Author: Denis Avetisyan
A new quantization technique intelligently reshapes activation distributions to minimize information loss in highly compressed language models.
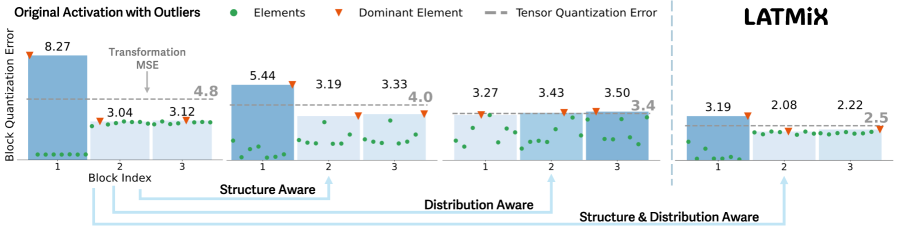
LATMiX employs learnable affine transformations to improve post-training quantization, particularly in low-bit regimes, by reducing outlier impact and optimizing activation energy.
Reducing the computational cost of large language models via quantization often suffers performance degradation, particularly with modern, low-bit microscaling (MX) data formats. This paper introduces ‘LATMiX: Learnable Affine Transformations for Microscaling Quantization of LLMs’, a novel post-training quantization method that learns affine transformations to redistribute activation energy and mitigate quantization errors. Our approach, guided by a theoretical analysis of transformation bounds under MX quantization, consistently improves accuracy across various zero-shot benchmarks and model sizes. Could learnable, distribution-aware transformations unlock even greater efficiency in deploying increasingly powerful large language models?
The Necessity of Efficient Language Models
Large language models have rapidly become integral to a diverse range of natural language processing applications, powering innovations from automated translation and chatbot interactions to complex text summarization and content generation. However, this progress comes at a cost; these models often comprise billions of parameters, demanding substantial computational resources for both training and deployment. The sheer size of these models creates significant barriers to accessibility, limiting their use to organizations with considerable infrastructure and expertise. Furthermore, the energy consumption associated with running these large models raises environmental concerns and hinders their scalability for widespread, real-time applications, necessitating research into methods for creating more efficient and sustainable language technologies.
The proliferation of Large Language Models (LLMs) is increasingly hampered by their substantial computational demands, creating a barrier to broader implementation and accessibility. While these models demonstrate impressive capabilities, their sheer size necessitates significant resources for both training and deployment – a limitation for many potential users and applications. Consequently, researchers are actively investigating quantization – a set of techniques designed to reduce the precision of the numbers used within the model – as a pathway to shrinking these digital behemoths. By representing model weights and activations with fewer bits, quantization aims to dramatically decrease memory footprint and accelerate processing speed, all while striving to maintain the high levels of accuracy that define these powerful tools. This pursuit of efficiency is not merely an optimization problem; it’s a critical step toward democratizing access to advanced natural language processing and enabling LLMs to function effectively across a wider range of devices and contexts.
Conventional quantization techniques, designed to compress large language models, frequently encounter a critical trade-off: a reduction in model size often correlates with a noticeable decline in accuracy. This challenge is particularly acute when scaling down to smaller models, where the limited parameter space becomes increasingly sensitive to information loss during the quantization process. The core issue lies in preserving the nuanced knowledge representation embedded within the model’s weights; simply reducing precision can disproportionately impact the ability to capture complex relationships in language. Consequently, research is actively focused on developing innovative quantization strategies – including techniques like mixed-precision quantization and learned quantization – that aim to minimize information loss and maintain robust performance even with significantly reduced model sizes, ultimately fostering more efficient and accessible natural language processing.
Refining Model Precision Through Advanced Techniques
Traditional LLM quantization methods often struggle to maintain performance after reducing model precision. Techniques like MR-GPTQ, FlatQuant, and LATMiX address these limitations through several innovations. MR-GPTQ utilizes a multi-resolution approach to selectively quantize weights, prioritizing the most impactful parameters. FlatQuant employs a learnable transformation to map weights to lower precision, minimizing information loss. LATMiX further refines this process by incorporating affine transformations learned through KL-Divergence minimization. These strategies collectively represent a departure from simple post-training quantization, enabling more aggressive compression with reduced accuracy degradation compared to baseline approaches.
Advanced quantization techniques for Large Language Models (LLMs) move beyond simple precision reduction by employing strategies designed to preserve model information. Multi-resolution approaches decompose the model, applying varying levels of quantization based on the sensitivity of different layers or parameters. Learnable transformations, often implemented as small neural networks, are integrated into the quantization process to adapt the representation of weights and activations. Affine learning, a specific type of learnable transformation, focuses on learning scaling and shifting parameters to minimize the distributional shift between the original and quantized models, thereby reducing performance loss. These combined methods allow for significant model compression with a smaller impact on accuracy compared to naive quantization strategies.
Employing low-precision numerical formats, such as MXFP4, represents a significant advancement in model compression for Large Language Models (LLMs). MXFP4 utilizes a 4-bit floating-point representation, substantially reducing model size and memory bandwidth requirements compared to traditional FP16 or FP32 formats. This reduction in precision is coupled with techniques designed to mitigate performance degradation, allowing LLMs to be deployed effectively in resource-constrained environments like edge devices and mobile platforms. While lower precision inherently introduces quantization error, careful implementation and accompanying algorithms minimize the impact on model accuracy, enabling significant compression ratios without prohibitive performance loss. The benefits of MXFP4 are particularly relevant for applications demanding low latency and reduced energy consumption.
LATMiX employs Kullback-Leibler (KL) Divergence as a guiding metric during the learning of affine transformations applied to Large Language Model weights during quantization. This approach minimizes the distributional shift between the original, full-precision weights and their quantized counterparts. By directly optimizing for reduced KL Divergence, LATMiX demonstrably improves quantization accuracy; benchmarks indicate a reduction of up to 15% in KL Divergence compared to standard quantization methods, resulting in improved model performance after quantization.
Validating Performance Across Model Scales
A systematic evaluation of quantization techniques is being conducted across a range of large language models, specifically those with 1, 3, and 8 billion parameters. The models included in this assessment are Llama3.2-1B, Qwen3-1.7B, Llama3.1-8B, Qwen3-8B, and Llama3.2-3B. This testing framework is designed to determine how effectively quantization scales with model size, providing data on performance maintenance and potential accuracy recovery as the number of parameters increases. The goal is to understand the limitations and benefits of these techniques when applied to models of varying computational complexity and to establish best practices for model optimization across different scales.
Model performance was evaluated using a suite of established reasoning benchmarks to assess capabilities across diverse tasks. These benchmarks include ARC-Easy and ARC-Challenge, which test commonsense reasoning; BoolQ, focusing on yes/no questions; HellaSwag, evaluating commonsense inference; OpenBookQA, requiring multi-step reasoning with scientific knowledge; PIQA, assessing physical commonsense; and WinoGrande, a challenging Winograd schema challenge dataset. Utilizing these benchmarks provides a standardized and comprehensive evaluation of model performance, allowing for comparison against existing methods and a detailed understanding of strengths and weaknesses in different reasoning domains.
Quantization applied to the Llama3.2-1B model demonstrates substantial performance gains in zero-shot accuracy. Utilizing the MXFP4 quantization technique, the model achieved an average accuracy of 72.1% across a suite of reasoning benchmarks. This represents an improvement of up to 3.5 percentage points compared to baseline, unquantized model performance. These results indicate that even smaller language models can realize significant benefits from quantization, improving their effectiveness without necessarily requiring increased model size or computational resources.
Testing on the Llama3.2-3B-Instruct model indicates that the proposed quantization method achieves an average accuracy recovery rate of 85.2%. This metric represents the extent to which accuracy is restored after quantization, compared to the original, full-precision model. Current benchmarks demonstrate this result is the highest reported to date for accuracy recovery on this model, suggesting a substantial improvement over previously published quantization techniques when applied to the Llama3.2-3B-Instruct architecture.
Evaluation of the Qwen3-8B model demonstrates consistent performance gains across the benchmark suite, encompassing ARC-Easy, ARC-Challenge, BoolQ, HellaSwag, OpenBookQA, PIQA, and WinoGrande. The implemented quantization method yielded an average accuracy of 68.7% on this model, indicating broad applicability and effectiveness regardless of the specific reasoning task. This improvement was observed across all evaluated tasks, suggesting a robust and generalized benefit from the technique applied to the Qwen3-8B architecture.
Towards Democratizing Access to Natural Language Processing
The pursuit of universally accessible natural language processing is gaining momentum through the synergistic combination of advanced quantization techniques and the development of smaller language models. Traditionally, powerful NLP capabilities demanded substantial computational resources, limiting access to large organizations with significant infrastructure. However, quantization – reducing the precision of numerical representations within the model – dramatically shrinks model size and lowers computational demands. When applied to strategically designed, smaller language models, this creates a pathway for deployment on a far broader range of devices, including mobile phones and embedded systems. This democratization of access empowers developers and researchers previously excluded by cost or resource limitations, fostering innovation across diverse fields such as personalized education, remote healthcare solutions, and assistive technologies for individuals with disabilities, ultimately broadening the positive impact of NLP on society.
The pursuit of smaller language models isn’t merely an academic exercise; it directly addresses the practical limitations of deploying these powerful tools. Reducing a model’s size dramatically lowers the computational resources required for operation, transitioning the landscape from reliance on expensive, centralized servers to the feasibility of on-device processing. This shift unlocks possibilities for integration into mobile devices, where models can respond instantly without internet connectivity, and embedded systems, allowing for intelligent automation in resource-constrained environments. Furthermore, deploying LLMs on edge servers-closer to the data source-minimizes latency and enhances data privacy, creating opportunities for real-time applications and localized intelligence across diverse fields, from personalized healthcare to smart infrastructure.
The broadening availability of large language models is poised to unlock a new wave of innovation across diverse fields. With reduced computational demands, developers and researchers previously constrained by resource limitations can now readily integrate LLMs into applications addressing critical societal needs. In education, personalized learning experiences and automated tutoring systems become increasingly feasible. Healthcare benefits from improved diagnostic tools and more efficient patient communication. Perhaps most profoundly, LLMs are enabling breakthroughs in assistive technology, offering individuals with disabilities unprecedented access to information and communication. This democratization of access isn’t simply about technological advancement; it represents a tangible step toward a more inclusive and equitable future powered by artificial intelligence.
The pursuit of increasingly efficient Large Language Models (LLMs) hinges on continued advancements in quantization and model compression techniques. Current research isn’t simply about shrinking models; it’s about intelligently reducing their size and computational demands without sacrificing performance. This involves exploring novel quantization schemes – representing model weights with fewer bits – and developing more sophisticated compression algorithms that identify and eliminate redundancy. Such innovations promise LLMs capable of running on resource-constrained devices, opening doors to real-time applications and personalized AI experiences previously unimaginable. Ultimately, these efforts aim to redefine the limits of Natural Language Processing, fostering a future where powerful AI is seamlessly integrated into everyday life and accessible to all, and enabling breakthroughs in fields ranging from automated scientific discovery to truly adaptive educational tools.
The pursuit of efficient large language models, as demonstrated by LATMiX, inherently demands a ruthless reduction of complexity. This work focuses on mitigating quantization errors through learned affine transformations, effectively reshaping the activation distribution to preserve crucial information. It echoes a principle articulated by Claude Shannon: “The most important thing is to get the message across.” LATMiX achieves this by skillfully managing the entropy introduced by low-bit quantization, ensuring that the core ‘message’ – the model’s knowledge – remains largely intact despite aggressive compression. The method’s focus on outlier reduction and energy redistribution aligns with the idea that lossless compression-and therefore, clarity-is achieved not through adding features, but through eliminating unnecessary noise.
Further Refinements
The pursuit of minimal quantization error continues. LATMiX demonstrates a pragmatic reduction, but the inherent trade-off between compression and fidelity remains. Future work must address the energy cost of learning these affine transformations. A truly efficient solution will not simply shift the burden of computation, but genuinely lessen it. The current focus on activation redistribution, while effective, feels… local. A more global understanding of information flow within these large models is necessary.
Consider the limitations of post-training quantization itself. It operates on a finished structure. Perhaps the most significant gains lie not in refining the compression after training, but in building models inherently resilient to it. Quantization-aware training, though more complex, may prove to be the more sustainable path. Clarity is the minimum viable kindness; forcing a model to fit a constrained space after the fact feels… unkind.
The present work primarily concerns activations. Weight quantization, though touched upon, presents a distinct set of challenges. A unified approach – one that considers both weights and activations holistically – may unlock further improvements. The question isn’t simply “how low can we go?”, but “what is the minimum necessary?”. Complexity is vanity.
Original article: https://arxiv.org/pdf/2602.17681.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Shadow Armor Locations in Crimson Desert
- All Skyblazer Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- Best Bows in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- How to Craft the Elegant Carmine Armor in Crimson Desert
- Wings of Iron Walkthrough in Crimson Desert
- Keeping Large AI Models Connected Through Network Chaos
2026-02-23 19:40