynamic approach – a model that adapts its rank based on input complexity – seems a logical, if considerably more difficult, extension. One suspects the ‘head diversity’ argument-that maintaining multiple attention heads is crucial-will be revisited. Perhaps the heads aren’t fundamentally different, but merely redundant, masking an underlying lower-dimensional structure.
Ultimately, LRKV is a provocation. It suggests that the current obsession with scaling – with simply adding more parameters – may be a misdirection. The real breakthroughs won’t come from building bigger boxes, but from understanding what’s inside them, and daring to take things apart.
Original article: https://arxiv.org/pdf/2601.11471.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- One Piece Chapter 1180 Release Date And Where To Read
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- All Shadow Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- How to Beat Stonewalker Antiquum at the Gate of Truth in Crimson Desert
- Cassius Morten Armor Set Locations in Crimson Desert
- Grime 2 Map Unlock Guide: Find Seals & Fast Travel
- Marni Laser Helm Location & Upgrade in Crimson Desert
- USD RUB PREDICTION
2026-01-21 00:24